2023年年中以來,生成式人工智能浪潮疊加產業周期變化,半導體細分產品紛紛打起“翻身仗”。受算力驅動,HBM存儲器優勢凸顯,在AI時代迅速擊落GDDR、LPDDR在內的競爭對手,價格狂飆、需求暴增:美光CEOSanjayMehrotra在2023年年底的財報會議上透露,其2024年的HBM產能預計已全部售罄;SK海力士副總裁KimKi-tae表示,雖然2024年剛開始,但旗下的HBM已全部售罄。
當存儲三巨頭(SK海力士、三星、美光科技)圍繞HBM進行升級、擴產的那一刻,意味著蟄伏十年之久、發展至第六代的HBM終於甩去“成本高昂”的束縛,以強悍性能步入存儲市場,攪動風雲:SK海力士市值突破千億美元、臺積電CoWoS先進封裝產能告急、DRAM投片量面臨擠壓……
但必須警惕的是,若隻將HBM視作存儲領域的一項新興技術而在戰術上亦步亦趨,若隻瞄準ChatGPT、Sora等生成式人工智能而忽視背後痛點,是要犯戰略錯誤的。我國半導體從業者需清晰認識到,倘若HBM在內的存儲領域受到長期遏制,我國相關產業發展將繼先進制程、GPU後,再失先手。正如電子科技大學長三角研究院(湖州)集成電路與系統研究中心副主任黃樂天所說:“就好像一把槍,子彈供應跟不上,射速再快也沒用。無法解決HBM問題,我國算力就難以提升,人工智能在內的諸多產業發展就將受限。”
HBM,一場無聲的暗戰。
“帶寬之王”狂飆,HBM無敵手
狂飆的HBM究竟有何魔力?HBM(High Bandwidth Memory ,高頻寬存儲器)屬於DRAM(動態隨機存取存儲器)中的一個類別,具有高帶寬、大容量、低延遲的DDR DRAM組合陣列。
AI時代,算力可以輕松破T(TOPS,每秒萬億次運算),但存儲器帶寬破T(TB/s,每秒萬億字節帶寬)則異常艱難。在需要高算力又需要大數據的應用場景下,存儲數據吞吐能力的不足被無限放大,出現所謂的“存儲墻”。
圖源:Rambus
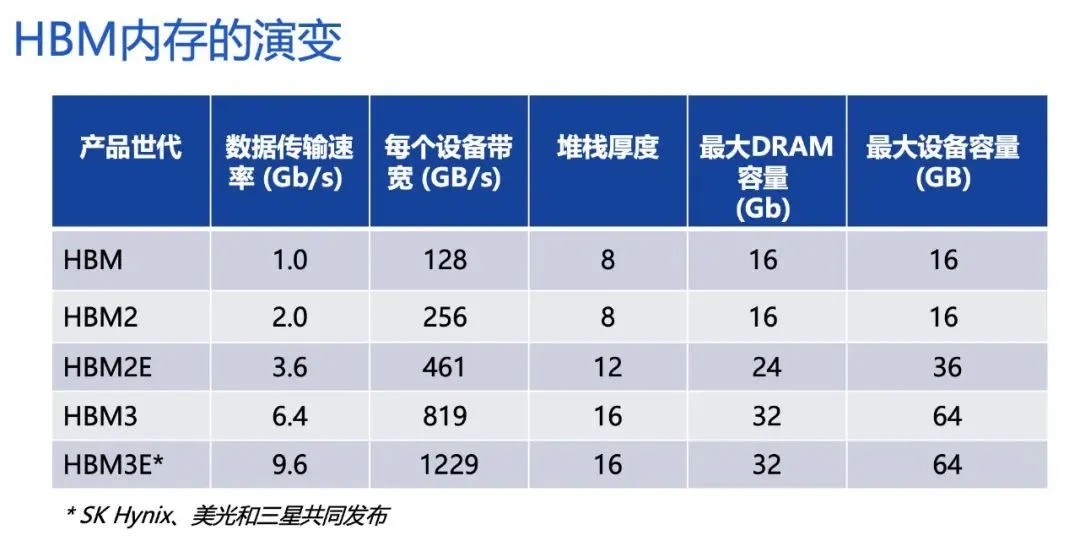
想要增加帶寬,最簡單粗暴的方法是增加數據傳輸線路的數量。當前,HBM由多達1024個數據引腳組成,其內部數據傳輸路徑隨著每代產品的發展而顯著增長——以SK海力士推出的HBM3E為例,其作為HBM3的擴展(Extended)版本,最高每秒可以處理1.15TB數據;三星的HBM3E“Shinebolt”經初步測試,最大數據傳輸速度預計達1.228TB/s。鑒於如此強大的帶寬性能,市面上大部分存儲器產品都難以在該領域擊敗HBM,唯一的勝出者隻能是下一代HBM。
HBM技術自2013年在半導體市場嶄露頭角以來,已擴展至第一代(HBM)、第二代(HBM2)、第三代(HBM2E),目前正步入第四代(HBM3)、第五代(HBM3E),而第六代(HBM4)也已蓄勢待發。
