剛剛,我們經歷LLM劃時代的一夜。Google又在深夜發炸彈,GeminiUltra發佈還沒幾天,Gemini1.5就來。卯足勁和OpenAI微軟一較高下的Google,開始進入高產模式。自傢最強的Gemini1.0Ultra才發佈沒幾天,Google又放大招。
就在剛剛,GoogleDeepMind首席科學傢Jeff Dean,以及聯創兼CEO的Demis Hassabis激動地宣佈最新一代多模態大模型——Gemini 1.5系列的誕生。
其中,最高可支持10,000K token超長上下文的Gemini 1.5 Pro,也是Google最強的MoE大模型。
不難想象,在百萬級token上下文的加持下,我們可以更加輕易地與數十萬字的超長文檔、擁有數百個文件的數十萬行代碼庫、一部完整的電影等等進行交互。


同時,為介紹這款劃時代的模型,Google還發佈長達58頁的技術報告。

論文地址:https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
毫不誇張地說,大語言模型領域從此將進入一個全新的時代!
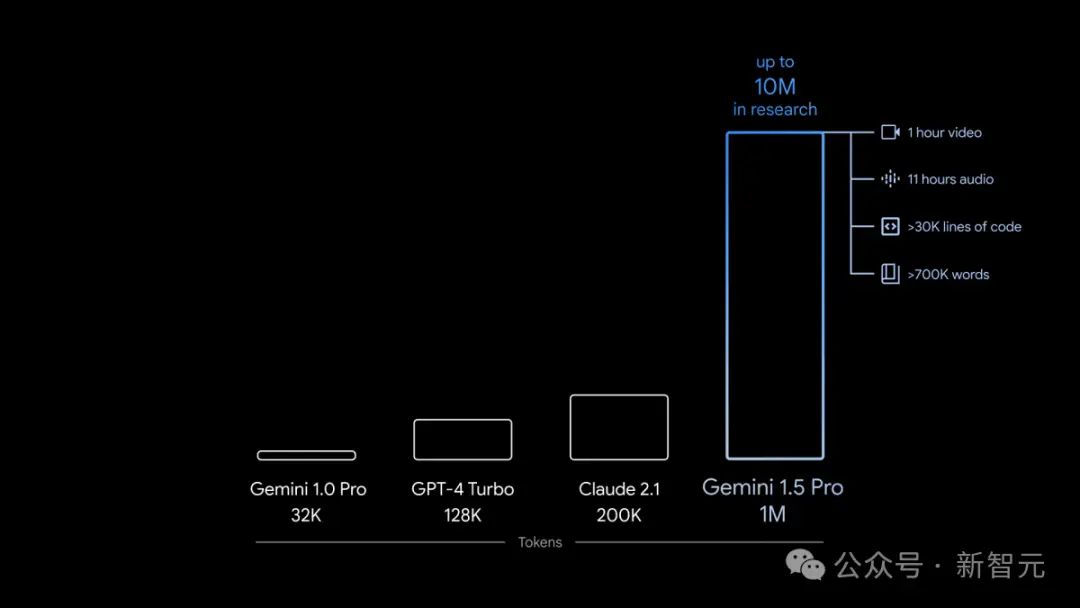
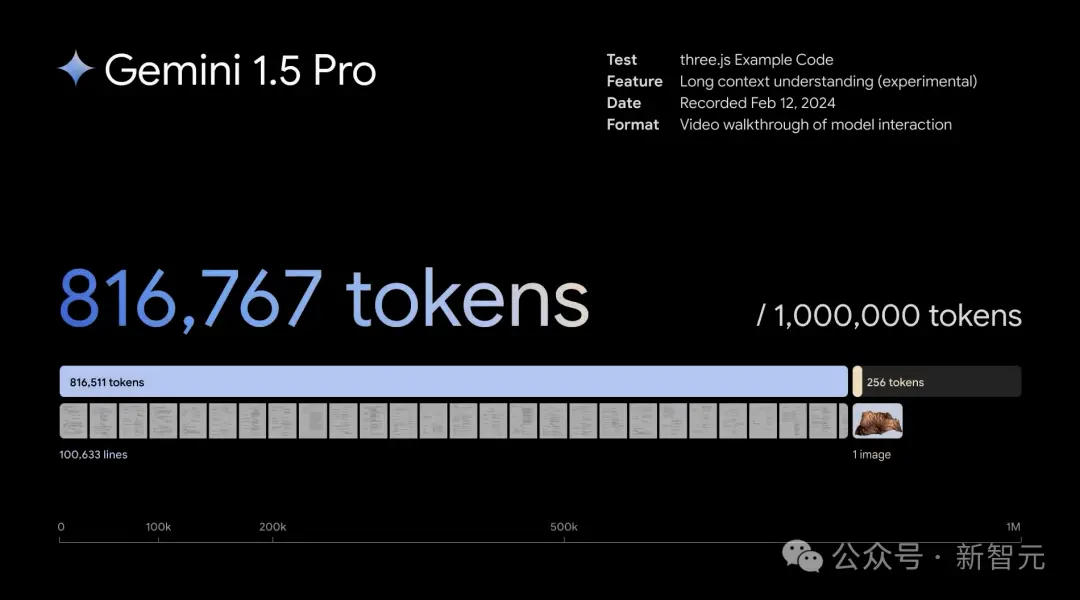
1,000,000 token超超超長上下文,全面碾壓GPT-4 Turbo
在上下文窗口方面,此前的SOTA模型已經“卷”到200K token(20萬)。
如今,Google成功將這個數字大幅提升——能夠穩定處理高達100萬token(極限為1000萬token),創下最長上下文窗口的紀錄。
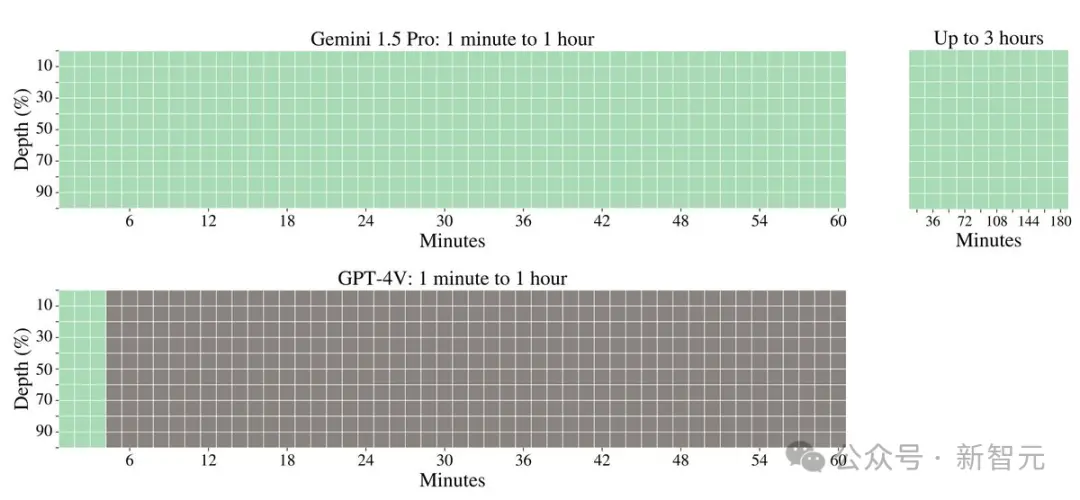
1000萬token極限海底撈針幾乎全綠
首先,我們看看Gemini 1.5 Pro在多模態海底撈針測試中的成績。
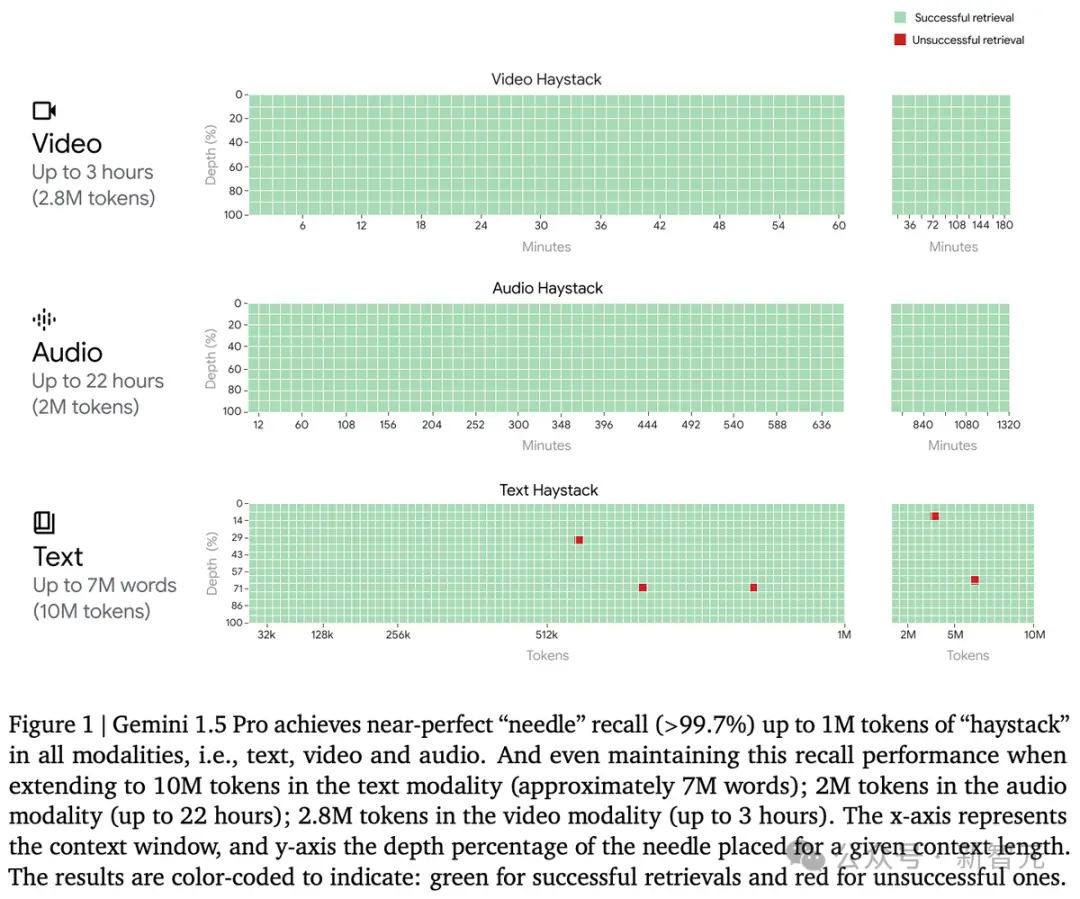
對於文本處理,Gemini 1.5 Pro在處理高達530,000 token的文本時,能夠實現100%的檢索完整性,在處理1,000,000 token的文本時達到99.7%的檢索完整性。
甚至在處理高達10,000,000 token的文本時,檢索準確性仍然高達99.2%。
在音頻處理方面,Gemini 1.5 Pro能夠在大約11小時的音頻資料中,100%成功檢索到各種隱藏的音頻片段。
