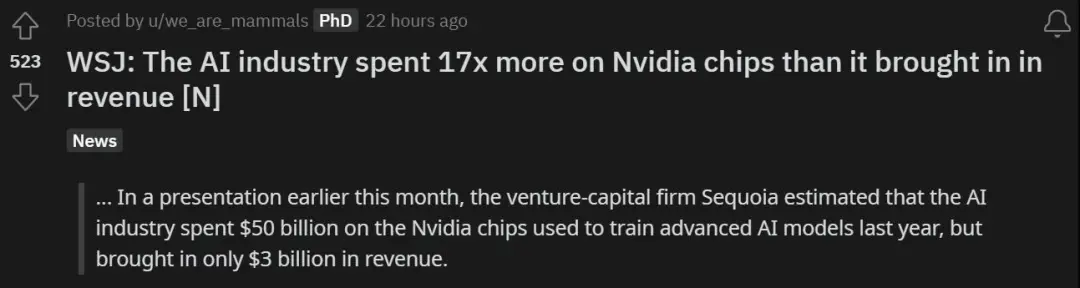
搞AI大模型,實在太燒錢。我們知道,如今的生成式AI有很大一部分是資本遊戲,科技巨頭利用自身強大的算力和數據占據領先位置,並正在使用先進GPU的並行算力將其推廣落地。這麼做的代價是什麼?最近《華爾街日報》一篇有關明星創業公司的報道裡給出答案:投入是產出的17倍。
上個周末,機器學習社區圍繞這個數字熱烈地討論起來。
明星創業公司,幾周估值翻倍:但沒有收入
由知名投資人 Peter Thiel 支持的 AI 初創公司 Cognition Labs 正在尋求 20 億美元估值,新一輪融資在幾周之內就將該公司的估值提高近六倍。
在如今火熱的生成式 AI 領域裡,Cognition 是一傢冉冉升起的新星。如果你對它還不太熟悉,這裡有它的兩個關鍵詞:國際奧賽金牌團隊,全球首位 AI 程序員。
Cognition 由 Scott Wu 聯合創立,其團隊組成吸引眼球,目前隻有 10 個人,但包含許多國際信息學奧林匹克競賽的金牌選手。

Cognition Labs 的團隊,CEO Scott Wu(後排身穿襯衣)隻有 27 歲。
該公司在今年 3 月推出 AI 代碼工具 Devin,號稱“第一位接近人類的 AI 程序員”,能夠自主完成復雜的編碼任務,例如創建自定義的網站。從開發到部署,再到 debug,隻需要人類用自然語言給需求,AI 就能辦到。
該新聞很快就登上眾多媒體的頭條,也成為熱搜:
一些投資者表示,Devin 代表人工智能的重大飛躍,並可能預示著軟件開發的大規模自動化之路已經開啟。
Cognition 雖然神奇,但它並不是個獨苗。最近一段時間,生成式 AI 展現超乎想像的吸金能力。去年 12 月,總部在法國的 Mistral 獲得 4.15 億美元融資,估值達到 20 億美元,比前一年夏天的一輪融資增長大約七倍。
3 月初,旨在挑戰Google網絡搜索主導地位的 AI 初創公司 Perplexity 也傳來新一輪融資的消息,新估值有望達到近 10 億美元。
而在這其中,作為一傢旨在提供 AI 自動代碼工具的創業公司,Cognition 去年才開始研發產品,目前並沒有獲得有意義的收入數字。今年初,在 Founders Fund 牽頭的一輪 2100 萬美元融資中,該公司的估值達到 3.5 億美元。據介紹,美國著名創業投資傢、創辦 Founders Fund 的 Peter Thiel 幫助領導對 Cognition 的投資。

