為何Sora會掀起滔天巨浪?Sora的技術,就是機器模擬我們世界的下一步。而且今天有人扒出,Sora創新的核心秘密時空Patches,竟是來自GoogleDeepMind和謝賽寧的論文成果。OpenAI,永遠快別人一步!像ChatGPT成功搶Claude的頭條一樣,這一次,Google核彈級大殺器Gemini1.5才推出沒幾個小時,全世界的目光就被OpenAI的Sora搶去。
100萬token的上下文,僅靠一本語法書就學會一門全新的語言,如此震撼的技術進步,在Sora的榮光下被襯得暗淡無光,著實令人唏噓。
這次,不過也是之前歷史的重演。

為什麼ChatGPT會提前誕生?
《這就是ChatGPT》一書對此進行揭秘: 當時OpenAI管理層聽說,從OpenAI“ 叛逃” 的前員工創立的公司Anthropic Claude有意提前推出Chatbot。
管理層立馬意識到這個產品潛力巨大,於是先下手為強,第一時間改變節奏,出手截胡Anthropic。
11月中旬,在研發GPT-4的OpenAI員工收到指令:所有工作暫停,全力推出一款聊天工具。兩周後,ChatGPT誕生,從此改變人類歷史。
或許,這也就揭示為什麼一傢公司可以永載史冊的原因:領導者能夠發現有市場潛力的新產品,全面攔截所有成功的可能性。
對於Google被截胡一事,網友銳評道:OpenAI用Sora對抗Gemini發佈的方式簡直,Google從沒有受過這樣的打擊。
這不得不讓人懷疑,OpenAI手裡是不是還攥著一堆秘密武器,每當競爭對手發佈新技術,他們就放出來一個爆炸級消息。

要知道,現在才剛剛是2024年2月,想想接下來要發生的事,不免覺得毛骨悚然。
為何Sora掀起滔天巨浪
Sora一出,馬斯克直接大呼:人類徹底完蛋!

馬斯克為什麼這麼說?
OpenAI科學傢Tim Brooks表示,沒通過人類預先設定,Sora就自己通過觀察大量數據,自然而然學會關於3D幾何形狀和一致性的知識。
從本質上說,Sora的技術,就是機器模擬我們世界的一個裡程碑。
外媒Decoder直言:OpenAI令人驚嘆的視頻模型處女作Sora的誕生,感覺就像是GPT-4時刻。

更有人表示,在Sora之中,我切實感受到AGI。

這也就是為什麼Sora會在全世界掀起滔天巨浪的原因。
要解Sora如此強大的能力從何而來,除OpenAI官方給出的技術報告,行業大佬也進行進一步的解讀。
LeCun轉發華人學者謝賽寧的推文,認為Sora基本上是基於謝賽寧等人在去年被ICCV 2023收錄的論文提出的框架設計而成的。
而和謝賽寧一起合著這篇論文的William Peebles之後也加入OpenAI,領導開發Sora的技術團隊。