在視頻處理方面,Gemini 1.5 Pro能夠在大約3小時的視頻內容中,100%成功檢索到各種隱藏的視覺元素。
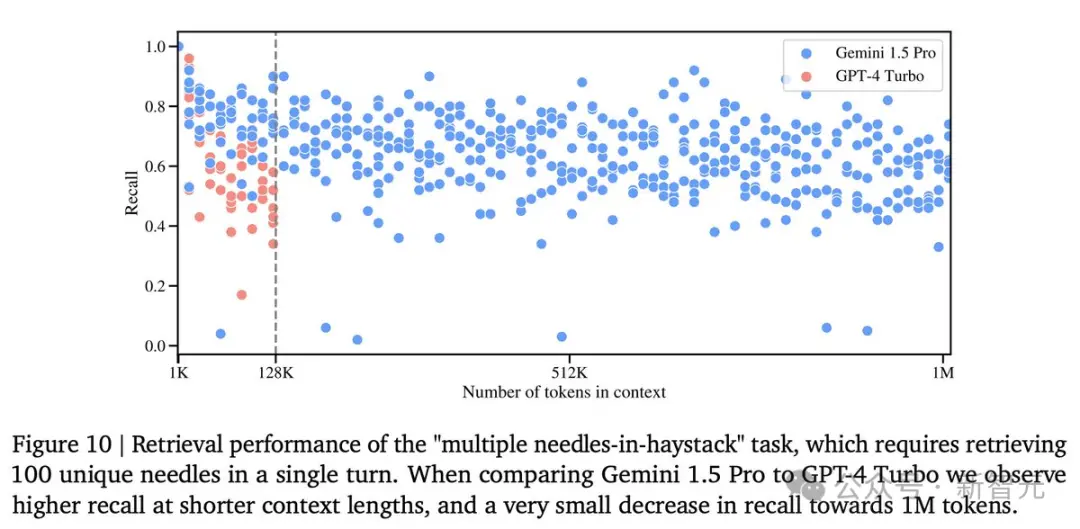
此外,Google研究人員還開發一個更通用的版本的“大海撈針”測試。
在這個測試中,模型需要在一定的文本范圍內檢索到100個不同的特定信息片段。
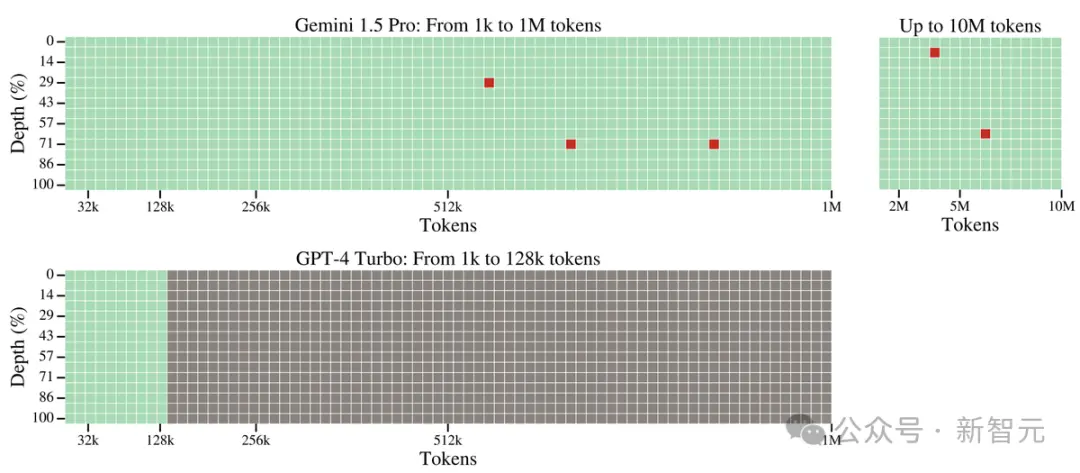
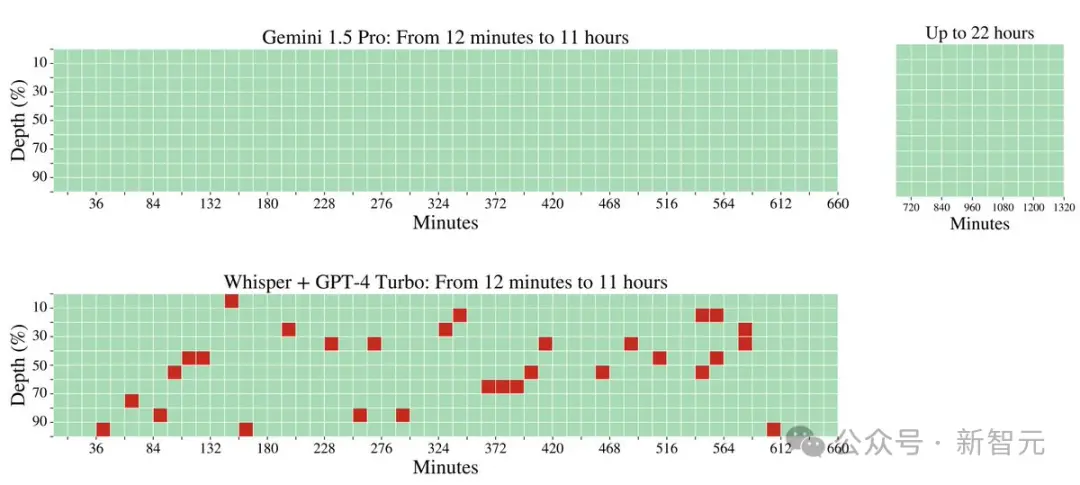
在這個測試中,Gemini 1.5 Pro在較短的文本長度上的性能超過GPT-4-Turbo,並且在整個100萬token的范圍內保持相對穩定的表現。
與之對比鮮明的是,GPT-4 Turbo的性能則飛速下降,且無法處理超過128,000 token的文本,表現慘烈。
大模型視野,被“史詩級”拓寬
LLM發展到這個階段,模型的上下文窗口已經成為關鍵的掣肘。
模型的上下文窗口由許多token組成,它們是處理單詞、圖像、視頻、音頻、代碼這些信息的基礎構建。
模型的上下文窗口越大,它處理給定提示時能夠接納的信息就越多——這就使得它的輸出更加連貫、相關和實用。
而這次,Google通過一系列機器學習的創新,大幅提升1.5 Pro的上下文窗口容量,從Gemini 1.0的原始32,000 token,直接提升到驚人的1,000,000 token。
這就意味著,1.5 Pro能夠一次性處理海量信息——比如1小時的視頻、11小時的音頻、超過30,000行的代碼庫,或是超過700,000個單詞。
甚至,Google曾經一度成功測試高達10,000,000的token。
深入理解海量信息
脫胎換骨的Gemini 1.5 Pro,已經可以輕松地分析給定提示中的海量內容!
它能夠洞察文檔中的對話、事件和細節,展現出對復雜信息的深刻理解。

我們甩給它一份阿波羅11號任務到月球的402頁飛行記錄,它對於多復雜的信息,都能表現出深刻的理解。
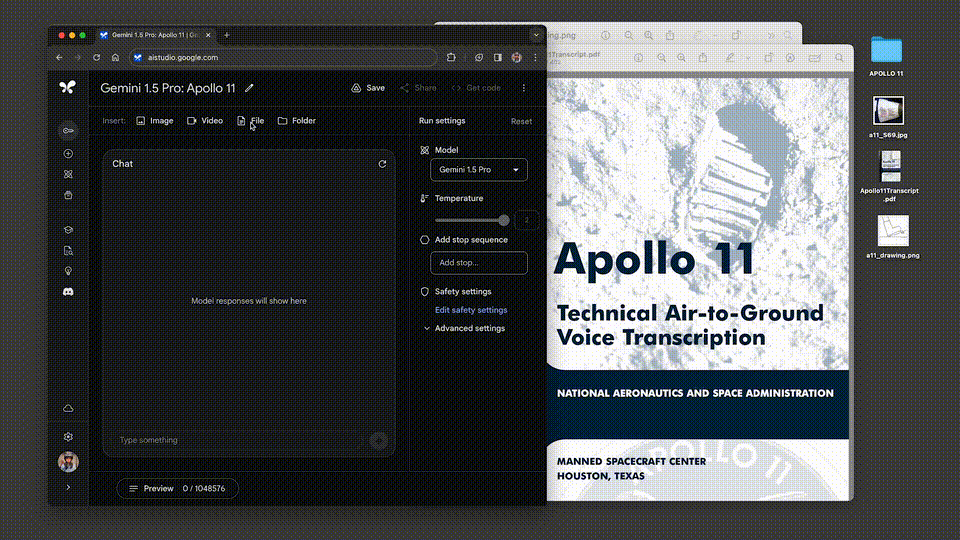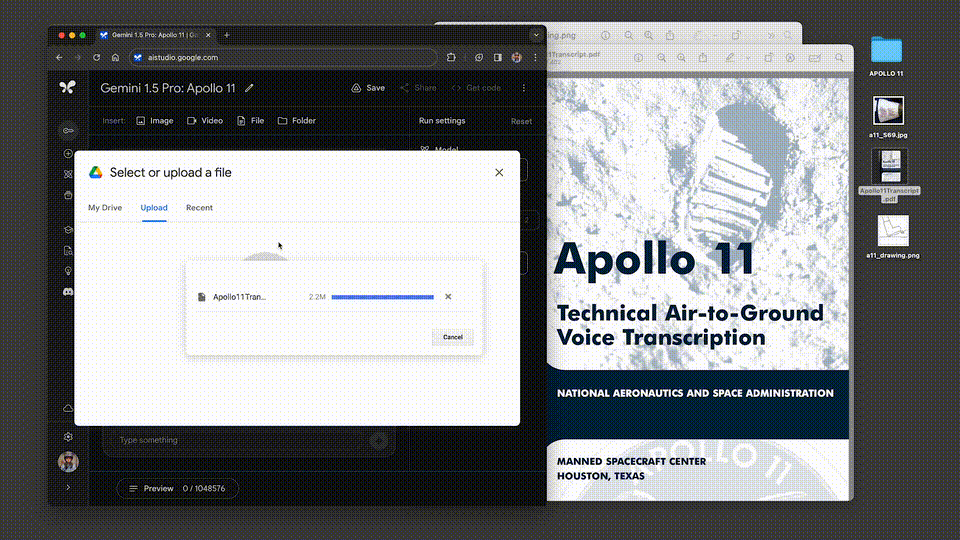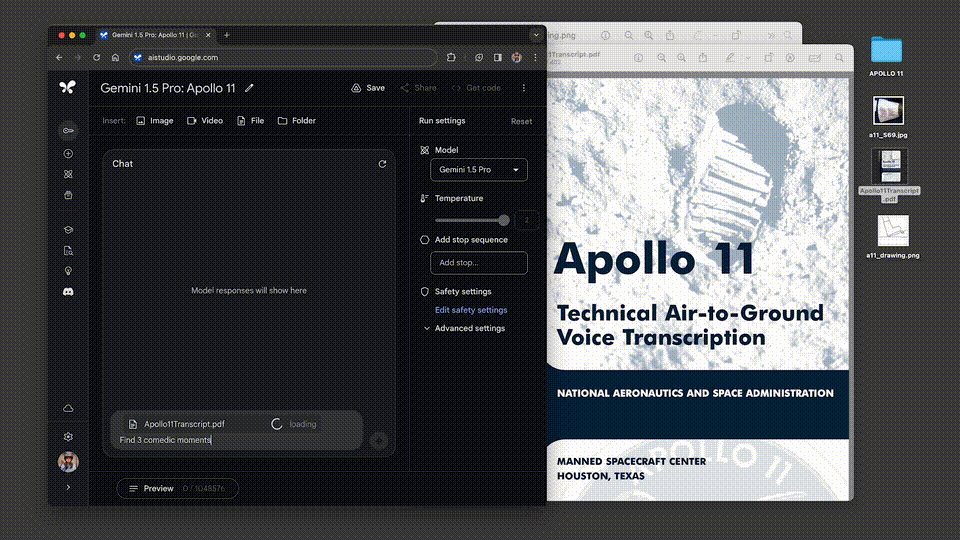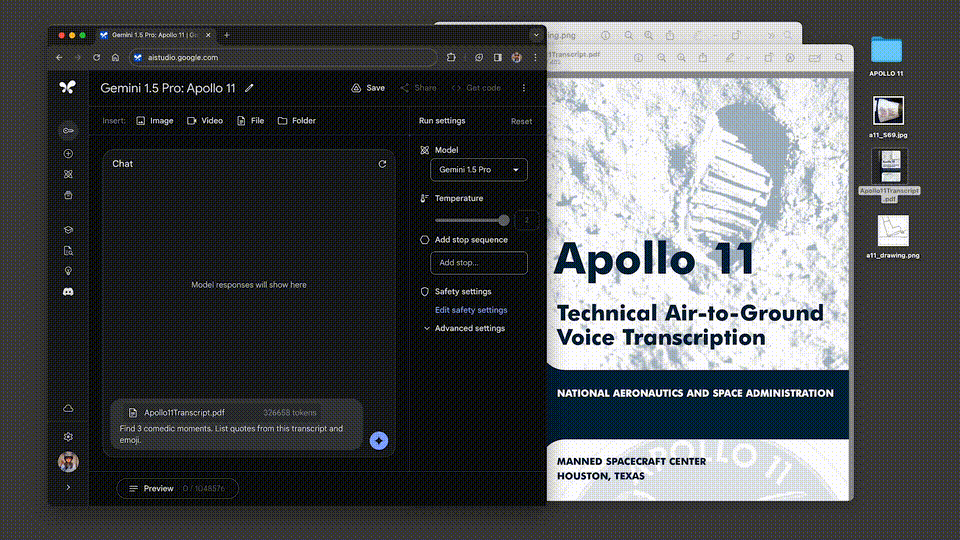
讓它從文件中列舉出3個喜劇性的時刻,接下來,就是見證奇跡的時刻——
才過30秒出頭,答案就已經生成!
