ChatGPT今天升級GPT-4模型,AI能力更加強大,國內在這方面也在迅速追趕,有國歌國產版ChatGPT問世,現在清華大學教授唐傑宣佈由該校AI成果轉化的ChatGLM開始內測。
據介紹,對話機器人 ChatGLM(alpha內測版:QAGLM),這是一個初具問答和對話功能的千億中英語言模型, 並針對中文進行優化,現已開啟邀請制內測,後續還會逐步擴大內測范圍。

與此同時,繼開源 GLM-130B 千億基座模型之後,我們正式開源最新的中英雙語對話 GLM 模型: ChatGLM-6B,結合模型量化技術,用戶可以在消費級的顯卡上進行本地部署(INT4 量化級別下最低隻需 6GB 顯存)。
經過約 1T 標識符的中英雙語訓練,輔以監督微調、 反饋自助、人類反饋強化學習等技術的加持,62 億參數的 ChatGLM-6B 雖然規模不及千億模型,但大大降低用戶部署的門檻,並且已經能生成相當符合人類偏好的回答。
ChatGLM 參考 ChatGPT 的設計思路,在千億基座模型 GLM-130B1 中註入代碼預訓練,通過有監督微調(Supervised Fine-Tuning)等技術實現人類意圖對齊。
ChatGLM 當前版本模型的能力提升主要來源於獨特的千億基座模型 GLM-130B。它是不同於 BERT、GPT-3 以及 T5 的架構,是一個包含多目標函數的自回歸預訓練模型。
2022年8月,我們向研究界和工業界開放擁有1300億參數的中英雙語稠密模型 GLM-130B1,該模型有一些獨特的優勢:
雙語: 同時支持中文和英文。
高精度(英文): 在公開的英文自然語言榜單 LAMBADA、MMLU 和 Big-bench-lite 上優於 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B。
高精度(中文): 在7個零樣本 CLUE 數據集和5個零樣本 FewCLUE 數據集上明顯優於 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B。
快速推理: 首個實現 INT4 量化的千億模型,支持用一臺 4 卡 3090 或 8 卡 2080Ti 服務器進行快速且基本無損推理。
可復現性: 所有結果(超過 30 個任務)均可通過我們的開源代碼和模型參數復現。
跨平臺: 支持在國產的海光 DCU、華為昇騰 910 和申威處理器及美國的英偉達芯片上進行訓練與推理。
2022年11月,斯坦福大學大模型中心對全球30個主流大模型進行全方位的評測2,GLM-130B 是亞洲唯一入選的大模型。
在與 OpenAI、谷歌大腦、微軟、英偉達、臉書的各大模型對比中,評測報告顯示 GLM-130B 在準確性和惡意性指標上與 GPT-3 175B (davinci) 接近或持平,魯棒性和校準誤差在所有千億規模的基座大模型(作為公平對比,隻對比無指令提示微調模型)中表現不錯(下圖)。
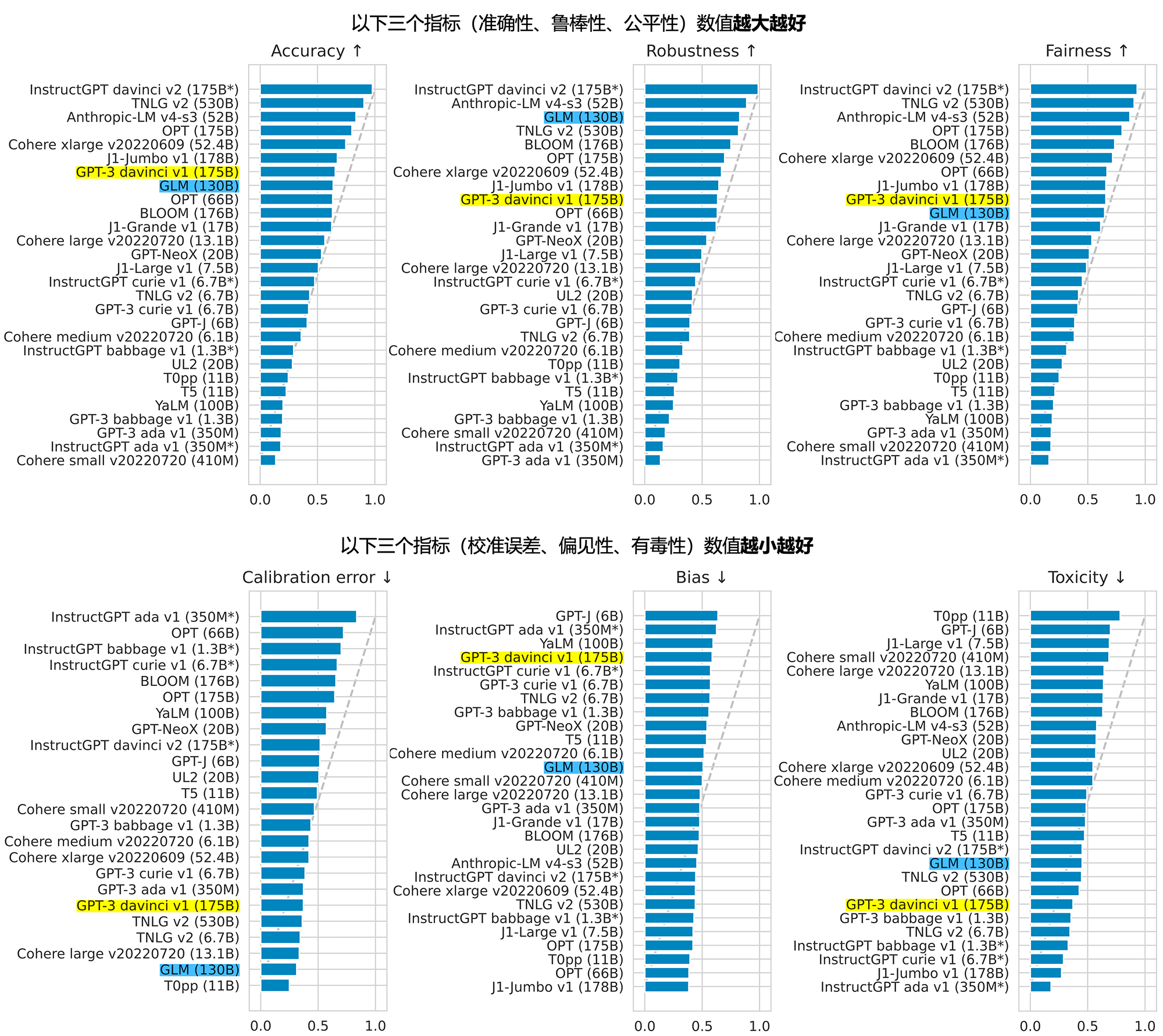
圖1. 斯坦福大學基礎模型中心對全球 30 個大模型的評測結果(2022年11月)