所以謝賽寧的對於Sora的技術解讀,具備極高的參考價值。
謝賽寧:Sora很厲害,不過好像是用我的論文成果
AI大神謝賽寧,針對Sora的技術報告談自己的看法。

項目地址:https://wpeebles.com/DiT
- 架構:Sora應該是基於他和Bill之前在ICCV 2023上提出的以Transformer為主幹的擴散模型(DIT)
其中,DIT=[VAE編碼器+VIT+DDPM+VAE解碼器]。
根據技術報告,好像沒有其他特別的設計。
-“視頻壓縮網絡”:似乎是一個VAE,但訓練的是原始視頻數據。
在獲得良好的時間一致性方面,tokenize可能起很重要的作用。
VAE是一個ConvNet。所以從技術上講,DIT是一個混合模型。
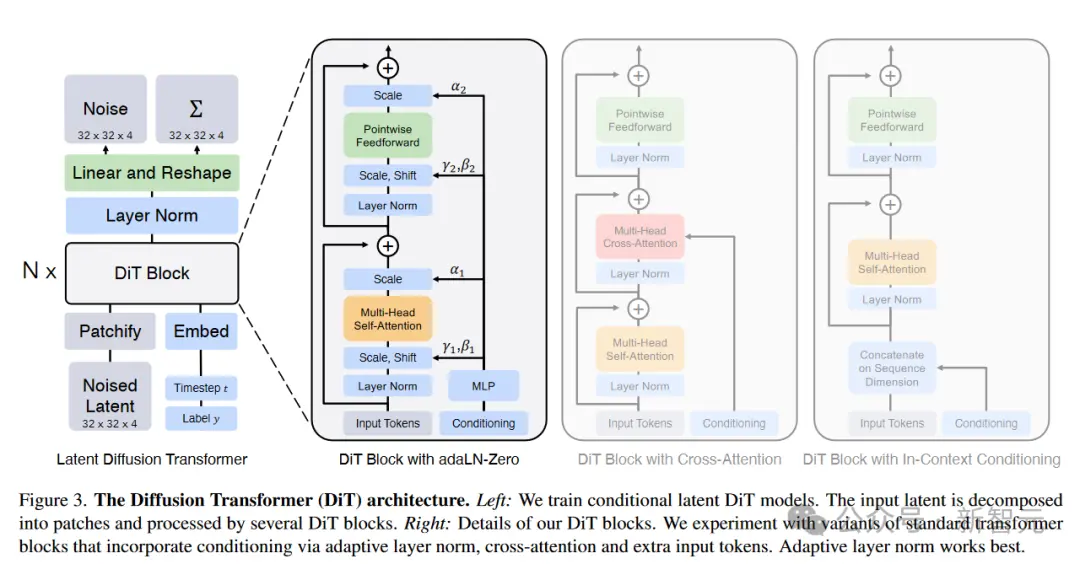
謝賽寧表示,他們在DIT項目沒有創造太多的新東西,但是兩個方面的問題:簡單性和可擴展性。
這可能就是Sora為什麼要基於DIT構建的主要原因。
首先,簡單意味著靈活
當涉及到輸入數據時,如何使模型更加靈活。
例如,在掩碼自動編碼器(MAE)中,VIT幫助我們隻處理可見的patch,而忽略掉被mask的。
同樣,Sora可以通過在適當大小的網格中安排隨機初始化的patch來控制生成的視頻的大小。
UNet並不直接提供這種靈活性。
猜測:Sora可能還會使用Google的Patch n‘Pack(Navit),以使DIT能夠適應不同的分辨率/持續時間/長寬比。
其次,可擴展性是DIT論文的核心主題
就每Flop的時鐘時間而言,優化的DiT比UNet運行得快得多。
更重要的是,Sora證明DIT縮放法則不僅適用於圖像,現在也適用於視頻——Sora復制DIT中觀察到的視覺縮放行為。
猜測:在Sora的演示中,第一個視頻的質量相當差,謝懷疑它使用的是最基礎的模型。
粗略計算一下,DIT XL/2是B/2模型的5倍GFLOPs,因此最終的16倍計算模型可能是DIT-XL模型的3倍,這意味著Sora可能有約30億個參數。

如果真的是如此,Sora的模型規模可能沒有那麼大。
這可能表明,訓練Sora可能不需要像人們預期的那樣,有非常大的算力要求,所以他預測未來Sora迭代的速度將會很快。