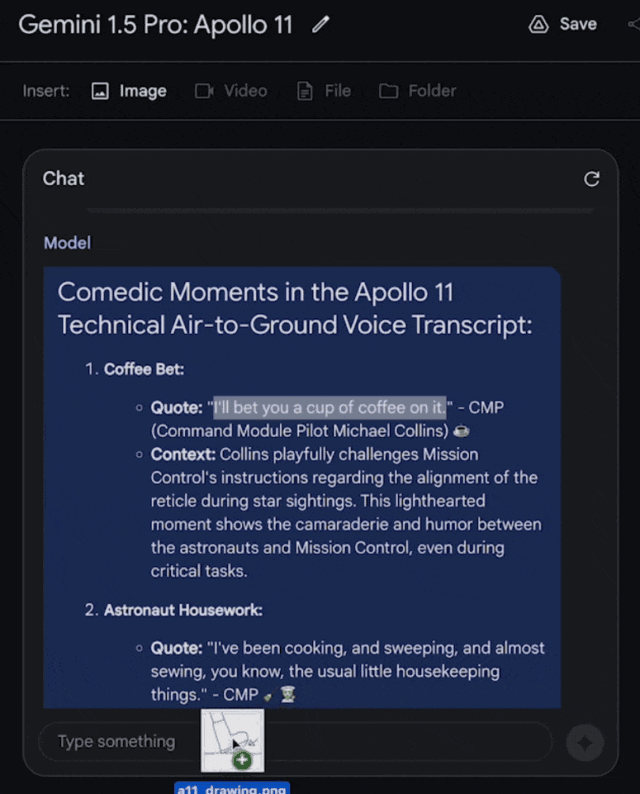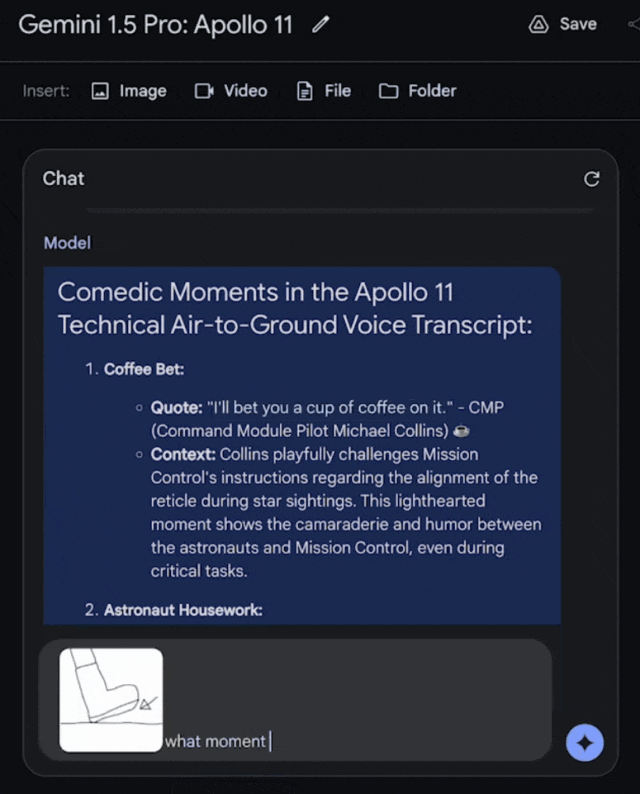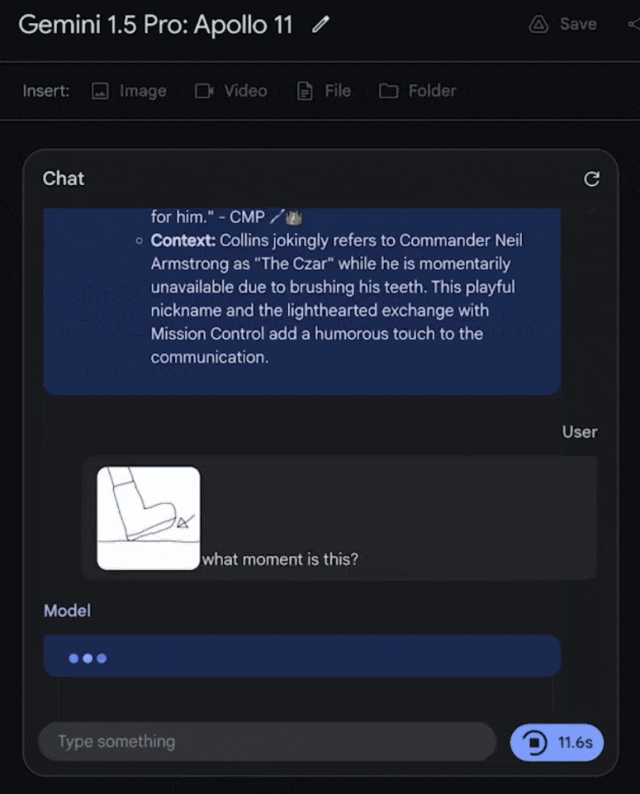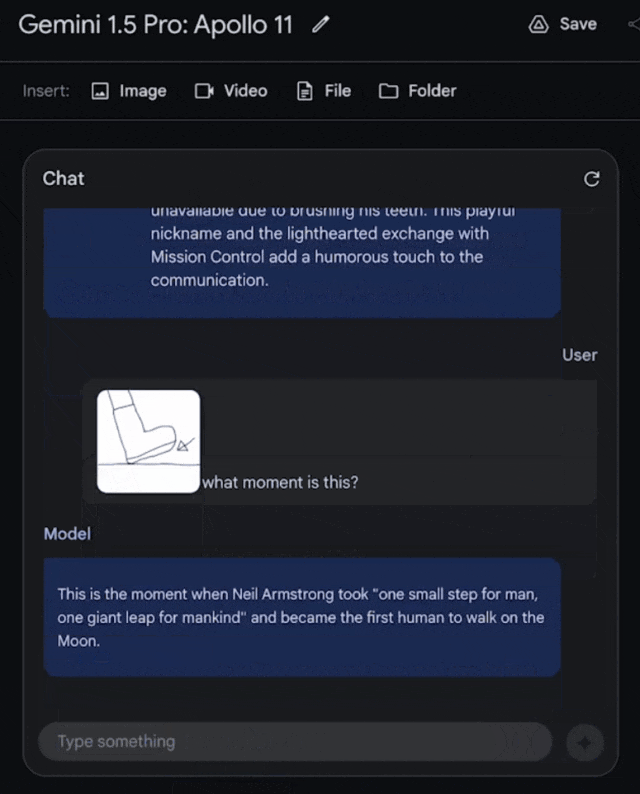
接下來,看看它的多模態功能。
把這張圖輸入進去,問它:這是什麼時刻?
它會回答,這是阿姆斯特朗邁上月球的一小步,也是人類的一大步。
這次,Google還新增一個功能,允許開發者上傳多個文件(比如PDF),並提出問題。
更大的上下文窗口,就讓模型能夠處理更多信息,從而讓輸出結果更加一致、相關且實用。
橫跨各種不同媒介
與此同時,Gemini 1.5 Pro還能夠在視頻中展現出深度的理解和推理能力!
