AI行業的“百模大戰”已經打大半年。從上半年的火熱,到下半年的漸冷,勝負難分。GPT成國內廠商的靶子。幾乎每傢在發佈大模型時,都要把GPT拉出來對比一波,而且他們總能找到一個指標把GPT超越——比如,中文能力。測評類的榜單太多。從英文的MMLU,到中文的SuperCLUE,再到借鑒遊戲排位賽機制的ChatbotArena,各種大模型榜單讓人眼花繚亂。很多時候,榜單上的排名成為廠商對外宣傳的工
但奇怪的是,用戶在體驗後發現,號稱超越ChatGPT的一些大模型產品,實際表現不盡如人意。各種不同的統計排名口徑,更是讓人感到迷惑。以至於“第一”太多,榜單都快不夠用。
比如最近,昆侖萬維開源‘天工’系列大模型,號稱多榜超越Llama 2;李開復的零一萬物公司發佈開源大模型“Yi”,“問鼎”全球多項榜單;vivo發佈自研AI“藍心”大模型,是國內“首傢”開源7B大模型的手機廠商。
如此之多的大模型,跑馬圈地這半年,大傢做得怎麼樣?我們又該如何評價孰優孰劣?
“刷榜”,大模型公開的秘密
就像當年手機廠商流行跑分打榜,現在的大模型廠商,也熱衷於沖上各種榜單。
大模型相關的榜單很多,學術圈、產業界、媒體智庫、開源社區,都在今年推出各種各樣的評測榜單。這其中,國內廠商常常引用的是SuperCLUE和C-Eval,這倆都由國人自己推出。
5月6日科大訊飛發佈星火認知大模型,三天後SuperCLUE發佈榜單,星火排在國產第一;6月13日360集團發佈360智腦大模型,六天後SuperCLUE更新榜單,360成第一。
再後來的7月、8月、9月、10月榜單,拿下國產第一的分別是百度、百川智能、商湯、vivo。“登頂”“奪冠”“國內第一”,出現在這些廠商的宣傳中。
有好事者發現,科大訊飛在5月9日“奪冠”時,SuperCLUE官網顯示的顧問成員中,排在最前面的那位,頭銜是哈工大訊飛聯合實驗室(HFL)資深級研究員。發榜第二天,這位專傢的信息被官網刪除。
當時,SuperCLUE隻用幾百道題進行測試,被人質疑不夠客觀。而在國外,早就有一個叫做SuperGLUE的權威榜單,二者名稱相似度極高,讓人傻傻分不清楚。後來,SuperCLUE對測評標準和題目數量進行完善,日漸成為國內知名度較高的測評榜。
大模型測評領域的業內人士趙小躍對‘定焦’說,一些測評機構有題庫,用接入各傢廠商API的方式來測試,但其實測一遍之後,廠商就知道測過什麼題,除非下輪測試換題,否則廠商可以用定向爆破的方式得高分。
在他看來,一套題隻要測過一傢模型,題目就廢,因為模型可以通過API獲取題目,題目的可重復性為零。這是模型評測最有挑戰的一件事情。
C-Eval榜單剛推出時,業內是認可的。它由上海交通大學、清華大學、愛丁堡大學共同完成,有13948道題目。
但很快,大傢就發現,一些原本知名度不高的大模型,突然沖到榜首,甚至把GPT4踩在腳下使勁摩擦。
在9月初的榜單中,雲天勵飛大模型總分排第一,360排第八,GPT4居然排第十。再後來,拿過榜單第一的還有度小滿金融大模型、作業幫銀河大模型,業內公認最強的GPT4被它們無情甩在身後。
成績墊底,到底是GPT錯還是榜錯?
