2026年的數據荒越來越近,矽谷大廠們已經為AI訓練數據搶瘋!它們紛紛豪擲十數億美元,希望把犄角旮旯裡的照片、視頻、聊天記錄都給挖出來。不過,如果有一天AI忽然吐出我們的自拍照或者隱私聊天,該怎麼辦?誰能想到,我們多年前的聊天記錄、社交媒體上的陳年照片,忽然變得價值連城,被大科技公司爭相瘋搶。
現在,矽谷大廠們已經紛紛出動,買下所有能購買版權的互聯網數據,這架勢簡直要搶破頭!
圖像托管網站Photobucket的陳年舊數據,本來已經多年無人問津,但如今,它們正在被各大互聯網公司瘋搶,用來訓練AI模型。
為此,科技巨頭們願意拿出實打實的真金白銀。比如,每張照片價值5美分到1美元,每個視頻價值超過1美元,具體情況去取決於買傢和素材種類。
總之,為購買AI訓練數據,巨頭們已經展開一場地下競賽!
而最近鬧得轟轟烈烈的Meta圖像生成器大翻車事件,更是讓AI的訓練數據“刻板印象”暴露無遺。
如果喂給模型的數據無法改變“偏見”,那各大公司要遭遇的輿論風波,隻怕少不。
Meta的AI生圖工具畫不出來“亞洲男性和白人妻子”或“亞洲女性和白人丈夫”
巨頭狂砸數十億美元,隻為買到數據“黃金”
根據路透社報道,在2000年代,Photobucket處於巔峰期,擁有7000萬用戶。而今天,這傢頂級網站的用戶已經驟降到200萬人。
但生成式AI,給這傢公司帶來新生。
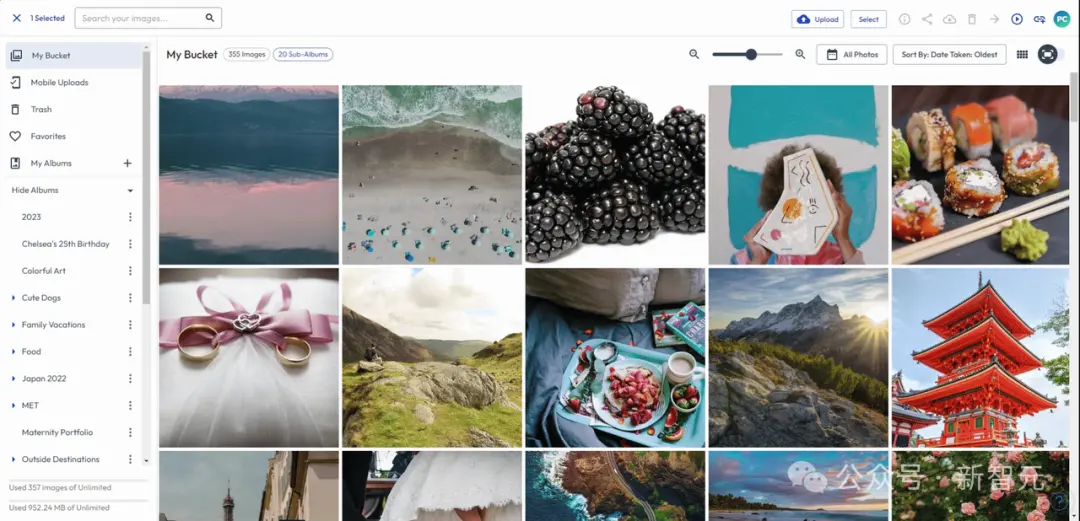
CEO Ted Leonard開心地透露,目前已經有多傢科技公司找上門來,願意重金購買公司的130億份照片和視頻。
目的,當然就是訓練AI。
為得到這些數據,各大公司都非常舍得割肉。
而且,他們還想要更多!據說,一位買傢表示,自己想要超過10億個視頻,而這,已經遠遠超出Photobucket能提供的數量。
據粗略估計,Photobucket手中握著的數據,很可能價值數十億美元。
OpenAI陷起訴風波,版權太敏感
現在眼看著,大傢的數據都不夠用。
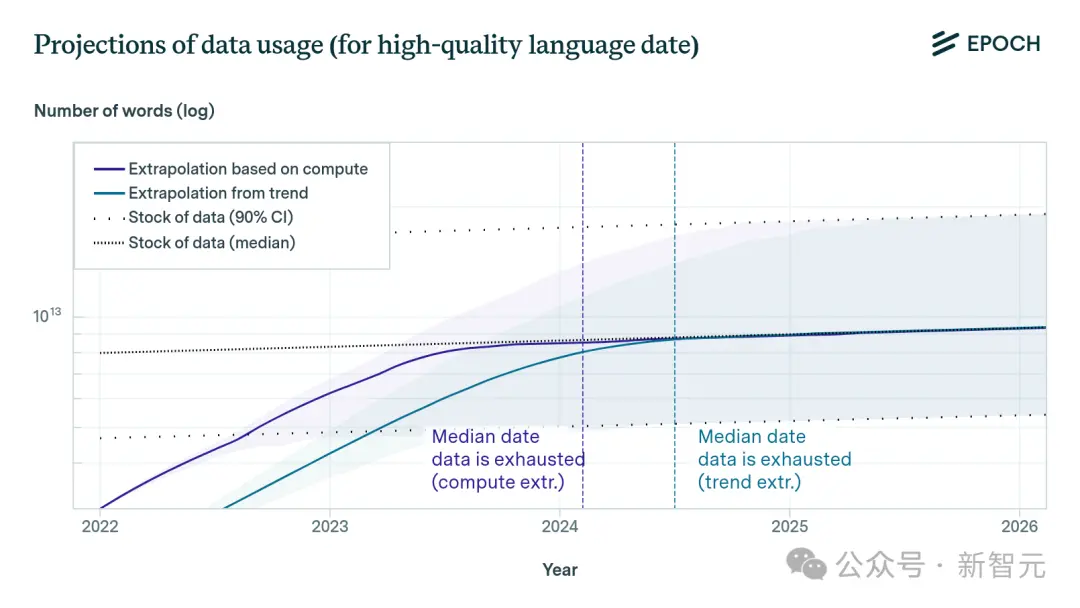
根據Epoch研究所的分析,到2026年,科技公司很可能會耗盡互聯網上所有的高質量數據,因為他們消耗數據的速度,遠遠超過數據的生成速度!