Peter Thiel 是全球暢銷書《從 0 到 1:開啟商業與未來的秘密》的作者,身傢 71 億美元。
AI 編寫代碼看起來是一個有前途的大模型應用方向,其他提供類似產品的公司也看到增長勢頭。上個季度,微軟的代碼工具 GitHub Copilot 用戶數量增長 30% 達到 130 萬。Magic AI 是 Cognition 的競爭對手,2 月份獲得 1.17 億美元的投資。國內也有一些代碼生成自動化工具的初創企業,在生成式 AI 技術爆發後正在加速行業落地。
盡管出現令人鼓舞的增長跡象,新公司的估值也不斷膨脹,但這種快速發展也引發人們對於出現泡沫的擔憂 —— 到目前為止,很少有初創公司能夠展示他們如何賺錢,想要收回開發生成式 AI 的高昂成本,似乎還沒有門道。
在 3 月的一次演講中,紅杉資本(Sequoia Capital)有投資人估計 AI 行業去年為訓練大模型,僅在英偉達芯片上就花費 500 億美元,而換來的收入是 30 億美元。
所以說,不算電費,開銷是收入的 17 倍。

怎麼樣,今年還玩得起嗎?
出路在哪
如今生成式 AI 技術的爆發,可謂驗證強化學習先驅 Richard S. Sutton 在《苦澀的教訓》中的斷言,即利用算力才是王道。黃仁勛兩周前在 GTC 上也曾表示:“通用計算已經失去動力,現在我們需要更大的模型、更大的 GPU,需要將 GPU 堆疊在一起…… 這不是為降低成本,而是為擴大規模。”
但是在千億、萬億參數量的大模型出現之後,通過提升規模來提升智能的方法是否還可以持續,是一個無法回避的問題。更何況現在的大模型已經很貴。
華爾街日報的文章迅速引起大量討論。有網友認為:“資本支出通常就是一次性的,而投資的收入卻是日積月累的。生成式 AI 剛剛起步,其後續的經濟收益可能是巨大的。”

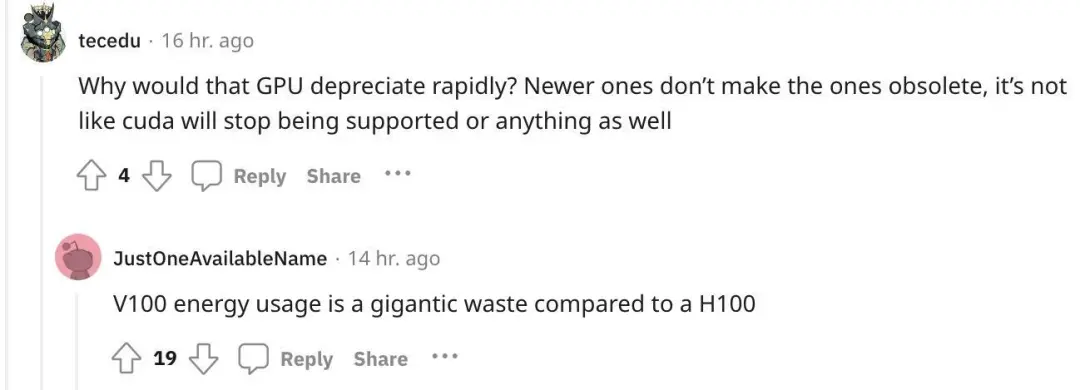
但這種樂觀的觀點很快遭到反駁,另一位網友指出:“資本的支出的確是一次性的,但 GPU 會相對較快地貶值。”

