Google下一代大模型,無預警降臨。Gemini1.5,除性能顯著增強,還在長上下文理解方面取得突破,甚至能僅靠提示詞學會一門訓練數據中沒有的新語言。此時距離去年12月Gemini1.0發佈,還不到3個月。
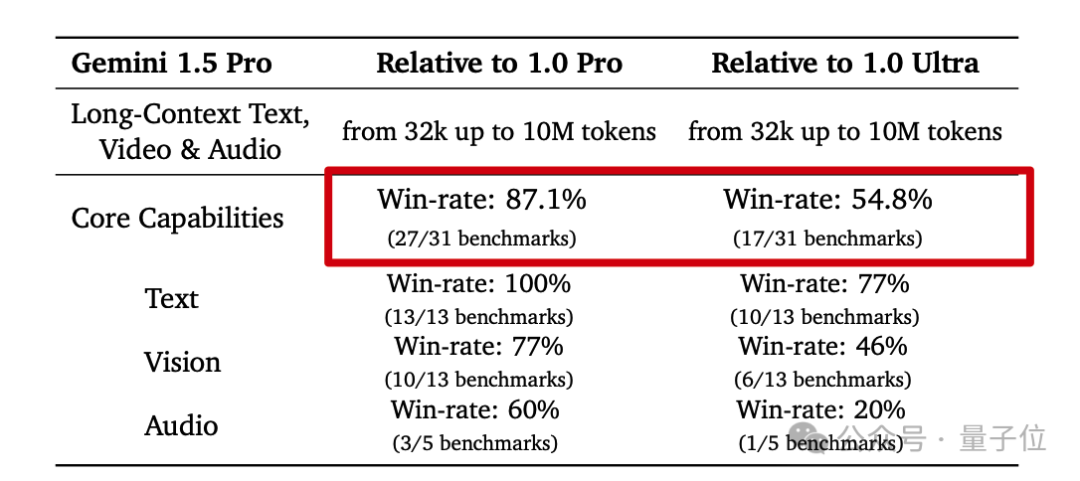
現在僅僅中杯1.5 Pro版就能越級打平上一代大杯1.0 Ultra版,更是在27項測試中超越平級的1.0 Pro。
支持100萬token上下文窗口,迄今為止大模型中最長,直接甩開對手一個量級。
這還隻是對外發佈的版本,Google更是透露內部研究版本已經能直沖1000萬。

現在Gemini能處理的內容,可換算成超過70萬單詞,或1小時視頻、11小時音頻、超過3萬行代碼。
沒錯,這些數據模態Gemini 1.5都已經內建支持。
從今天起,開發者和客戶就可以在Vertex API或AI Studio申請試用。
剛剛收到消息還在震驚中的網友們 be like:

還有人直接@OpenAI的奧特曼,這你們不跟進一波?

上下文理解能力拉滿
目前Google已放出三個不同任務的演示視頻,隻能說Gemini 1.5是個抽象派(doge)。
在第一段演示視頻中,展示的是Gemini 1.5處理長視頻的能力。
使用的視頻是巴斯特·基頓(Buster Keaton)的44分鐘電影,共696161 token。

演示中直接上傳電影,並給模型這樣的提示詞:
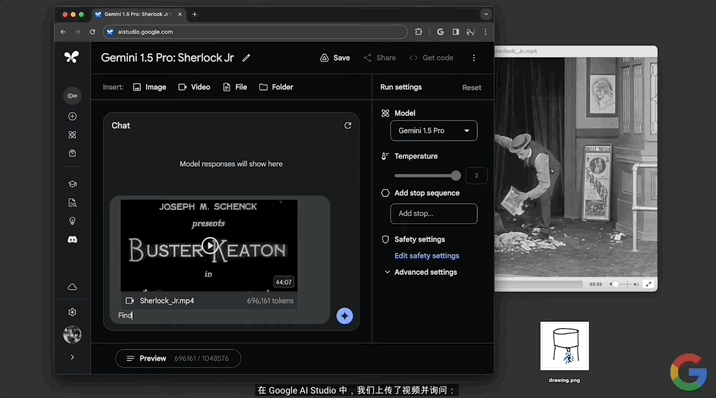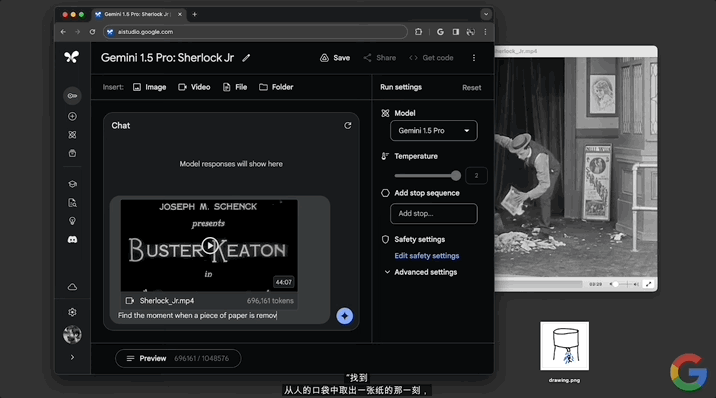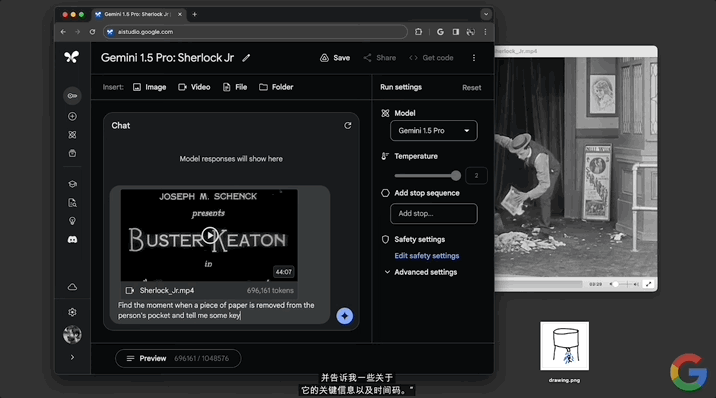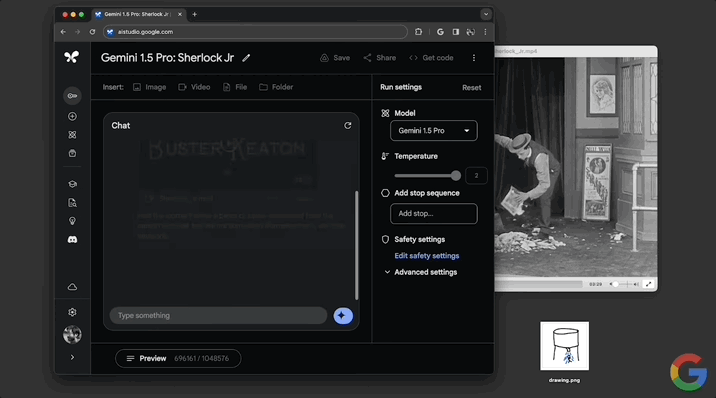
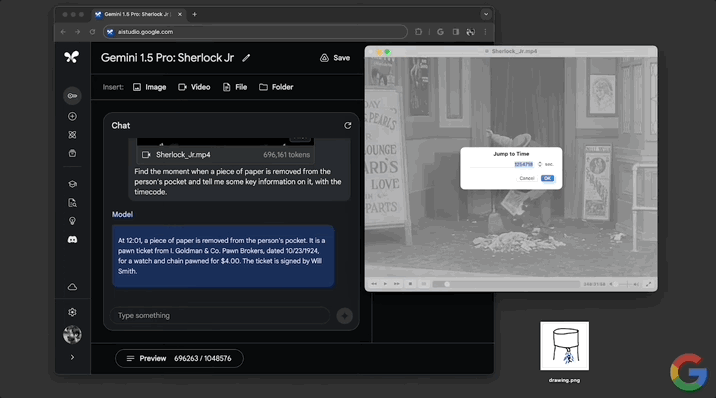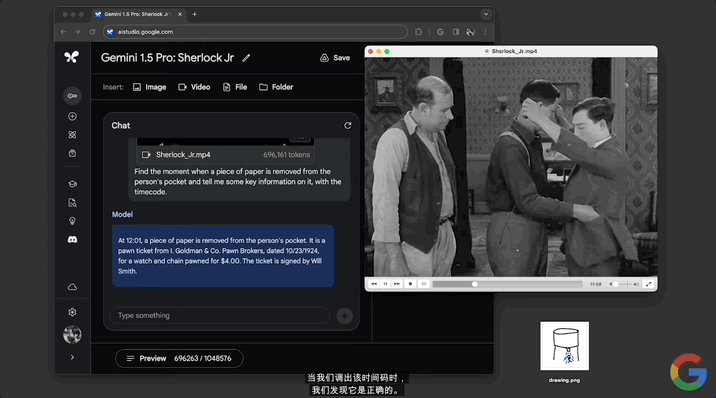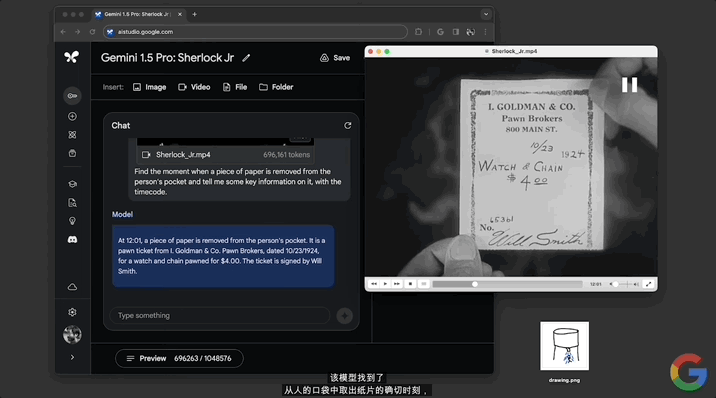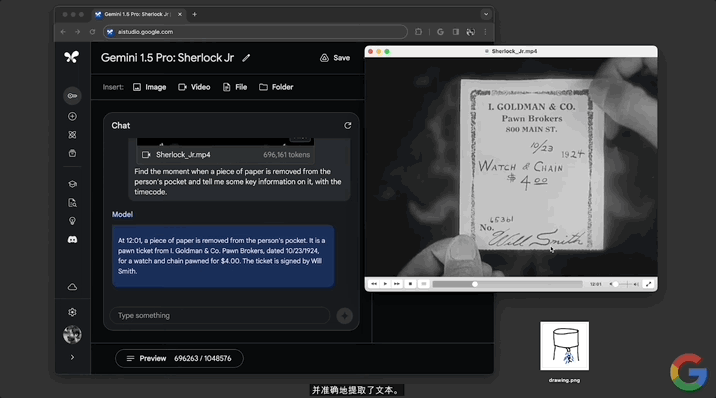
找到從人的口袋中取出一張紙的那一刻,並告訴我一些關於它的關鍵信息以及時間碼。
隨後,模型立刻處理,輸入框旁邊帶有一個“計時器”實時記錄所耗時間:
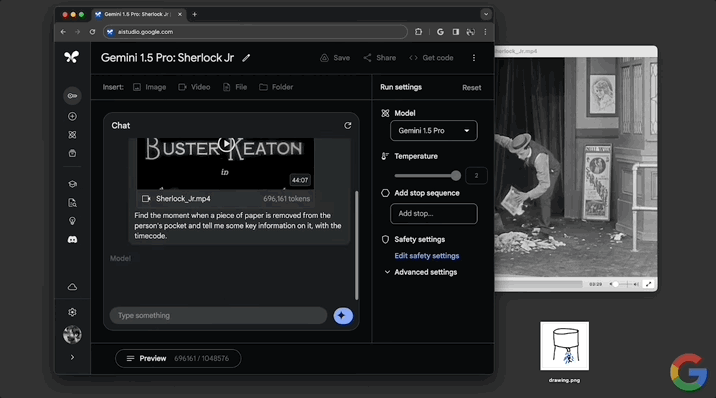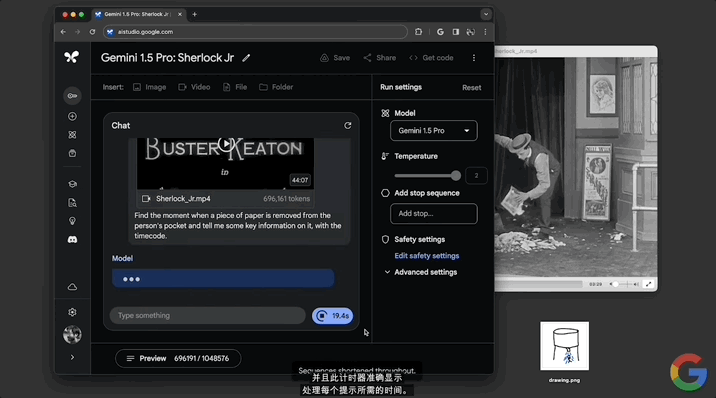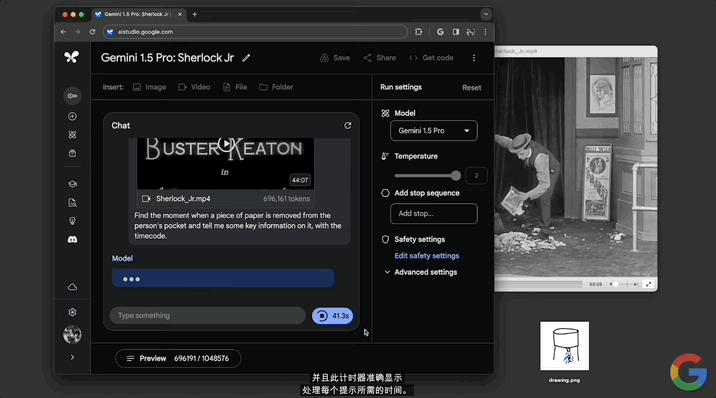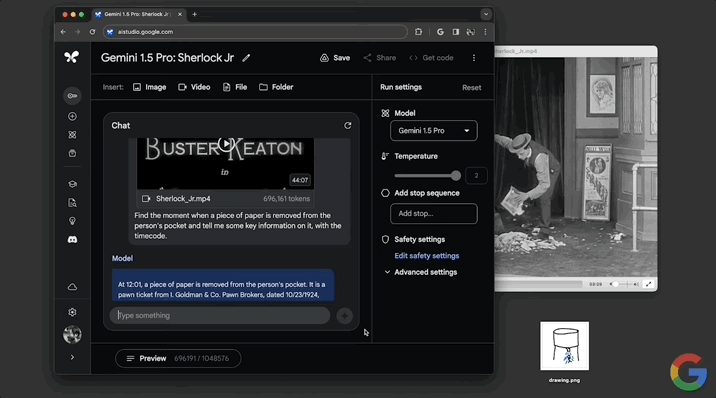
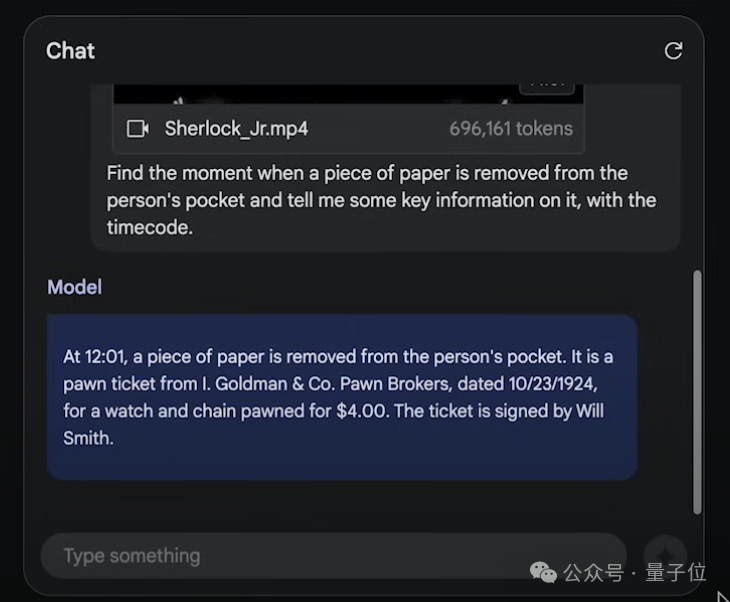
不到一分鐘,模型做出回應,指出12:01的時候有個人從兜裡掏出一張紙,內容是高盛典當經紀公司的一張當票,並且還給出當票上的時間、成本等詳細信息。
隨後經查證,確認模型給出的12:01這個時間點準確無誤:
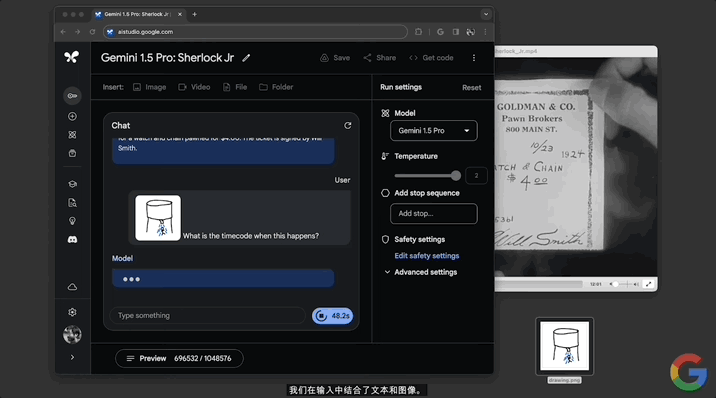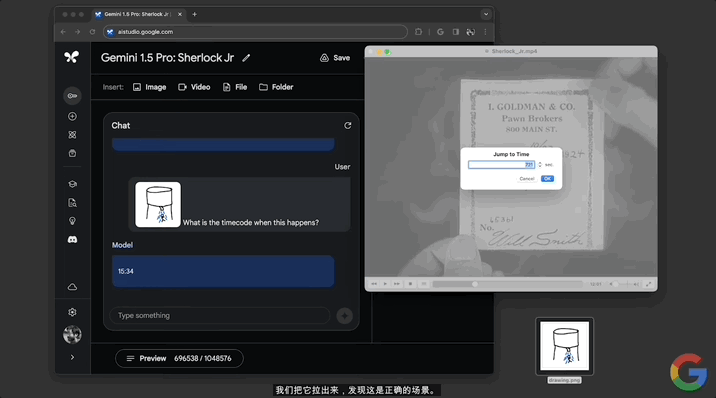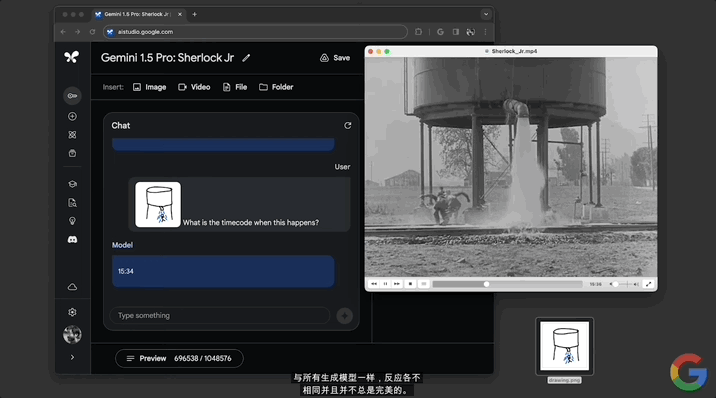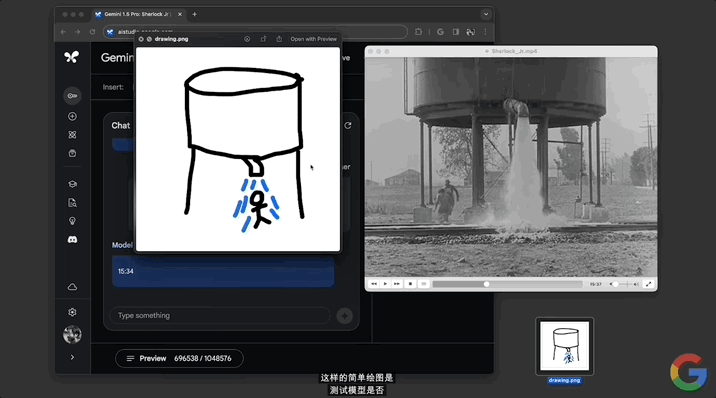
除純文字prompt,還有更多玩法。直接給模型一張抽象“場景圖”,詢問“發生這種情況時的時間碼是多少?”。
同樣不到一分鐘,模型準確給出的電影對應的時間點15:34。
在第二段演示視頻中,Google展示Gemini 1.5分析和理解復雜代碼庫的能力。用到的是Three.js,這是一個3D Javascript庫,包含約100000行代碼、示例、文檔等。

演示中他們將所有內容放到一個txt文件中,共816767 token,輸入給模型並要求它“找到三個示例來學習角色動畫”。
結果模型查看數百個示例後篩選出三個關於混合骨骼動畫、姿勢、面部動畫的示例。

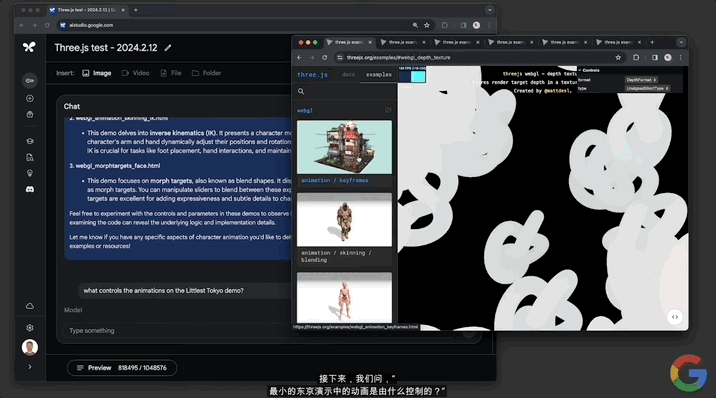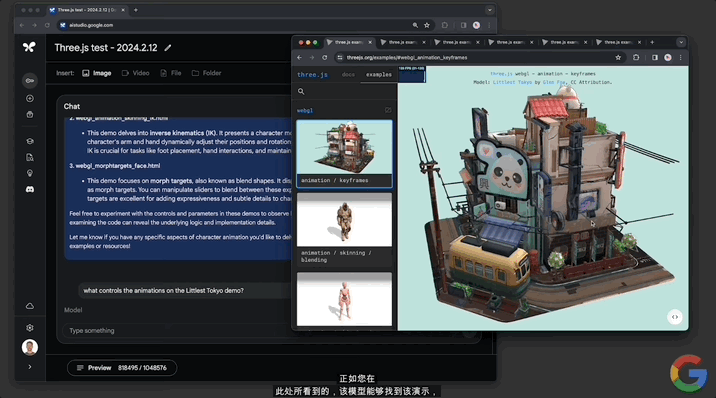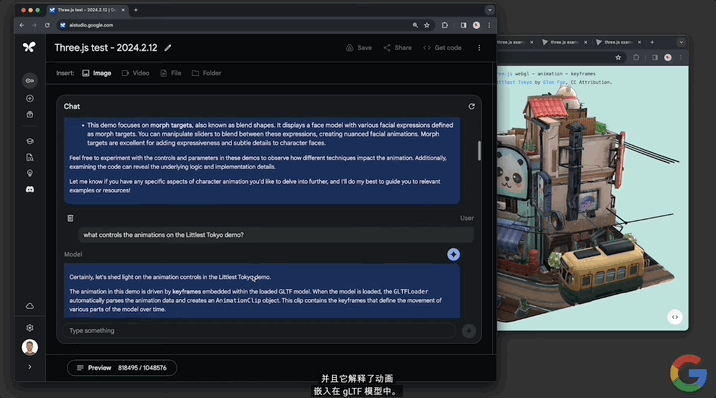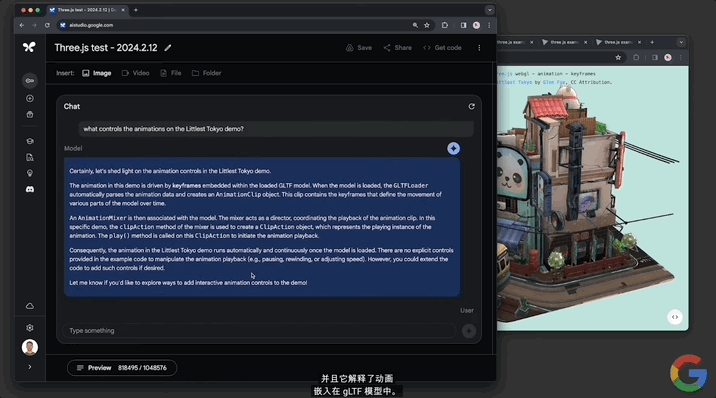
這隻是開胃小菜。接下來隻用文字詢問模型“動畫Little Tokyo的demo是由什麼控制?”