進一步的,謝賽寧解釋Sora提供的關鍵的洞見來自“湧現的模擬能力”這一表現上。
在Sora之前,尚不清楚長期形式的一致性是否會自行湧現,或者是否需要復雜的主題驅動的其他流程,甚至是物理模擬器。
而現在OpenAI已經表明,雖然現在結果還不完美,但這些行為和能力可以通過端到端的訓練來實現。
然而,有兩個要點還不是很明確。
1. 訓練數據:技術報告沒有涉及訓練的數據集,這可能意味著數據是Sora成功的最關鍵因素。
目前已經有很多關於遊戲引擎數據的猜測。 他期待包括電影、紀錄片、電影長鏡頭等。
2. (自回歸)長視頻生成:Sora的一個重大突破是生成超長視頻的能力。
制作一段2秒的視頻和1分鐘的視頻之間的差異是巨大的。
Sora可能是通過允許自回歸采樣的聯合幀預測來實現的,但這裡最主要挑戰是如何解決誤差累積問題,並隨著時間的推移保持質量/一致性。
OpenAI Sora的技術,就是機器模擬我們世界的重要下一步
AI究竟如何將靜態圖形轉換為動態、逼真的視頻?
Sora的一大創新,就是創新性地使用時空patch。
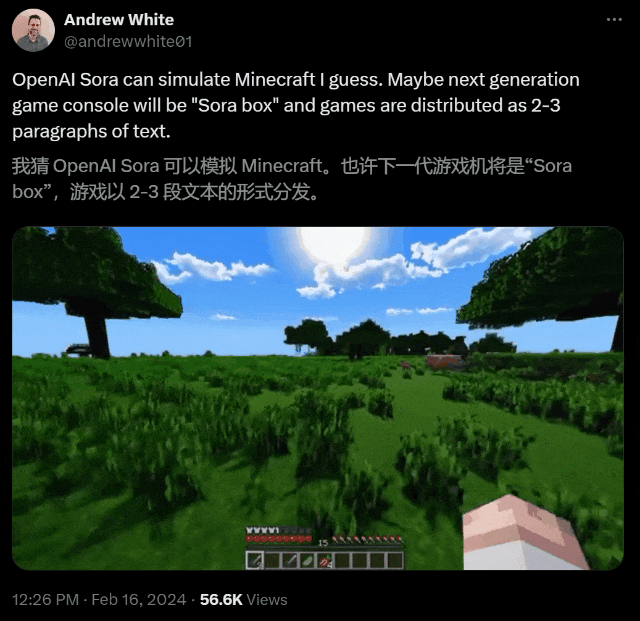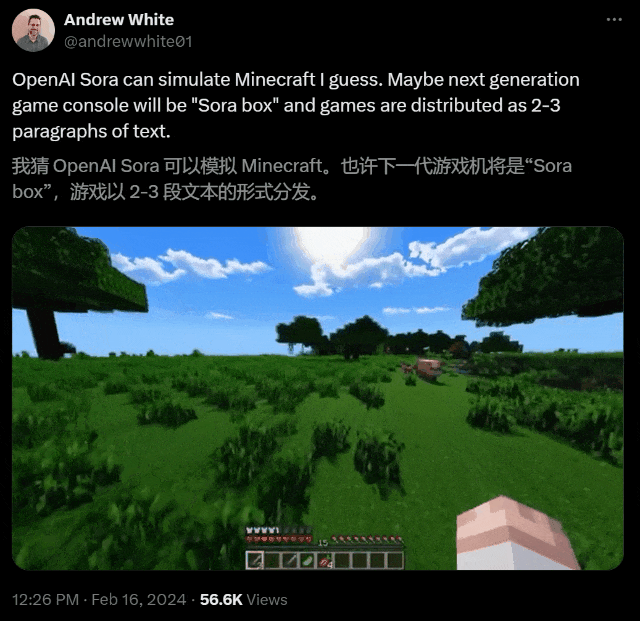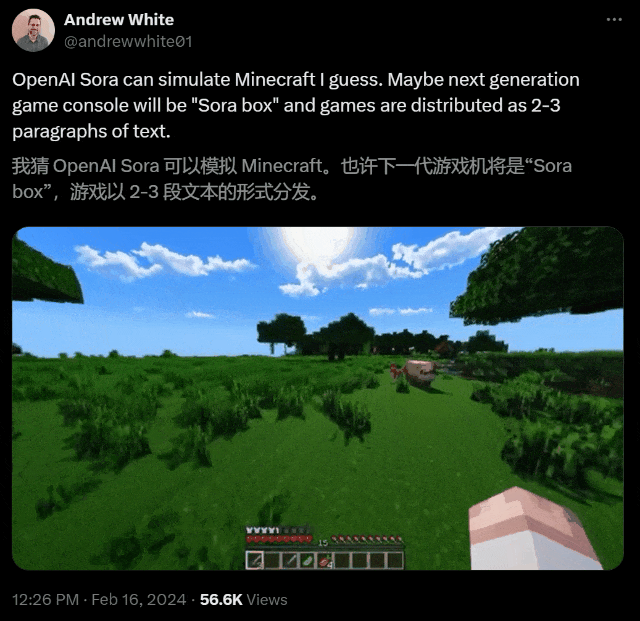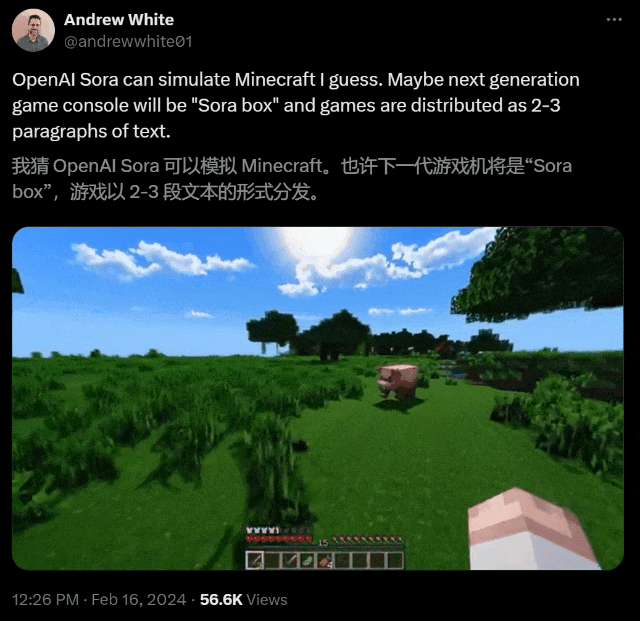
通過底層訓練和patch,Sora能夠理解和開發近乎完美的視覺模擬,比如Minecraft這樣的數字世界。這樣,它就會為未來的AI創造出訓練內容。有數據和系統,AI就能更好地理解世界。

