沒有出乎太多意外,Meta帶著號稱“有史以來最強大的開源大模型”Llama3系列模型來“炸街”。具體來說,Meta本次開源8B和70B兩款不同規模的模型。Llama38B:基本上與最大的Llama270B一樣強大。
Llama 3 70B: 第一檔 AI 模型,媲美 Gemini 1.5 Pro、全面超越 Claude 大杯
以上還隻是 Meta 的開胃小菜,真正的大餐還在後頭。在未來幾個月,Meta 將陸續推出一系列具備多模態、多語言對話、更長上下文窗口等能力的新模型。
其中,超 400B 的重量級選手更是有望與 Claude 3 超大杯“掰手腕”。

又一 GPT-4 級模型來,Llama 3 開卷
與前代 Llama 2 模型相比,Llama 3 可謂是邁上一個新的臺階。
得益於預訓練和後訓練的改進,本次發佈的預訓練和指令微調模型是當今 8B 和 70B 參數規模中的最強大的模型。
同時後訓練流程的優化顯著降低模型的出錯率,增強模型的一致性,並豐富響應的多樣性。
紮克伯格曾在一次公開發言中透露,考慮到用戶不會在 WhatsApp 中向 Meta AI 詢問編碼相關的問題,因此 Llama 2 在這一領域的優化並不突出。
而這一次,Llama 3 在推理、代碼生成和遵循指令等方面的能力取得突破性的提升,使其更加靈活和易於使用。
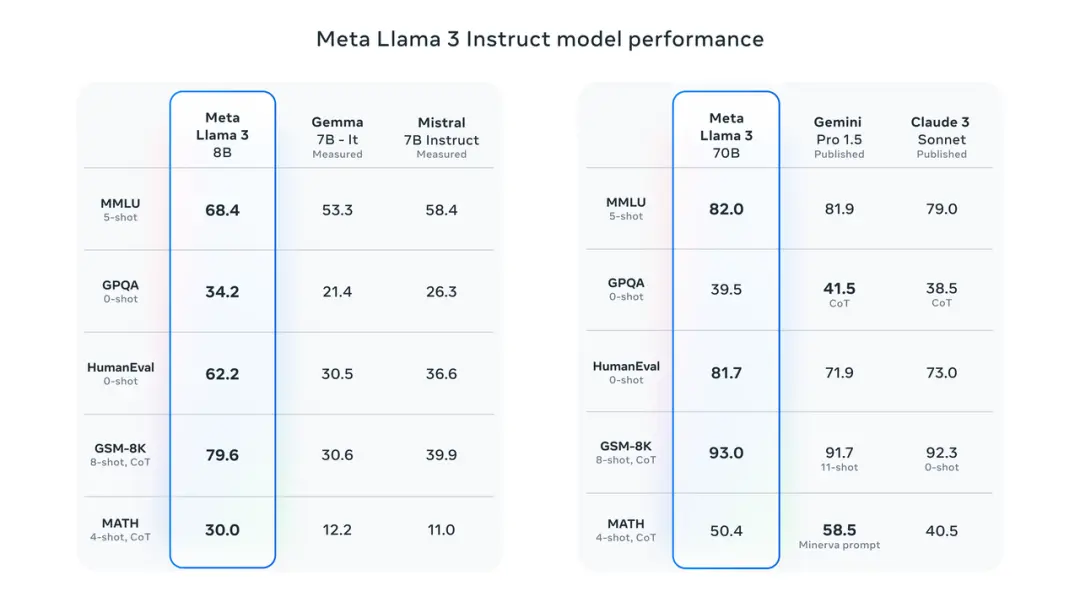
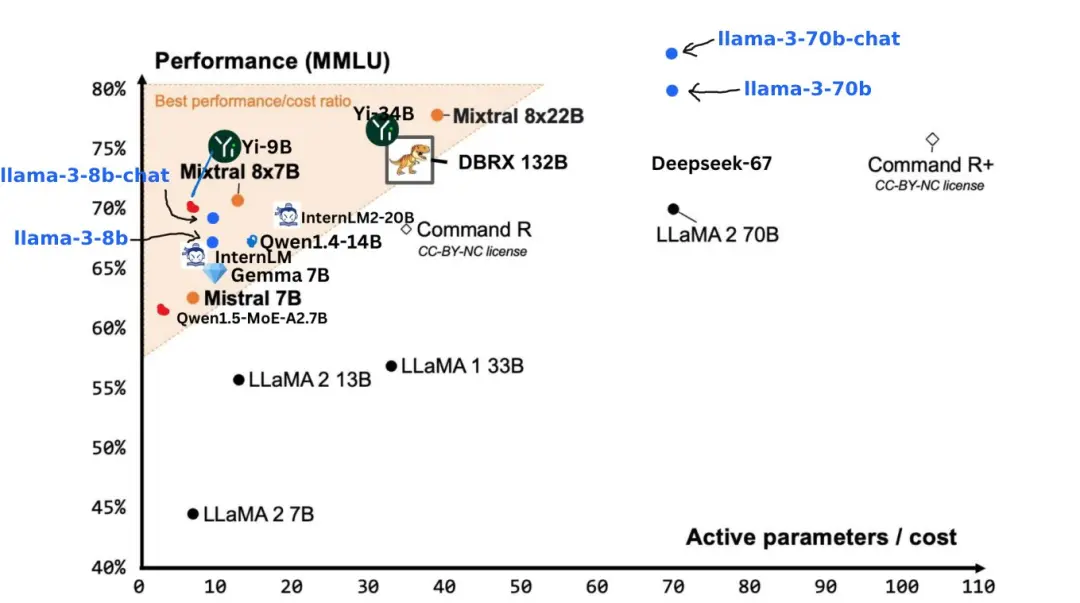
基準測試結果顯示,Llama 3 8B 在 MMLU、GPQA、HumanEval 等測試的得分遠超 Google Gemma 7B 以及 Mistral 7B Instruct。用紮克伯格的話來說,最小的 Llama 3 基本上與最大的 Llama 2 一樣強大。
Llama 3 70B 則躋身於頂尖 AI 模型的行列,整體表現全面碾壓 Claude 3 大杯,與 Gemini 1.5 Pro 相比則是互有勝負。
為準確研究基準測試下的模型性能,Meta 還特意開發一套新的高質量人類評估數據集。