模型不僅找到這個demo,並且解釋動畫嵌入在gLTF模型中。
並且還能實現“定制代碼”。讓模型“給一些代碼,添加一個滑塊來控制動畫的速度。使用其它演示所具有的那種GUI”。
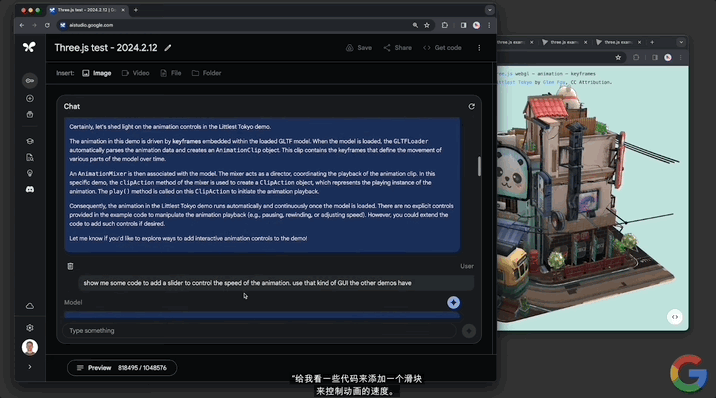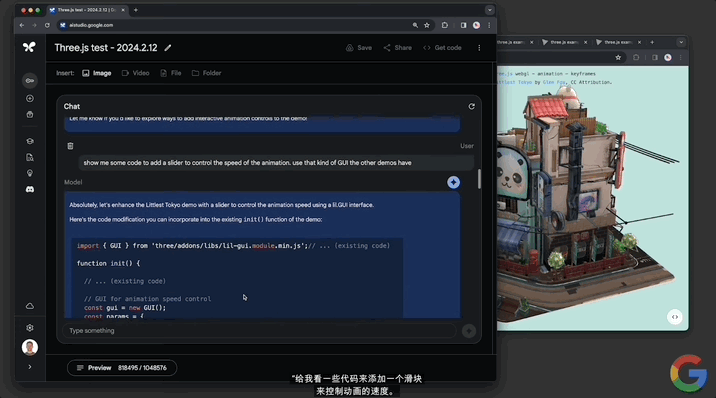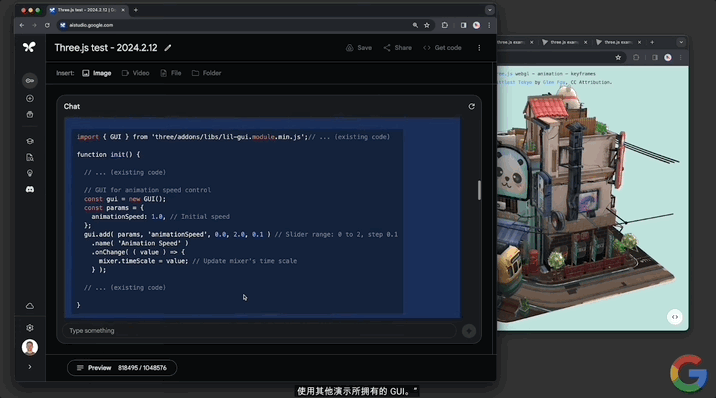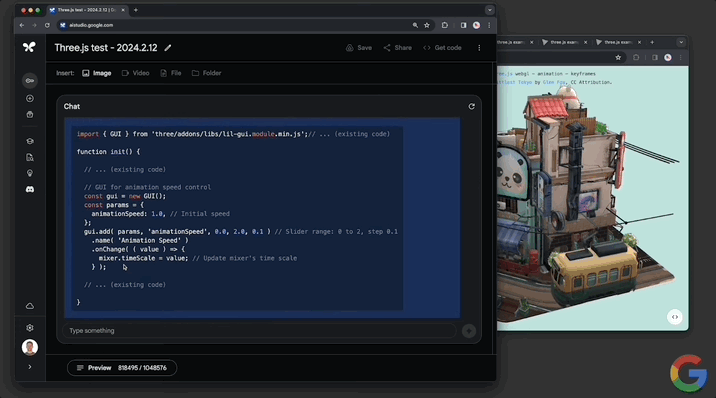
Gemini 1.5分分鐘給出可以成功運行的代碼,動畫右上角出現一個可控速的滑塊:
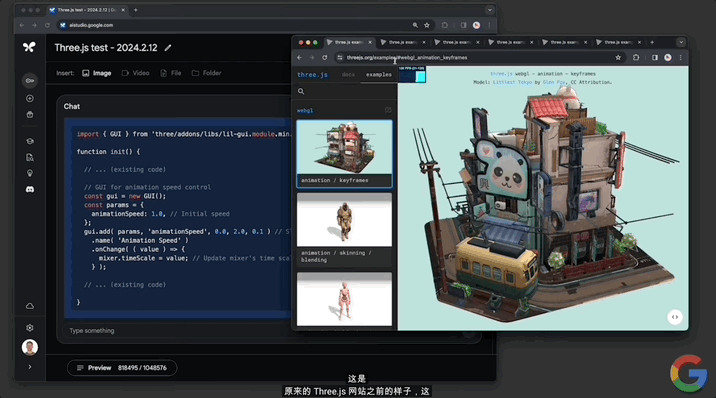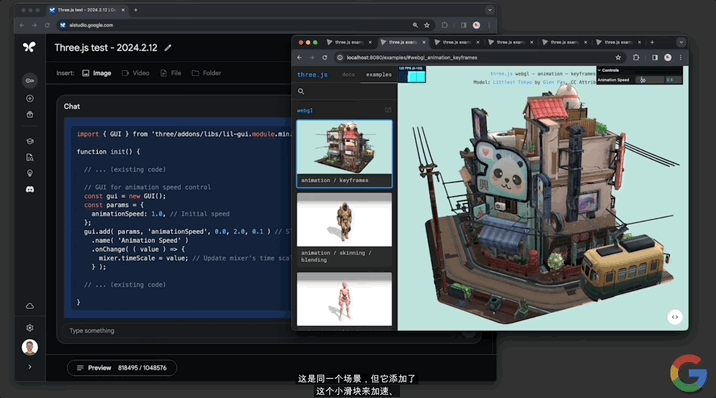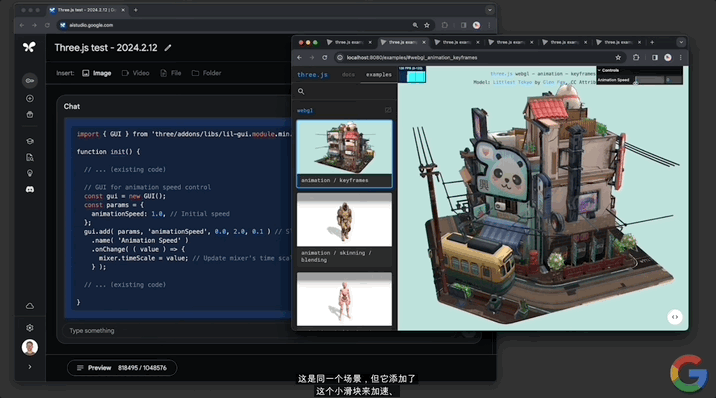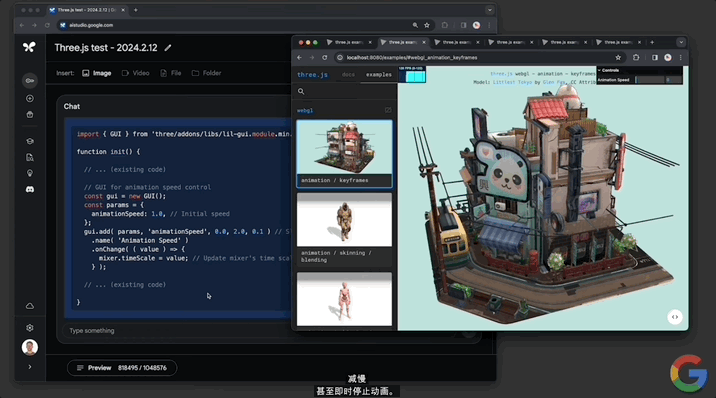
當然也可以做“代碼定位”。僅靠一張demo的圖片,Gemini 1.5就能在代碼庫中從數百個demo中,找到該圖對應動畫的代碼:
