英偉達的節奏,越來越可怕。就在剛剛,老黃又一次在深夜炸場——發佈目前世界最強的AI芯片H200!較前任霸主H100,H200的性能直接提升60%到90%。不僅如此,這兩款芯片還是互相兼容的。這意味著,使用H100訓練/推理模型的企業,可以無縫更換成最新的H200。

全世界的AI公司都陷入算力荒,英偉達的GPU已經千金難求。英偉達此前也表示,兩年一發佈的架構節奏將轉變為一年一發佈。
就在英偉達宣佈這一消息之際,AI公司們正為尋找更多H100而焦頭爛額。
英偉達的高端芯片價值連城,已經成為貸款的抵押品。

誰擁有H100,是矽谷最引人註目的頂級八卦
至於H200系統,英偉達表示預計將於明年二季度上市。
同在明年,英偉達還會發佈基於Blackwell架構的B100,並計劃在2024年將H100的產量增加兩倍,目標是生產200多萬塊H100。
而在發佈會上,英偉達甚至全程沒有提任何競爭對手,隻是不斷強調“英偉達的AI超級計算平臺,能夠更快地解決世界上一些最重要的挑戰。”
隨著生成式AI的大爆炸,需求隻會更大,而且,這還沒算上H200呢。贏麻,老黃真的贏麻!
141GB超大顯存,性能直接翻倍!
H200,將為全球領先的AI計算平臺增添動力。
它基於Hopper架構,配備英偉達H200 Tensor Core GPU和先進的顯存,因此可以為生成式AI和高性能計算工作負載處理海量數據。
英偉達H200是首款采用HBM3e的GPU,擁有高達141GB的顯存。

與A100相比,H200的容量幾乎翻一番,帶寬也增加2.4倍。與H100相比,H200的帶寬則從3.35TB/s增加到4.8TB/s。
英偉達大規模與高性能計算副總裁Ian Buck表示——
要利用生成式人工智能和高性能計算應用創造智能,必須使用大型、快速的GPU顯存,來高速高效地處理海量數據。借助H200,業界領先的端到端人工智能超算平臺的速度會變得更快,一些世界上最重要的挑戰,都可以被解決。
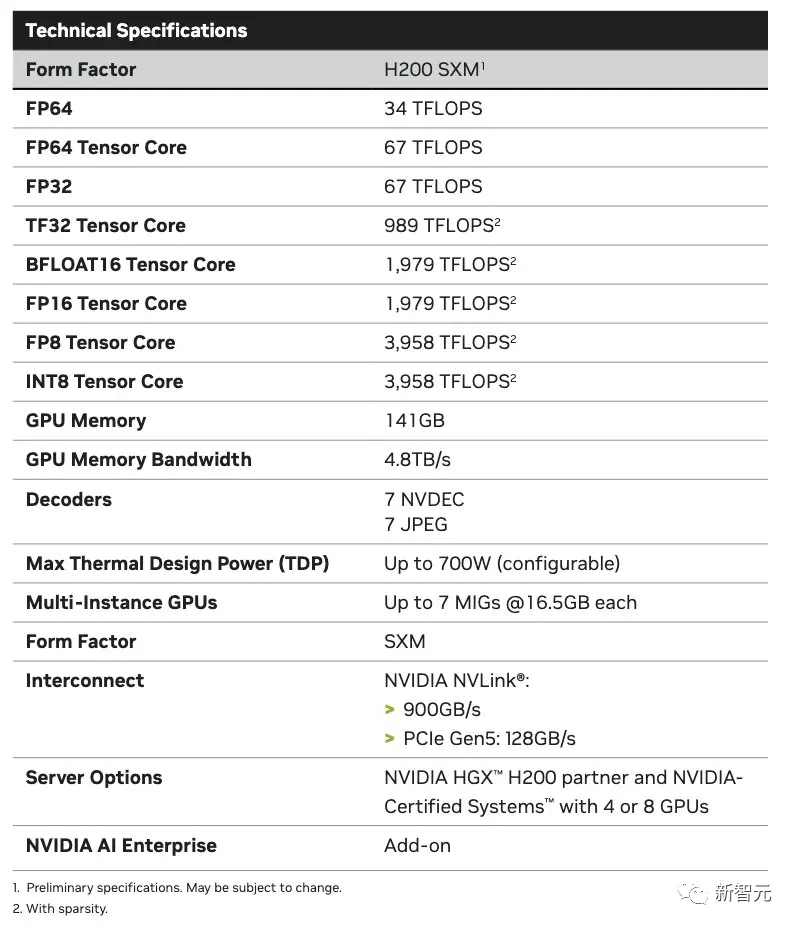
Llama 2推理速度提升近100%
跟前代架構相比,Hopper架構已經實現前所未有的性能飛躍,而H100持續的升級,和TensorRT-LLM強大的開源庫,都在不斷提高性能標準。
H200的發佈,讓性能飛躍又升一級,直接讓Llama2 70B模型的推理速度比H100提高近一倍!
H200基於與H100相同的Hopper架構。這就意味著,除新的顯存功能外,H200還具有與H100相同的功能,例如Transformer Engine,它可以加速基於Transformer架構的LLM和其他深度學習模型。