從此,我們可以解鎖VR的新高度,因為它改變我們看待數字環境的方式,將VR的邊界推向新的高度,創建出近乎完美的3D環境。可以在Apple Vision Pro或Meta Quest上按需與空間計算配對。
除謝賽寧的解讀之外,AI專傢Vincent Koc,也對此展開詳細分析。
Sora的獨特方法如何改變視頻生成
以往,生成模型的方法包括GAN、自回歸、擴散模型。它們都有各自的優勢和局限性。
而Sora引入的,是一種全新的范式轉變——新的建模技術和靈活性,可以處理各種時間、縱橫比和分辨率。
Sora所做的,是把Diffusion和Transformer架構結合在一起,創建diffusion transformer模型。
於是,以下功能應運而生——
文字轉視頻:將文字內容變成視頻
圖片轉視頻:賦予靜止圖像動態生命
視頻風格轉換:改變原有視頻的風格
視頻時間延展:可以將視頻向前或向後延長
創造無縫循環視頻:制作出看起來永無止境的循環視頻
生成單幀圖像視頻:將靜態圖像轉化為最高2048 x 2048分辨率的單幀視頻
生成各種格式的視頻:支持從1920 x 1080到1080 x 1920之間各種分辨率格式
模擬虛擬世界:創造出類似於Minecraft等遊戲的虛擬世界
創作短視頻:制作最長達一分鐘的視頻,包含多個短片
這就好比,我們正在廚房裡。
傳統的視頻生成模型,比如Pika和RunwayML,就像照著食譜做飯的廚師一樣。
他們可以做出好吃的菜肴(視頻),但會受到他們所知的食譜(算法)所限。
使用特定的成分(數據格式)和技術(模型架構),它們隻擅長烘焙蛋糕(短片)或烹飪意大利面(特定類型的視頻)。