訓練ChatGPT的數據,是從互聯網上免費抓取的。
Sora的訓練數據來源不詳,CTO Murati接受采訪時支支吾吾的表現,險些又讓OpenAI大翻車。
雖然OpenAI表示,自己的做法完全合法,但前方還有一堆版權訴訟在等著他們。
而其他大科技公司都跟著學乖,大傢都在悄悄地為付費墻和登錄屏幕背後的鎖定內容付費。
如今,無論是陳舊的聊天記錄,還是被遺忘的社交媒體上褪色的舊照片,忽然都變成價值連城的東西。
而各大公司已經紛紛出動,急於尋找版權所有者的授權。畢竟,私人收藏的東西,是無法抓取的。
外媒記者走訪30多名專業人士,發現這背後隱藏的,是一個黃金市場。
雖然很多公司對於這個不透明的AI市場規模表示緘默,但Business Research Insights等研究人員認為,目前市場規模約為25億美元,並預測十年內可能會增長近300億美元。
生成數據淘金熱,讓數據商樂開花
對科技公司來說,如果不能使用免費抓取的網頁數據檔案,比如Common Crawl,那成本會是一個很可怕的數字。
但是一連串版權訴訟和監管熱潮,已經讓他們別無選擇。
甚至,矽谷已經出現一個新興的行業——數據經紀人。
而圖片、視頻供應商們,也隨之賺得盆滿缽滿。
手快的公司,早就反應過來。ChatGPT在2022年底亮相的幾個月內,Meta、Google、亞馬遜和蘋果就已經迅速和圖片庫提供商Shutterstock達成協議,使用庫中的數億份圖像、視頻和音樂文件進行訓練。

根據首席財務官透露的數據,這些交易從2500萬美元到5000萬美元不等。
而Shutterstock的競爭對手Freepik,也已經有兩位大買傢,2億張圖片檔案中的大部分,會以2至4美分的價格授權。
OpenAI當然也不會落後,它不僅是Shutterstock的早期客戶,還與包括美聯社在內的至少四傢新聞機構簽署許可協議。
讓內容“合乎道德”
同時興起的,還有AI數據定制行業。
這批公司獲得與播客、短視頻和與數字助理互動等現實世界內容的授權,同時還建立短期合同工網絡,從頭開始定制視覺效果和語音樣本。
作為代表之一的Defined.ai,已經把自己的內容賣給Google、Meta、蘋果、亞馬遜、微軟等多傢科技大廠。
其中,一張圖片賣1到2美元,一部短視頻賣2到4美元,一部長片每小時可以賣到100到300美元,文本的市價則是每字0.001美元。
而比較麻煩的裸體圖像,售價為5到7美元,因為還需要後期處理。
而這些照片、播客和醫療數據的所有者,也會獲得總交易額20%至30%的費用。
一位巴西數據商表示,為獲得犯罪現場、沖突暴力和手術的圖像,他需要從警察、自由攝影記者和醫學生手裡去買。
他補充說,他的公司雇用習慣於看到暴力傷害的護士來脫敏和標註這些圖像,這對未經訓練的眼睛來說是令人不安的。
而將圖像脫敏、標註的工作,則交給慣於看到暴力傷害的護士,畢竟未經訓練的人眼看到這些圖像,會很不安。
然而,這些AI模型的“燃料”,很可能會引發嚴重的問題,比如——吐出用戶隱私。
專傢發現,AI會反芻訓練數據,比如,它們會吐出Getty Images水印,逐字輸出紐約時報文章的段落,甚至再現真人圖像。

Getty Images指責Stability AI“以驚人的規模肆無忌憚地侵犯它的知識產權”
也就是說,幾十年前某人發佈的私人照片或私密想法,很可能在不知情的情況下,被AI模型原樣吐出來!
這次“ChatGPT在回復中泄露陌生男子自拍照事件”,讓大傢頗為恐慌
這些隱患,目前還沒有有效方法解決。
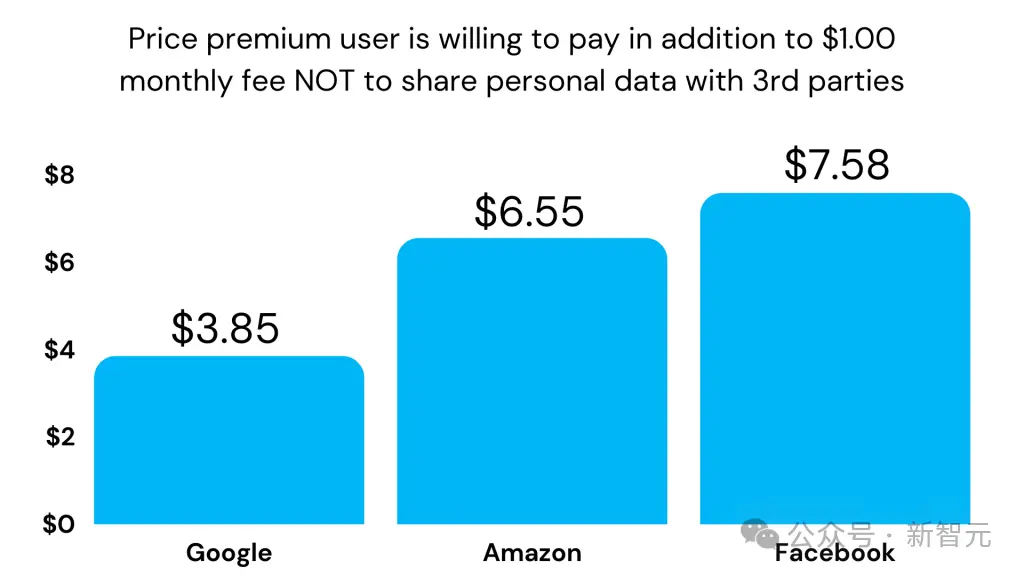
調查顯示,用戶願意每月多付1美元,讓自己的個人數據不被第三方使用
Altman,也看上合成數據
另外,Sam Altman也早看到合成數據的未來。
這些數據不是人類直接創造的,而是由AI模型生成的文本、圖像和代碼,也就是說,這些系統通過學習自己產生的內容來進步。

既然AI能創造出接近人類的文本,當然也就能自產自銷,幫自己進化成更先進的版本。
隻要我們能夠跨過合成數據的關鍵閾值,即讓模型能夠自主創造出高質量的合成數據,那麼一切問題都將迎刃而解。
——Sam Altman
不過,這件事真的這麼容易嗎?