HGX H200采用英偉達NVLink和NVSwitch高速互連技術,8路HGX H200可提供超過32 Petaflops的FP8深度學習計算能力和1.1TB的超高顯存帶寬。
當用H200代替H100,與英偉達Grace CPU搭配使用時,就組成性能更加強勁的GH200 Grace Hopper超級芯片——專為大型HPC和AI應用而設計的計算模塊。

下面我們就來具體看看,相較於H100,H200的性能提升到底體現在哪些地方。
首先,H200的性能提升最主要體現在大模型的推理性能表現上。
如上所說,在處理Llama 2等大語言模型時,H200的推理速度比H100提高接近1倍。
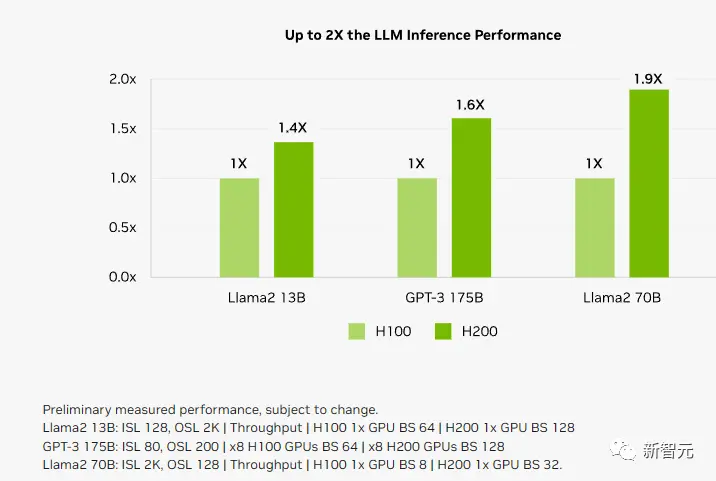
因為計算核心更新幅度不大,如果以訓練175B大小的GPT-3為例,性能提升大概在10%左右。
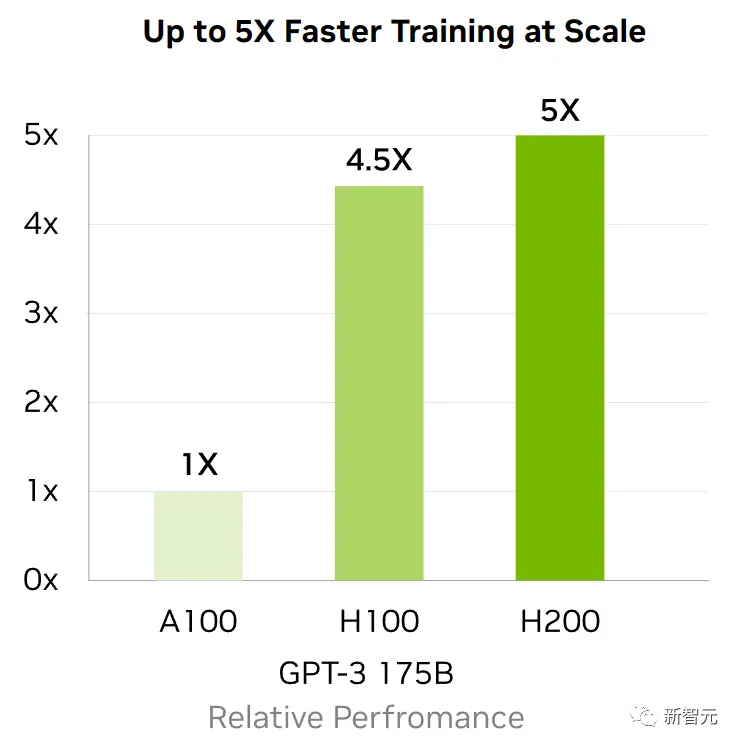
顯存帶寬對於高性能計算(HPC)應用程序至關重要,因為它可以實現更快的數據傳輸,減少復雜任務的處理瓶頸。
對於模擬、科學研究和人工智能等顯存密集型HPC應用,H200更高的顯存帶寬可確保高效地訪問和操作數據,與CPU相比,獲得結果的時間最多可加快110倍。
相較於H100,H200在處理高性能計算的應用程序上也有20%以上的提升。