而與他們不同的是,Sora是一位基礎知識紮實的新型廚師。
它不僅能照著舊食譜做菜,還能自己發明新食譜!
這位住大廚多才多藝,對於食材(數據)和技術(模型架構)的掌握十分靈活,因而能夠做出各種高質量的視頻。
探尋Sora秘密成分的核心:時空patch
時空patch,是Sora創新的核心。
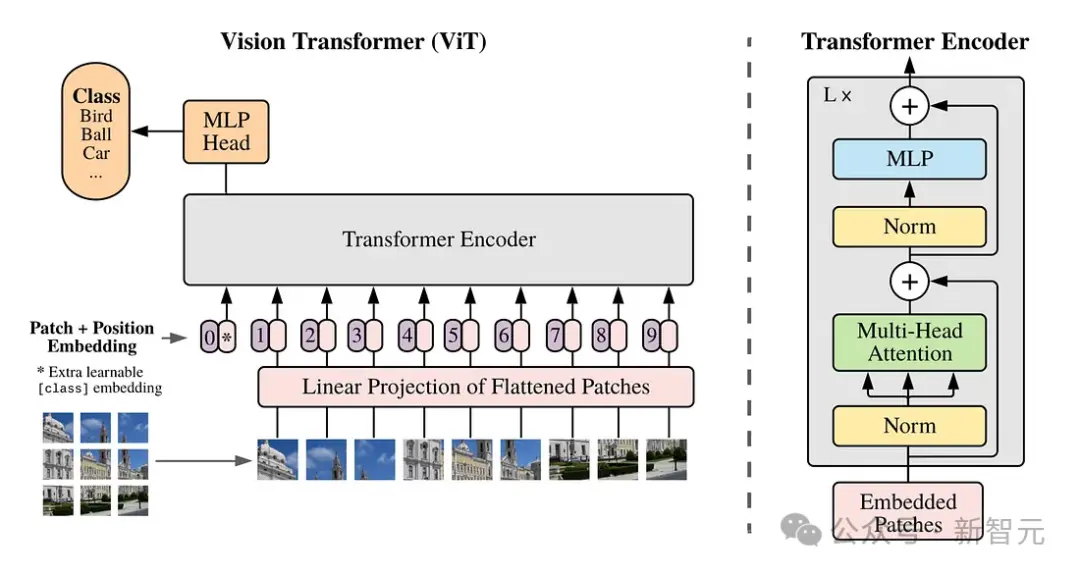
它建立在Google DeepMind早期對NaViT和ViT(視覺Transformer)的研究之上。

論文地址:https://arxiv.org/abs/2307.06304
而這項研究,又是基於一篇2021年的論文“An Image is Worth 16x16 Words”。

論文地址:https://arxiv.org/abs/2010.11929
傳統上,對於視覺Transformer,研究者都是使用一系列圖像patch來訓練用於圖像識別的Transformer模型,而不是用於語言Transformer的單詞。
這些patch,能使我們能夠擺脫卷積神經網絡進行圖像處理。