顯然,榜單有問題,因為它遭遇“不健康的刷榜”。
C-Eval團隊在官網發出聲明,承認評測方式有局限性,同時指出刷榜得高分的一些方法,比如:從GPT-4的預測結果蒸餾,找人工標註然後蒸餾,在網上找到原題加入訓練集中微調模型。
這三種方法,前兩種可以視為間接作弊,第三種相當於直接作弊。
大模型從業者李健對‘定焦’說,間接作弊,就是知道考試大概的類型,然後花較多精力把可能的題目都找出來或叫專業的人造出來,答案也給出來,用這樣的數據訓練模型。
他指出,業內現在常用的手段是,讓GPT4來“造答案”,然後得到訓練數據。
李健分析,直接作弊,就是知道考試題目,然後稍微改改,得到新的很多份題目,之後直接拿來訓練模型。
“在清楚榜單任務的情況下,很多類型的任務,很容易刷榜。”他說。
這樣得到的分數是沒有意義的。“直接作弊基本對提升模型的泛化能力(舉一反三)沒用,間接作弊有點像做題傢,對提升學生真實的素質弊大於利。”
為讓“用戶謹慎看待以下榜單”,C-Eval團隊不得不將榜單拆分成兩個,一個是模型已公開的,一個是未公開的。結果,那些得分高的基本全是未公開的大模型。而這些模型的真實表現,人們是無法體驗的。
復旦大學計算機科學技術學院教授邱錫鵬說,C-Eval本身質量還挺高,但被刷榜後導致學術價值不大。現在很多企業去刷榜,但又不公開數據,也不具體說怎麼做,這是一種不公平的競爭。
多位大模型從業者對‘定焦’說,刷榜在大模型行業很常見。
躍盟科技創始人王冉對‘定焦’打一個比方:“先射完箭再畫靶子”。他認為今天的某些測評手段,是有一些大模型公司為表現自己牛而專門設計的。
盛景嘉成董事總經理劉迪認為,有答案或者評分標準,就有人能鉆空子。單靠數據集和問題集的評判方式,很難評出大模型在應用層面的好壞。
“一個丹一個煉法,哪個對癥還得吃下去看。”他對‘定焦’說。
考試拿第一,不是好學生?
大模型評測,作為評估大模型綜合實力的一個手段,還有參考價值嗎?
趙小躍認為,在核心的通用能力上,比如語言理解、邏輯推理等,學術數據集的榜單測評能反映七八成。這其中最大的問題是,開源的榜單結果跟大傢用大語言模型的場景之間有鴻溝。
“測評隻能反映模型某一部分的能力,大傢其實都是從不同的維度盲人摸象,很難知道它的能力邊界在哪裡。”他說。
對於大語言模型,首先在語言上,分為英文和中文兩大語種。國外大模型的訓練語料以英文為主,所以英文很強,但中文不一定比國內大模型強。這也是為什麼國內很多大模型,都在“超越ChatGPT”之前加一個“中文能力”的定語。
其次在考察科目上,評測數據集通常會設置很多個方面,從百科知識到角色扮演,從上下文對話到閑聊。但這些能力隻能單一評價,然後得分加總。
這跟評價一個人很像。任何一道考卷,都隻能測試出這個人某方面的能力。即便是全套試卷的成績,也不等同於這個人的能力。就像ChatGPT的榜單排名不一定能比過國內的一些大模型,但使用體驗上就是更好。
王冉認為,如果將大模型比作一個人的大腦,如何評測一個人的大腦好用,如果隻給他做題,其實是充滿偏見的。“大模型的測評不應該用考試來做,而應該用應用來做。”
人工智能公司開放傳神(OpenCSG)創始人、CEO陳冉認為,通用性的評測,看綜合得分,沒有一個大模型超過GPT4,但是在特定領域,可能有些指標GPT4得分不一定高。
問題在於,有些廠商拿特定領域的得分,去宣傳整體超過GPT4。“這就是以偏概全,我覺得有些廠商在對外宣傳時,還是要對生態公司給到正確的指引,具體哪個指標在哪個領域得分高,要說清楚。”他對‘定焦’表示。
而一旦測評成績進入排名賽,有功利的成分,有些廠商就會有刷榜的動機。“從刷榜的角度,不太能保證中小廠不會把這部分數據拿去訓練,這是大傢對公開數據集最大的顧慮。”趙小躍說。
綜合多位業內人士的觀點,目前國內還沒有一個特別好的數據集,能綜合反映大模型的能力,各方都在探索。
李健在今年做“CLiB中文大模型能力評測榜單”,為避免泄題,他盡量參考業界好的方案,自己出題。“主要是業界和學術界的榜單,不太讓人滿意,公開程度不高,都是各說各話。”