業內判斷,HBM作為今後AI時代的必備材料,雖然在內存市場中比例還不大,但盈利能力是其他DRAM的5~10倍。日前,市場調研機構Yole Group發佈的數據進一步印證這一點。Yole預計,今年HBM芯片平均售價是傳統DRAM內存芯片的5倍。而考慮到擴產難度,HBM價格預計在相當長一段時間內將保持高位。
鑒於HBM目前無可撼動的市場地位,以及緊張的產能和昂貴的價格,業界是否可以通過犧牲某項性能而另尋方案,譬如使用潛在替代者GDDR、LPDDR?事實上,英偉達較早期的GTX 1080、GTX 2080Ti、GTX 3090也的確采用GDDR技術。
一位國內芯片企業負責人接受集微網采訪時指出,HBM緊缺的產能令其價格一直維持在高位,但隨著大模型訓練成熟,逐漸進入大規模推理部署階段,將不得不面對性價比的問題。推理場景中,算力成本至關重要,事實上目前各個大模型廠商也均在探索更高性價比的推理方案。譬如使用GDDR或LPDDR等方案獲得更高的性價比,英偉達及國內廠傢的推理板卡也不同程度上使用GDDR方案作為替代。
“GDDR本身存在顆粒容量不足的顧慮,在模型參數規模日漸增長的趨勢下,如果單卡或者單節點無法提供足夠的顯存容量,反而會降低單卡的計算效率。但隨著GDDR7(其更加兼顧AI場景對帶寬和顆粒容量密度的需求)逐步商業化,預計HBM價格也將伴隨產能釋放而逐步下降,未來在過渡期內還將是多方案共存的狀態。”該人士表示。
HBM走俏,CoWoS吃緊
HBM的大火正快速推高市場規模以及預期。市場調查機構Gartner預測,2022~2027年,全球HBM市場規模將從11億美元增至52億美元,復合年均增長率(CAGR)為36.3%。高盛甚至給出翻倍的預期,預計市場規模將在2022年(23億美元)到2026年(230億美元)前增長10倍(CAGR77%)。
在催動先進封裝的同時,HBM的產能卻顯得捉襟見肘。
具體地看,HBM由多個DRAM堆疊而成,利用TSV(矽通孔)和微凸塊(Microbump)將裸片相連接,多層DRAMdie再與最下層的Basedie連接,然後通過凸塊(Bump)與矽中階層(interposer)互聯。HBM與GPU、CPU或ASIC共同鋪設在矽中階層上,再通過CoWoS等2.5D封裝工藝相互連接,矽中介層通過CuBump連接至封裝基板上,最後封裝基板再通過錫球與下方PCB基板相連。
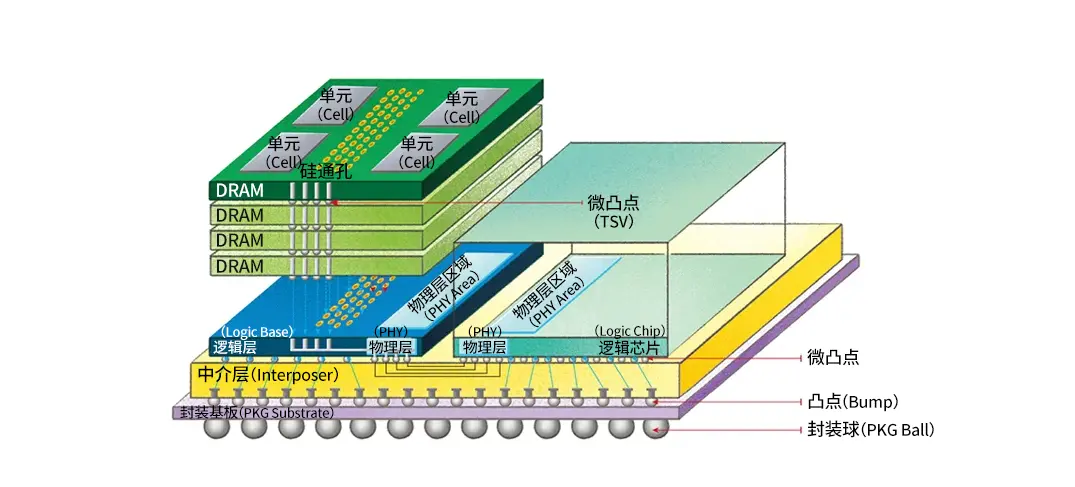
圖片:使用HBM的2.5D封裝
由此,臺積電的CoWoS技術成為目前HBM與CPU/GPU處理器集成的理想方案。HBM高焊盤數和短跡線長度要求需要2.5D先進封裝技術,目前幾乎所有的HBM系統都封裝在CoWoS上,而高端AI服務器也基本使用HBM。這樣看起來,幾乎所有領先的數據中心GPU都是臺積電封裝在CoWos上的。黃仁勛在NVIDIA GTC 2024大會期間更是直白喊話,英偉達今年對CoWos的需求非常大。
