Meta發佈開源生成式人工智能模型Llama系列的最新產品:Llama3。或者,更準確地說,該公司已經開源新的Llama3系列中的兩個模型,其餘模型將在未來某個不確定的日期推出。
Meta 稱,與上一代 Llama 模型 Llama 2 8B 和 Llama 2 70B 相比,新模型 Llama 3 8B(包含 80 億個參數)和 Llama 3 70B(包含 700 億個參數)在性能上有"重大飛躍"。(參數從本質上定義人工智能模型處理問題的能力,比如分析和生成文本;一般來說,參數數越高的模型比參數數越低的模型能力越強)。事實上,Meta 表示,就各自的參數數而言,Llama 3 8B 和 Llama 3 70B 是在兩個定制的 24,000 GPU 集群上訓練出來的,是當今性能最好的生成式人工智能模型之一。
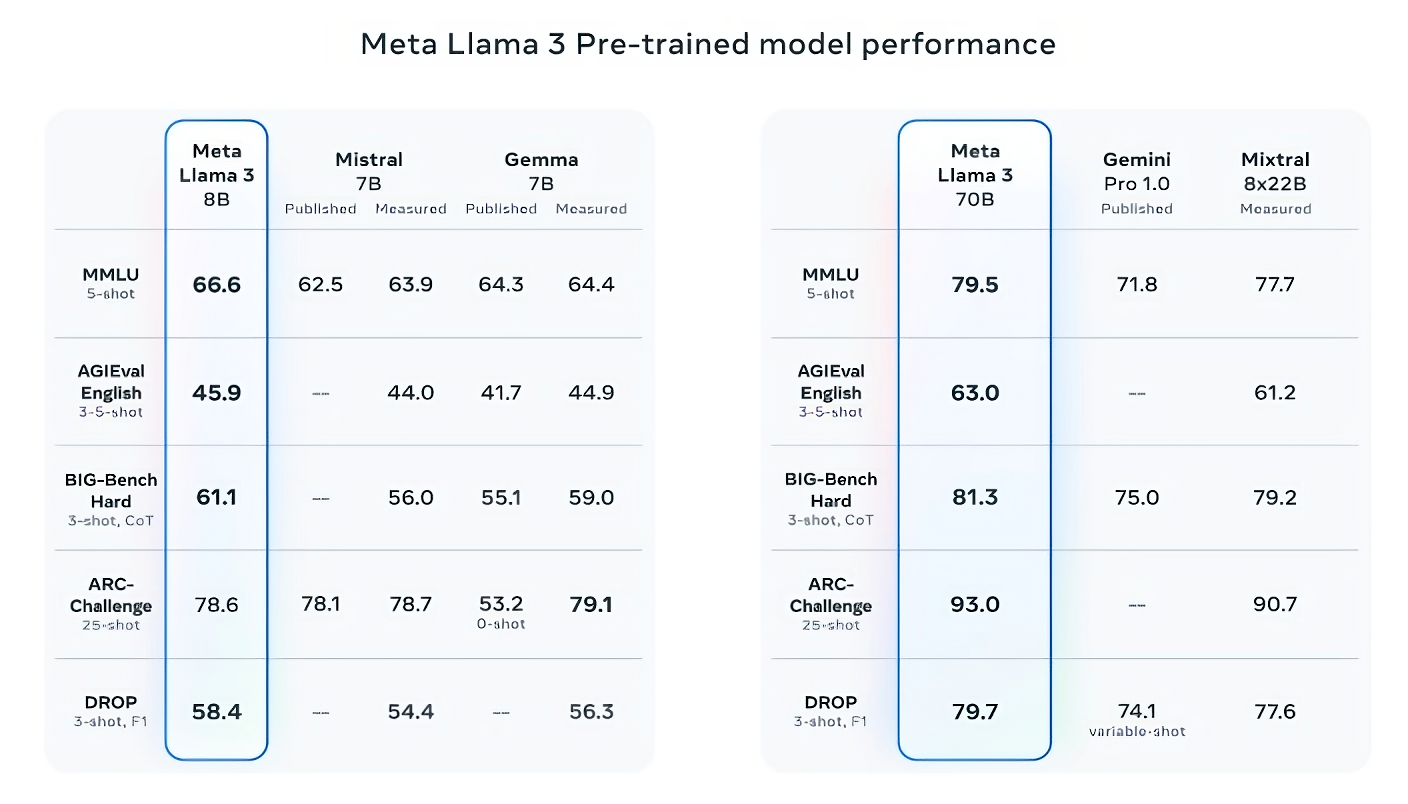
話說得很滿,那麼,Meta 公司是如何證明這一點的呢?該公司指出 Llama 3 模型在 MMLU(用於測量知識)、ARC(用於測量技能習得)和 DROP(用於測試模型對文本塊的推理能力)等流行的人工智能基準上的得分。正如我們之前所寫,這些基準的實用性和有效性還有待商榷。但無論好壞,它們仍然是 Meta 等人工智能玩傢評估其模型的少數標準化方法之一。