還有一些非商業性質的機構相信,測評榜單最大的意義在於,從模型演化的角度,能夠幫助廠商監控模型生產過程中能力的變化,糾正訓練模型的方法,有針對性提高模型能力。
比如OpenCompass,它是Meta官方推薦的開源大模型評測框架,利用分佈式技術支持上百個數據集的評測,提供大模型評測的所有技術細節,同時給大傢提供統一的測試基準,方便各傢模型在公平公正的情況下開展對比。
開源:先賺吆喝再賺錢
對大模型做出全面評價是困難的。除打榜的方式,有一些廠商通過開源,獲得巨大的關註。
開源是一種經營策略,需要對自傢產品足夠自信。相比之下,敢於放開註冊讓公眾體驗的閉源大模型,要比那些無法體驗的強,開源大模型則又往前邁一步。
第一個被大范圍使用、好評度最高的開源大語言模型,是由Meta在今年2月推出的Llama。當時全球科技公司都盯著OpenAI,試圖追趕閉源的ChatGPT。但開源讓Meta坐上牌桌,吸引大量開發者,一時名聲大噪。
國內公司很快跟上,搶抓第一波關註度。智譜AI、智源研究院、百川智能,是動作最快的三傢。
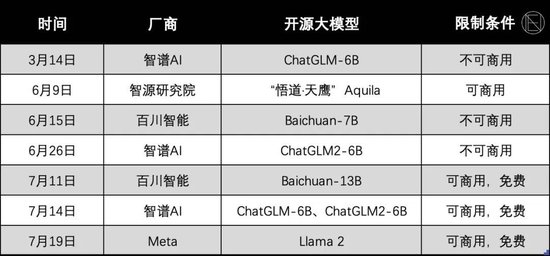
在Llama開源之後,號稱全面對標OpenAI、有著清華背景的智譜AI,迅速在國內第一個開源自己的大模型ChatGLM-6B。這個時間點非常早,當時國內廠商的大模型都還沒發佈,百度文心一言兩天後才推出,而王小川的百川智能公司還沒成立。
三個月後的6月9日,跟智譜AI有著很深淵源的智源研究院,宣佈開源“悟道·天鷹”Aquila。它比智譜AI更進一步——可商用,於是拿下“國內首個開源可商用語言大模型”的頭銜。
是否支持商用,是判斷模型能力的一個關鍵指標。GPT 3.5的水平,通常被認為是大模型商用的標準線。不過,智源是一個非營利機構,它更多的用意是為公用發展提供技術支持。
智源主動開源之後,開源大模型的軍備競賽正式打響。
這其中值得一提的是百川智能。作為一傢今年4月才成立的初創公司,百川獲得的關註度甚至超過很多互聯網大廠。
從時間上來看,百川是智源之後第一傢開源的創業公司,且第一個宣佈可免費商用。它開源不可商用的版本時,比智譜AI早九天;後來開源免費可商用的版本時,又比智譜AI早三天。
時間點很重要。當時Llama1隻被允許用作研究,但市場有傳聞可商用的Llama 2即將開源。百川不僅搶在Llama 2之前,還卡在智譜AI之前宣佈免費可商用,贏得巨大的關註度,一周之內下載量破百萬。
趙小躍認為,百川在那個時間發佈一個開源模型,作為自己的第一槍,是一個很對的決策。“賺一波吆喝。”
支持商用的Llama 2比百川和智譜AI晚一周,即便如此,它還是在全球引發巨震。在同等參數規模下,Llama 2能力超過所有的開源大模型,是目前全球公認的開源大模型的代表。
因為Llama的帶動,國內廠商踩上開源熱潮的風口。它們急著秀肌肉,爭奪大眾註意力。但從技術角度,尚不能說明它們就跑在前面。
有觀點認為,開源模型雖多,但大多數都是從Llama派生出來。簡單來說,就是用Llama作為基模型,然後選用其它不同的訓練方法微調。因為Llama原生在中文方面相對較弱,給國產開源大模型宣傳的發力點。
6月中旬百川開源第一版Baichuan-7B時,公司隻成立剛兩個月。當時有人質疑其模型架構跟Llama很相似。“借助已經開源的技術和方案,百川是站在巨人的肩膀上。”一位大模型創業者評價。
本質上,開源也是一種商業模式。賺完吆喝後,廠商的目的還是賺錢。
陳冉向‘定焦’舉個例子,開源就像一些化妝品品牌推出試用裝,免費給用戶用,但不會透露配方和成分。用戶試用完如果覺得好想繼續用,就得付費買商業版。另外它可能透露配方,如果有廠商想基於這個配方去創造一個新的產品,就需要交授權費。
百川在9月下旬推出兩款閉源大模型,API接口對外開放,進入ToB領域,開啟商業化進程。
“它已經通過開源賺一波吆喝,接下來一定會推閉源大模型做商業化,它最先進的模型是一定不會開源的。”趙小躍說。
大傢都沒有護城河?
