昨日晚間,Google毫無預兆地發佈開源模型Gemma,直接狙擊Llama2,繼通過Gemini拳打OpenAI後,試圖用Gemma腳踢Meta。不同於Gemini的“全傢桶”路線,Gemma主打輕量級、高性能,有20億、70億兩種參數規模,能在筆記本電腦、臺式機、物聯網設備、移動設備和雲端等不同平臺運行。

Google發佈Gemma(圖源:Google)
性能方面,Gemma在18個基準測評中平均成績擊敗目前的主流開源模型Llama 2和Mistral,特別是在數學、代碼能力上表現突出,還直接登頂Hugging Face開源大模型排行榜。
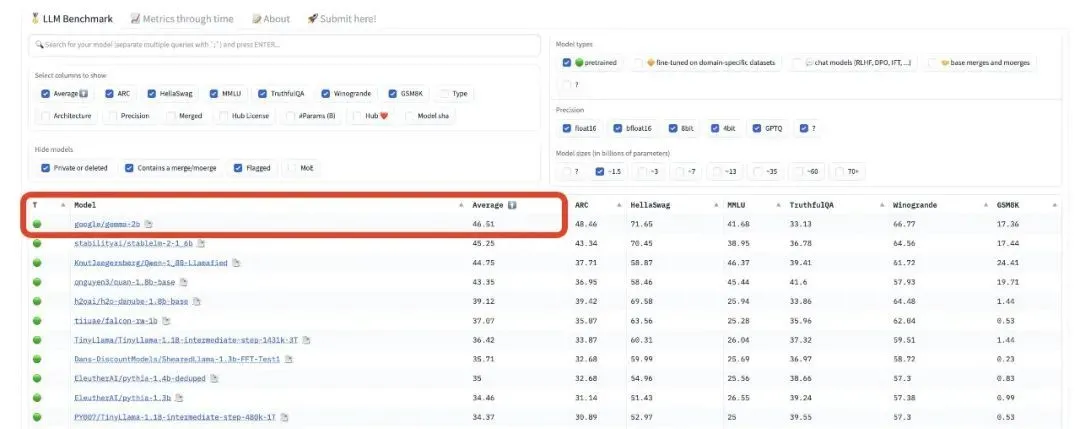
Gemma登頂Hugging Face開源大模型排行榜(圖源:X)
Google同步放出技術報告,通過深度解讀,智東西註意到除模型性能優異外,Gemma的分詞器詞表大小達到256k,這意味著它更容易擴展至其他語言。
Google還強調Gemma基於自傢TPUv5e芯片訓練,Gemma 7B使用4096個TPUv5e,Gemma 2B使用512個TPUv5e,秀出挑戰英偉達GPU統治地位的“肌肉”。
短短12天,Google連續放出三個大招,先是9日宣佈其最強大模型Gemini Ultra免費用,又在16日放出大模型“核彈”Gemini 1.5,再是21日突然放出開源模型Gemma,動作之密集、行動之迅速,似乎在向搶自己風頭的OpenAI宣戰。
Gemma具體強在哪兒?它在哪些方面打贏Llama 2?其技術原理和訓練過程有哪些亮點?讓我們從技術報告中尋找答案。
Gemma官網地址:
https://ai.google.dev/gemma
Gemma開源地址:
https://www.kaggle.com/models/google/gemma/code/
01.