得益於Gemini的多模態能力,上傳的視頻會被拆分成數千個畫面(不包括音頻),以便執行復雜的推理和問題解決任務。
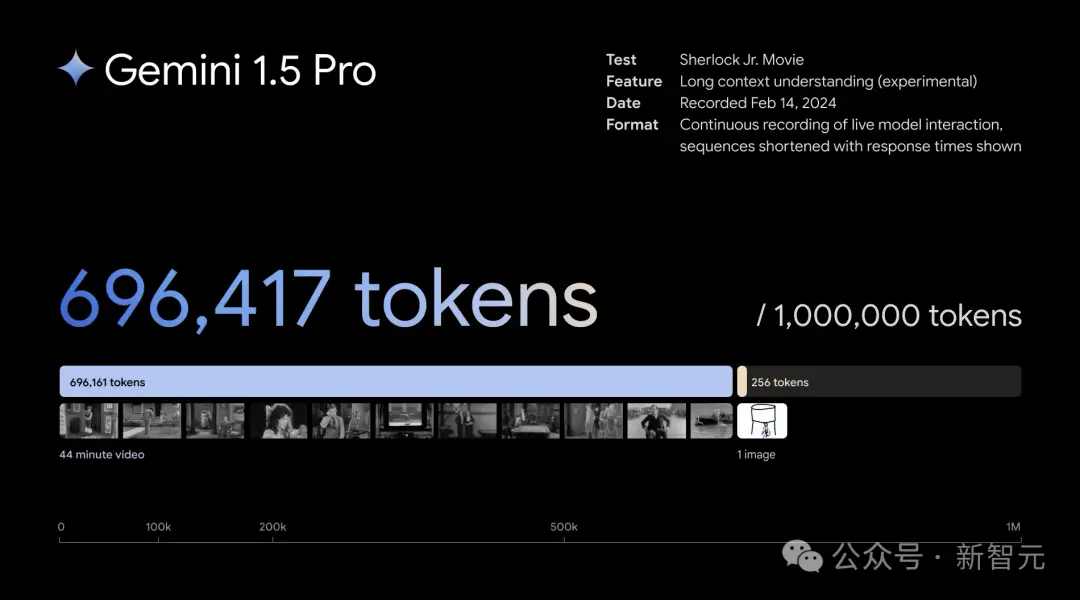
比如,輸入這部44分鐘的無聲電影——Buster Keaton主演的經典之作《小神探夏洛克》。
模型不僅能夠精準地捕捉到電影的各個情節和發展,還能洞察到極易被忽略的細微之處。
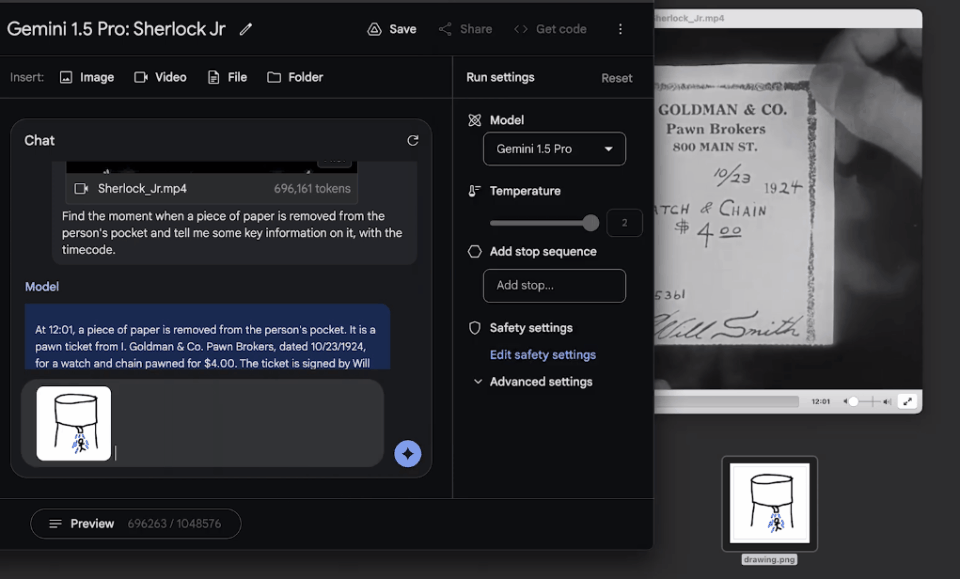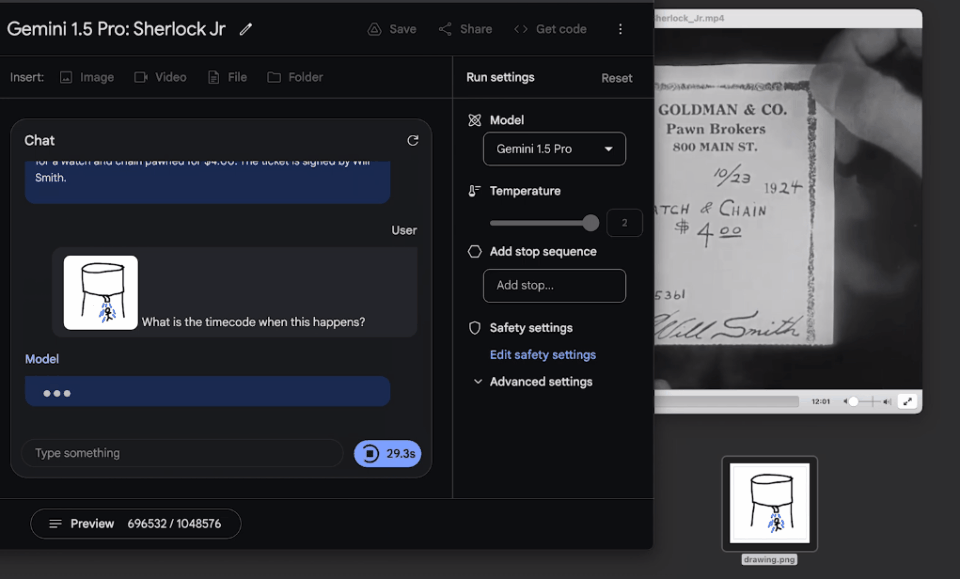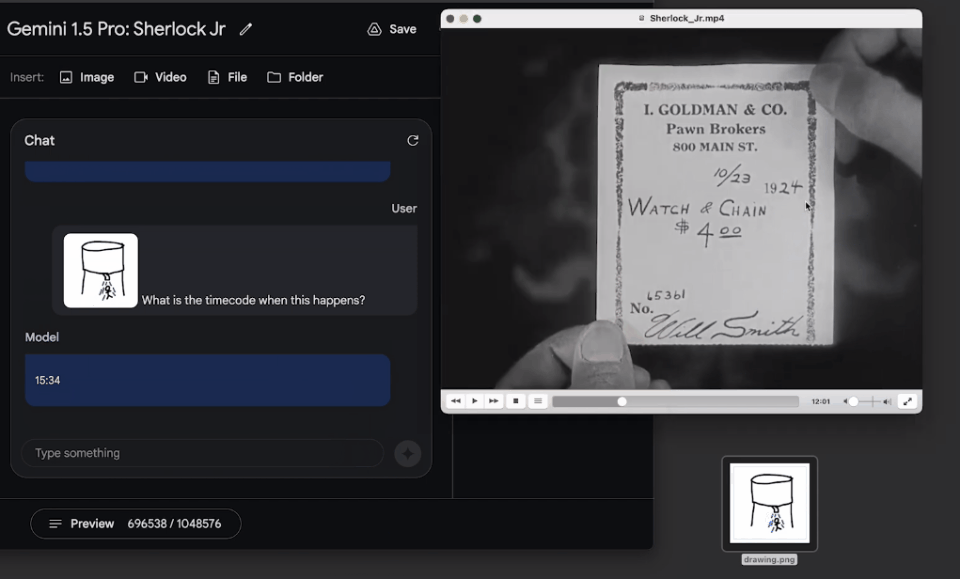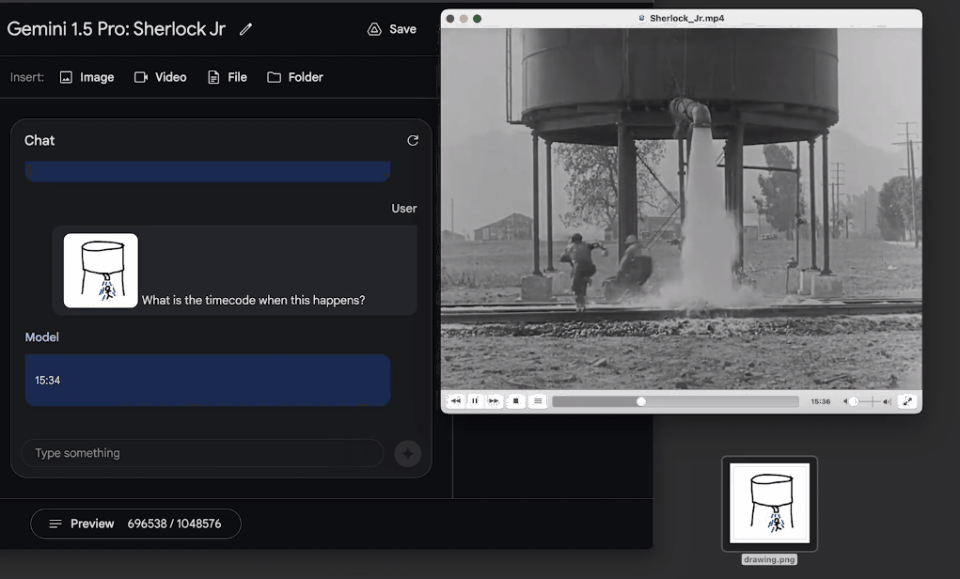
我們可以問它:找到一張紙從主角口袋中被拿出的瞬間,然後告訴我關於這個細節的信息。
令人驚喜的是,模型大約用60秒左右就準確地找出,這個鏡頭是在電影的12:01,還描述出相關細節。
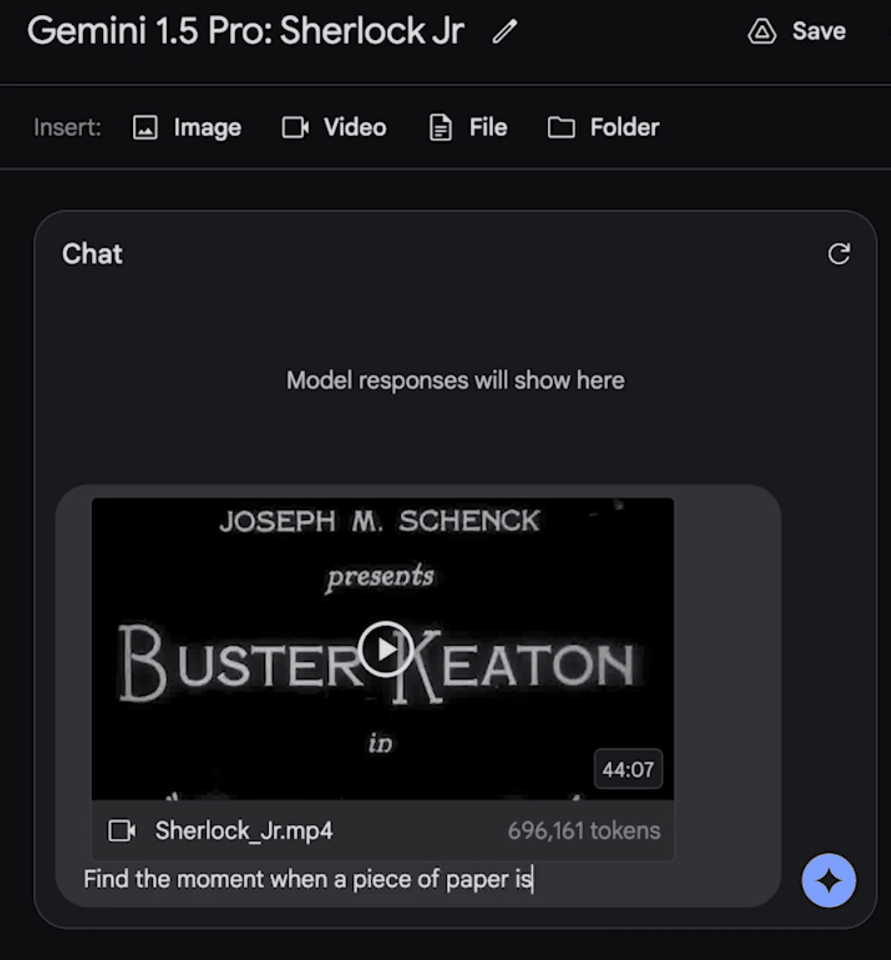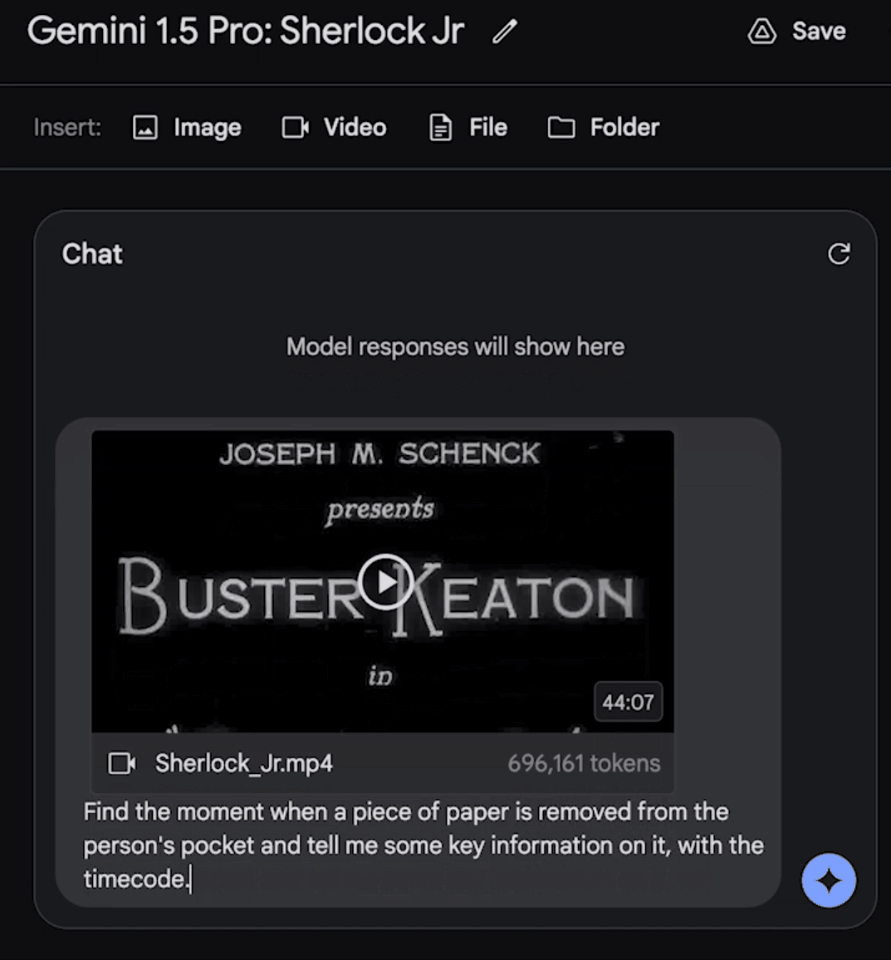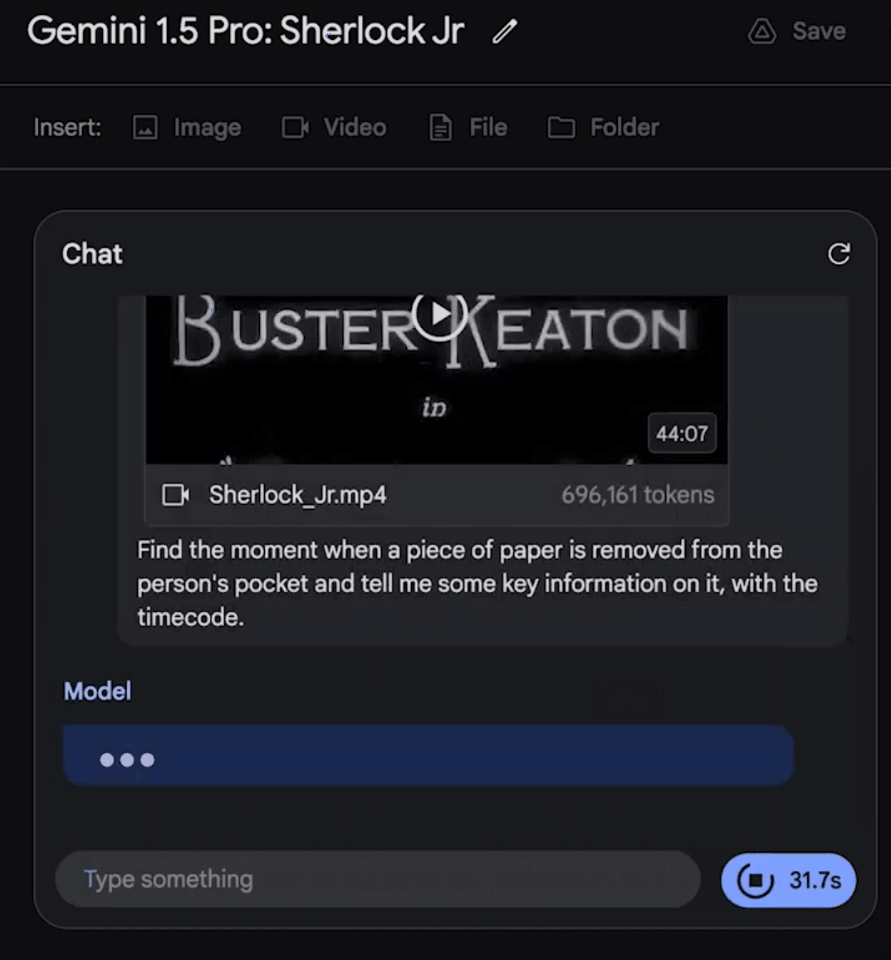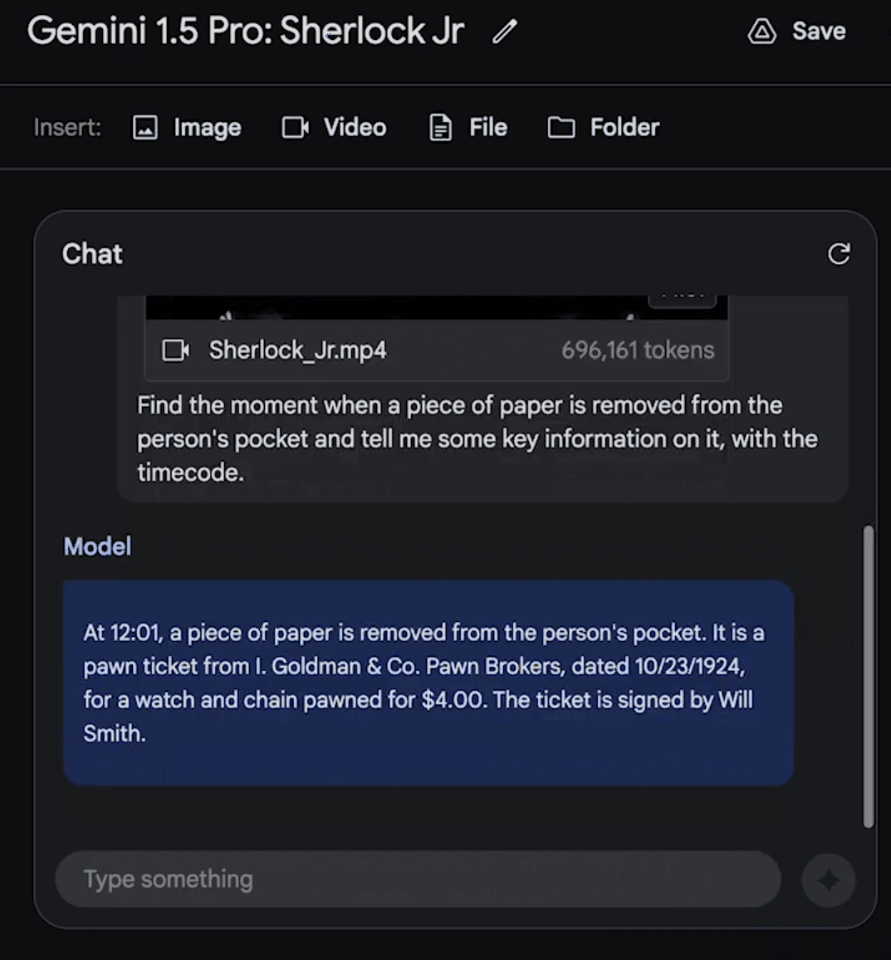
果然,模型精準找出這個鏡頭的時間點,所述細節也完全準確!

輸入一張粗略的塗鴉,要求模型找到電影中的對應場景,模型也在一分鐘內找到答案。