該評估集包含 1800 個提示,涵蓋 12 個關鍵用例:尋求建議、頭腦風暴、分類、封閉式問答、編碼、創意寫作、提取、塑造角色、開放式問答、推理、重寫和總結。
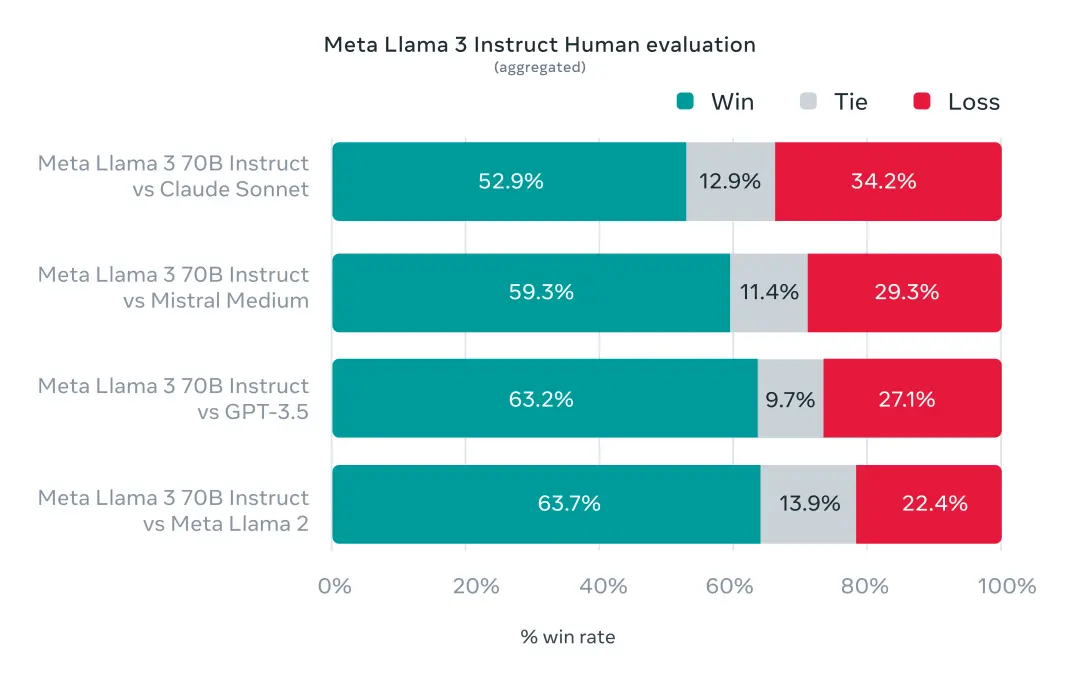
出於避免 Llama 3 在此評估集上出現過度擬合,Meta 甚至禁止他們的研究團隊訪問該數據集。在與 Claude Sonnet、Mistral Medium 和 GPT-3.5 的逐一較量中,Meta Llama 70B 都以“壓倒性勝利”結束比賽。
據 Meta 官方介紹,Llama 3 在模型架構上選擇相對標準的純解碼器 Transformer 架構。與 Llama 2 相比,Llama 3 進行幾項關鍵的改進:
使用具有 128K token 詞匯表的 tokenizer,可以更有效地編碼語言,從而顯著提升模型性能
在 8B 和 70B 模型中都采用分組查詢註意力 (GQA),以提高 Llama 3 模型的推理效率
在 8192 個 token 的序列上訓練模型,使用掩碼來確保自註意力不會跨越文檔邊界。
訓練數據的數量和質量是推動下一階段大模型能力湧現的關鍵因素。
從一開始,Meta Llama 3 就致力於成為最強大的模型。Meta 在預訓練數據上投入大量的資金。 據悉,Llama 3 使用從公開來源收集的超過 15T 的 token,是 Llama 2 使用數據集的七倍,其中包含的代碼數據則是 Llama 2 的四倍。
考慮到多語言的實際應用,超過 5% 的 Llama 3 預訓練數據集由涵蓋 30 多種語言的高質量非英語數據組成,不過,Meta 官方也坦言,與英語相比,這些語言的性能表現預計是稍遜一籌。
為確保 Llama 3 接受最高質量的數據訓練,Meta 研究團隊甚至提前使用啟發式過濾器、NSFW 篩選器、語義重復數據刪除方法和文本分類器來預測數據質量。
值得註意的是,研究團隊還發現前幾代 Llama 模型在識別高質量數據方面出奇地好,於是讓 Llama 2 為 Llama 3 提供支持的文本質量分類器生成訓練數據,真正實現“AI 訓練 AI”。
除訓練的質量,Llama 3 在訓練效率方面也取得質的飛躍。