為什麼說 GPU 會快速貶值呢?雖然較老版本的 GPU 也不會停止支持 CUDA(英偉達推出的運算平臺)等等,但與 H100 相比,V100 的能源消耗是巨大的浪費。
畢竟同樣也是在 3 月份,英偉達已經發佈全新一代 AI 加速的 GPU Blackwell 系列。
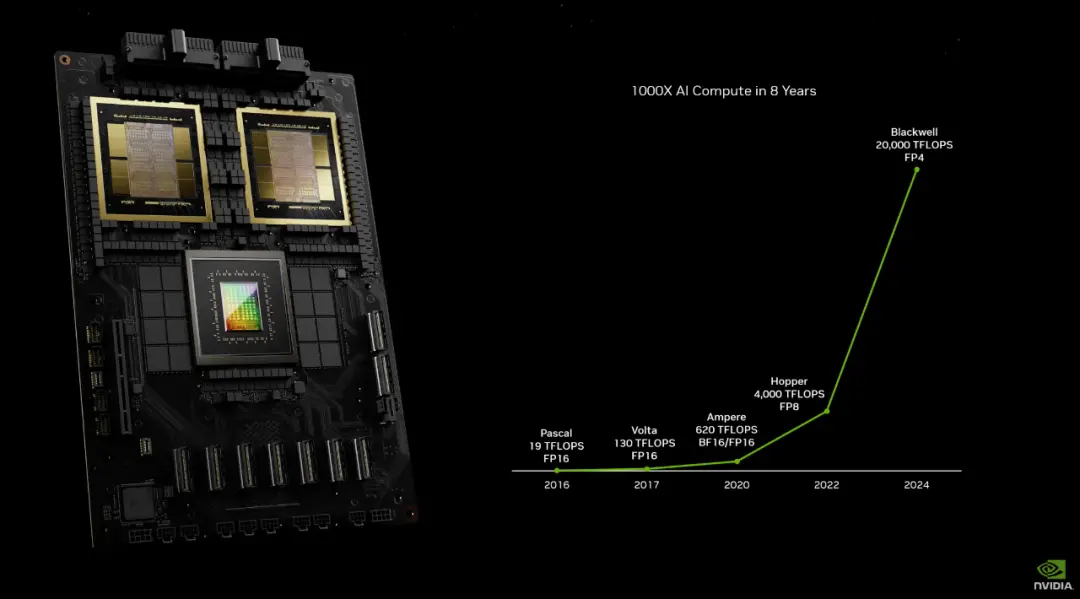
近八年來,AI 算力增長一千倍。
如果使用 V100 可以賺錢,那當然沒問題。然而,如諸多媒體報道所述,對大多數公司來說,現階段運行大模型並沒有轉化為實際收入。
另一方面,看看現在大模型每周都在推陳出新的狀態,即使幾年前的 GPU 在算力角度看可以接受,但大模型也在“快速折舊”。七年後的 AI,用現在的基礎設施能支撐嗎?
此外,如果一傢公司花費大量成本來購買 V100,試圖跟上生成式模型的趨勢,那麼可能就會出現研究團隊雇傭成本不足的問題,那麼最終可能還是無法做出有實際應用、經濟收益的產品。
值得註意的是,許多 LLM 都需要額外的處理層來消除幻覺或解決其他問題。這些額外的層顯著增加生成式模型的計算成本。這不是 10% 的小幅增長,而是計算量增長一個數量級。並且許多行業可能都需要這種改進。

圖源:Reddit 用戶 @LessonStudio
從行業的角度講,運行生成式大模型需要大型數據中心。英偉達已經非常解這個市場,並持續迭代更新 GPU。其他公司可能無法僅僅投資數百億美元來與之競爭。而這些 GPU 需求還隻是來自各大互聯網公司的,還有很多初創公司,例如 Groq、Extropic、MatX、Rain 等等。
最後,也有人給出這種誇張投入的“合理性”:坐擁大量現金的微軟、Google和 Meta,他們因為反壟斷法規而無法繼續收購,因而隻能選擇將資金投入 AI 技術發展。而 GPU 支出的折舊,可以作為損失避免繳納更多稅款。
但這就不是創業公司所要考慮的事。
無論如何,競爭會決出勝者。無論花掉多少錢,成為第一可能就會帶來潛在的收益……
但是什麼樣的收益,我們還無法作出預測。難道,生成式 AI 真正的贏傢是英偉達?