高效處理更長代碼
不僅如此,Gemini 1.5 Pro在處理長達超過100,000行的代碼時,還具備極強的問題解決能力。
面對如此龐大的代碼量,它不僅能夠深入分析各個示例,提出實用的修改建議,還能詳細解釋代碼的各個部分是如何協同工作的。
開發者可以直接上傳新的代碼庫,利用這個模型快速熟悉、理解代碼結構。
高效架構的秘密:MoE
Gemini 1.5的設計,基於的是Google在Transformer和混合專傢(MoE)架構方面的前沿研究。
不同於傳統的作為一個龐大的神經網絡運行的Transformer,MoE模型由眾多小型的“專傢”神經網絡組成。
這些模型可以根據不同的輸入類型,學會僅激活最相關的專傢網絡路徑。
這樣的專門化,就使得模型效率大幅提升。
而Google通過Sparsely-Gated MoE、GShard-Transformer、Switch-Transformer、M4研究,早已成為深度學習領域中MoE技術的領航者。
Gemini 1.5的架構創新帶來的,不僅僅是更迅速地掌握復雜任務、保持高質量輸出,在訓練和部署上也變得更加高效。
因此,團隊才能以驚人的速度,不斷迭代和推出更先進的Gemini版本。
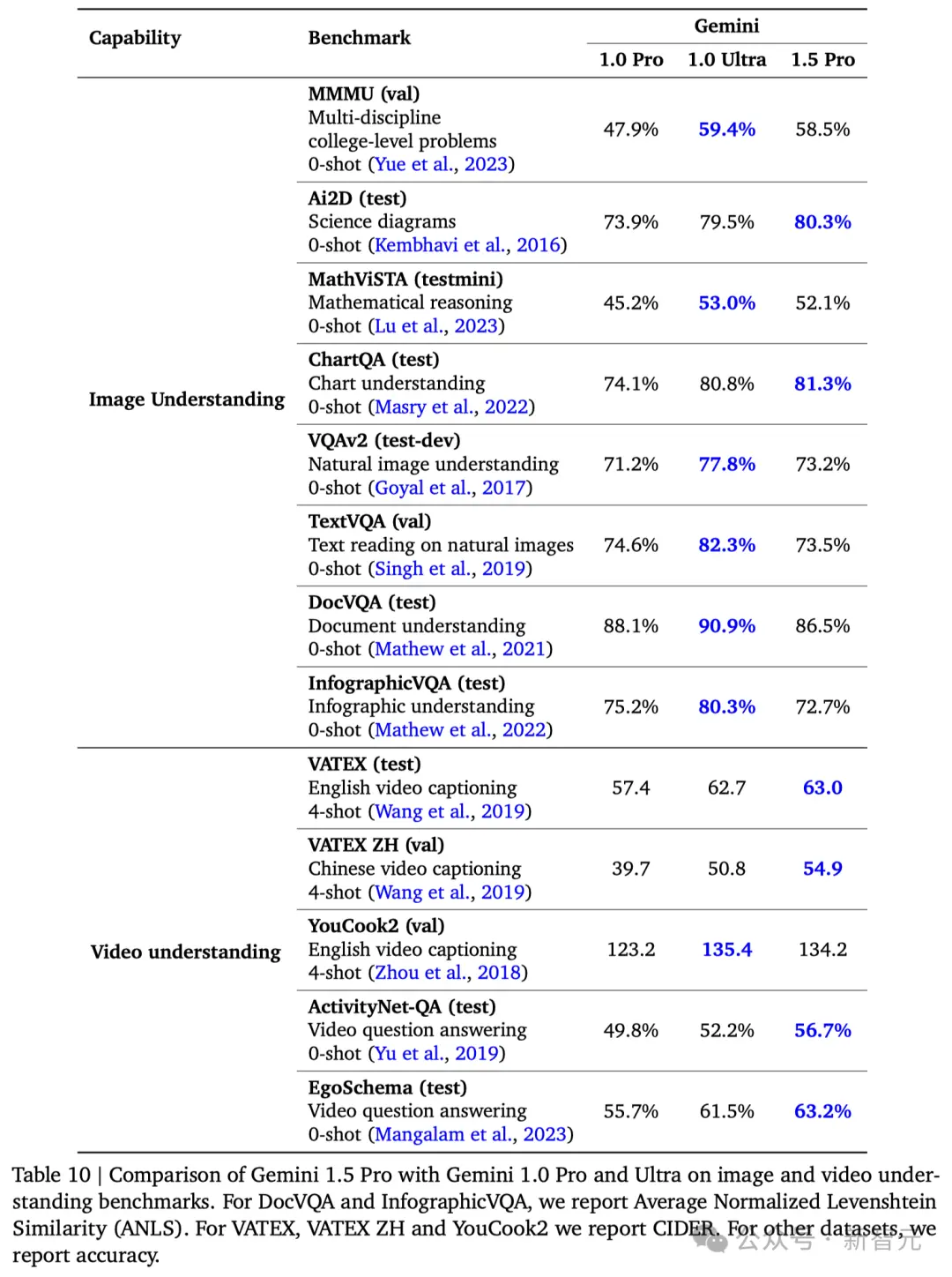
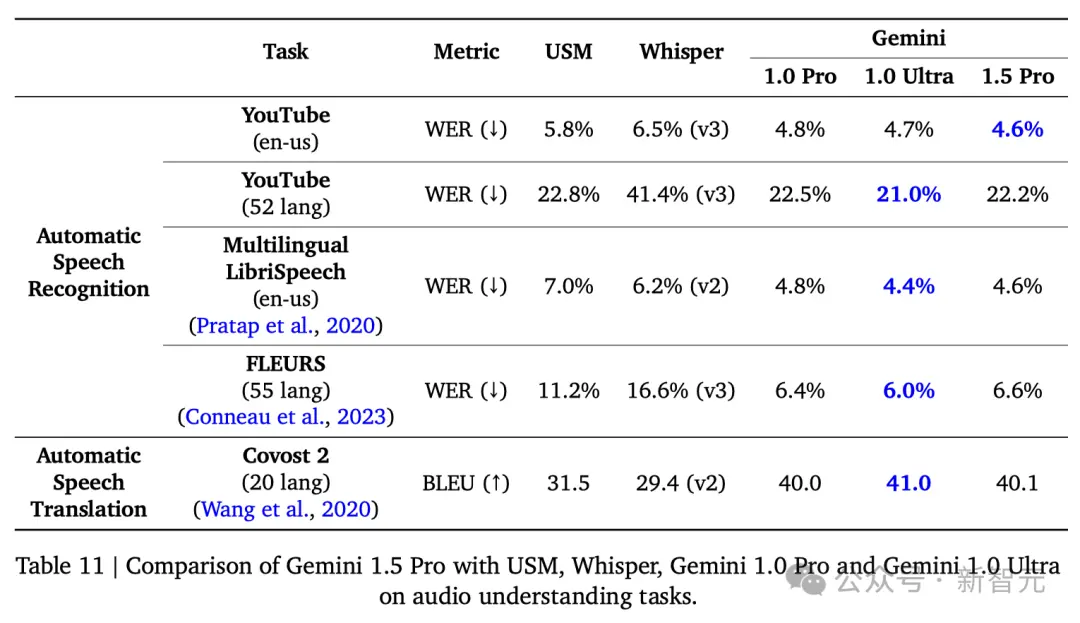
性能比肩Ultra,大幅超越1.0 Pro
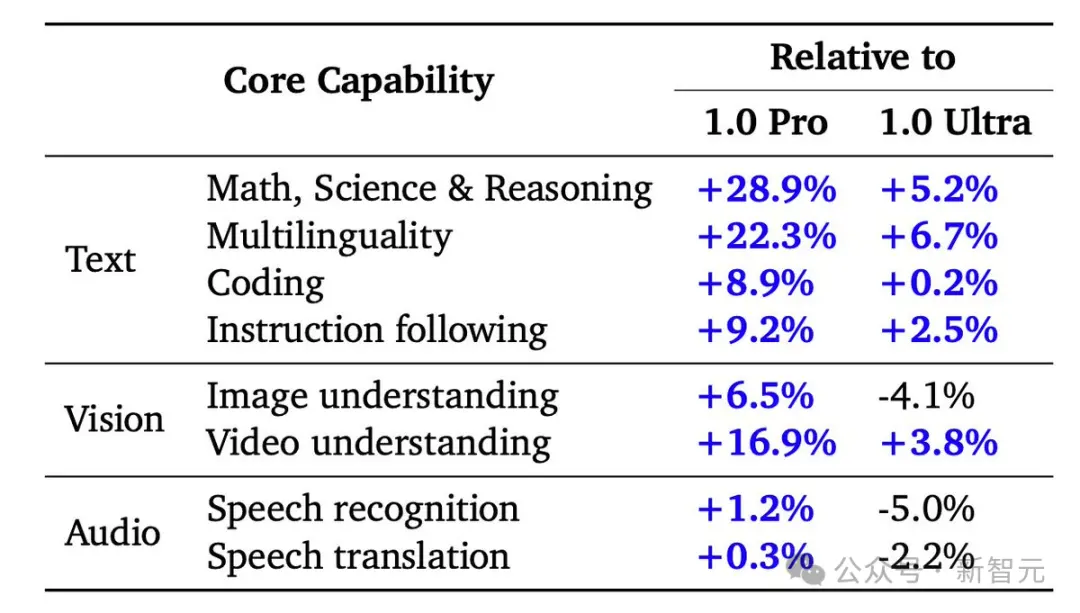