“百模大戰”發展到今天,各傢廠商通過各種方式博取關註度,那麼誰做到真正的領先?
趙小躍認為,從主觀感受層面來看,國內的大模型,無論是開源還是閉源,本質上沒有核心的技術代差。因為無論是模型大小,還是數據質量,大傢都沒有飛躍式的突破。“在GPT3.5的指引下,國內廠商隻要模型容量達到一定地步,再配合一批高質量數據,大傢都不會太差。”
但跟GPT4相比,技術代差是存在的。“因為閉源,大傢不知道GPT4背後真正的技術方案是什麼,如何把這麼大的模型用專傢結構訓練出來,目前大傢還都在探索。”
在陳冉看來,國內的大語言模型完全原創的較少,有些是在transformer架構上做一個整體調優,本質是在算子上做調優,而沒有本質上的改變。還有一些走開源路線的廠商,更多是在中文方面深入研究。
大傢都有自己的大模型,但本質上沒有顯著的區別,這就是當前國內大模型行業的特點。
某種程度上,這是由行業階段決定的。國內的互聯網大廠、創業公司、高校科研機構,真正開始投入大量人力物力做大模型,也就在今年。行業的技術路線也還在摸索中,沒有哪傢公司建立起護城河。
相比純技術實力方面的比拼,算力和數據層面的比拼更能出效果。
“大傢更多的精力是花在數據和語料上,誰能花錢獲得高質量的語料,同時有足夠的算力,誰就能訓練出一個相對好一點的模型。”陳冉說。
開源讓局面變得更加不可控。去年底ChatGPT亮相後,全球冒出來上百個大模型,但今年Meta開源Llama 2之後,很多模型還沒有投入市場就已經過時。就連Google的工程師都在內部直言稱,Google和OpenAI都沒有護城河。
大模型更新迭代太快。“今天你推出一個大模型,花錢打榜,有很多人用,可能明天就有個新的模型迅速替代掉。”陳冉說。
多位業內人士對‘定焦’表示,大模型之間真正顯著的區別,會在具體的用戶場景或B端的業務中體現。
“現實世界裡我們評價某個人是專傢,是因為他在特定領域很厲害。大模型也一樣,要在領域裡建立共識,專業性一定要放到具體的場景裡去體現。”王冉說。
核心的通用能力是基礎,廠商會根據自己所在的領域,差異化發展。“比如我們跟醫院和律所接觸,他們其實更關心的是醫療或法律方面的能力。”趙小躍說。
對於互聯網巨頭而言,需要考量的因素相對更多。
除要對外“接單”,巨頭們已經開始在內部進行大模型的應用端部署。比如騰訊的廣告、遊戲、社交、會議等業務,接入混元大模型,百度搜索、文庫、百傢號等產品早已接入文心大模型,阿裡把AI作為各大業務板塊的驅動力。
大模型對巨頭內部的正面影響究竟有多大,會更難量化評估。
綜合來看,國內大模型還處在起跑的混沌階段,一切都在快速變化中。做出一個大模型的技術壁壘不高,但要做好並真的解決問題,還有很長的路要走。
*應受訪者要求,趙小躍為化名。