你能想象,那些被遺忘在網盤的陳年老圖,有朝一日能價值千金?就在最近,路透社報道稱,蘋果公司正與圖像托管網站Photobucket協商,希望得到這傢公司近130億張照片、視頻組成的龐大圖像庫,並以此來訓練AI模型。蘋果不是這傢網站的唯一買傢,其他矽谷大廠們都在尋求與之達成協議。而這些巨頭們也毫不吝嗇,甚至願意掏出數十億美元的真金白銀購買這些素材。
不隻是Photobucket,Reddit、Youtube等知名網站都成科技巨頭們的瘋搶目標。
蘋果為訓練AI買圖片,網友擔憂隱私
Photobucket是一個提供影像寄存、視頻寄存、幻燈片制作與照片分享服務網站,成立於2003年。在當時,用戶把這個網站當作個人相冊,與功能與現在流行的在線相冊非常相似。
在巔峰期,該網站曾擁有7000萬用戶。而到2007年,Photobucket就聲稱已有超過28億張圖像上傳到其網站。不過隨著越來越多的功能更強大的在線相冊App出現之後,這種網站式的在線相冊也逐漸失去熱度。
不過畢竟是一傢成立二十多年的網站,別的不說,數據是真的多,130億張圖片與視頻,足夠AI模型消化很久。
據悉,蘋果購買的圖片的主要目的就是提高生成式AI的水平。
除此之外,蘋果公司在早些時候與另一傢圖片素材網站Shutterstock達成數百萬張圖片的授權協議,據悉這筆交易的價值在2500萬美元到5000萬美元之間。
隨著 今年6月份WWDC大會日益臨近,每個人都在期待蘋果公司能帶來“令人驚嘆”的AI功能。
但和上筆交易不同,不少網友開始為隱私擔心。有人評論表示,Photobucket的圖片來源都是基於網友的“托管,這就意外著這些圖片雖然已經是陳年老圖,但仍屬於用戶的個人秘密。
而Shutterstock的數據大多是免版稅的圖片、矢量圖和插圖庫,包括影片剪輯以及音樂曲目,本身就可以授權給用戶使用。這麼一對比,網友對於Photobucket的數據隱私安全問題也可以理解。
除涉及隱私以外,不少網友還對這些庫存照片的質量提出質疑。如果給AI喂食這些本來就帶有錯誤的圖片,那麼是否會生成質量更低的圖片呢?

總之,就蘋果購買Photobucket圖片的行為,大多數網友並不贊同。
但即使冒著泄露隱私的風險,蘋果和其他公司們還是得“鋌而走險”搞來這些數據。主要原因還是高質量的互聯網數據,可能沒幾年就要耗盡。
其實早在多年前,各大科技巨頭就已經碰到訓練語料缺失的瓶頸。
據《紐約時報》報道,OpenAI在訓練GPT-4時,就曾遇到英文文本資料缺失的情況。
為處理這個問題,OpenAI推出一款名為Whisper語音識別工具,用來轉錄Google旗下視頻平臺Youtube的視頻音頻,生成大量的對話文本。

據報道稱,這款工具以開源的名義轉錄超過一百萬小時的Youtube視頻,實際上已經違反Youtube的隱私規則,而這些資料也成為ChatGPT的基礎。
這並不是OpenAI第一次因為偷扒數據犯錯。包括《紐約時報》在內,多傢數字新聞媒體對OpenAI提起版權侵權訴訟,認為他們的數千篇報道被OpenAI用來訓練ChatGPT。
當然,通過“爬蟲”等手段搜刮訓練數據的科技公司不止OpenAI這一傢,“受害者”Google也曾通過修改服務條款的方式,將“使用公開信息訓練AI模型”偷偷寫進隱私細則中,從而允許工程師們利用公開的文檔、在線資料等開發AI產品。
不過隨著OpenAI在版權問題上越陷越深,其他科技巨頭也隻能乖乖掏錢為訓練數據付費。
至少比起互聯網上免費抓取的數據,Photobucket近130億的數據量還是相對來說質量更高點。
花錢買數據,或許還不夠
可怕的是,即便是130億的數據量,也可能喂不飽現在的AI的模型。
研究機構Epoch直白地表示,現在科技公司使用數據的速度已經超過數據生產的速度,這些公司最快會在2026年就耗盡互聯網上的高質量數據。
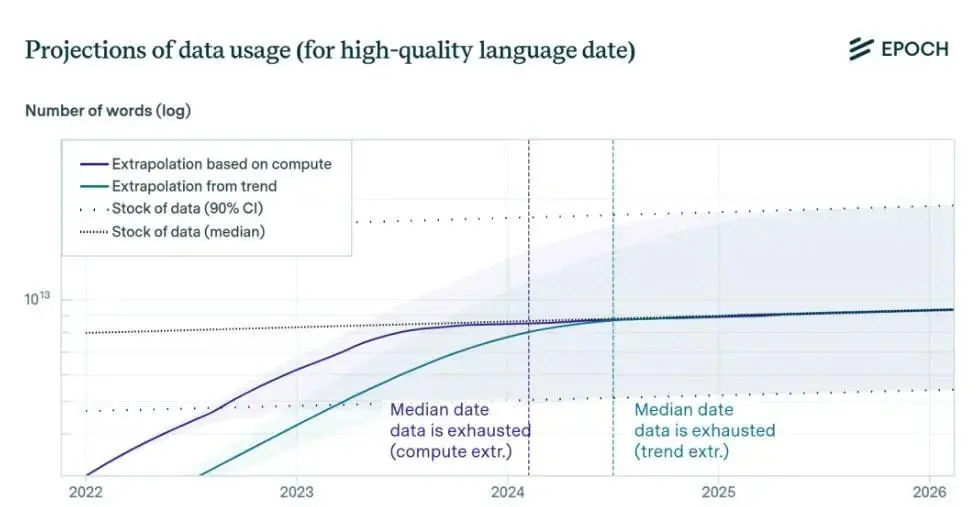
有數據統計,在2020年11月發佈的GPT-3上,使用3000億個Token的訓練數據。而到2024年,GooglePaLM 2的訓練數據量則達到3.6萬億個Token。
數據量是一回事,數據的質量更是直接影響AI大模型的生成能力。正如網友所擔憂的那樣,低質量的數據甚至可能讓AI陷入不可逆轉的方向。
面對這樣的問題,OpenAI開始嘗試使用合成數據(AI生成的數據)來訓練AI。這樣既可以減少對受版權保護數據的依賴,同時也能訓練出更強大的結果。
對此OpenAI和一系列機構開始研究使用兩個不同的模型來生成更有用、更可靠的合成數據,其中一個模型用來生成數據,另一個則用來對生成的數據進行審核。
不隻是OpenAI,英偉達很早就在用合成數據彌補現實世界的數據。在2021年11月,英偉達對外推出合成數據生成引擎Omniverse Replicator 。
英偉達將其描述為“用於生成具有基本事實的合成數據以訓練 AI 網絡的引擎”,其作用就是用來訓練AI。
此產品推出後,由該引擎生成的合成數據在自動駕駛、機器人等多個場景裡都得到驗證,因此英偉達也在近些年希望將其推廣到更多領域,包括聊天機器人。
然而,合成數據在工業場景裡的成功案例,並不代表在其他領域都能遵循物理規律。
有時候AI連真實圖片都無法理解,更不要說理解二次生成的圖片。