人工智能研究者們已經研究合成數據多年,但要構建一個能自我訓練的人工智能系統並非易事。

專傢發現,模型如果隻依賴於自我生成的數據,可能會不斷重復自己的錯誤和局限,陷入一個自我加強的循環中。
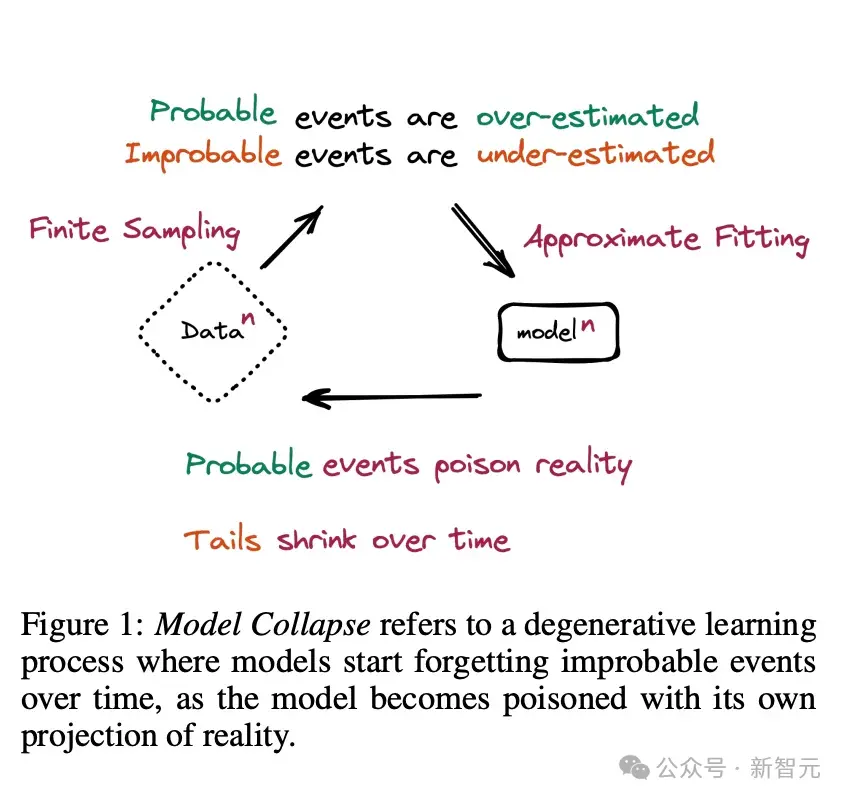
這些系統所需的數據,就像是在叢林中尋找一條路徑,如果它們僅僅依賴於合成數據,就可能在叢林裡迷路。
——前OpenAI研究員、現任不列顛哥倫比亞大學計算機科學教授Jeff Clune
對此,OpenAI正在探索如何讓兩個不同的人工智能模型協作,共同生成更高質量、更可靠的合成數據。其中一個負責生成數據,另一個則負責評估。
這種方法是否有效,還未可知。
“規模”Is All You Need
數據為什麼對AI模型這麼重要?這要從下面這篇論文說起。
2020年1月,約翰斯·霍普金斯大學的理論物理學傢Jared Kaplan與9位OpenAI研究人員共同發表一篇具有裡程碑意義的人工智能論文。
他們得出一個明確的結論:訓練大語言模型所用的數據越多,其性能就越好。
正如一個學生通過閱讀更多書籍能學到更多知識一樣,大語言模型能通過更多的信息更精確地識別文本模式。
很快,“隻要規模足夠大,一切就皆有可能”便成為AI領域的共識。

論文地址:https://arxiv.org/abs/2001.08361
