大模型的橫空出世,打破30年來互聯網的運行規則。代碼版“互聯網小憲法”robots.txt開始失效。robots.txt是一個文本文件,每個網站都用它來說明自己是否願意被爬蟲抓取。30年來,一直是它,讓互聯網不至於在混亂中運行。
不過這個規則能長久運行其實純靠一個人性邏輯——你讓搜索引擎抓取你的網站,同時你會獲得搜索引擎的流量回報。這也是幾位互聯網先驅者達成的握手協議,為造福互聯網上的所有人。
這種既沒有寫入法律,也沒有權威約束,稍顯天真的規則在運行 30 年後,終於出現問題——越來越多的 AI 公司用爬蟲抓取你的網站數據,提取數據集,訓練大模型和相關產品,但他們並不像搜索引擎那樣回饋以流量,甚至根本不承認有你存在,你的數據就像肉包子打狗一樣有去無回。
很多數據擁有者非常憤怒,新聞出版商等數據擁有者不斷地發聲,封鎖 AI 爬蟲,反抗自己的數字資產被無償使用。不過如Google和 OpenAI 這樣的 AI 推動者,也在試圖找到更好的規則,畢竟隻有各方獲益才能持續發展。
01
robots.txt,
一個簡單有效的協議
robots.txt,通常位於“yourwebsite.com/robots.txt”。
任何一個運營網站的人,無論他的網站是大是小、是烹飪博客還是跨國公司,都可以通過這個文件來告訴誰可以進入網站,而誰不可以。
“哪些搜索引擎可以索引你的網站?哪些文件項目可以提取並保存你的網頁版本?競爭對手能否保存你的網頁?……”這些都由你決定,並通過這個文件作出聲明,讓整個互聯網看到。
不過現在,AI 已經打破這個平衡:網上的公司正在利用你的網站數據,提取大量訓練數據集,建立大模型和相關產品,這裡面可能根本不承認有你存在。
在互聯網發展的早期,機器人有很多名字:蜘蛛、爬蟲、蠕蟲、網蟻、網絡爬蟲。大多數時候,這些名字都出於好意。通常抓取數據是開發人員為給一個新網站建立目錄,以確保自己的網站正常運行,或者建立一個研究數據庫——這是 1993 年左右的事情,當時搜索引擎還沒有普及,電腦硬盤裡還裝不下大部分互聯網內容。
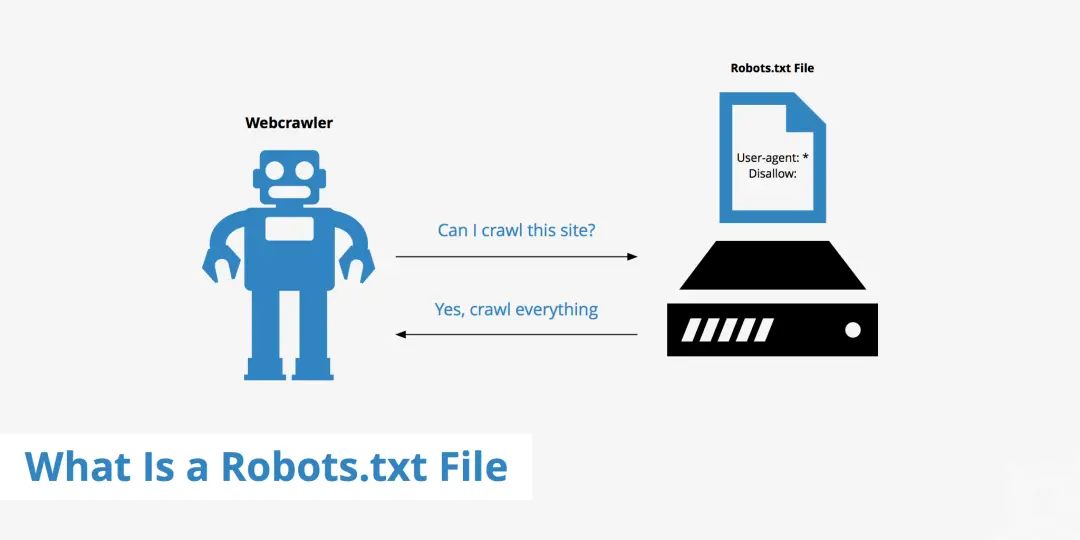
robots.text 的真正作用|圖片來源:KeyCDN
那時唯一的問題是流量:對於網站瀏覽者或所有者來說,訪問互聯網都又慢又貴。如果你像大多數人一樣,在自己的電腦上管理網站,或用傢庭互聯網,但凡有幾個機器人過度熱衷於下載網頁,就會導致網站崩潰,流量賬單激增。
1994 年的幾個月裡,一位名叫馬特恩·科斯特(Martijn Koster)的軟件工程師,與其他一群網站管理員一起,提出一個名為“機器人修復協議”的解決方案。該方案非常簡單:要求網站開發人員在其域名中添加一個純文本文件,指定哪些機器人不得瀏覽其網站,或者列出對所有機器人禁止訪問的網頁。
在這個時期,你甚至可以維護一個包含每個機器人的清單——科斯特這些人就是這麼做的。對於機器人制造者來說就更簡單:一切按照文本文件的規定來。
從一開始科斯特就明確表示,他並不討厭機器人,也不打算消滅它們。1994 年初,有一個名為 WWW-Talk,包括蒂姆·伯納斯·李(Tim Berners-Lee)和馬克·安德森(Marc Andreessen)等早期互聯網先驅的郵件列表,科斯特給這個列表發送的第一封電子郵件中說:“網絡中有少數會造成運行問題和令人不快的情況,機器人是其中之一。但與此同時,它們確實提供有用的信息。”
科斯特說,不要爭論機器人是好是壞——因為這並不重要,它們就在這裡,不會消失,他隻是想設計一種系統,“將問題最小化,將利益最大化”。