在至少九項基準測試中,Llama 3 8B 優於其他開源模型,如 Mistral 的Mistral 7B和 Google 的Gemma 7B,這兩個模型都包含 70 億個參數:這些基準包括:MMLU、ARC、DROP、GPQA(一組生物、物理和化學相關問題)、HumanEval(代碼生成測試)、GSM-8K(數學單詞問題)、MATH(另一種數學基準)、AGIEval(解決問題測試集)和 BIG-Bench Hard(常識推理評估)。
現在,Mistral 7B 和 Gemma 7B 並不完全處於最前沿(Mistral 7B 於去年 9 月發佈),在 Meta 引用的一些基準測試中,Llama 3 8B 的得分僅比這兩款產品高幾個百分點。但 Meta 還聲稱,參數數更多的 Llama 3 型號 Llama 3 70B 與旗艦生成式人工智能模型(包括Google Gemini 系列的最新產品 Gemini 1.5 Pro)相比也具有競爭力。
圖片來源:Meta
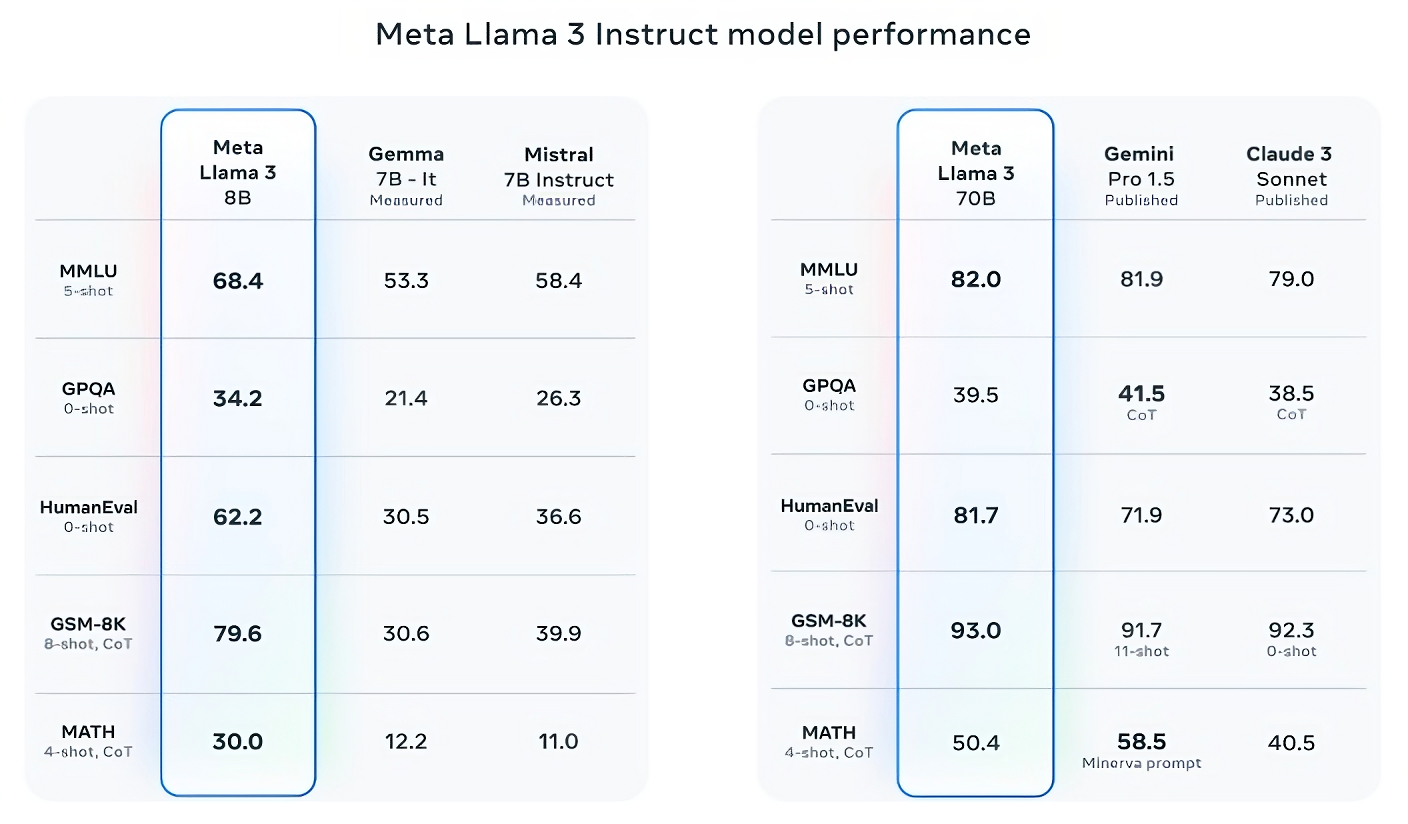
Llama 3 70B 在 MMLU、HumanEval 和 GSM-8K 三項基準測試中均優於 Gemini 1.5 Pro,而且,雖然它無法與 Anthropic 性能最強的 Claude 3 Opus 相媲美,但 Llama 3 70B 在五項基準測試(MMLU、GPQA、HumanEval、GSM-8K 和 MATH)中的得分均優於 Claude 3 系列中性能最弱的 Claude 3 Sonnet。