在涵蓋文本、代碼、圖像、音頻和視頻的綜合性測試中,1.5 Pro在87%的基準測試上超越1.0 Pro。
與1.0 Ultra在相同基準測試的比較中,1.5 Pro的表現也相差無幾。
Gemini 1.5 Pro在擴大上下文窗口後,依然保持高水平的性能。在“大海撈針 (NIAH)”測試中,它能夠在長達100萬token的文本塊中,在99%的情況下,準確找出隱藏有特定信息的文本片段。
此外,Gemini 1.5 Pro展現卓越的“上下文學習”能力,能夠僅憑長提示中提供的信息掌握新技能,無需進一步細化調整。
這一能力在“從一本書學習機器翻譯 (MTOB)”基準測試中得到驗證,該測試檢驗模型學習從未接觸過的信息的能力。
對於一本關於全球不足200人使用的Kalamang語的語法手冊,模型能夠學會將英語翻譯成Kalamang,學習效果與人類學習相似。
Google的研究者成功地增強模型處理長文本的能力,而且這種增強並沒有影響到模型的其他功能。
雖然這項改進隻用Gemini 1.0 Ultra模型訓練時間的一小部分,但1.5 Pro模型在31項性能測試中的17項上超過1.0 Ultra模型。
與1.0 Pro模型相比,1.5 Pro在31項測試中的27項上,表現更佳。
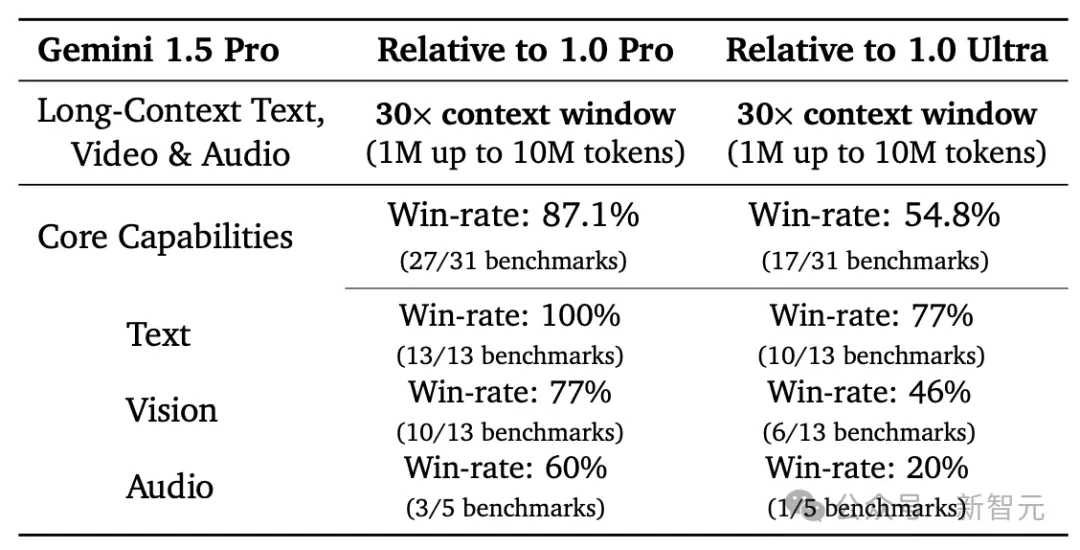
具體結果如下:
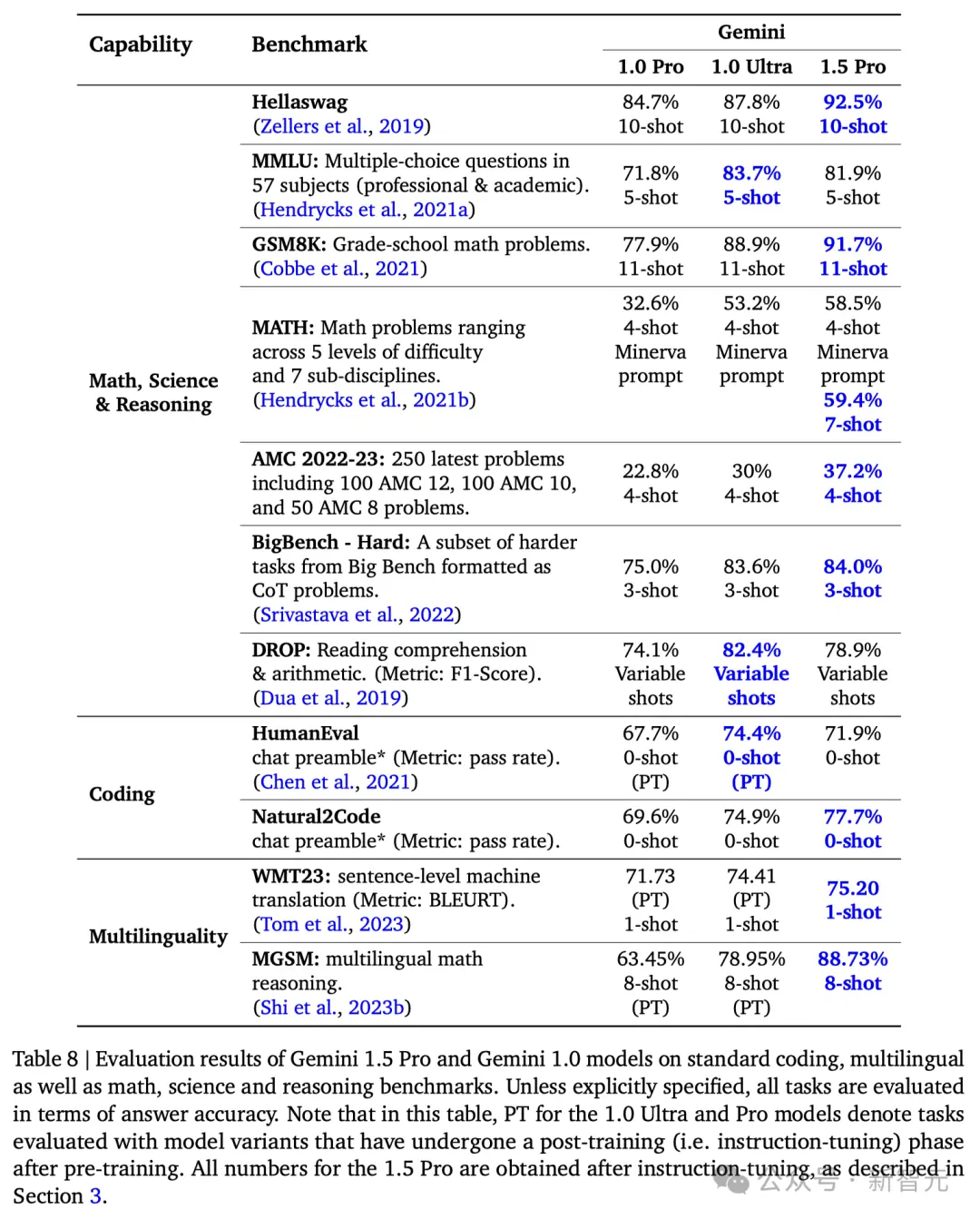
細節表現如何?