到那年夏天,他的建議已經成為一項標準——雖然不是官方標準,但已被普遍接受。那年 6 月,科斯特再次向 WWW-Talk 小組更新提案,他寫道,“這是一種通過在服務器上提供一個簡單的文本文件,引導機器人遠離網絡服務器 URL 空間中某些區域的方法。如果你有大型文件、帶有大量 URL 子目錄的 CGI 腳本、臨時信息,或者你根本不想為機器人提供服務,那麼這種方法就特別方便。”
他建立一個特定主題的郵件列表,其成員就這些文本文件的一些基本語法和結構達成一致,把文件名從 RobotsNotWanted.txt 改為簡單的 robots.txt,幾乎所有成員都支持它。在接下來 30 年的大部分時間裡,這種方式都非常有效。
接著,硬盤不再適合互聯網,機器人的功能也隨之變得更強大更細分。Google使用機器人來提取和索引其整個網絡的搜索引擎,該搜索引擎成為網絡的接口,每年已為該公司帶來數十億美元的收入。必應的爬蟲也如此,微軟將其數據庫授權給其他搜索引擎和公司。
互聯網檔案館(非營利組織,定期收錄並永久保存全球網站上可以抓取的信息)使用爬蟲來存儲網頁,以供子孫後代使用。亞馬遜的爬蟲在網絡上尋找產品信息,根據最近的一個反壟斷訴訟,該公司利用這些信息來處罰那些在亞馬遜網站外提供更低價交易的賣傢。
02
搜索爬蟲對網站來說
“有得有失”,AI 呢?
但現在,像 OpenAI 這樣的人工智能公司提取網絡數據,是為訓練大語言模型,這些模型可能會再次從根本上改變我們訪問和共享信息的方式。
現代互聯網通過下載、存儲、組織和查詢的能力,為任何一傢公司或任何一位開發人員都提供幾乎世界上所有累積的知識。在過去的一年左右的時間裡,ChatGPT等人工智能產品的崛起及其背後的大型語言模型,讓高質量的訓練數據成為互聯網上最有價值的商品。
這使得各大互聯網必須重新考慮其服務器上數據的價值,並重新思考誰可以訪問哪些數據。過度放任會讓你的網站失去所有價值;過度限制則會讓你的網站成為隱形網站。你正在面對新的公司、新的合作夥伴和新的利害關系,必須不斷作出選擇。
互聯網機器人有幾種類型。你可以做一個人畜無害的機器人,讓你所有的網頁鏈接到其他有效的網頁上;你也可以讓一個糙漢的機器人,在網上到處搜集可以找到的每個電子郵件地址和電話號碼。但最常見的也是目前最具爭議的,是最簡單的網絡爬蟲,它的工作就是盡可能多地查找和下載互聯網上的內容。
網絡爬蟲的運行一般都很簡單。它們從一個網站開始,例如 cnn.com、wikipedia.org 或 health.gov。爬蟲下載第一頁並將其存放在某個位置,然後自動點擊該頁面上的每個鏈接,下載這些鏈接,點擊上面的所有鏈接,再點擊、下載……。隻要有足夠的時間和足夠的計算資源,爬蟲最終就能找到並下載所需的上億個網頁。
2019 年,Google約有超過 5 億個網站擁有 robots.txt 頁面,來規定是否允許這些爬蟲訪問以及允許訪問哪些內容。這些頁面的結構通常大致相同:命名一個“用戶代理”(User-agent),即爬蟲向服務器表明身份時使用的名稱。
Google的代理是 Googlebot;亞馬遜的代理是 Amazonbot;必應的代理是 Bingbot;OpenAI 的代理是 GPTBot。Pinterest、LinkedIn、Twitter 以及許多其他網站和服務都有自己的機器人,但並非所有機器人都會在每個頁面上被提及。

Google對 Googlebot 的解釋 | 圖片來源:Google
維基百科和 Facebook 這兩個平臺,被機器人接管得最為徹底。在 robots.txt 頁面下面,推出不允許特定代理訪問的網站部分或頁面,以及允許訪問的特定例外情況。如果這一行隻寫著“禁止:/”,則完全不歡迎爬蟲。
現在對於大多數人來說,“服務器過載”已經不是什麼需要考慮的問題。Google搜索發起者之一約翰·穆勒(John Mueller)說:“現在,這通常與網站資源關系不大,更多與個人喜好有關,也就是你想要爬取和索引什麼就有什麼。”