Meta 透露,為訓練最大的 Llama 3 模型,他們結合數據並行化、模型並行化和管道並行化三種類型的並行化。
在 16K GPU 上同時進行訓練時,每個 GPU 可實現超過 400 TFLOPS 的計算利用率。研究團隊在兩個定制的 24K GPU 集群上執行訓練運行。

為最大限度地延長 GPU 的正常運行時間,研究團隊開發一種先進的新訓練堆棧,可以自動執行錯誤檢測、處理和維護。此外,Meta 還極大地改進硬件可靠性和靜默數據損壞檢測機制,並且開發新的可擴展存儲系統,以減少檢查點和回滾的開銷。
這些改進使得總體有效訓練時間超過 95%,也讓 Llama 3 的訓練效率比前代足足提高約 3 倍。
開源 VS 閉源
作為 Meta 的“親兒子”,Llama 3 也順理成章地被優先整合到 AI 聊天機器人 Meta AI 之中。
追溯至去年的 Meta Connect 2023 大會,紮克伯格在會上正式宣佈推出 Meta AI,隨後便迅速將其推廣至美國、澳大利亞、加拿大、新加坡、南非等地區。
在此前的采訪中,紮克伯格對搭載 Llama 3 的 Meta AI 更是充滿信心,稱其將會是人們可以免費使用的最智能的 AI 助手。
我認為這將從一個類似聊天機器人的形式轉變為你隻需提出一個問題,它就能給出答案的形式,你可以給它更復雜的任務,它會去完成這些任務。
當然,Meta AI 若是“ 尚未在您所在的國傢/地區推出”,你可以采用開源模型最樸素的使用渠道——全球最大的 AI 開源社區網站 Hugging Face。
Perplexity、Poe 等平臺也迅速宣佈將 Llama 3 集成到平臺服務上。

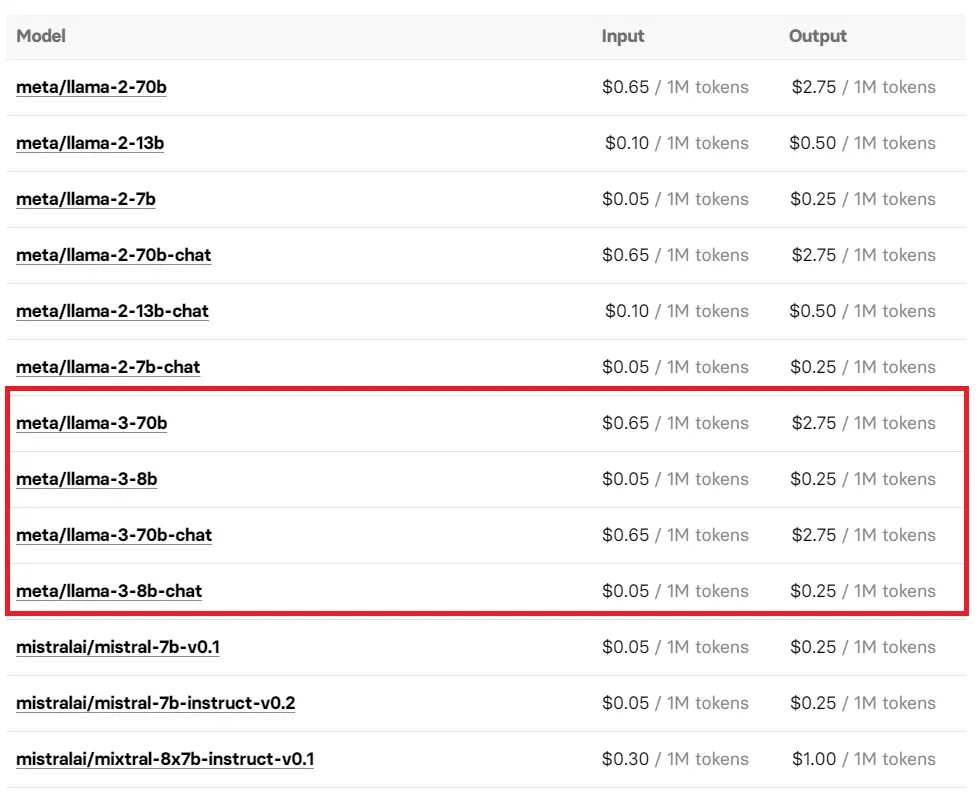
你還可以通過調用開源模型平臺 Replicate API 接口來體驗 Llama 3,其使用的價格也已經曝光,不妨按需使用。
有趣的是,在 Meta 官宣 Llama 3 前,有眼尖的網友發現微軟的 Azure 市場偷跑 Llama 3 8B Instruct 版本,但隨著消息的進一步擴散,當蜂擁而至的網友再次嘗試訪問該鏈接時,得到的隻有“404”的頁面。