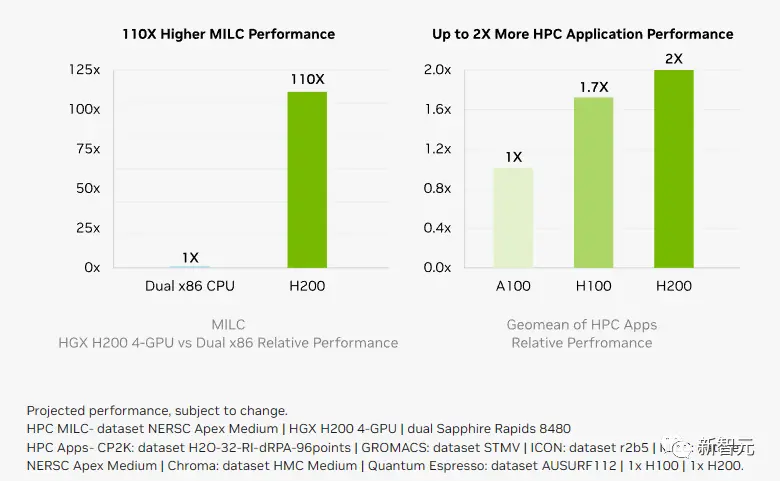
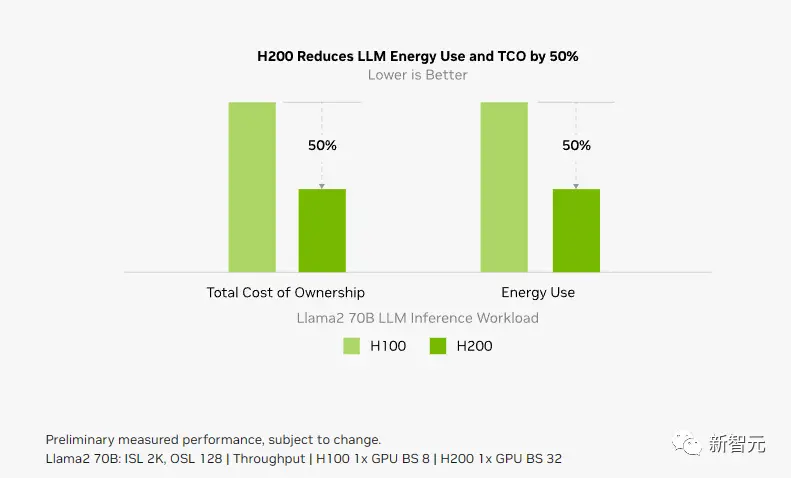
而對於用戶來說非常重要的推理能耗,H200相比H100直接腰斬。
這樣,H200能大幅降低用戶的使用成本,繼續讓用戶“買的越多,省的越多”!
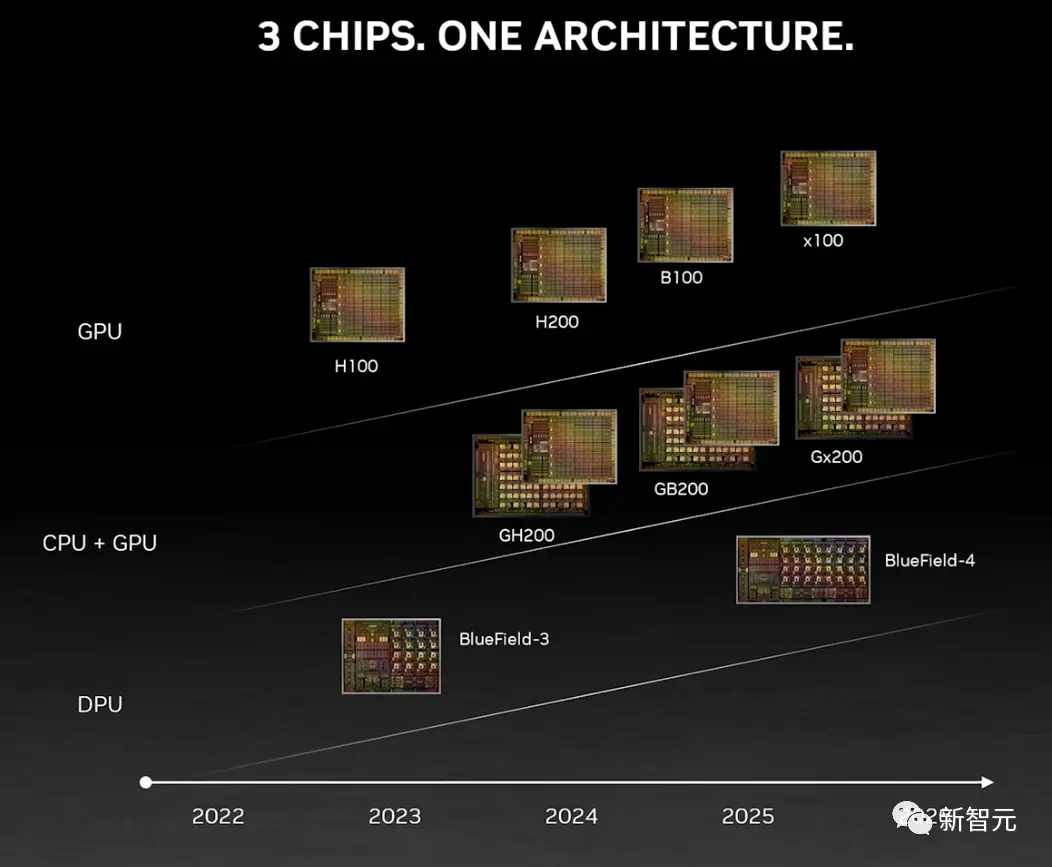
上個月,外媒SemiAnalysis曾曝出一份英偉達未來幾年的硬件路線圖,包括萬眾矚目的H200、B100和“X100”GPU。
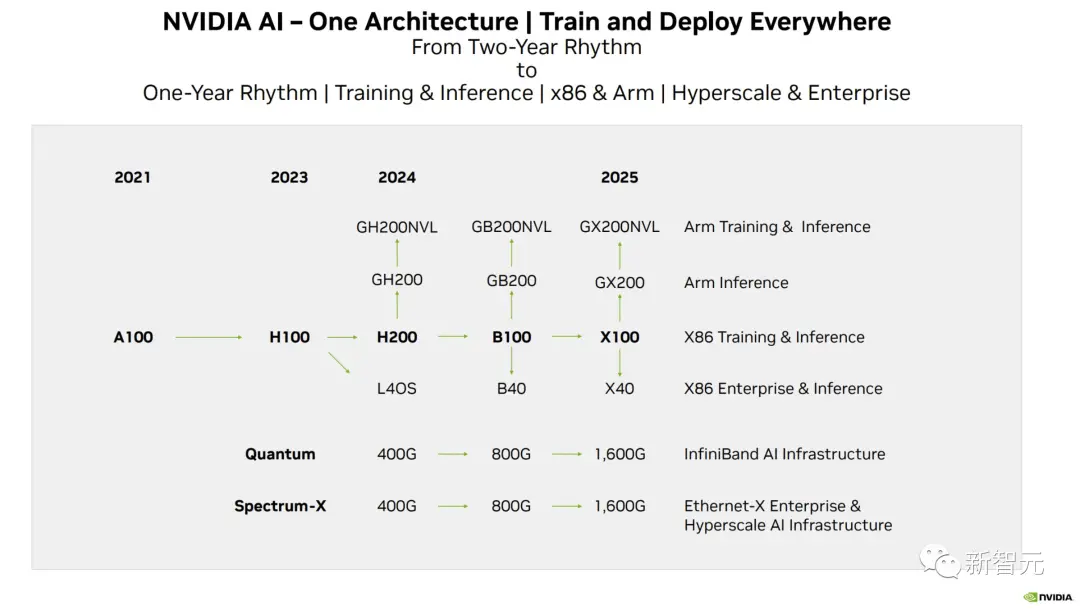