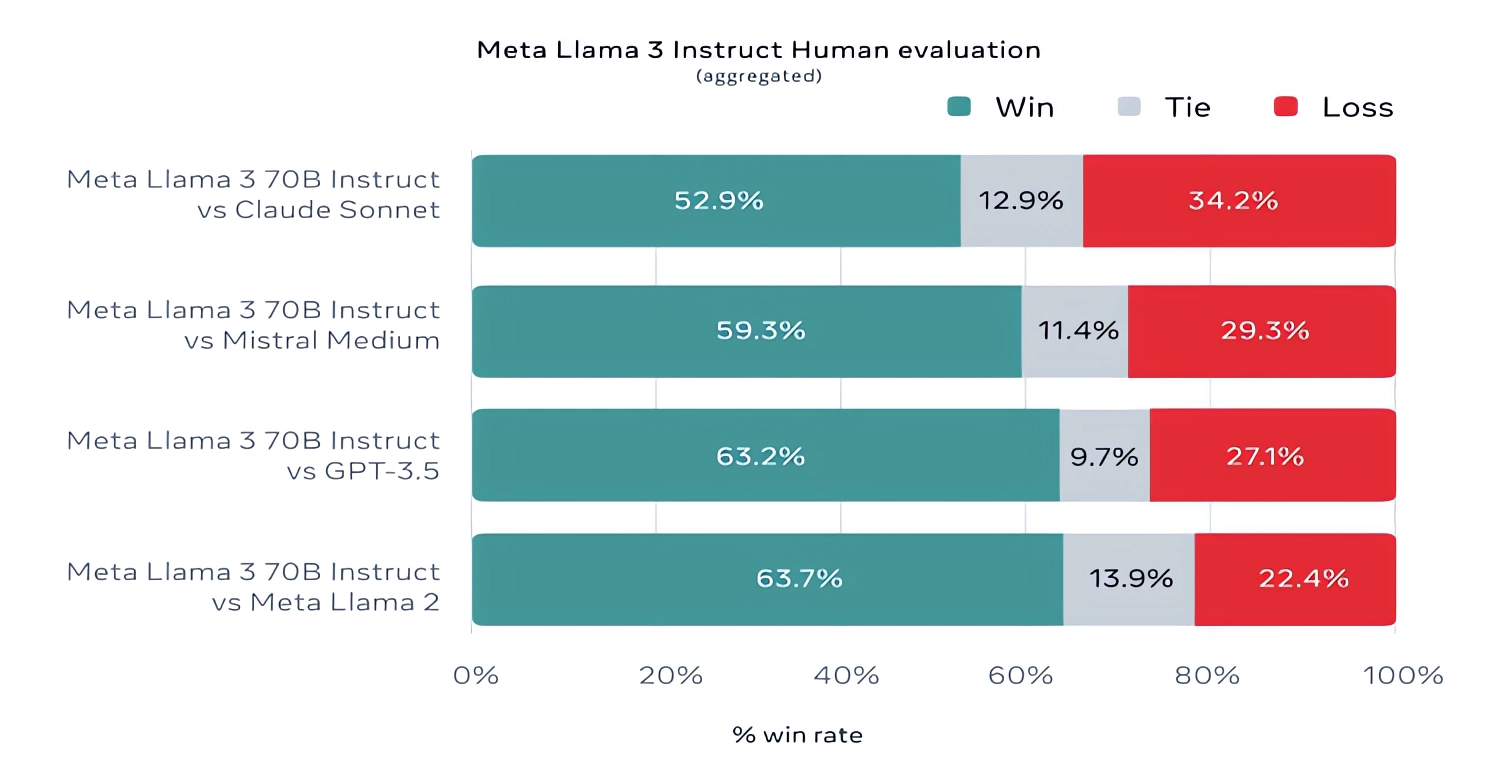
值得註意的是,Meta 還開發自己的測試集,涵蓋從編碼、創作到推理、總結等各種用例,令人驚喜的是,Llama 3 70B 在與 Mistral Medium 模型、OpenAI 的 GPT-3.5 和 Claude Sonnet 的競爭中脫穎而出!- Llama 3 70B 在與 Mistral 的 Mistral Medium 模型、OpenAI 的 GPT-3.5 和 Claude Sonnet 的競爭中脫穎而出。Meta 表示,為保持客觀性,它禁止其建模團隊訪問這組數據,但很明顯,鑒於 Meta 自己設計這項測試,我們必須對結果持謹慎態度。
在質量方面,Meta 表示,新 Llama 模型的用戶可以期待更高的"可操控性"、更低的拒絕回答問題的可能性,以及更高的瑣碎問題、與歷史和 STEM 領域(如工程和科學)相關的問題和一般編碼建議的準確性。這在一定程度上要歸功於一個更大的數據集:一個由 15 萬億個標記組成的集合,或者說一個令人難以置信的 750,000,000,000 單詞,是 Llama 2 訓練集的七倍。
這些數據從何而來?Meta 公司不願透露,隻表示數據來自"公開來源",包含的代碼數量是 Llama 2 訓練數據集的四倍,其中 5%包含非英語數據(約 30 種語言),以提高非英語語言的性能。Meta 還表示,它使用合成數據(即人工智能生成的數據)來創建較長的文檔,供 Llama 3 模型訓練使用,由於這種方法存在潛在的性能缺陷,因此頗受爭議。
