今天AI圈又迎來一件大事:Meta正式發佈他們迄今最強的新一代開源大語言模型Llama3。首批發佈的Llama38B和Llama370B包括預訓練和指令微調版本,8K上下文,在兩個24KGPU定制集群上使用15萬億tokens數據訓練而成,Meta稱它們分別是80億和700億參數上最好的模型。同時一個參數超過400B的“最大Llama3”也在訓練中,社區認為這個模型更恐怖,極有可能超過當前的閉源王
Llama3在各種行業基準測試中表現驚艷,廣泛支持各種場景。接下來幾個月,Meta將陸續引入新的功能,包括多語言對話、多模態、更長的上下文和更強整體核心性能,並將與社區分享研究論文。
紮克伯格和Meta首席AI科學傢Yann LeCun分別在Instagram和X宣佈這一消息。
網友們在評論區一片沸騰,馬斯克前排回應,不錯(有種淡淡的憂傷)。
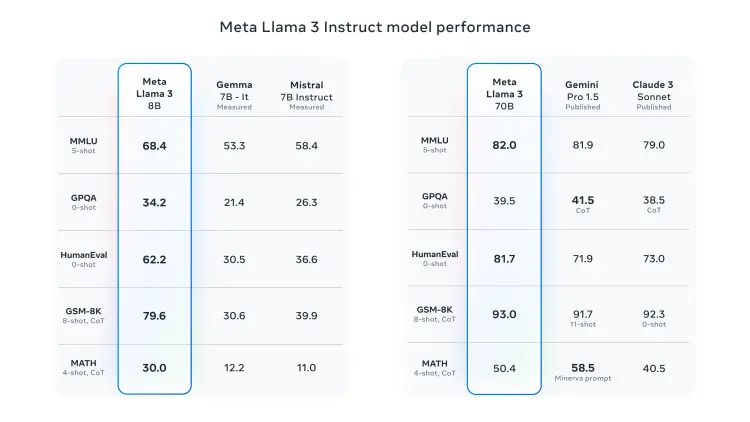
我們趕快來看看Llama 3的具體性能表現:
多項測試成績大幅超過Gemini 1.5和Claude Sonnet
Meta表示,新一代Llama3在Llama 2 的基礎上有重大飛躍,確立 LLM的新標準。在預訓練和後訓練過程上的改進大大降低錯誤拒絕率,提高一致性,並增加模型響應的多樣性。在推理、代碼生成和指令遵循等方面都得到極大改善,使得 Llama 3 更加可控。
對照表中可見,Llama3 8B在大規模多任務語言理解、生成式預訓練問題回答、編碼和數學等LLM核心基準測試上都力挫Gemma 7B和Mistral 7B。Llama3 70B同樣戰勝 Gemini Pro 1.5和此前被誇爆的Claude 3 Sonnet。
預訓練版本的Llama3 8B和70B也在通用智能評估、困難任務、ARC挑戰賽、DROP數據集上把Mitral 7B、Gemma 7B、Gemini Pro 1.0、新出的Mixtral 8x22B 打入手下敗將之列。

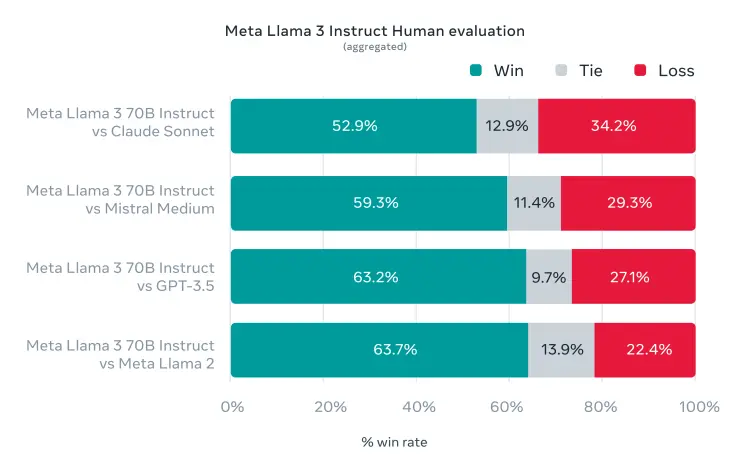
除關註LLM標準基準測試項目, Meta還尋求模型在現實場景中的性能優化。為此,他們開發一套新的高質量人工評估集。包含 1800 個提示,涵蓋“尋求建議、頭腦風暴、分類、封閉式問題回答、編碼、創意寫作、提取、模擬角色/人物、開放式問題回答、推理、重寫和總結” 這12 個關鍵用例。為防止發生意外過擬合,即使是 Meta自己的建模團隊也無法訪問它。
在這套評估集上, Llama3 70B與Claude Sonnet、Mistral Medium、GPT-3.5 和上一代Llama2對戰後勝率突出。(這裡沒有把GPT-4和Claude 3 Opus拉來對比,推測後續的400B模型將接過重任。)
Llama 3有哪些技術創新
Meta稱,在Llama3的開發過程中秉承創新、擴展規模和優化簡潔性的設計理念。重點關註四個關鍵要素:模型架構、預訓練數據、擴大預訓練規模以及指令微調。下面分項來看:
模型架構
Llama 3 選擇一個相對標準的純解碼器 Transformer 架構。
相比 Llama 2 的改進之處有:Llama 3 使用一個包含 128K tokens的分詞器,可以更有效地編碼語言,從而顯著提高模型性能;在 8B 和 70B 兩種規模上都采用分組查詢註意力(GQA)機制來提高模型推理效率;同時在 8192 個tokens的序列上訓練模型,使用掩碼確保自註意力不會跨越文檔邊界。
訓練數據
Meta認為訓練出最佳LLM的關鍵是要整理一個大型高質量訓練數據集,為此他們投入大量資源:
Llama 3 在超過 15 萬億個公開可用來源的token上進行預訓練,比訓練 Llama 2 時的數據集足足大 7 倍,代碼量是 Llama 2 的 4 倍。其中超過 5% 來自高質量非英語數據,總共涵蓋 30 多種語言,以為即將到來的多語言使用場景做準備。