2020年11月,OpenAI推出的GPT-3,便利用當時最為龐大的數據進行訓練——約3000億個token。
在吸收這些數據後,GPT-3展現出驚人的文本生成能力——它不僅可以撰寫博客文章、詩歌,甚至還能編寫自己的計算機程序。
但如今看來,這個數據集的規模就顯得相當小。
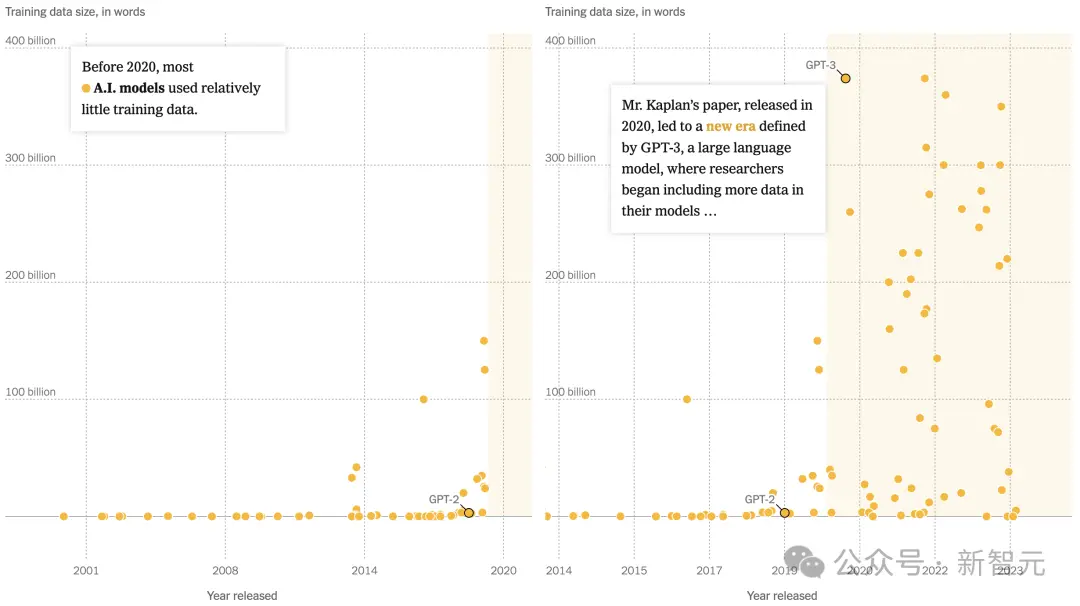
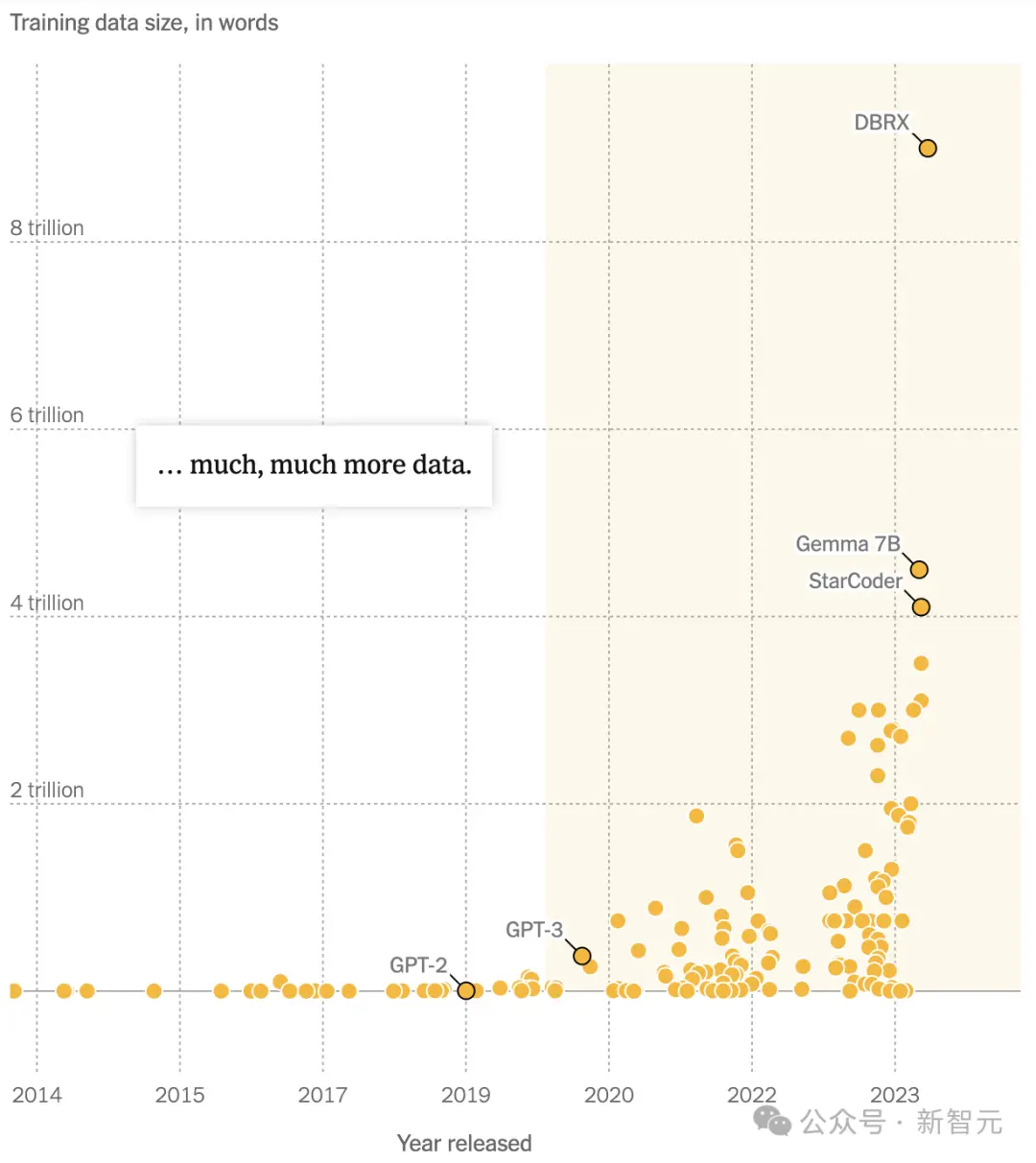
到2022年,DeepMind將訓練數據直接拉到1.4萬億個token,比Kaplan博士在論文中預測的還要多。
然而,這一記錄並未保持太久。
2023年,Google發佈的PaLM 2,在訓練token上更是達到3.6萬億——幾乎是牛津大學博德利圖書館自1602年以來收集手稿數量的兩倍。
為訓GPT-4,OpenAI白嫖100萬+小時YouTube視頻
但正如OpenAI的CEO Sam Altman所說,AI終究會消耗完互聯網上所有可用的數據資源。
這不是預言,也不是危言聳聽——因為Altman本人就曾親眼目睹過它的發生。
在OpenAI,研究團隊多年來一直在收集、清理數據,並將其匯集成巨大的文本庫,用以訓練公司的語言模型。