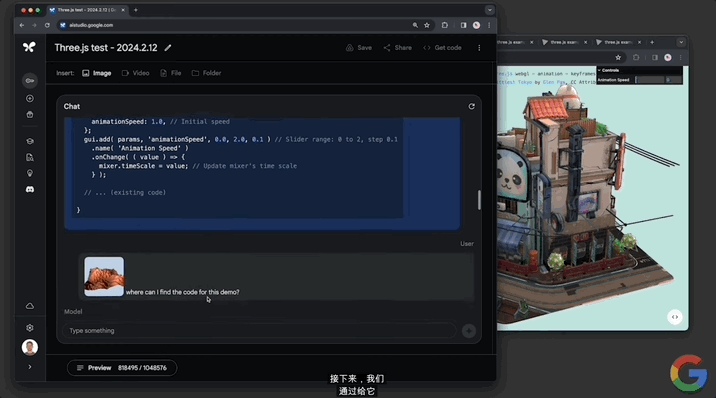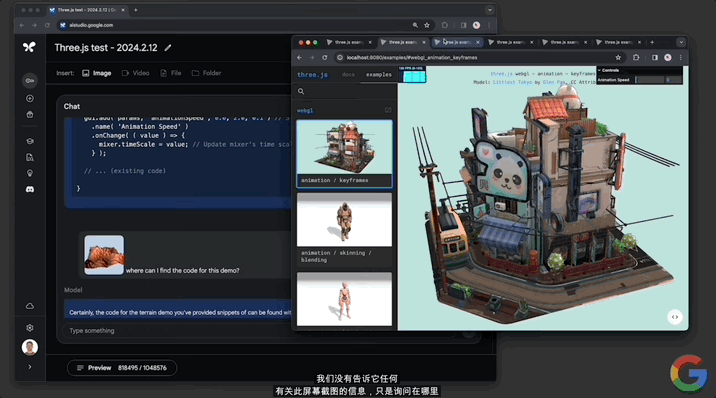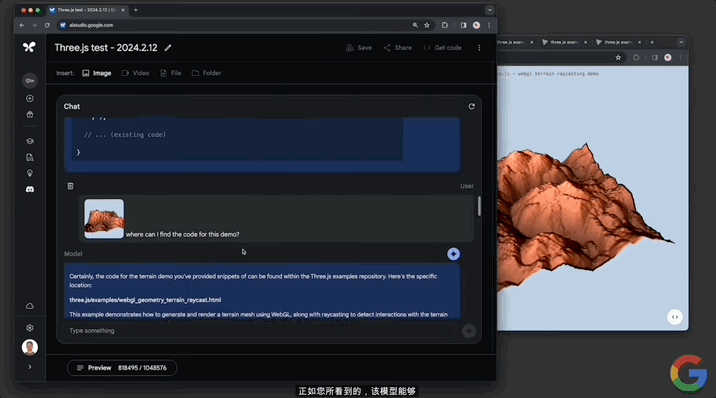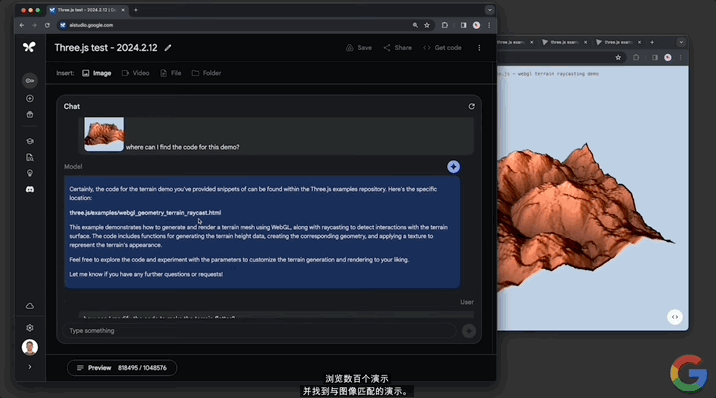
還能修改代碼,讓地形變得平坦,並解釋其中的工作原理:
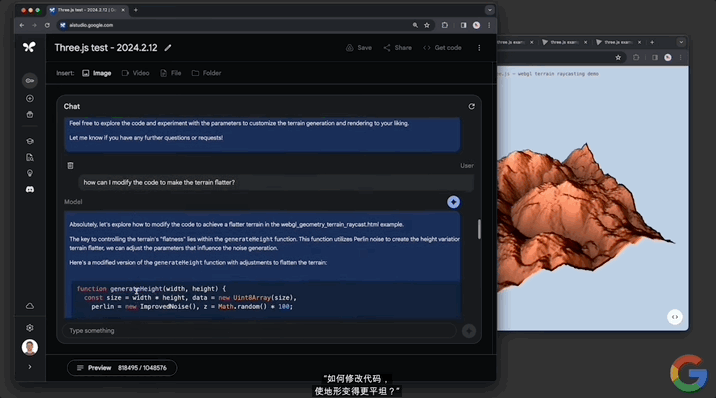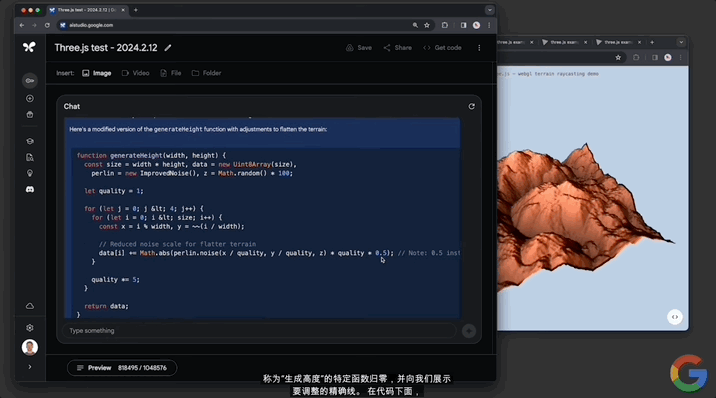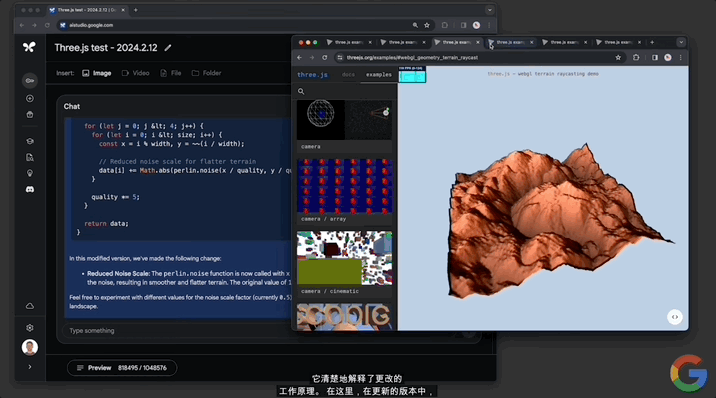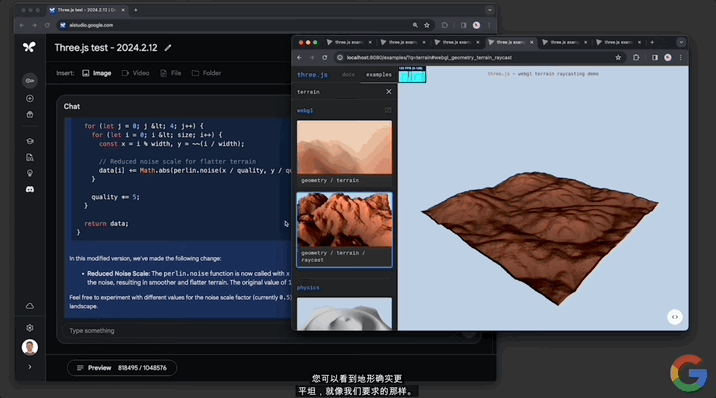
修改代碼這一塊,對文本幾何體的修改也不在話下:
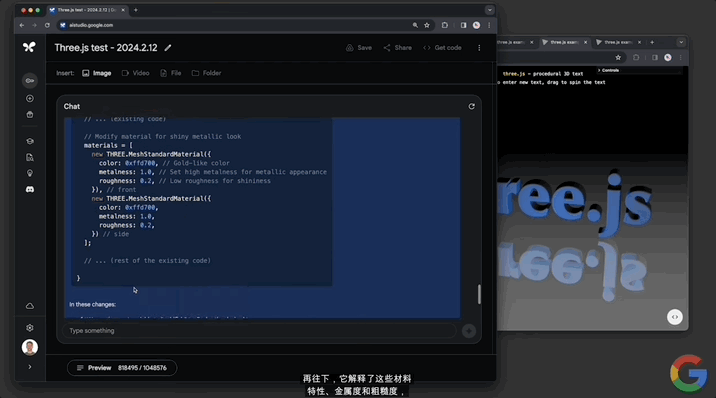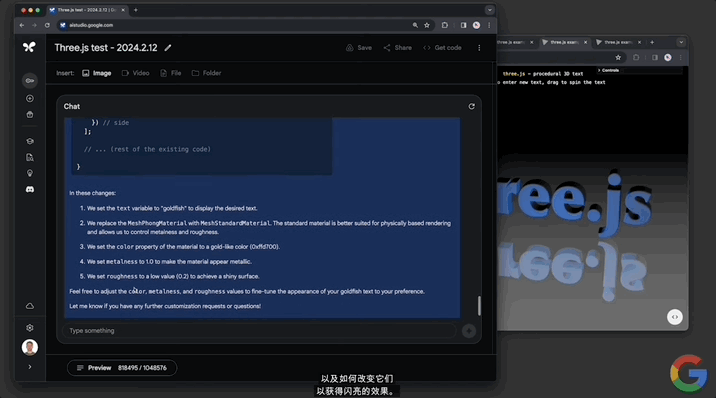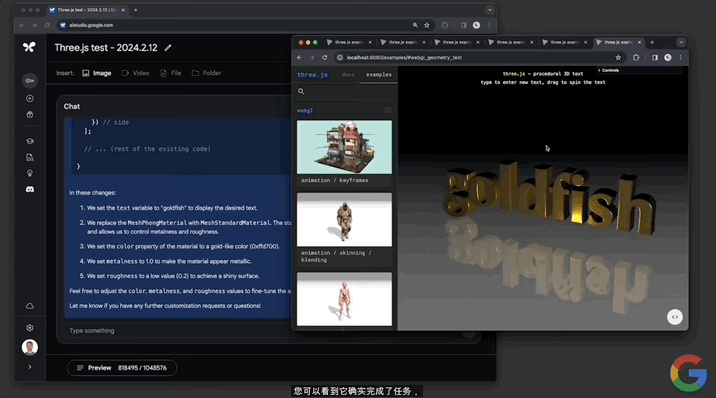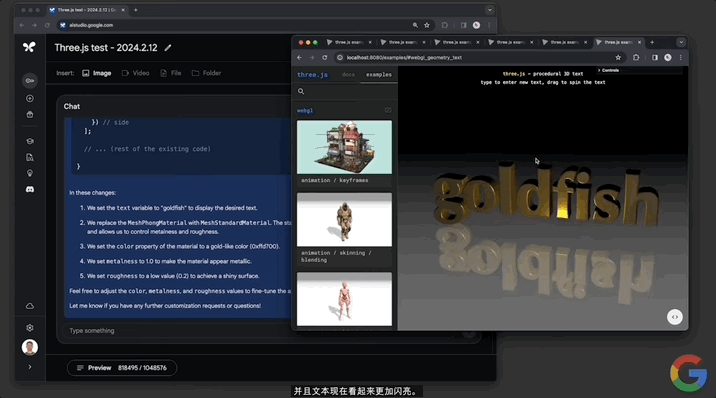
第三個演示視頻展示的是Gemini 1.5的文檔處理能力。
選用的是阿波羅11號登月任務的402頁PDF記錄,共326658 token。

要求Gemini 1.5“找到三個搞笑時刻,並列出文字記錄以及表情符號引述”:
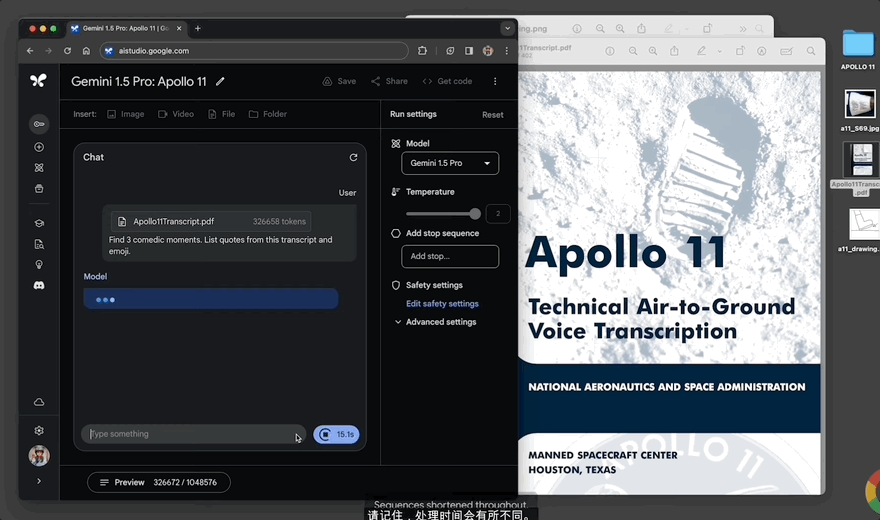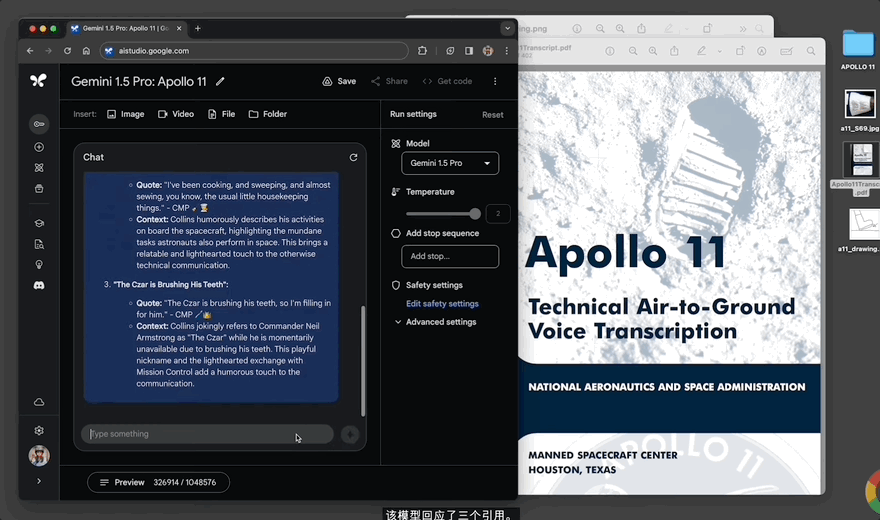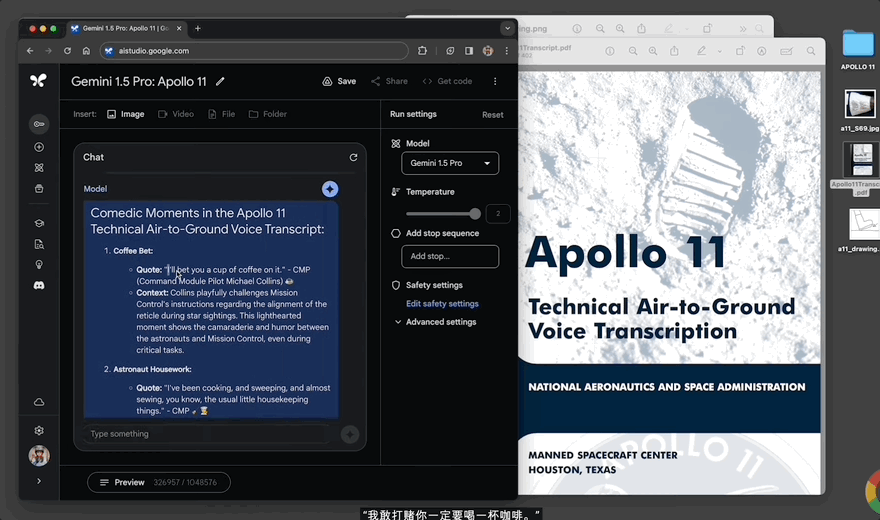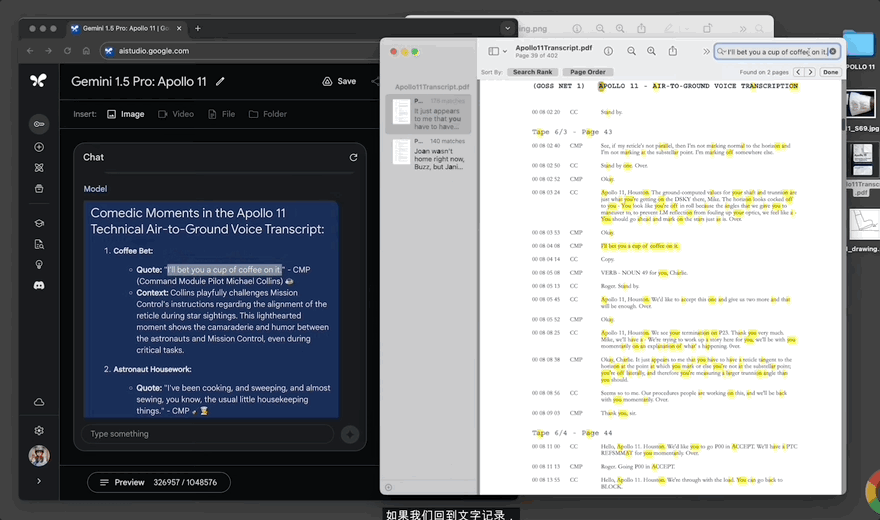
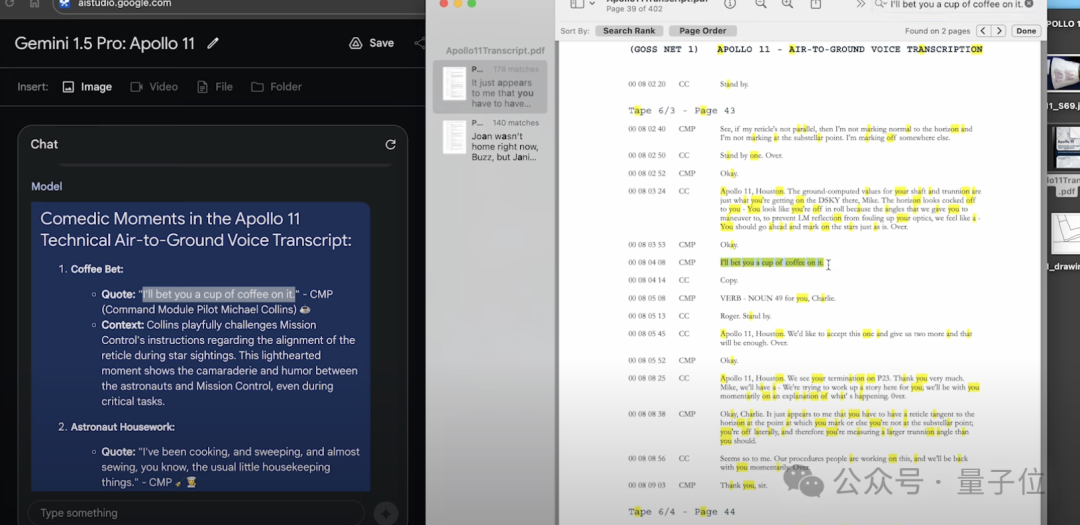
30秒,模型給出回應,其一是邁克爾·柯林斯的這句話“我敢打賭你一定要喝一杯咖啡”,經查詢文檔中的確有記錄:
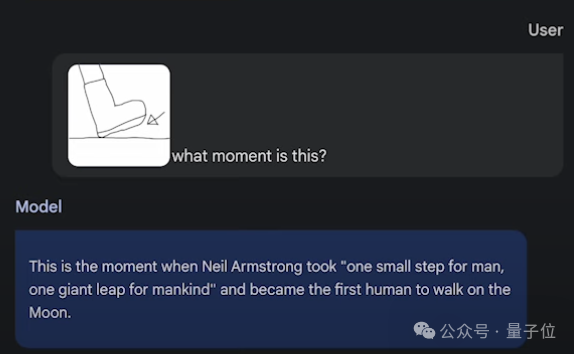
更抽象一點,繪制一個靴子的圖片,詢問模型“這是什麼時刻”。
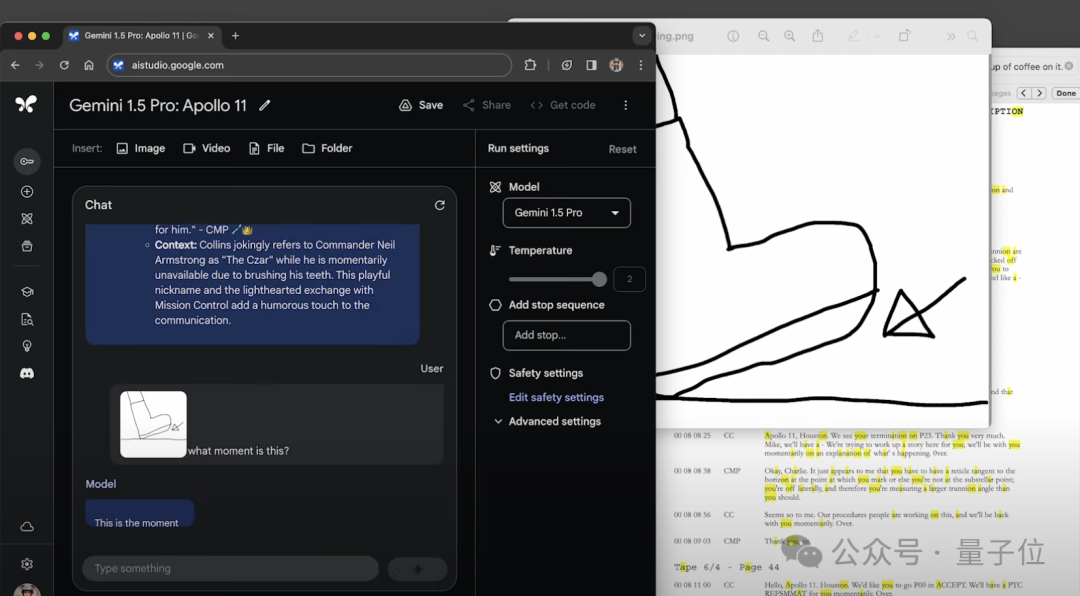
模型正確地將其識別為這是Neil在月球上的第一步:
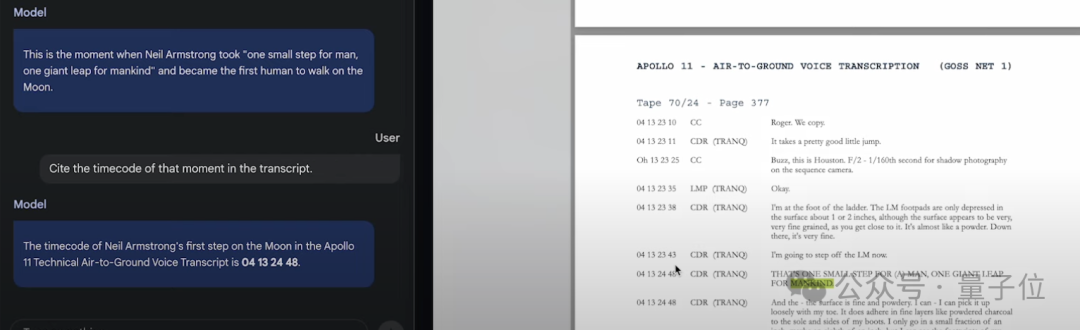
最後同樣可以詢問模型快速定位這一時刻在文檔中對應的時間位置:
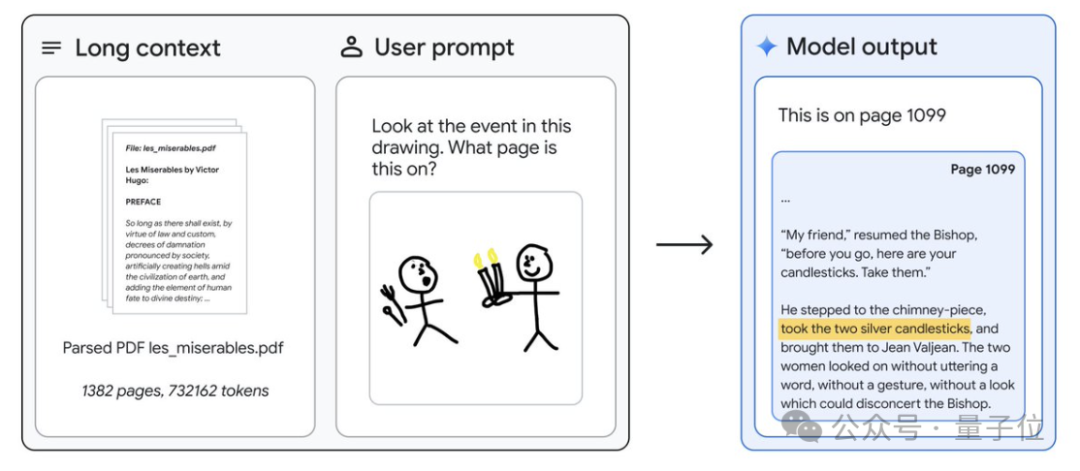
差不多的抽象風同樣適用於1382頁、732000 token的《悲慘世界》,一張圖定位小說位置。
僅從提示詞中學會一門新語言