采用Gemini相同架構
輕量級筆記本也能跑
據介紹,Gemma模型的研發是受到Gemini的啟發,它的名字來源於意大利語“寶石”,是由GoogleDeepMind和其他團隊共同合作開發。
Gemma采用與Gemini相同的技術和基礎架構,基於英偉達GPU和Google雲TPU等硬件平臺進行優化,有20億、70億兩種參數規模,每個規模又分預訓練和指令微調兩個版本。
性能方面,Google稱Gemma在MMLU、BBH、HumanEval等八項基準測試集上大幅超過Llama 2。
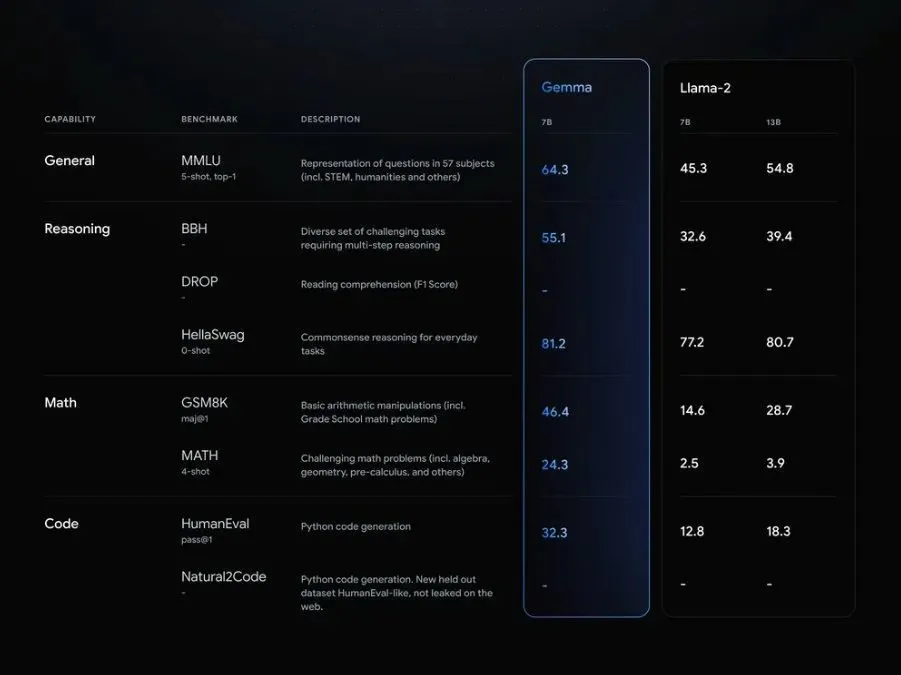
Gemma在基準測試上與Llama 2的跑分對比(圖源:Google)
在發佈權重的同時,Google還推出Responsible Generative AI Toolkit等一系列工具,為使用Gemma創建更安全的AI應用程序提供指導。此外,Google通過原生Keras 3.0為JAX、PyTorch和TensorFlow等主要框架提供推理和監督微調(SFT)的工具鏈。
Google強調Gemma在設計時將其AI原則放在首位,通過大量微調和人類反饋強化學習(RLHF)使指令微調模型與負責任的行為對齊,還通過手工紅隊測試、自動對抗性測試等對模型進行評估。
此外,Google與英偉達宣佈合作,利用英偉達TensorRT-LLM對Gemma進行優化。英偉達上周剛發佈的聊天機器人Chat with RTX也將很快增加對Gemma的支持。
即日起,Gemma在全球范圍內開放使用,用戶可以在Kaggle、Hugging Face等平臺上進行下載和試用,它可以直接在筆記本電腦或臺式機上運行。
發佈才幾個小時,已有不少用戶分享試用體驗。社交平臺X用戶@indigo11稱其“速度飛快”,“輸出很穩定”。

X用戶@indigo11分享Gemma試用體驗(圖源:X)
還有用戶嘗試其他語種,稱Gemma對日語的支持很流暢。
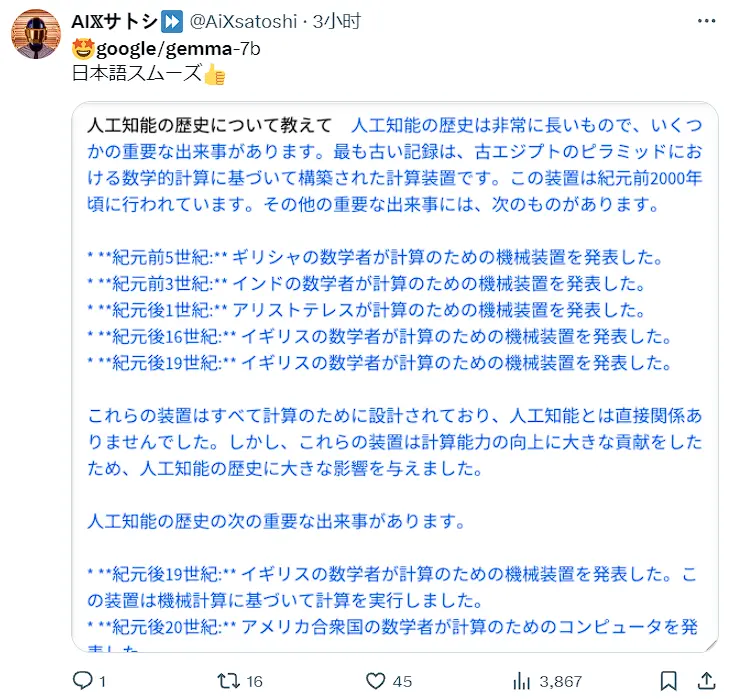
X用戶@AiXsatoshi分享Gemma在日語上的試用體驗(圖源:X)
02.