Llama3團隊開發一系列數據過濾管道來保證數據質量。他們還進行大量實驗,來評估在最終預訓練數據集中混合不同來源數據的最佳方式,以此來選擇一個包括STEM、編碼、歷史知識等等數據類別的最優數據組合,確保 Llama 3 在各種使用場景中表現良好。
擴大預訓練規模
為更有效利用預訓練數據,Meta針對下遊基準評估開發一系列詳細的擴展法則,在實際訓練模型之前就能預測最大模型在關鍵任務上的性能,來確保最終模型在各種使用場景和能力上都有出色的表現。
在 Llama 3 的開發過程中,團隊也對擴展行為有一些新的觀察。例如,盡管一個 8B 參數模型對應的最佳訓練計算量是 200B個 tokens,但他們的 8B 和 70B 參數模型在接受高達 15 萬億個token訓練後,性能仍然呈對數線性提高。
Meta結合三種並行化方式:數據並行、模型並行和管道並行,來訓練最大的Llama3模型。最高效地實現在同時使用 16K 個 GPU 訓練時,每個 GPU 的計算利用率超過 400 TFLOPS。他們還開發一個先進的新訓練堆棧,可以自動進行錯誤檢測、處理和維護,並進行一系列硬件和可擴展存儲系統的改進。最終使總體有效訓練時間超過 95%,與 Llama 2 相比訓練效率提升約 3 倍。
指令微調方法創新
為在聊天場景中充分釋放預訓練模型的潛力,Meta也在指令微調方法上進行創新。後訓練方法采用監督微調(SFT)、拒絕采樣、鄰近策略優化(PPO)和直接策略優化(DPO)的組合。在模型質量上的最大改進來自於仔細整理的訓練數據,並對人工標註人員提供的標註進行多輪質量保證。
通過 PPO 和 DPO 從偏好排序中學習,也大大提高 Llama 3 在推理和編碼任務上的性能。團隊發現,當你問模型一個它難以回答的推理問題時,模型會產生正確的推理軌跡:知道如何得出正確答案,但不知道如何選擇它。通過在偏好排序上進行訓練,模型就能學會如何去選擇正確答案。
哪裡可以用到
根據官方介紹,Llama 3 將很快在所有主要平臺上可用,包括雲服務商、API 提供商等。從AWS、Google Cloud、Databricks、Snowflake 、NVIDIA NIM到Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure——Llama 3 將無處不在。它也得到 AMD、AWS、Dell、Intel、NVIDIA 和 Qualcomm 提供的硬件平臺支持。
對於普通用戶來說,最方便直接感受Llama3的方式就是通過 Meta AI。
除在WhatsApp、Messenger、Instagram、Facebook等應用與Meta AI聊天助手對話外,今天還推出網頁版https://www.meta.ai/。即開即用,可以輸入文本提問來生成圖片和簡單代碼,支持實時搜索,其它功能還不是很完善。如果想存儲歷史記錄則需登錄Facebook賬號。
真正的“GPT-4級”開源模型就在眼前
而Meta透露,Llama 3 8B 和 70B 隻是 Llama 3 系列的開始,更多令人期待的東西即將到來。
一個超過 400B 參數的最大模型正在訓練中,開發團隊對此感到興奮。未來幾個月,Meta將發佈多個新功能,包括多模態、多語言對話能力、更長的上下文窗口以及更強大的整體能力。一旦完成所有Llama 3 的訓練,他們也會發表一篇詳細的研究論文供社區參考。
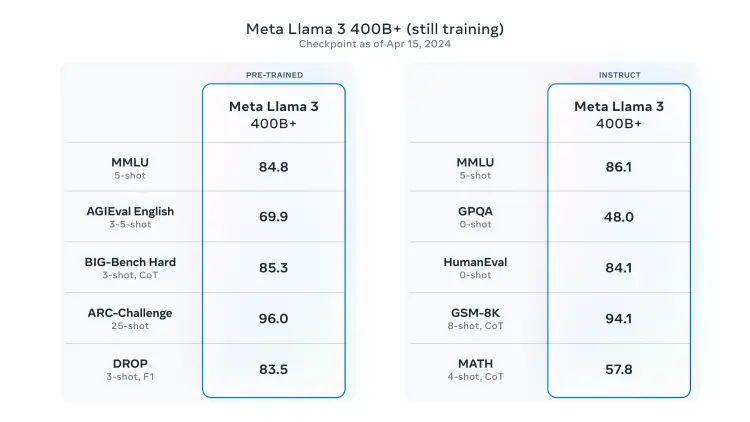
Llama3 8B和70B,加上一個證實正在訓練的400B大模型,無疑向開源社區註入一支超強興奮劑。

而不久後即將發佈的Llama3 400B+會有多厲害?