而英偉達官方,也公佈官方的產品路線圖,將使用同一構架設計三款芯片,在明年和後年會繼續推出B100和X100。
B100,性能已經望不到頭
這次,英偉達更是在官方公告中宣佈全新的H200和B100,將過去數據中心芯片兩年一更新的速率直接翻倍。
以推理1750億參數的GPT-3為例,今年剛發佈的H100是前代A100性能的11倍,明年即將上市的H200相對於H100則有超過60%的提升,而再之後的B100,性能更是望不到頭。
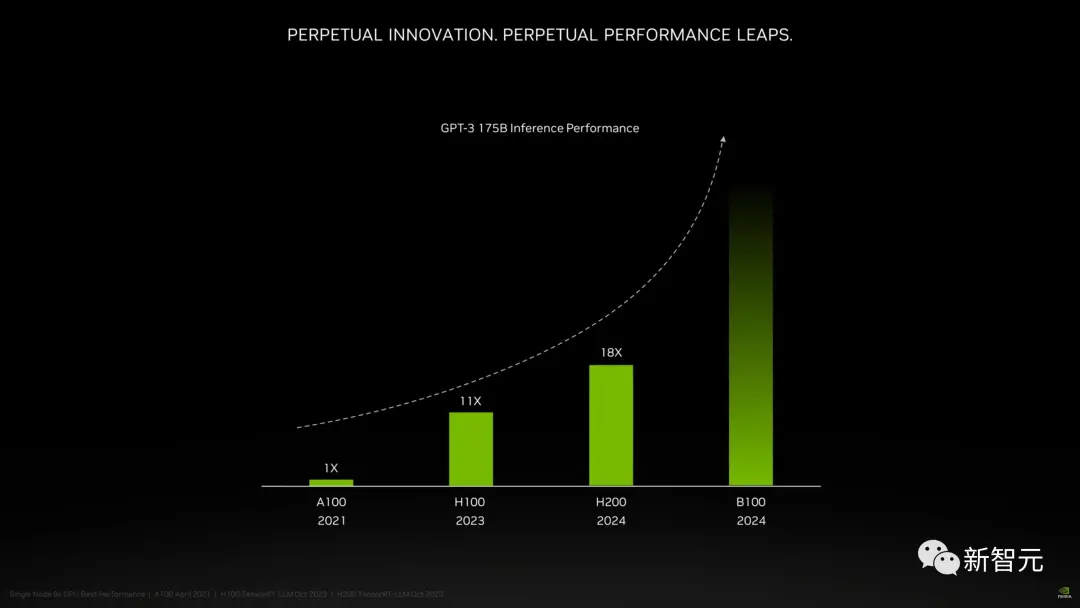
至此,H100也成為目前在位最短的“旗艦級”GPU。
如果說H100現在就是科技行業的“黃金”,那麼英偉達又成功制造“鉑金”和“鉆石”。