Meta 在一篇博文中寫道:"雖然我們今天發佈的模型僅針對英語輸出進行微調,但數據多樣性的增加有助於模型更好地識別細微差別和模式,並在各種任務中表現出色。"
許多生成式人工智能供應商將訓練數據視為一種競爭優勢,因此對訓練數據和相關信息守口如瓶。但是,訓練數據的細節也是知識產權相關訴訟的潛在來源,這是另一個不願意透露太多信息的原因。最近的報道顯示,Meta 公司為追趕人工智能競爭對手的步伐,曾一度不顧公司律師的警告,將受版權保護的電子書用於人工智能訓練;包括喜劇演員莎拉-西爾弗曼(Sarah Silverman)在內的作者正在對 Meta 和 OpenAI 提起訴訟,指控這兩傢公司未經授權使用受版權保護的數據進行訓練。
那麼,生成式人工智能模型(包括 Llama 2)的另外兩個常見問題--毒性和偏差又是怎麼回事呢?Llama 3 是否在這些方面有所改進?Meta 聲稱:是的。
Meta 表示,公司開發新的數據過濾管道,以提高模型訓練數據的質量,並更新一對生成式人工智能安全套件 Llama Guard 和 CybersecEval,以防止 Llama 3 模型和其他模型的濫用和不必要的文本生成。該公司還發佈一款新工具 Code Shield,旨在檢測生成式人工智能模型中可能引入安全漏洞的代碼。