數學、代碼能力碾壓Llama 2
采用自傢TPUv5e訓練
與Gemini發佈時一樣,Google此次也同步公開Gemma的技術報告。

Gemma技術報告(圖源:Google)
報告稱,Gemma 2B和7B模型分別在2T和6T的tokens上進行訓練,數據主要來自網絡文檔、數學和代碼的英語數據。不同於Gemini,這些模型不是多模態的,也沒有針對多語言任務進行訓練。
Google使用Gemini的SentencePiece分詞器的一個子集以保證兼容性。它分割數字但不去除額外的空格,並且對未知標記依賴於字節級編碼,詞表大小為256k個tokens,這可能意味著它更容易擴展到其他語言。

開發者稱256k分詞器值得註意(圖源:X)
兩個規模中,70億參數的Gemma 7B適用於GPU、TPU上的高效部署和開發,20億參數的Gemma 2B則適用於CPU。
Gemma基於Google的開源模型和生態構建,包括Word2Vec、BERT、T5、T5X等,其模型架構基於Transformer,主要核心參數如下表。
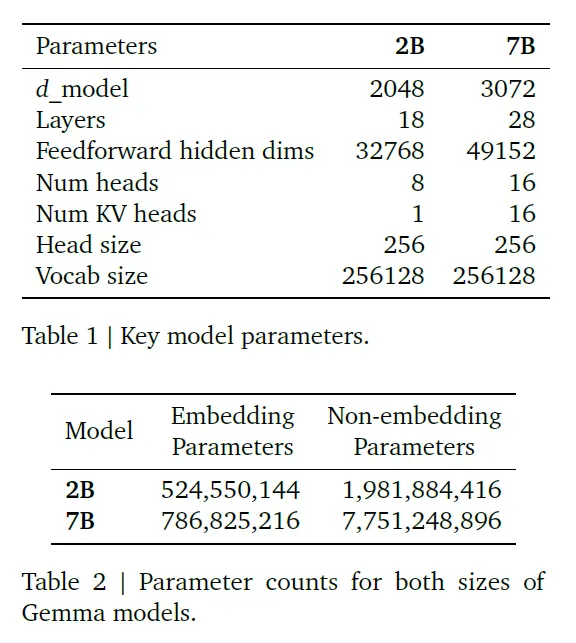
Gemma模型主要參數(圖源:Google)
在基準測評中,Gemma直接對標目前先進的開源模型Llama 2和Mistral,其中Gemma 7B在18個基準上取得11個優勝,並以平均分56.4高於同級別模型。