H200加持,新一代AI超算中心大批來襲
雲服務方面,除英偉達自己投資的CoreWeave、Lambda和Vultr之外,亞馬遜雲科技、Google雲、微軟Azure和甲骨文雲基礎設施,都將成為首批部署基於H200實例的供應商。

此外,在新的H200加持之下,GH200超級芯片也將為全球各地的超級計算中心提供總計約200 Exaflops的AI算力,用以推動科學創新。

在SC23大會上,多傢頂級超算中心紛紛宣佈,即將使用GH200系統構建自己的超級計算機。
德國尤裡希超級計算中心將在超算JUPITER中使用GH200超級芯片。
這臺超級計算機將成為歐洲第一臺超大規模超級計算機,是歐洲高性能計算聯合項目(EuroHPC Joint Undertaking)的一部分。

Jupiter超級計算機基於Eviden的BullSequana XH3000,采用全液冷架構。
它總共擁有24000個英偉達GH200 Grace Hopper超級芯片,通過Quantum-2 Infiniband互聯。
每個Grace CPU包含288個Neoverse內核, Jupiter的CPU就有近700萬個ARM核心。
它能提供93 Exaflops的低精度AI算力和1 Exaflop的高精度(FP64)算力。這臺超級計算機預計將於2024年安裝完畢。
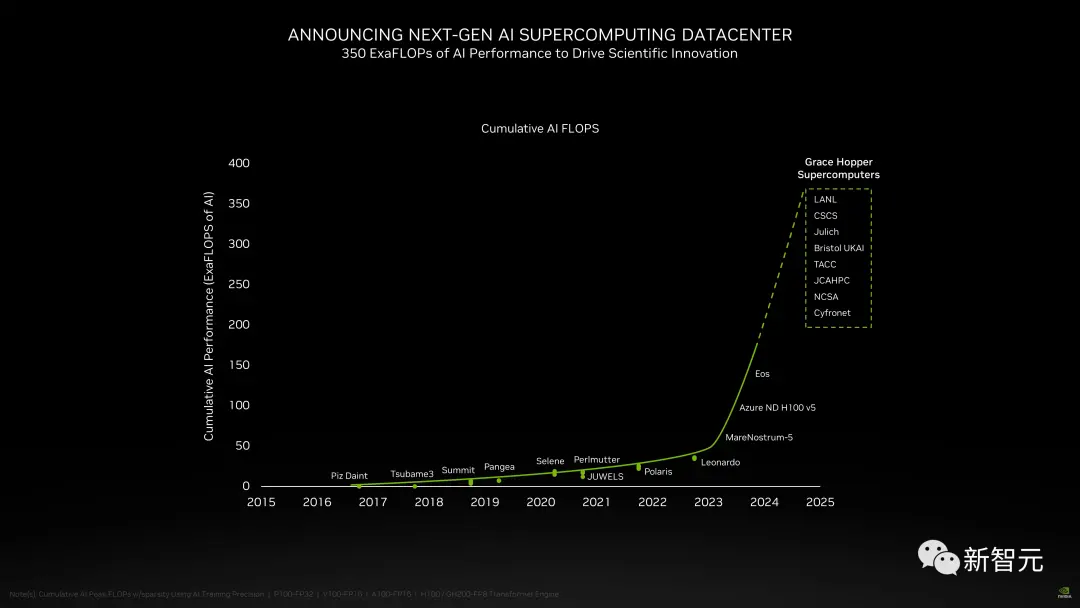
由築波大學和東京大學共同成立的日本先進高性能計算聯合中心,將在下一代超級計算機中采用英偉達GH200 Grace Hopper超級芯片構建。
作為世界最大超算中心之一的德克薩斯高級計算中心,也將采用英偉達的GH200構建超級計算機Vista。