對於Gemini 1.5的技術細節,Google遵循OpenAI開的好頭,隻發佈技術報告而非論文。

其中透露Gemini 1.5使用MoE架構,但沒有更多細節。

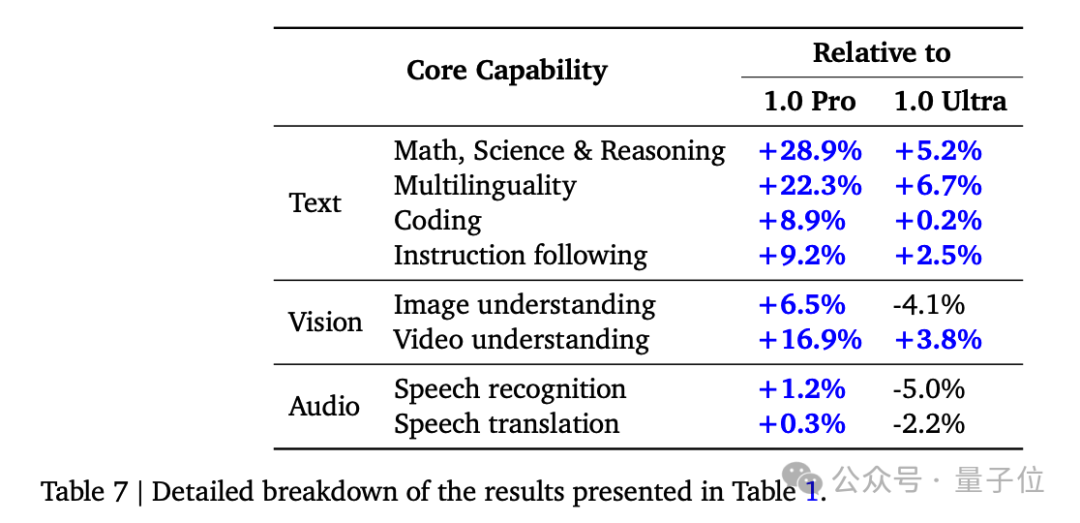
與上代1.0 Pro相比,1.5 Pro在數學、科學、推理、多語言、視頻理解上進步最大,並達到1.0 Ultra層次。
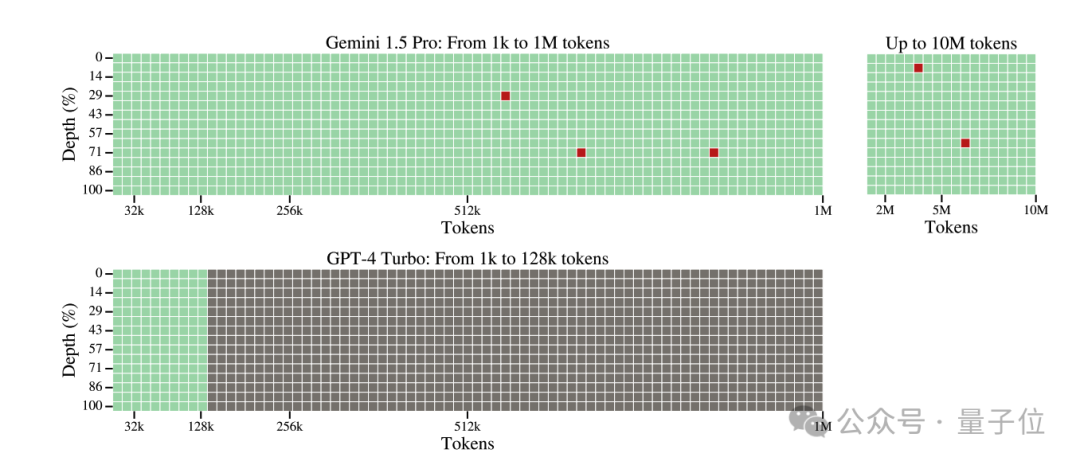
為驗證長上下文窗口的性能,使用開源社區通行的大海撈針測試,也就是在長文本中準確找到可以藏起來的一處關鍵事實。
結果50萬token之前的表現非常完美,一直到千萬token,Gemini 1.5也隻失誤5次。
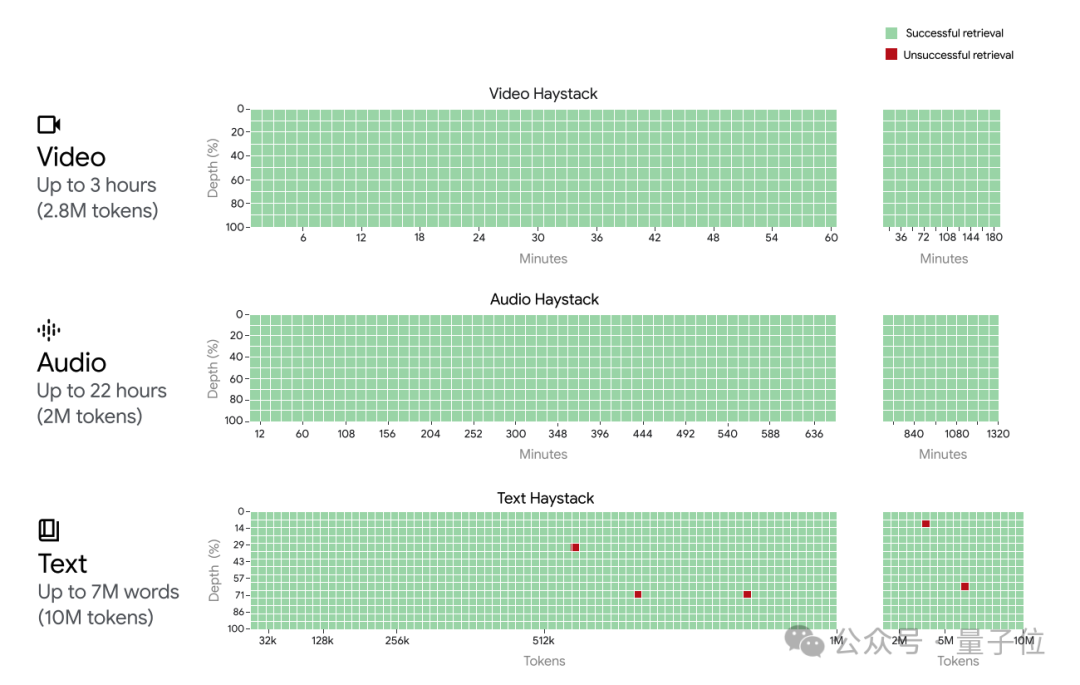
此外還將測試擴展到多模態版本,如在視頻畫面的某一幀中藏一句話,給的例子是在阿爾法狗的紀錄片中藏“The secret word is ‘needle’”字樣。

結果在視頻、音頻測試中都實現100%的召回率。
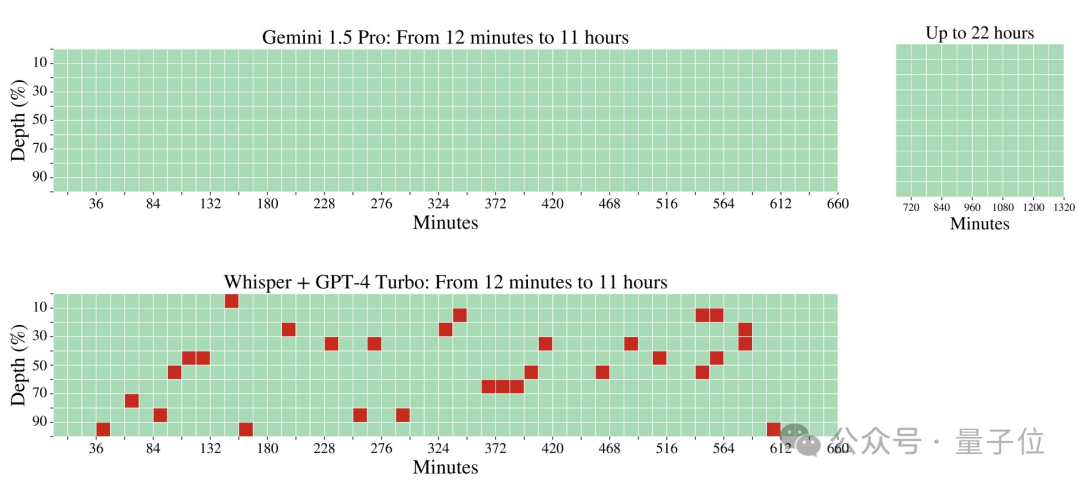
特別是音頻中,對比GPT-4+Whisper的結果,差距非常明顯。
此外GoogleDeepMind團隊還測試一項高難任務,僅通過長提示詞讓模型學會全新的技能。