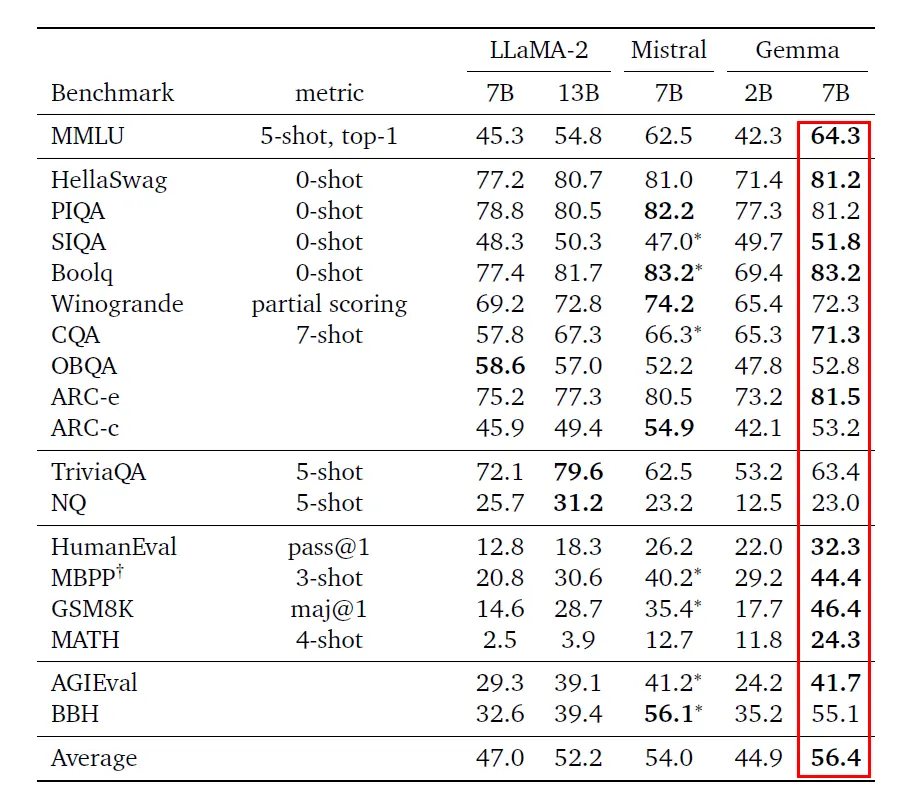
Gemma與Llama 2、Mistral基準測評分數對比(圖源:Google)
從具體能力上看,Gemma 7B在問答、推理、數學/科學、代碼等方面的標準學術基準測試平均分數都高於同規模的Llama 2和Mistral模型。
此外,其推理、數學/科學、代碼能力還高於規模更大的Llama 2 13B。
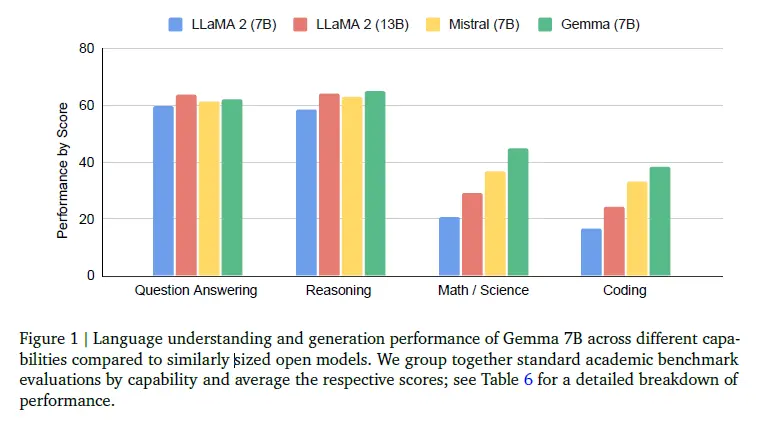
Gemma與Llama 2、Mistral各能力對比(圖源:Google)
報告還詳細介紹Gemma訓練采用的硬件:使用部署在256個芯片組成的Pod中的TPUv5e訓練,這些Pod配置成一個16*16芯片的2D環形網絡。
其中,Gemma 7B模型跨16個Pod進行訓練,共使用4096個TPUv5e;Gemma 2B模型跨越2個Pod進行訓練,共使用512個TPUv5e。
在一個Pod內部,Google為Gemma 7B使用16路模型分片和16路數據復制,Gemma 2B則使用256路數據復制。優化器狀態進一步通過類似於ZeRO-3的技術進行分片。
技術報告地址:
https://goo.gle/GemmaReport
03.