伊利諾伊大學香檳分校的美國國傢超級計算應用中心,將利用英偉達GH200超級芯片來構建他們的超算DeltaAI,把AI計算能力提高兩倍。
此外,佈裡斯托大學將在英國政府的資助下,負責建造英國最強大的超級計算機Isambard-AI——將配備5000多顆英偉達GH200超級芯片,提供21 Exaflops的AI計算能力。

英偉達、AMD、英特爾:三巨頭決戰AI芯片
GPU競賽,也進入白熱化。

面對H200,而老對手AMD的計劃是,利用即將推出的大殺器——Instinct MI300X來提升顯存性能。
MI300X將配備192GB的HBM3和5.2TB/s的顯存帶寬,這將使其在容量和帶寬上遠超H200。
而英特爾也摩拳擦掌,計劃提升Gaudi AI芯片的HBM容量,並表示明年推出的第三代Gaudi AI芯片將從上一代的 96GB HBM2e增加到144GB。
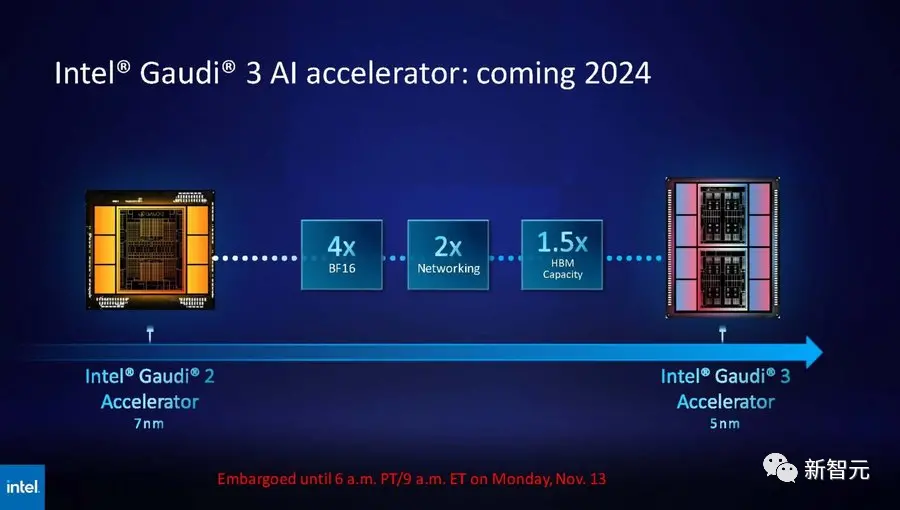
英特爾Max系列目前的HBM2容量最高為128GB,英特爾計劃在未來幾代產品中,還要增加Max系列芯片的容量。
H200價格未知
所以,H200賣多少錢?英偉達暫時還未公佈。
要知道,一塊H100的售價,在25000美元到40000美元之間。訓練AI模型,至少需要數千塊。
此前,AI社區曾廣為流傳這張圖片《我們需要多少個GPU》。

GPT-4大約是在10000-25000塊A100上訓練的;Meta需要大約21000塊A100;Stability AI用大概5000塊A100;Falcon-40B的訓練,用384塊A100。
根據馬斯克的說法,GPT-5可能需要30000-50000塊H100。摩根士丹利的說法是25000個GPU。
Sam Altman否認在訓練GPT-5,但卻提過“OpenAI的GPU嚴重短缺,使用我們產品的人越少越好”。
我們能知道的是,等到明年第二季度H200上市,屆時必將引發新的風暴。