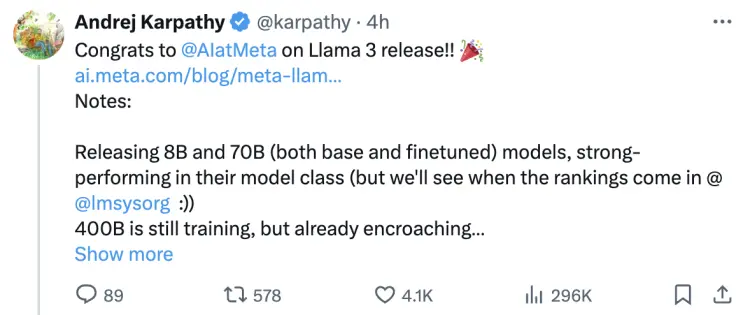
大神卡帕西給予很高評價:“Llama 3 是 Meta 一個看起來非常強大的模型。堅持基本原則,在可靠的系統和數據工作上花費大量高質量時間,探索長期訓練模型的極限。我也對 400B 模型非常興奮,它可能是第一個 GPT-4 級別的開源模型。我想很多人會要求更長的上下文長度。”
同時他也提出個人請求,希望能有比 8B 更小參數,理想規模在0.1B到1B左右的模型,用於教育工作、(單元)測試、嵌入式應用等。
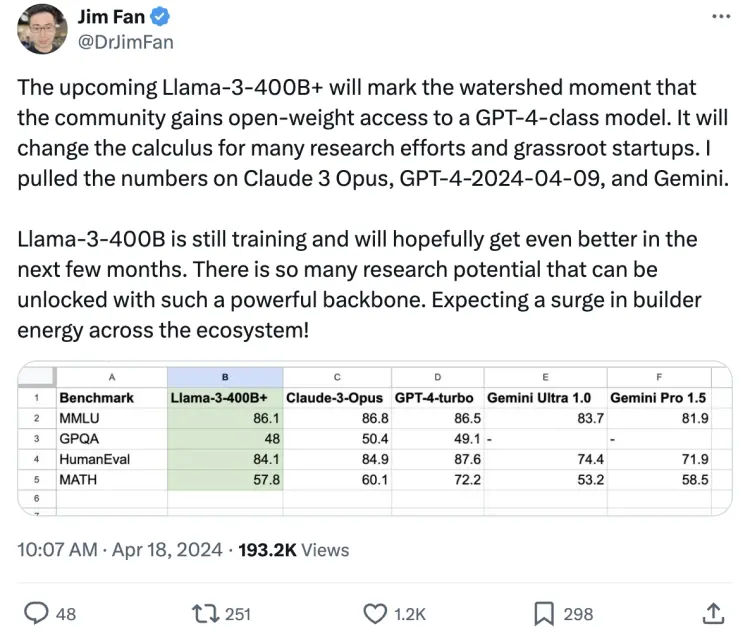
英偉達高級研究經理Jim Fan認為,它將標志著社區獲得對“GPT-4級別模型”開放權重訪問的分水嶺時刻,這將改變許多研究工作和草根創業公司的計算方法。
從當前預測數據來看,Llama3 400B+已經足以匹敵市場上最強大的Claude 3 Opus和GPT-4。而Llama-3-400B仍在訓練中,有望在接下來的幾個月中變得更好。“有如此強大的基礎設施,可以解鎖很多研究潛力。期待整個生態系統的建設者能量激增!”
一個讓所有人必須考慮的事實就是:開源模型追上閉源模型的歷史時刻可能就在眼前。
這對開發者可能意味著,AI應用可以更加快速的湧現和迭代出來。
而對創業公司們來說,則意味著更徹底的思路上的沖擊。
它直接影響到所有以閉源模型 API 為核心的商業模式——既然免費的足夠好用,為什麼還要花錢呢?
更重要的是,如果連OpenAI、Google和Anthropic神秘的工具箱都不再高不可攀,那做一個比不上開源最強水平的閉源模型的意義何在呢。
最後還是不得不問一句:GPT-5,你到底在哪裡呢?