被OpenAI逼急
Google一月連放三大招
2024開年,OpenAI發佈的Sora文生視頻模型爆火,一舉搶走Google最新力作Gemini 1.5 Pro大模型的風頭。
但Google並沒有就此打住,而是乘勝追擊放出一個月裡的第三個大招,這三個大招分別是:
2月9日大年三十,Google宣佈其最強大模型Gemini Ultra免費用,Gemini Ultra於2023年12月發佈時在MMLU(大規模多任務語言理解)測評上超過人類專傢,在32個多模態基準中取得30個SOTA(當前最優效果),幾乎全方位超越GPT-4,向OpenAI發起強勢一擊。(《Google大年三十整大活!最強大模型Gemini Ultra免費用,狙擊GPT-4》)
2月16日大年初七,Google放出其大模型核彈——Gemini 1.5,並將上下文窗口長度擴展到100萬個tokens。Gemini 1.5 Pro可一次處理1小時的視頻、11小時的音頻、超過3萬行代碼或超過70萬字的代碼庫,向OpenAI還沒發佈的GPT-5發起挑戰。 (《GoogleGemini 1.5模型來!突破100萬個tokens,能處理1小時視頻【附58頁技術報告】》)
2月21日正月十二,Google在被“搶頭條”後,一舉將采用創建Gemini相同研究和技術的Gemma開源,一方面狙擊Llama 2等開源模型,登上開源大模型鐵王座,同時為嗷嗷待哺的生成式AI的應用開發者帶來福音,更是為閉源的代表OpenAI狠狠地上一課。
自2022年12月ChatGPT發佈以來,AI領域扛把子Google就陷入被OpenAI壓著打的境地,“復仇”心切。
在GPT-3大模型問世前,DeepMind的風頭更勝一籌,坐擁AlphaGo、AlphaGo Zero、MuZero、AlphaFold等一系列打敗人類的明星AI模型。隨著生成式AI風口漸盛,GoogleDeepMind卻開始顯得力不從心,ChatGPT引發GoogleAI人才大軍流向OpenAI,OpenAI卻由此扶搖直上。
2023年3月,Google促成Google大腦和DeepMind冰釋前嫌,合並對抗OpenAI,被業內稱為“Google復仇聯盟”。然而,直到年底的12月7日,Google最強大模型Gemini才姍姍來遲,盡管效果驚艷卻令市場有些意興闌珊。2024年1月31日,Google最新財報顯示其收入亮眼,卻因AI方面進展不及預期市值一夜蒸發超1000億美元。
然而,2024年2月一來到,Google的狀態來個180度大轉彎,攢一年的大招接二連三地釋放,試圖用強大的Gemini大模型矩陣證明,其是被嚴重低估的。
值得一提的是,Google還有另一張王牌是自研芯片,有望成為其與OpenAI抗衡的有力底牌。2023年8月,Google雲發佈最新雲端AI芯片TPU v5e,TPU被視作全球AI芯片霸主英偉達GPU的勁敵。
據半導體研究和咨詢公司SemiAnalysis的分析師曝料,Google擁有的算力資源比OpenAI、Meta、亞馬遜、甲骨文和CoreWeave加起來還要多,其下一代大模型Gemini已經開始在新的TPUv5 Pod上進行訓練,算力達到GPT-4的5倍,基於其目前的基礎設施建設情況,到明年年底可能達到20倍。
04.
結語:Google再放大招
拳打OpenAI,腳踢Meta
從2023年12月發佈Gemini多模態大模型,到2024年2月連放Gemini Ultra免費版、Gimini 1.5、Gemini技術開源三個大招,Google的大模型矩陣逐漸清晰,從閉源和開源兩大路線對OpenAI打響復仇戰,也向推出開源模型Llama 2的Meta宣戰。
當下,OpenAI的文生視頻大模型Sora風頭正盛。實際上,Google已於2023年12月推出用於零樣本視頻生成的大型語言模型VideoPoet,可在單個大模型中無縫集成多種視頻生成功能。Google在文生視頻領域的儲備想必也深,可以預測後續和OpenAI有得一打,而壓力也就此給到國內的AI企業。