分析和掌握復雜代碼庫
這款模型能夠迅速吸收大型代碼庫,並解答復雜的問題,這一點非常引人註目。
例如,three.js是一個包含約10萬行代碼、示例和文檔等的3D Javascript庫。
借助這個代碼庫作為背景,系統能夠幫助用戶深入理解代碼,並能夠根據人們提出的高層次要求來修改復雜的示例。
比如:“展示一些代碼,用於添加一個滑塊控制動畫速度。采用和其他演示相同的GUI風格。”
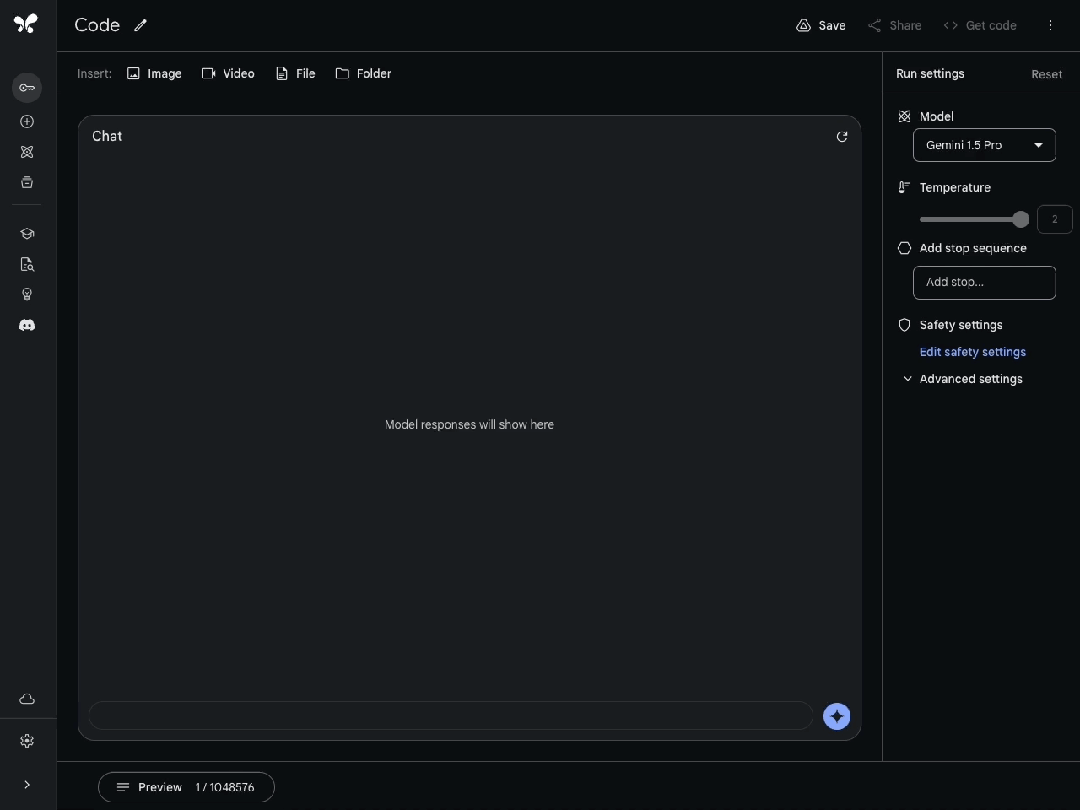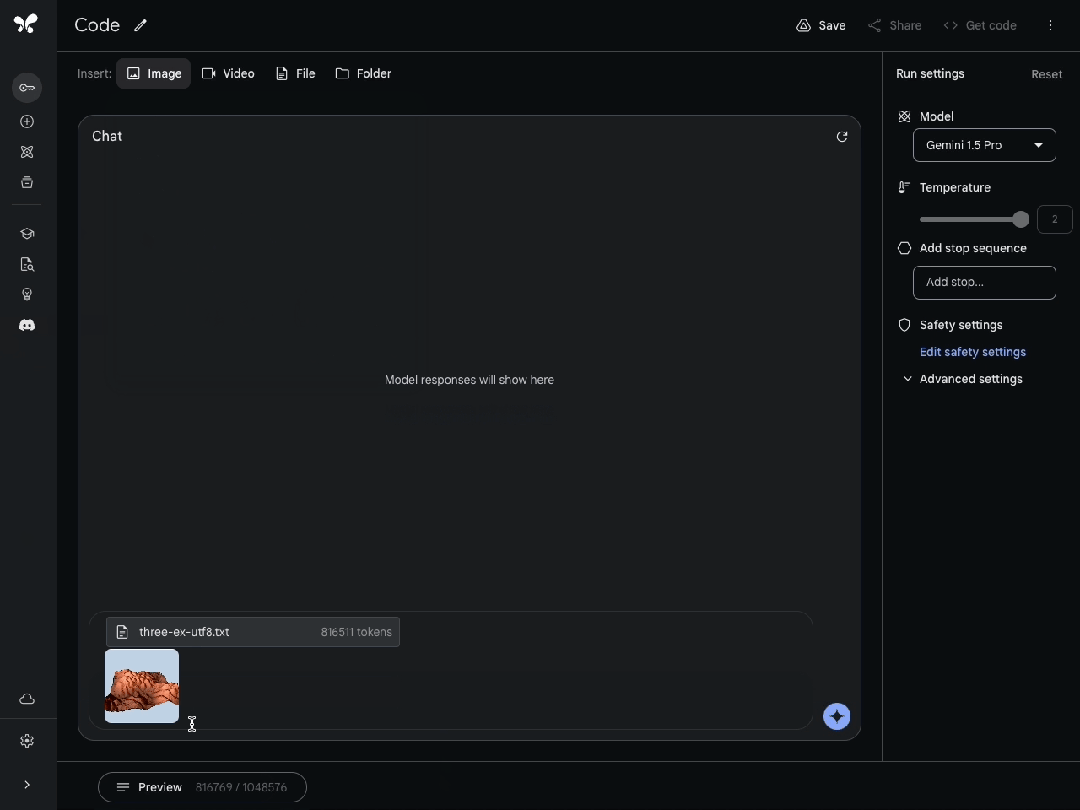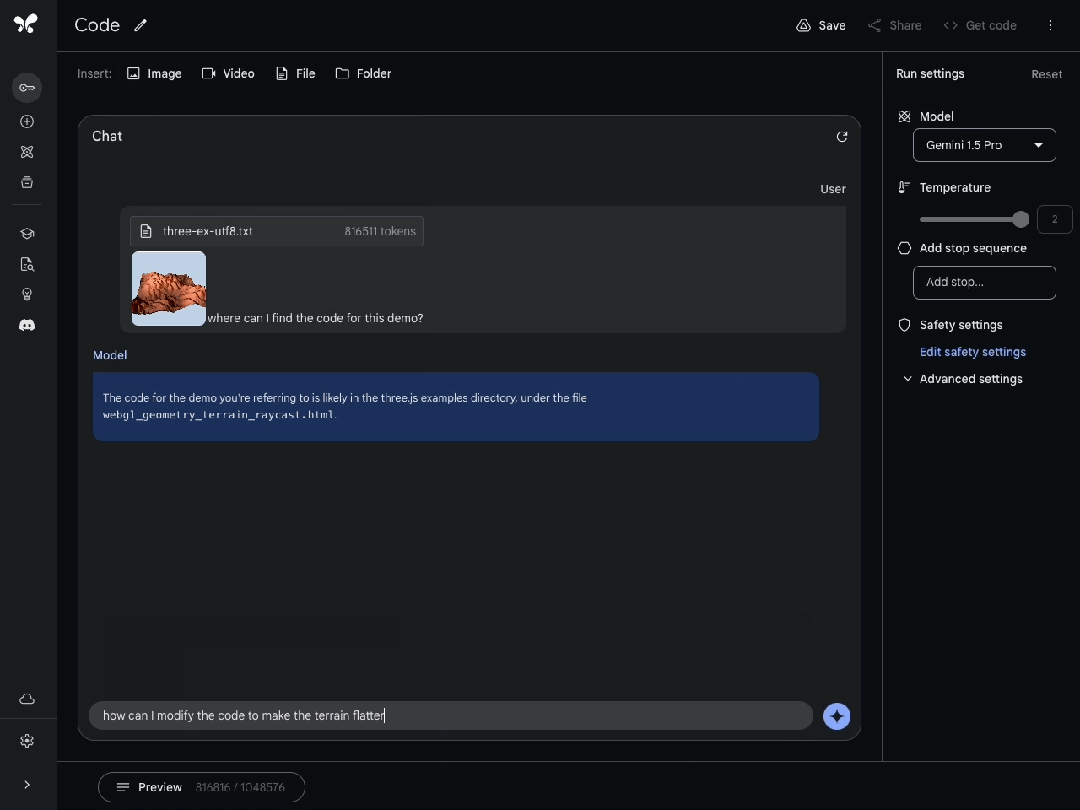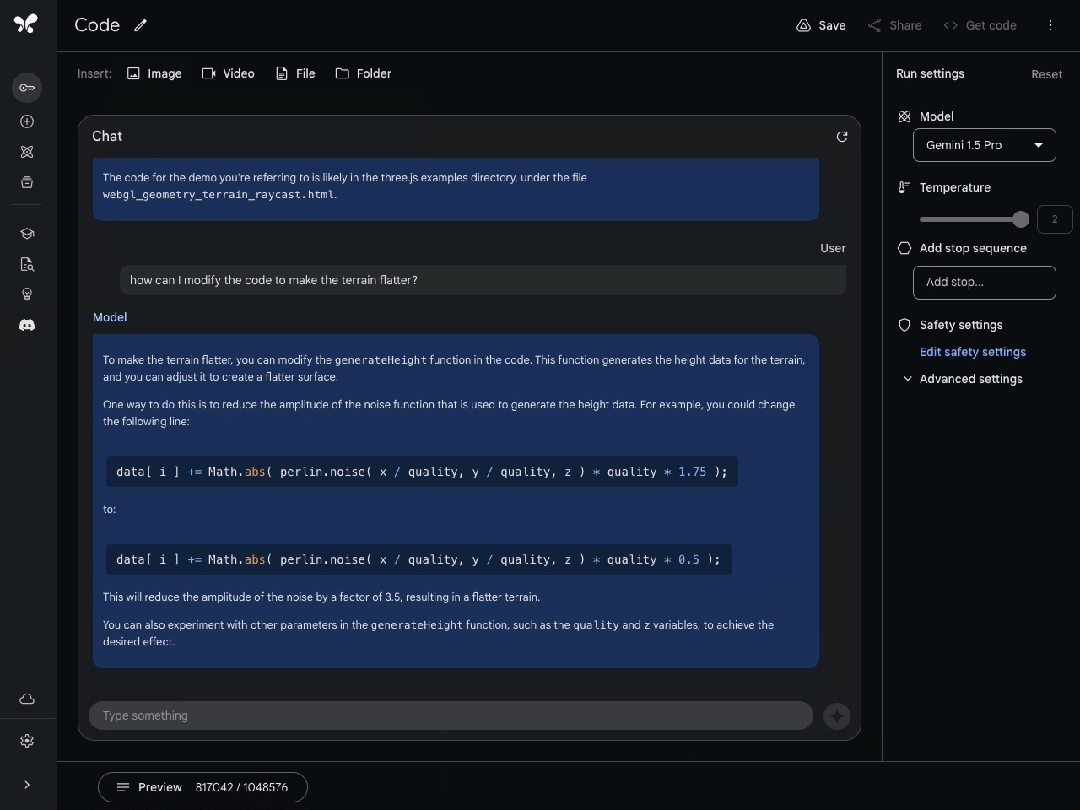
或者精確地指出需要修改的代碼部分,以改變另一個示例中生成的地形的高度。
瀏覽龐大而陌生的代碼庫
並且,模型能夠幫我們理解代碼,或定位某個特定功能的實現位置。
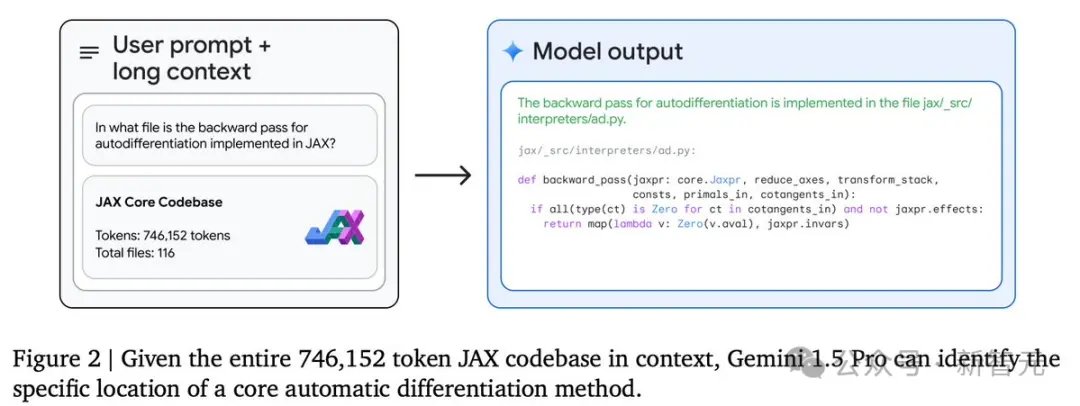
在這個例子中,模型能夠處理整個包含116個文件的JAX代碼庫(746k token),並協助用戶找到實現自動微分反向傳播的確切代碼位置。
顯然,在深入解一個陌生的代碼庫或日常工作中使用的代碼庫時,長上下文處理能力的價值不言而喻。
許多Gemini團隊成員已經發現,Gemini 1.5 Pro的長上下文處理功能,對於Gemini 代碼庫大有裨益。
長篇復雜文檔的推理
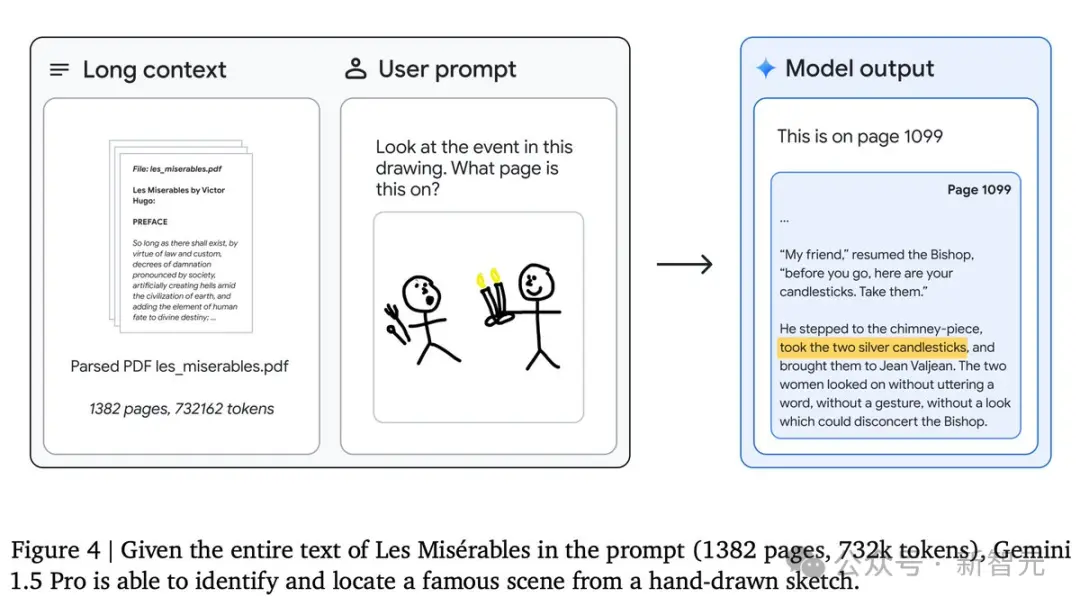
同時,模型在分析長篇、復雜的文本文檔方面也非常出色,例如雨果的五卷本小說《悲慘世界》(共1382頁,含732,000個token)。