產業人士指出,CoWoS封裝所需中介層材料,因高精度設備不足和關鍵制程復雜,中介層材料供不應求,牽動CoWoS封裝排程及AI芯片出貨。
2022年以來,ChatGPT為代表的人工智能帶動AI芯片搶購潮,英偉達、AMD為代表的國際大廠紛紛下單,並均采用臺積電CoWoS先進封裝。大廠“分食”之下,CoWoS產能吃緊。
臺積電總裁魏哲傢在1月的法說會上稱,計劃今年將CoWoS先進封裝產能增加一倍,並計劃在2024年進一步擴充。相關數據顯示,去年12月臺積電CoWoS月產能已經增至1.4萬~1.5萬片,預估到今年第四季度,CoWoS月產能將大幅擴充至3.3萬~3.5萬片,這與魏哲傢“產能增加一倍”的說法基本吻合。而最新消息,臺積電將在嘉義科學園區設兩座CoWoS先進封裝廠,首廠預計5月動工,2028年量產。
良率低、散熱難,HBM“妥協”
市場調研機構集邦預估,2024年底HBM產值占整體DRAM比重有望攀至20.1%的水平。集邦科技資深研究副總經理吳雅婷表示,在相同制程及容量下,HBM顆粒尺寸較DDR5大35%~45%;良率(包含TSV封裝良率),則比起DDR5低約20%~30%;生產周期(包含TSV)較DDR5多1.5~2個月不等。
HBM在市場上“攻城略地”的同時,也面臨良率低、散熱難等方面問題。
首先是低良率遏制產能。HBM制造過程中,垂直堆疊多個DRAM,並通過 TSV將它們連接起來,由高層向下打孔,通過整個矽片做信號通道;一般技術是信號引腳從側面左右兩邊拉下來,而HBM是從中間直接打孔,在極小的裸片上打1000多個孔,並涉及多層;封裝過程中,由於線路多且距離近,封裝時的幹擾、散熱等問題均有可能影響線路。這意味著,上述任何階段的失敗都可能導致一枚芯片的廢棄。此前有傳聞稱三星HBM3芯片生產良率僅10%~20%,三星予以堅決反駁,稱“這不是真的”。
其次是散熱之困。“85℃左右它開始忘記東西,125℃左右則完全心不在焉,”這是業界對DRAM在熱量面前尷尬表現的調侃。黃樂天認為,這種說法並不是很客觀。存儲器相對於處理器等邏輯電路,無論從峰值功耗還是功率密度而言都不算高,之所以存在散熱問題,是由於3D-IC堆疊造成的。無論是哪種芯片,隻要使用3D堆疊的方式就不可避免有熱量聚集,如同多條電熱毯堆在一起,熱量自然無法散發。
“事實上,散熱問題是影響3DIC商用化的主要問題。3DIC早在20年前就被提出,但由於解決不好散熱,隻能在某些可以不計成本加入微流道能強力散熱機制的場景中應用。HBM可視作在2D和3D之間尋求妥協,采用存儲器件3D、邏輯器件2D的方式,盡量避免熱量集中。”黃樂天告訴集微網。
存儲大廠起幹戈,走向技術分野
2013年,SK海力士與AMD合作開發世界上的首個HBM,率先“揮師入關”。有數據顯示,2023年SK海力士市占率預計為53%,三星市占率38%、美光科技市占率9%——令人不禁感慨,AI的風口還是吹到韓國。