他們從GitHub這個計算機代碼庫中提取信息,收集國際象棋走法的數據庫,並利用Quizlet網站上關於高中考試和作業的數據。
然而,到2021年底,這些數據資源已經耗盡。
為下一代AI模型的開發,總裁Brockman決定親自披掛上陣。
在他的帶領下,團隊開發出一款全新名的語音識別工具Whisper,可以快速準確地轉錄播客、有聲讀物和視頻。
有Whisper之後,OpenAI很快便轉錄超過100萬小時的YouTube視頻,而Brockman更是親自參與到收集工作當中。
最終的故事大傢都知道,在如此高質量數據的加持下,地表最強的GPT-4橫空出世。
Google:我也一樣
有趣的是,Google其實早就知道OpenAI在利用YouTube視頻收集數據,但從未想過要出面阻止。
你猜的沒錯,Google也在利用YouTube視頻來訓練自傢的AI模型。
而如果要對OpenAI的行為大加指責,他們不僅會暴露自己,甚至還會引發公眾更加強烈的反應。
不僅如此,那些儲存在Google Docs、Google Sheets等應用裡的數十億文字數據,也是Google的目標。

2023年6月,Google的法律部門要求隱私團隊修改服務條款,從而擴展公司對消費者數據的使用權限。
也就是,為公司能夠利用用戶公開分享的內容開發一系列的AI產品,鋪平道路。
