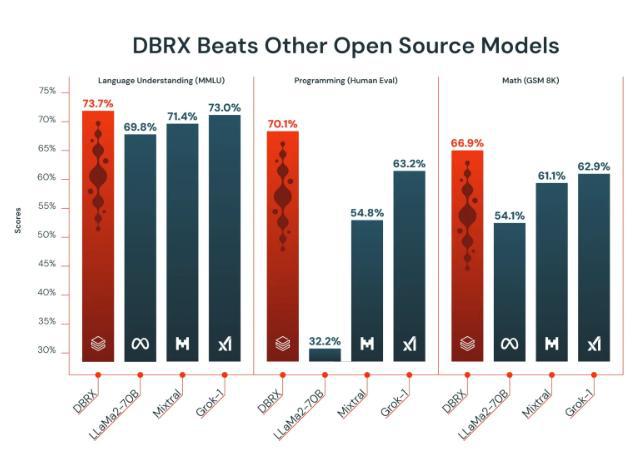
美國當地時間周三,企業軟件公司Databricks宣佈推出新的開源人工智能模型DBRX,聲稱這一模型在開源人工智能領域的效率和性能上樹立新的行業標準。Databricks宣稱,DBRX模型擁有1320億個參數,在語言理解、編程和數學技能等關鍵領域的基準測試中,其性能超過其他領先的開源人工智能模型,包括Meta的Llama2-70B和法國初創企業MixtralAI的模型。
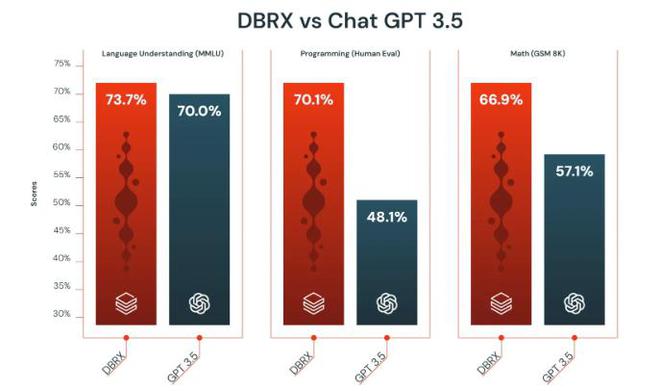
雖然DBRX在某些原始功能上還無法與OpenAI的GPT-4相比,但Databricks高管表示,DBRX無疑是一個功能遠超GPT-3.5的替代產品,並且成本隻是GPT-3.5的一小部分。
Databricks的首席執行官阿裡·戈德西(Ali Ghodsi)在新聞發佈會上表示:“我們非常高興能向全世界展示DBRX,並帶動整個行業向更強大、更高效的開源人工智能方向前進。雖然GPT-4這類基礎模型無疑是極其優秀的通用工具,但Databricks專註於為客戶量身打造模型,這些模型能深入解析他們的專有數據。DBRX的發佈正體現我們實現該目標的決心。”
創新的“專傢混合”架構
Databricks的研究團隊揭示DBRX模型的關鍵創新之處——“專傢混合”架構。這一架構使DBRX與其他競爭模型顯著不同,後者往往利用所有參數生成每個單詞。相較而言,DBRX巧妙地整合16個專傢子模型,並在實時處理中為每個token準確挑選最相關的四個子模型。
這種設計的巧妙之處在於,它使DBRX在任何時刻隻需激活360億個參數,因而實現更高的性能輸出。這不僅顯著提高模型的處理速度,還大幅降低運行成本,使其更為高效和經濟。
這一創新策略是基於Mosaic團隊在早期Mega-MoE項目上的進一步研究而開發的。Mosaic團隊是去年被Databricks收購的一個研究部門。
戈德西高度評價Mosaic團隊的貢獻,他表示:“多年來,Mosaic團隊在更高效訓練基礎人工智能模型方面取得顯著進步。正是他們的努力讓我們能夠迅速開發出如DBRX這般卓越的人工智能模型。實際上,開發DBRX隻用約兩個月時間,成本大概在1000萬美元左右。”
推進Databricks的企業AI戰略
通過將DBRX開源,Databricks的目標不僅是在前沿人工智能研究領域確立其領導者地位,而且還希望促進其創新架構在整個行業中的更廣泛采用。此外,DBRX也致力於支持Databricks的核心業務——為客戶定制和托管基於其專有數據集的人工智能模型。
在如今的市場環境中,很多Databricks的客戶都依賴於OpenAI及其他供應商提供的GPT-3.5等模型來支撐其業務運作。然而,將敏感的企業數據托管給第三方,常常會激起關於安全性和合規性的一系列擔憂。
針對這一點,戈德西表示:“我們的客戶相信,Databricks能夠妥善處理跨國界數據監管的問題。他們已在Databricks平臺上存儲並管理龐大數據量。現在,有DBRX以及Mosaic的定制模型功能,客戶們能夠在保障數據安全的同時,充分利用先進人工智能技術帶來的諸多益處。”
在日益激烈的競爭中占據一席之地
隨著DBRX的推出,Databricks在核心數據和人工智能平臺業務領域面臨著激烈的競爭。競爭對手諸如數據倉庫巨頭Snowflake已通過推出自有的人工智能服務Cortex,復制Databricks的部分功能。同時,亞馬遜、微軟和谷歌等領先的雲計算服務供應商也正紛紛在其技術堆棧中集成生成式人工智能功能。
Databricks借助其開創性的開源項目DBRX,自詡具備最前沿的人工智能研究能力,旨在確立自身作為該領域領導者的地位,並吸引頂尖的數據科學人才。這一策略也反映人們對大型科技公司將人工智能模型商業化的越來越多的抵制,許多人批評這些商業模型像“黑盒子”,缺乏透明度和可解釋性。
DBRX面臨的真正挑戰在於市場的接受程度以及它為Databricks客戶所創造的具體價值。在企業越來越多尋求利用人工智能推動業務增長和創新的同時,還要保持對自有數據的控制,Databricks賭註於其尖端研究與企業級平臺的完美融合能夠讓它在競爭中脫穎而出。
Databricks已經向大型科技公司及開源社區的競爭對手拋出挑戰,要求他們在創新上與其一較高下。人工智能領域的競爭日趨激烈,而Databricks已明確宣佈其志在成為這場競爭的關鍵力量。