大多數網站所有者需要回答的最大問題就是,是否允許被Google機器人抓取。這個問題的取舍相當簡單:如果Google可以抓取你的頁面,它就可以將其編入索引並顯示在搜索結果中。任何您希望 Google 抓取的頁面,Googlebot 都需要看到。(當然,Google 在哪裡展示的你網站,在何處折疊頁面,這是另一個問題。)前面的問題就在於,你是否願意讓 Google 占用你的帶寬並下載你網站,以換取被搜索帶來的可見性。
對於大多數網站來說,這是很容易做的決定。Medium 創始人托尼·斯塔佈賓(Tony Stubblebine)說:“Google是我們最重要的爬蟲。Google下載 Medium 的所有網頁,作為交換,我們獲得大量的流量,這是雙贏。每個人都這麼認為,這就是Google與整個互聯網達成的協議,在向其他網站傳輸流量的同時,他們還在搜索結果中出售廣告。”
從各個方面來看,Google都是 robots.txt 的好公民。Google的穆勒說,“幾乎所有知名的搜索引擎都遵守這一規定。”他們很高興能夠抓取網頁,也沒有因此惹惱別人,隻會讓大傢的生活變得更輕松。
03
數據被用來訓練 AI,
是肉包子打狗?
在過去一年左右的時間裡,人工智能的興起顛覆這種方式。對於許多出版商和平臺來說,他們的數據被抓取訓練,感覺不像是交易,更像是被偷竊。
斯圖佈爾賓說:“我們很快就發現,人工智能公司不僅沒有進行價值交換,我們也沒有得到任何回報,完全是零。”去年秋天,當斯塔伯賓宣佈將封鎖 AI 爬蟲時,他寫道:“AI 公司從作傢那裡攫取價值,以便向互聯網讀者發送垃圾郵件”。
過去一年,媒體行業的大多數人都達成斯塔佈賓的觀點。去年秋天,BBC 國傢總監羅德裡·塔爾凡·戴維斯 (Rhodri Talfan Davies) 寫道:“我們認為,目前這種未經允許就『搜刮』BBC 數據以訓練大模型的做法不符合公眾利益,”他宣佈 BBC 也將封鎖 OpenAI 的爬蟲。
《紐約時報》也封鎖 GPTBot,幾個月後對 OpenAI 提起訴訟,指控 OpenAI 的模型是通過使用《紐約時報》數百萬篇受版權保護的新聞文章、深度調查、觀點文章、評論、操作指南等建立起來的。路透社新聞應用編輯本·威爾士(Ben Welsh)的一項研究發現,在 1156 傢公開出版商中,有 606 傢在其 robots.txt 文件中封鎖 GPTBot。
不僅僅是出版商,亞馬遜、Facebook、Pinterest、WikiHow、WebMD 和許多其他平臺都明確禁止 GPTBot 訪問其部分或全部網站。在這些 robots.txt 頁面中,OpenAI 的 GPTBot 是唯一一個被明確完全禁止的爬蟲,但也有很多其他人工智能專用機器人開始爬取網絡,比如 Anthropic 的 anthropic-ai 和Google的新版 Google-Extended。
根據 Originality.AI 去年秋季進行的一項研究,網絡上排名前 1000 位的網站有 306 個封鎖 GPTBot,但隻有 85 個封鎖 Google-Extend,28 個封鎖 anthropic-ai。
也有一些爬蟲同時用於網絡搜索和 AI 訓練。由 Common Crawl 組織運營的 CCBot 作為搜索引擎抓取網絡,但其數據也被 OpenAI、Google等公司用於訓練模型。微軟的 Bingbot 既是搜索爬蟲,也是 AI 爬蟲。而這些僅僅是表明自己身份的爬蟲——還有許多爬蟲試圖“陰暗地”運行,因此很難在無數的網絡流量中封鎖它們,甚至都找不到它們。
在很大程度上,GPTBot 之所以成為 robots.txt 中的最主要被封鎖對象,是 OpenAI 自己允許的。OpenAI 發佈推廣一個關於如何封鎖 GPTBot 的頁面,還建立自己的爬蟲,以便在每次接近各個網站時候,大聲嚷嚷是誰來。