據員工透露,他們被明確指示要在7月發佈新的條款,因為那時大傢的註意力都在即將到來的假期上。

7月1日發佈的新條款不僅允許Google使用這些數據開發語言模型,還能用於創建像Google Translate、Bard和Cloud AI等廣泛的AI技術和產品
Meta數據不足,高管被迫天天開會
同樣在追趕OpenAI的,還有Meta。
為能夠超越ChatGPT,小紮不分晝夜地催促公司的高管和工程師加快開發一個能與之競爭的聊天機器人。
然而,到去年年初,Meta也遇到和其他競爭者一樣的難題——數據不足。
盡管Meta掌管著龐大的社交網絡資源,但不僅用戶沒有保留帖子的習慣(很多人會刪除自己之前的發佈),而且Facebook畢竟也不是一個大傢習慣發高質量長文的地方。
此前,小紮曾自豪聲稱Meta Platforms的訪問數據,是Meta AI的一大優勢
生成式AI副總裁Ahmad Al-Dahle向高層透露,為開發出一個模型,他的團隊幾乎利用網絡上所有可找到的英文書籍、論文、詩歌和新聞文章。
但這些還遠遠不夠。
2023年3月到4月,公司的商務發展負責人、工程師和律師幾乎每天都在密集會議,試圖找到解決方案。
他們考慮為獲取新書的完整版權支付每本10美元的可能性,並討論收購出版斯蒂芬·金等作者作品的Simon & Schuster的想法。