不過,過濾並非萬無一失,Llama Guard、CybersecEval 和 Code Shield 等工具也隻能做到這一步。我們需要進一步觀察 Llama 3 型號在實際運用時的表現如何,包括學術界對其他基準的測試。
Meta公司表示,Llama 3模型現在已經可以下載,並在Facebook、Instagram、WhatsApp、Messenger和網絡上為Meta公司的Meta人工智能助手提供支持,不久將以托管形式在各種雲平臺上托管,包括AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM的WatsonX、Microsoft Azure、NVIDIA的NIM和Snowflake。未來,還將提供針對 AMD、AWS、戴爾、英特爾、NVIDIA 和高通硬件優化的模型版本。
而且,功能更強大的型號即將問世。Meta 表示,它目前正在訓練的 Llama 3 模型參數超過 4000 億個--這些模型能夠"用多種語言交流"、接收更多數據、理解圖像和其他模式以及文本,這將使 Llama 3 系列與 Hugging Face 的Idefics2 等公開發佈的版本保持一致。
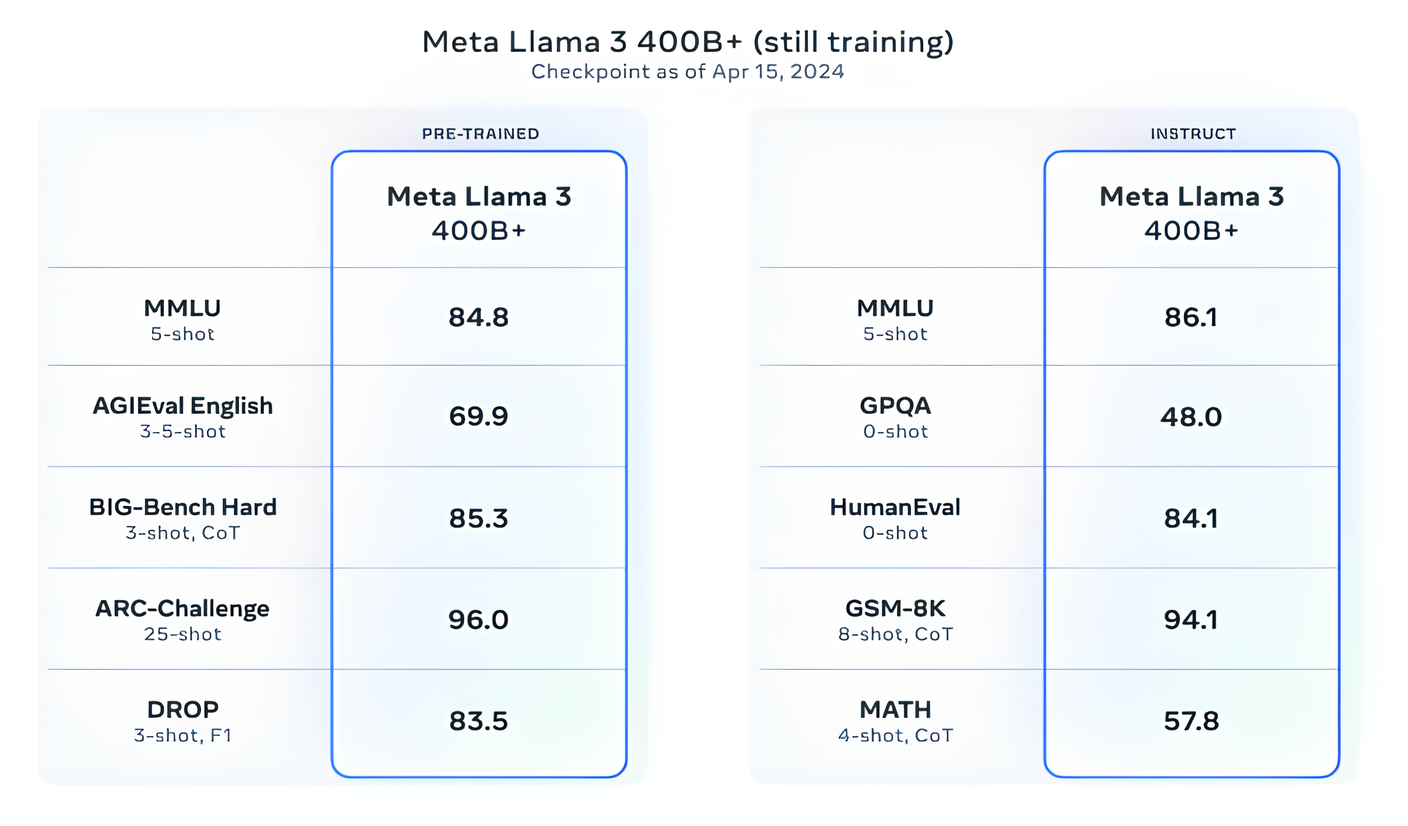
"我們近期的目標是讓 Llama 3 成為多語言、多模態、具有更長上下文的產品,並繼續提高推理和編碼等核心(大型語言模型)功能的整體性能,"Meta 在一篇博文中寫道。"還有很多事情要做"。