當然,OpenAI 是在制作出如此強大的底層模型之後才做這事的,這時候它都已經成為技術生態系統的重要組成部分。

OpenAI 的部分安全性聲明 | 圖片來源:OpenAI
但 OpenAI 的首席戰略官 傑森·權(Jason Kwon)說,這正是問題的關鍵所在,他說,“我們是生態系統中的一個參與者。如果你想以開放的方式參與這個生態系統,那麼這是每個人都感興趣的。”他說,如果沒有交易,網絡就會開始收縮、關閉——這對 OpenAI 和每個人來說都是不利的,“我們做這一切都是為讓網絡保持開放”。
在默認情況下,《機器人修復協議》一直是被允許的。因為就像科斯特 30 年前所做的那樣,它相信大多數機器人都是好的,都是由好人制造的。總的來說,這個思想也是正確的。“我認為互聯網從根本上說是一種社會生物,”OpenAI 的傑森·權說,“這種握手言和方式已經持續幾十年,並且很有效。”他說,OpenAI 在遵守這一協議方面的作用包括:保持 ChatGPT 對大多數用戶免費(從而實現價值反哺),並尊重機器人的規則。
04
阻止 AI 爬蟲,
是對抗未來嗎?
但是,robots.txt 並不是一份法律文件,在它誕生 30 年後的今天,仍然依賴於所有相關方的善意。任何爬蟲都可以無視 robots.txt,用不用擔心受到影響。(網絡抓取問題也有法律先例,但很復雜,且主要是在允許抓取的情況下,而不是禁止情況)。
例如,互聯網檔案館在 2017 年就宣佈不再遵守 robots.txt 的規則。互聯網檔案館 Wayback Machine 主任馬克·格雷厄姆(Mark Graham)當時寫道:“隨著時間的推移,我們發現,為搜索引擎而建的 robots.txt 文件並不一定符合我們的目的。”
隨著人工智能公司的不斷增加,他們的爬蟲也越來越肆無忌憚,任何想“事不關己高高掛起”或坐等人工智能占領世界的人,都將面臨著一場無休止的“打地鼠”遊戲。
人們需要盡力阻止每個爬蟲(如果可能的話)的同時,還要考慮一個人後果——如果真的像Google等公司預測的那樣,AI 是搜索的未來,那麼阻止 AI 爬蟲可能是短期的勝利,長遠的災難。
圖片來源:視覺中國
阻止和不阻止 AI 爬蟲的兩方都有人認為,需要更好、更強、更嚴格的工具來管理爬蟲。因為事關的利益太大,而且有太多不受監管的例子出現,畢竟不能指望每個人都自覺遵守規則。2019 年,一篇關於網絡爬蟲合法性的論文中寫道:“雖然許多人在使用網絡爬蟲時有一些自我管理規則,但整體規則過於薄弱,且追責困難。”
一些出版商希望有新的規則,可以對抓取的內容和用途進行更準確的控制,而不是 像 robots.txt 一樣一刀切,隻有“是”或“否”。幾年前,Google曾努力將機器人排除協議作為正式的官方標準,Google也曾以 robots.txt 為舊標準、太多網站不重視它,力圖不再強調 robots.txt。
Google信任副總裁丹尼爾·羅曼(Danielle Romain)2023 年寫道:“現有的網絡發佈者控制規則是在新的 AI 和研究案例之前開發的。現在是時候為網絡和 AI 社區,重新探索機器讀取方式,以供網絡出版商選擇。”
即使在訓練大模型上,AI 公司面臨著很多監管和法律問題,但大模型仍在快速進步,似乎每天都有新公司成立。現在不論大小的網站都面臨著一個抉擇:是屈從於人工智能革命,還是堅守選擇陣地進行對抗。對於那些屈服的網站來說,他們最有力的說辭,便是沿用三十年的 robots.txt,這個由一些最早最樂觀的互聯網忠實信徒們達成的協議。他們相信,互聯網是好的,其中都是希望互聯網變好的人。
在那個世界,用文本文件解釋你的願望就足夠。現在,隨著 AI 重塑互聯網的文化和經濟,一個不起眼的純文本文件開始有點過時。