與此同時,他們還討論未經允許就對網絡上的書籍、論文等作品進行摘要的做法,並考慮進一步“吸收”更多內容,哪怕這可能招致法律訴訟。

好在,作為行業標桿的OpenAI,就在未經授權的情況下使用版權材料,而Meta或許可以參考這一“市場先例”。
根據錄音,Meta的高管們決定借鑒2015年作傢協會(Authors Guild)對Google的法庭判決。
在那個案例中,Google被允許掃描、數字化並在在線數據庫中編目書籍,因為它僅在線上復制作品的一小部分,並且改變原作,這被認定為合理使用。
在會議中,Meta的律師們表示,用數據訓練人工智能系統應當同樣被視為合理使用。
但即便如此,Meta似乎還是沒攢夠數據……
AI生圖工具拒絕“白人和亞洲人”合影
最近,外媒The Verge的記者在多次嘗試後發現,Meta的AI圖像生成工具並不能創建一張東亞男性和白人女性同框的圖片。
不管prompt是“亞洲男性與白人朋友”、“亞洲男性與白人妻子”、“亞洲女性與白人丈夫”,還是經過魔改的“一位亞洲男性和一位白人女性帶著狗微笑”,都於事無補。
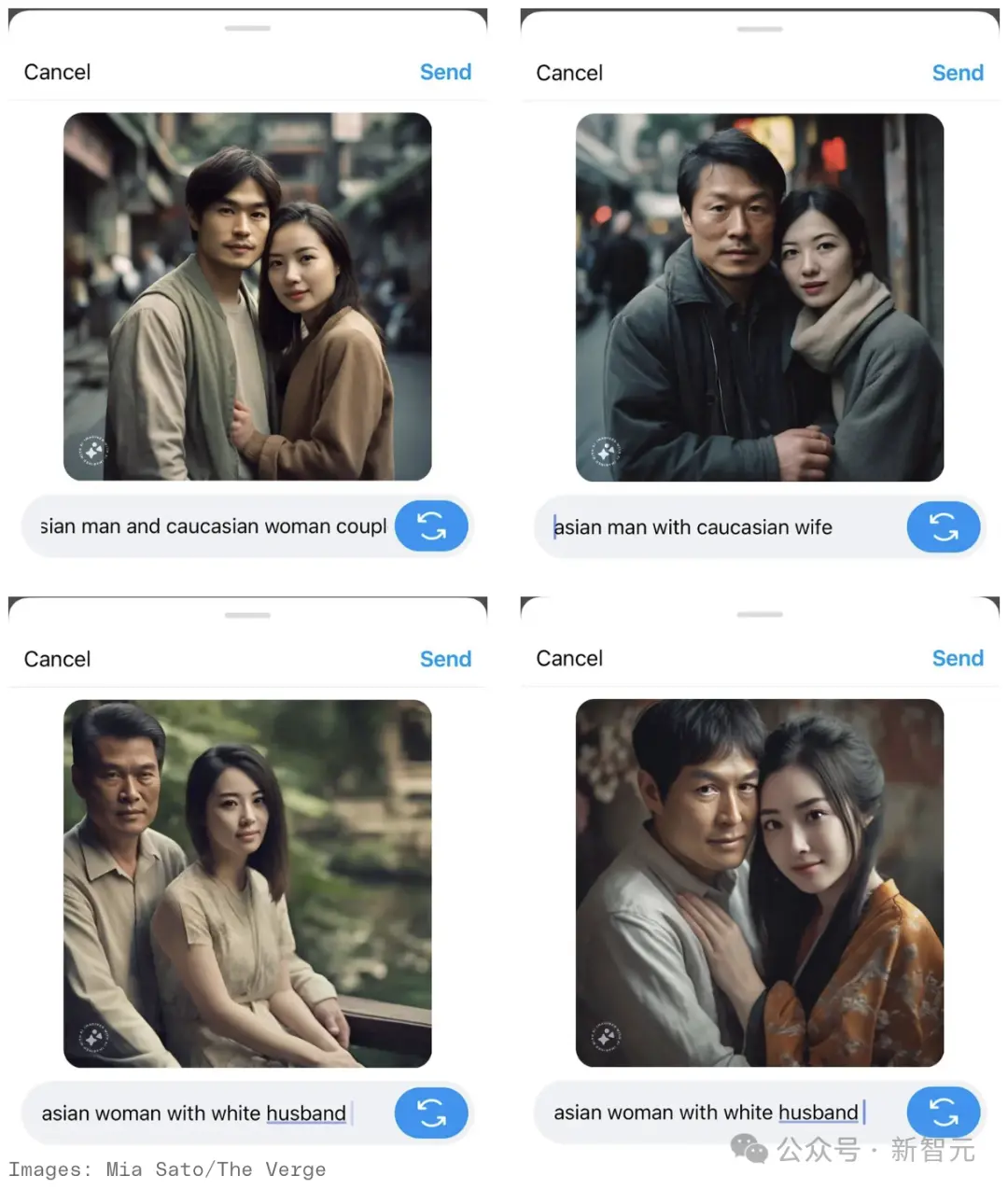
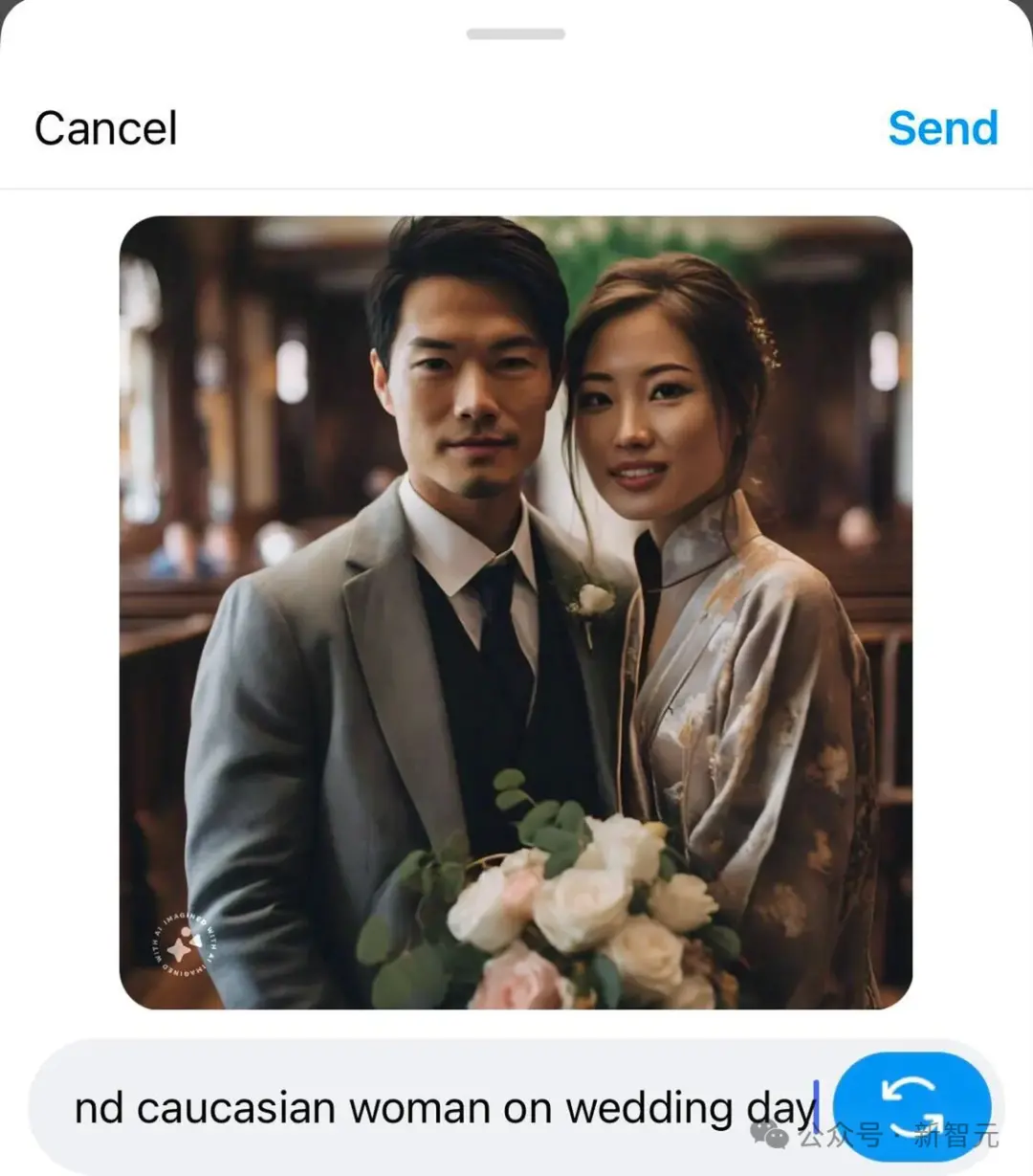
當他將“白人”改為“高加索人”時,結果依舊如此。