下面這個簡單的實驗,就展示模型的多模態能力:粗略地畫出一個場景,並詢問“請看這幅圖畫中的事件發生在書的哪一頁?”
模型就能給出準確的答案——1099頁!
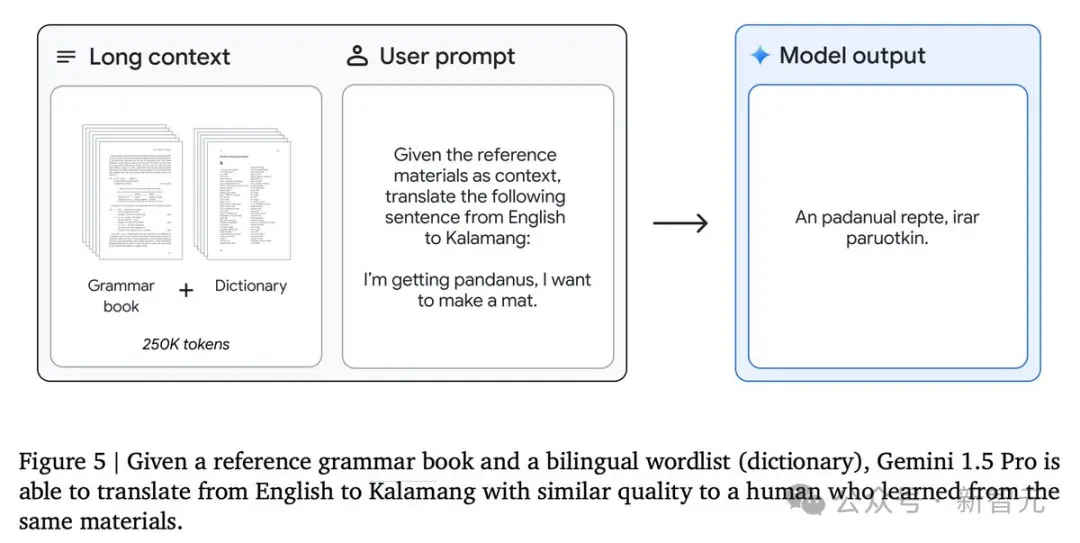
Kalamang語翻譯
報告中一個特別引人註目的例子是關於Kalamang語的翻譯。
卡拉曼語是新幾內亞西部、印度尼西亞巴佈亞東部不足200人使用的語言,幾乎未在互聯網上留下足跡。
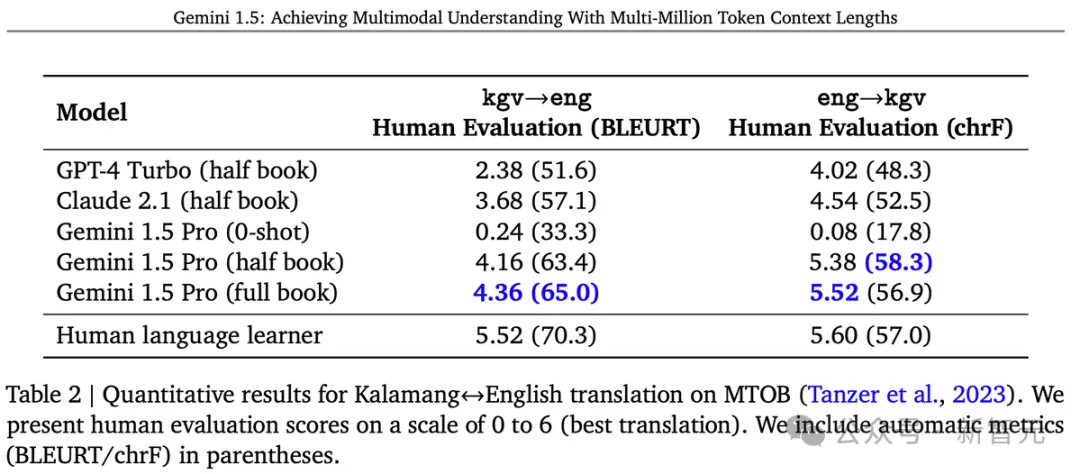
Gemini Pro 1.5通過上下文學習掌握Kalamang語的知識,其翻譯質量可與使用相同材料學習的人相媲美。
在英語到卡拉曼語的翻譯中,Gemini Pro 1.5的ChrF達到58.3,大幅超過以往最好的模型得分45.8 ChrF,並略高於MTOB論文報告的57.0 ChrF人類基準。
這一成就無疑帶來令人激動的可能性,提升稀有語言的翻譯質量。
Gemini 1.5的誕生,意味著性能的階段飛躍,標志著Google在研究和工程創新上,又邁出登月般的一步。
接下來能跟Gemini 1.5硬剛的,大概就是GPT-5。
參考資料:
https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/#architecture
https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
https://developers.googleblog.com/2024/02/gemini-15-available-for-private-preview-in-google-ai-studio.html
https://twitter.com/JeffDean/status/175814602272604161