輸入一整本語法書,Gemini 1.5 Pro就能在翻譯全球不到200人使用的Kalamang上達到人類水平。
相比之下,GPT-4 Turbo和Claude 2.1一次隻能看完半本書,想獲得這個技能就必須要微調或者使用外部工具。
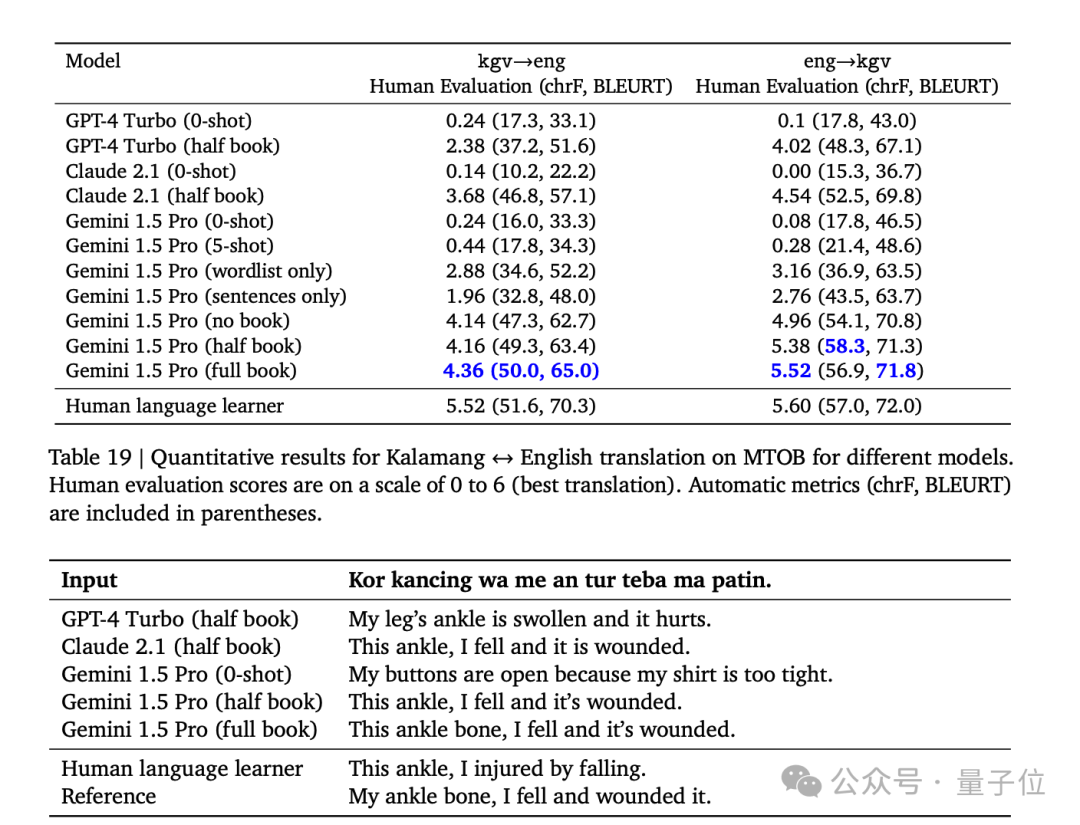
也難怪有網友看過後驚呼,“哥們這是要把RAG玩死啊”。

One More Thing
Google還公佈一波已在業務中采用Gemini大模型的客戶。
其中有三星手機這樣的大廠,也有像Jasper這種靠GPT起傢的創業公司,甚至OpenAI董事Adam D‘Angelo旗下的Quora。
與OpenAI形成直接競爭關系。

對此,一位網友道出大傢的心聲:
真希望這能促使OpenAI發佈他們的下一代大模型。

參考鏈接:
[1] https://twitter.com/JeffDean/status/1758146022726041615
[2] https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf
[3] https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/#gemini-15