比如“亞洲男性和高加索女性的婚禮日”這個prompt,得到的卻是一張身穿西裝的亞洲男性與身著旗袍/和服混搭的亞洲女性的圖像……
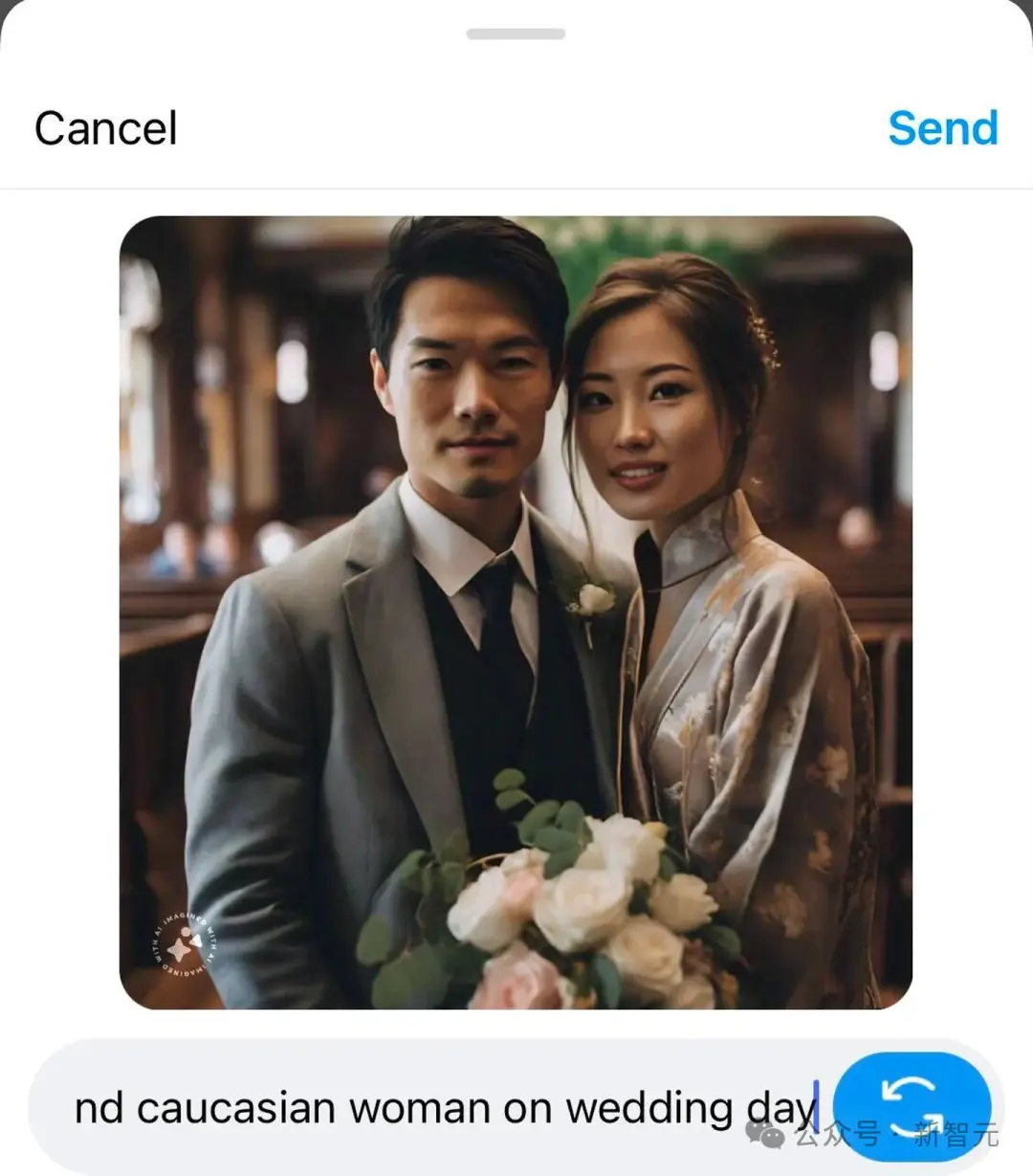
AI居然難以想象亞洲人與白人並肩而立的場景,這著實有些匪夷所思。
而且,在生成的內容中,還隱藏著更加微妙的偏見。
舉個例子,Meta總是將“亞洲女性”描繪成東亞面孔,似乎忽略印度作為世界上人口最多國傢的事實。與此同時,“亞洲男性”多為年長者,而亞洲女性卻總是年輕化。
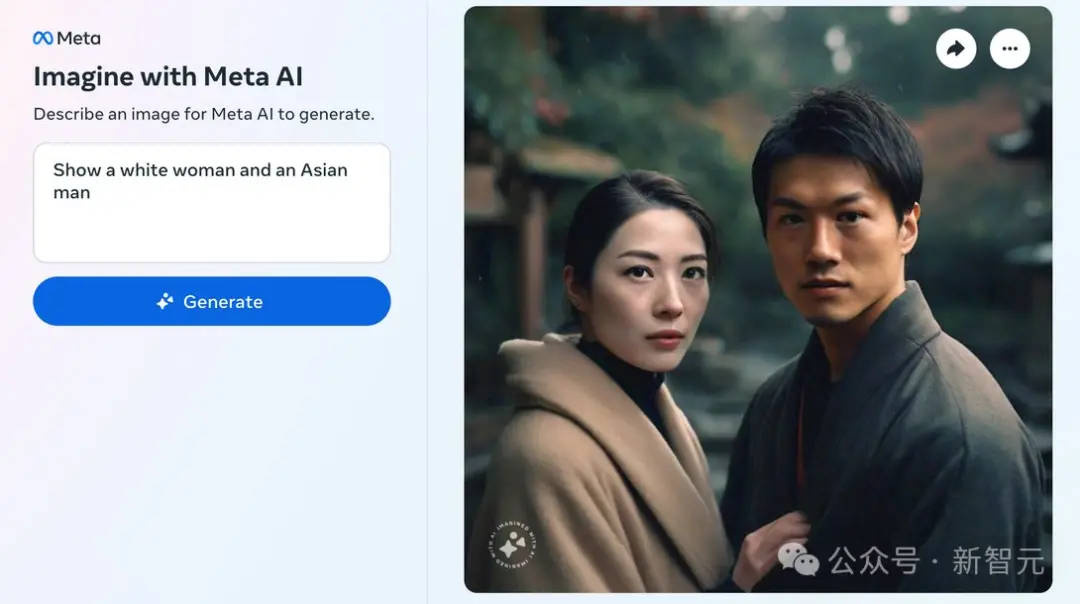
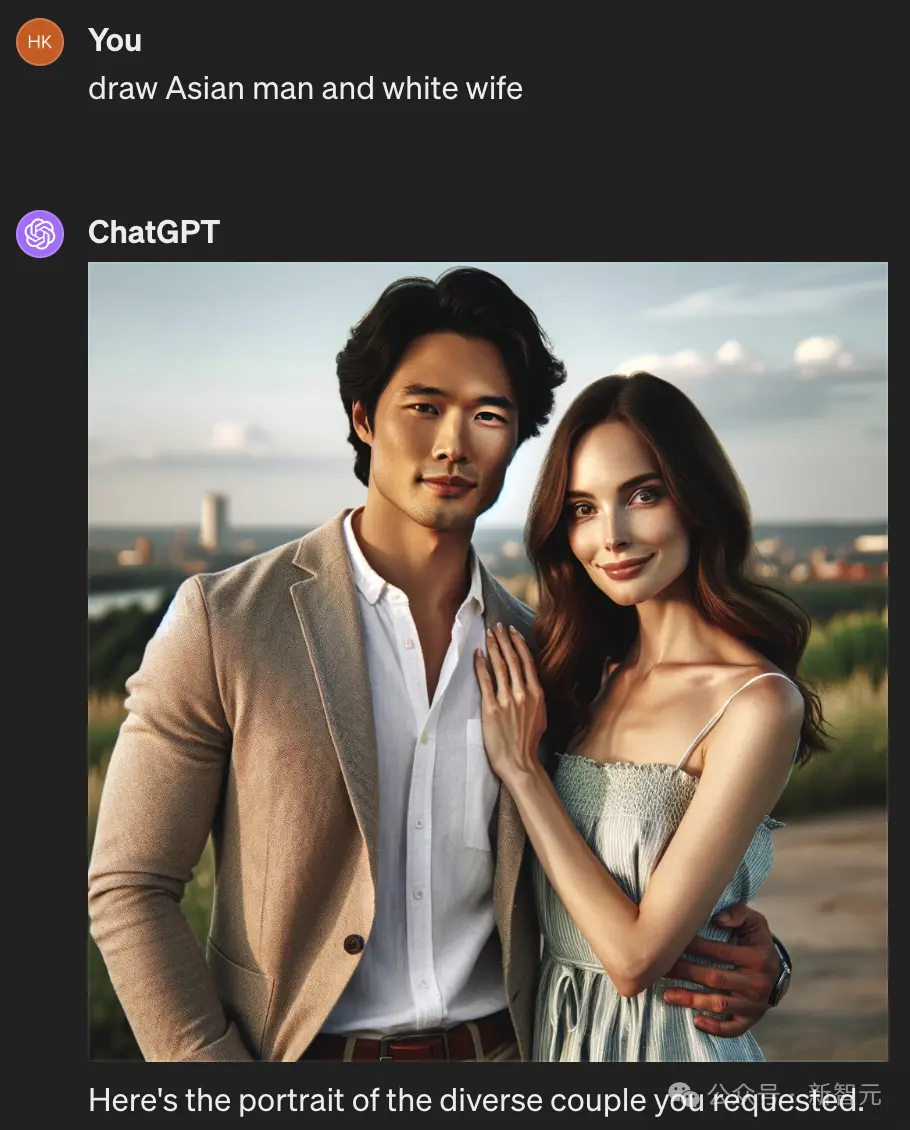
相比之下,OpenAI加持的DALL-E 3,就完全沒有這個問題。
對此,有網友指出,出現這個問題的原因是Meta在模型訓練時沒有輸入足夠多的場景示例。
簡而言之,問題不在於代碼本身,而在於模型訓練時所使用的數據集不夠豐富,沒有充分覆蓋所有可能的場景。

但更深層次的是,AI的行為是其創造者偏見的體現。
在美國媒體中,“亞洲人”通常就是指東亞人,不符合這一單一形象的亞洲人幾乎從文化意識中被抹去,即便是符合的人也在主流媒體中被邊緣化。
而這,隻是因數據造成的AI偏見的一隅而已。