Llama 3 的到來,正在社交平臺 X 上掀起一股新的討論風暴。
Meta AI 首席科學傢、圖靈獎得主 Yann LeCun 不僅為 Llama 3 的發佈搖旗吶喊,並再次預告未來幾個月將推出更多版本。就連馬斯克也現身於該評論區,用一句簡潔而含蓄的“Not bad 不錯”,表達對 Llama 3 的認可和期待。
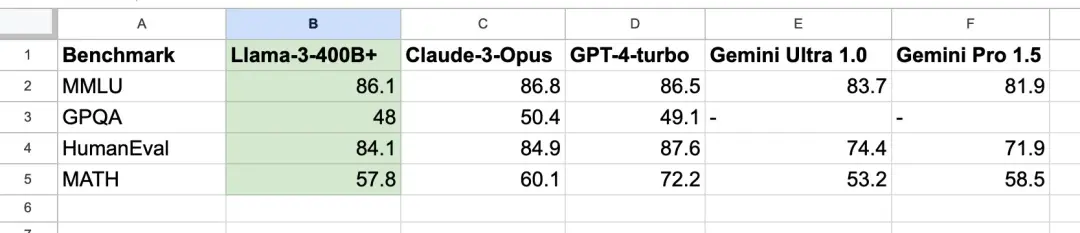
英偉達高級科學傢 JIm Fan 則將註意力投向即將推出的 Llama 3 400B+,在他看來,Llama 3 的推出已經脫離技術層面的進步,更像是開源模型與頂尖閉源模型並駕齊驅的象征。
從其分享的基準測試可以看出,Llama 3 400B+ 的實力幾乎媲美 Claude 超大杯、以及 新版 GPT-4 Turbo,雖然仍有一定的差距,但足以證明其在頂尖大模型中占有一席之地。
今天恰逢斯坦福大學教授,AI 頂尖專傢吳恩達的生日,Llama 3 的到來無疑是最特別的慶生方式。
不得不說,如今的開源模型當真是百花齊放,百傢爭鳴。
今年年初,手握 35 萬塊 GPU 的紮克伯格在接受 The Verge 的采訪時描繪 Meta 的願景——致力於打造 AGI(通用人工智能)。
與不 open 的 OpenAI 形成鮮明對比,Meta 則沿著 open 的開源路線朝 AGI 的聖杯發起沖鋒。
正如紮克伯格所說,堅定開源的 Meta 在這條充滿挑戰的征途中也並非毫無收獲:
我通常非常傾向於認為開源對社區和我們都有好處,因為我們會從創新中受益。
在過去的一年中,整個 AI 圈都在圍繞開源或閉源的路線爭論不休, 甚至親自下場的馬斯克也通過開源 Grok 1.0 的方式給全世界打個樣。
如今 這場辯論,已經超越技術層面的優劣比較,觸及 AI 未來發展的核心方向。
前不久,一些觀點稱開源模型將會越來越落後,如今 Llama 3 的到來,也給這種悲觀的論調一記響亮的耳光。
然而,盡管 Llama 3 為開源模型扳回一局,但這場關於開源與閉源的辯論還遠未結束。
畢竟暗中蓄勢待發的 GPT-4.5/5 也許會在今年夏天,以無可匹敵的性能為這場曠日持久的爭論畫上一個句號。