進入HBM3E時代後,盡管有市場份額的差別,但三大存儲廠鼎足而立的格局並未打破,SK海力士、三星和美光科技的技術路線也不盡相同。

圖源:SK中國
2023年8月,SK海力士宣佈開發HBM3E。僅7個月後,SK海力士即宣佈率先成功量產HBM3E,並將在3月末開始向客戶供貨。其表示,該產品在速度方面,最高每秒可以處理1.18TB(太字節)的數據,其相當於在1秒內可處理230部全高清(FHD)級電影。
據悉,SK海力士在新產品上采用Advanced MR-MUF最新技術,散熱性能與前一代相比提升10%。(MR-MUF:將半導體芯片堆疊後,為保護芯片和芯片之間的電路,在其空間中註入液體形態的保護材料,並進行固化的封裝工藝技術。與每堆疊一個芯片時鋪上薄膜型材料的方式相較,工藝效率更高,散熱方面也更加有效。)

圖源:三星
2月27日,三星電子宣佈成功發佈其首款12層堆疊HBM3E DRAM——HBM3E 12H,這是其目前為止容量最大的HBM產品。從性能指標上看,HBM3E 12H支持全天候最高帶寬達1280GB/s(約1.25TB/s),產品容量也達到36GB。相比三星8層堆疊的HBM3 8H,HBM3E 12H在帶寬和容量上大幅提升超50%。
公開資料顯示,HBM3E 12H采用先進的熱壓非導電薄膜(TC NCF)技術,使得12層和8層堆疊產品的高度保持一致。三星一直在努力降低其非導電薄膜(NCF)材料的厚度,並實現芯片間的間隙最小化至7微米(µm),同時消除層與層之間的空隙。值得一提的是,三星非導電薄膜技術曾引起外界爭議,認為這是導致其良率不高的主要原因。

圖源:美光科技
美光科技作為HBM領域“後來者”,已於3月宣佈開始量產其HBM3E高帶寬內存解決方案。英偉達 H200 Tensor Core GPU 將采用其8層堆疊的24GB容量HBM3E內存,並在第二季度開始出貨。其HBM3E 引腳速率超9.2Gb/s,提供超1.2TB/s 的內存帶寬。
技術路徑上,美光科技利用其1β(1-beta)技術、先進的矽通孔(TSV)和其他實現差異化封裝解決方案的創新技術開發出業界領先的 HBM3E 設計。
存儲三大廠廝殺激烈、各祭法寶的另一面,是國內存儲行業在企業體量、技術實力等方面均有不足,圍繞HBM研發工作較為困難的現實,但諸多信號顯示它們並未將該市場拱手相讓。日前,武漢新芯發佈《高帶寬存儲芯粒先進封裝技術研發和產線建設》招標項目,這一舉動顯示其對HBM市場的看重。
黃樂天認為,HBM技術的攻克盡管困難,但依然要著手準備。中美芯片競爭經歷數個回合的拉扯,已經發生根本性變化,相較於數年前的亂打一氣,美國對我國芯片產業正形成定點遏制的傾向。其遏制的焦點在於阻止我國高端芯片尤其是大算力芯片的研制和生產,通過阻止我國算力提升來拖慢人工智能等數字產業的發展,存儲帶寬受限將直接阻礙芯片乃至整個計算系統算力提升。