然而,視覺Transforemr對圖像訓練數據的限制是固定的,這些數據的大小和縱橫比是固定的,這舊限制質量,並且需要大量的圖像預處理。

而通過將視頻視為patch序列,Sora保持原始的縱橫比和分辨率,類似於NaViT對圖像的處理。
這種保存,對於捕捉視覺數據的真正本質至關重要!
通過這種方法,模型能夠從更準確的世界表示中學習,從而賦予Sora近乎神奇的準確性。
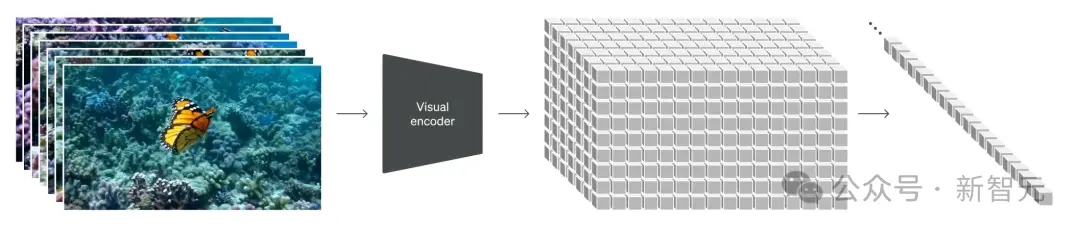
時空patch的可視化
這種方法使Sora能夠有效地處理各種視覺數據,而無需調整大小或填充等預處理步驟。
這種靈活性確保每條數據都有助於模型的理解,就像廚師可以使用各種食材,來增強菜肴的風味特征一樣。
時空patch對視頻數據詳細而靈活的處理,為精確的物理模擬和3D一致性等復雜功能奠定基礎。
從此,我們可以創建看起來逼真且符合世界物理規則的視頻,人類也得以一窺AI創建復雜、動態視覺內容的巨大潛力。
多樣化數據在訓練中的作用
訓練數據的質量和多樣性,對於模型的性能至關重要。
傳統的視頻模型,是在限制性更強的數據集、更短的長度和更窄的目標上進行訓練的。
而Sora利用龐大而多樣的數據集,包括不同持續時間、分辨率和縱橫比的視頻和圖像。
它能夠重新創建像Minecraft這樣的數字世界,以及來自Unreal或Unity等系統的模擬世界鏡頭,以捕捉視頻內容的所有角度和各種風格。
這樣,Sora就成一個“通才”模型,就像GPT-4對於文本一樣。
這種廣泛的訓練,使Sora能夠理解復雜的動態,並生成多樣化、高質量的內容。
這種方法模仿在各種文本數據上訓練LLM的方式,將類似的理念應用於視覺內容,實現通才功能。
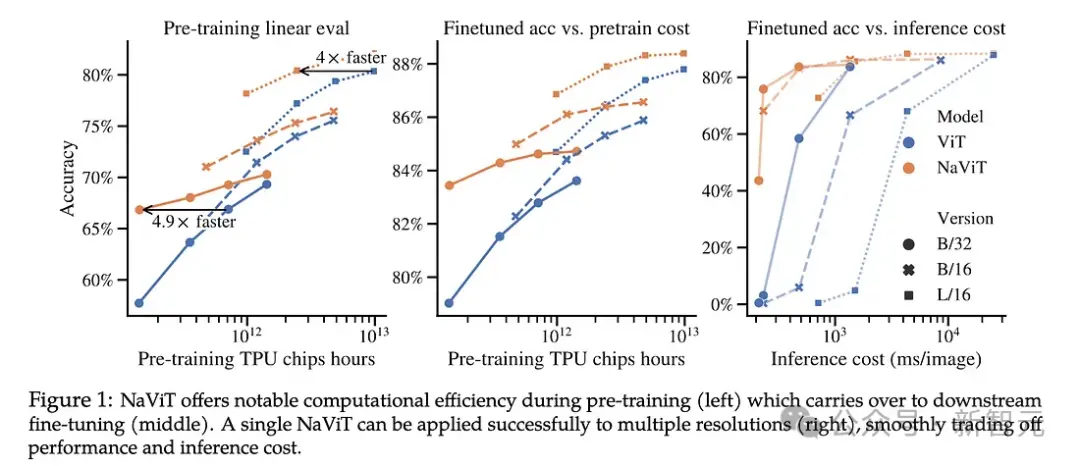
可變Patches NaVit與傳統的視覺Transformer
NaViT模型通過將來自不同圖像的多個patch打包到單個序列中,得到顯著的訓練效率和性能提升一樣。
同樣地,Sora利用時空patch在視頻生成中實現類似的效率。
這種方法允許模型從龐大的數據集中更有效地學習,提高模型生成高保真視頻的能力,同時降低與現有建模架構相比所需的計算量。
讓物理世界栩栩如生:Sora對3D和連續性的掌握
3D空間和物體的一致性,是Sora演示中的關鍵亮點。
通過對各種視頻數據進行訓練,無需對視頻進行調整或預處理,Sora就學會以令人印象深刻的精度對物理世界進行建模,原因就在於,它能夠以原始形式使用訓練數據。
在Sora生成的視頻中,物體和角色在三維空間中令人信服地移動和交互,即使它們被遮擋或離開框架,也能保持連貫性。
從此,現實不存在,創造力和現實主義的界限被突破。
並且,Sora為模型的可能性設立全新的標準,開源社區很可能會掀起視覺模型的全新革命。
而現在,Sora的旅程才剛剛開始呢,正如OpenAI所說,擴展視頻生成模型是構建物理世界通用模擬器的一條有前途的道路。
前方,就是AGI和世界模型。
不過好在,OpenAI員工透露說,Sora短期內不會面世。

一位OpenAI員工發推表示,現在Sora隻會在有限的范圍內試用,現在放出的demo主要是為獲得社會大眾對它能力的反應
現在,標榜要開發負責任AGI的OpenAI,應該不會冒著風險給大眾拋出一個潘多拉魔盒。
參考資料:
https://twitter.com/sainingxie/status/1758433679238471744
https://towardsdatascience.com/explaining-openai-soras-spacetime-patches-the-key-ingredient-e14e0703ec5