威爾·史密斯的這段視頻,把全網都騙!其實Sora的技術路線,早已被人預言。李飛飛去年就用Transformer做出逼真的視頻。但隻有OpenAI大力出奇跡,跑在所有人前面。今天,全體AI社區都被威爾·史密斯發出的這段視頻震驚!
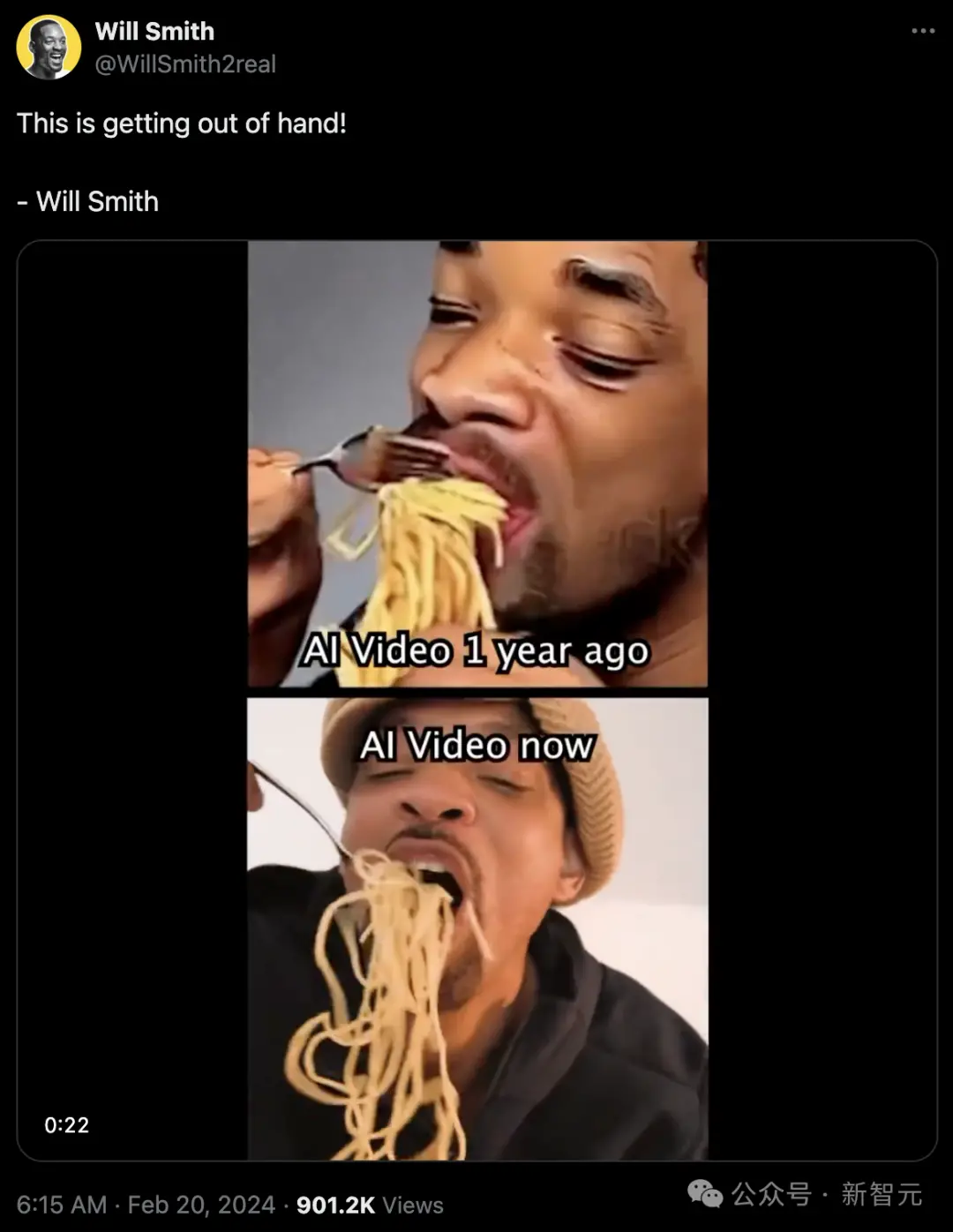
你以為,上面是一年前的AI視頻,下面是如今的AI視頻?

錯!這個所謂AI生成的視頻,其實正是威爾史密斯本人!

威爾·史密斯吃意面這個“圖靈測試”,曾讓Runway、Pika等屢屢翻車。
Runway生成的,是這樣的——



但如今,Sora已經做到逼真似真人、毫無破綻,所以才讓威爾史密斯成功騙過大眾,這太可怕!

Sora的出現,其實在今年1月就已被人預言
1月5日,一位前阿裡的AI專傢表示——
我認為,Transformer框架和LLM路線,將是AI視頻的一個突破口和新范式,它將使AI視頻更加連貫、一致,並且時長更長。目前的Diffusion+Unet路線(如Runway、Pika等),隻是暫時的解決方案。

無獨有偶,斯坦福學者李飛飛在去年年底,就用Transformer就做出逼真的視頻。
而馬毅教授也表示,自己團隊去年在NeurIPS一篇論文中也已經證實,用Transformer可以實現diffusion和denosing。

馬毅團隊提出:假設數據分佈是mixed Gaussians,那Transformer blocks就是在實現diffusion/擴散和denoising/壓縮
能想到Sora技術路線的,肯定不止一個人。可是全世界第一個把Sora做出來的,就是OpenAI。
OpenAI為何總能成功?無他,唯手快爾。
Runway和Pika“點歪”的科技樹,被OpenAI掰正
在此之前,Runway、Pika等AI視頻工具吸引不少聚光燈。

而OpenAI的Sora,不僅效果更加真實,就是把Transformer對前後文的理解和強大的一致性,發揮得淋漓盡致。
這個全新的科技樹,可真是夠震撼的。
不過我們在開頭也可以看到,OpenAI並不是第一個想到這個的人。Transformer框架+LLM路線這種新范式,其實早已有人想到。
就如同AI大V“闌夕”所言,OpenAI用最簡單的話,把最復雜的技術講清楚——
“圖片隻是單幀的視頻。”
科技行業這種從容的公共表達,真是前所未見,令人醍醐灌頂。

“闌夕”指出,“圖片隻是單幀的視頻”的妙處就在於,圖片的創建不會脫離時間軸而存在,Sora實際上是提前給視頻寫腳本的。
甚至無論用戶怎樣Prompt,Sora AI都有自己的構圖思維。
而這,就是困住Runway、Pika等公司最大的問題。
它們的思路,基本都是基於一張圖片來讓AI去想象,完成延伸和填補,從而疊加成視頻。比拼的是誰傢的AI更能理解用戶想要的內容。
因此,這些AI視頻極易發生變形,如何保持一致性成登天般的難題。
Diffusion Model這一局,是徹底輸給Transformer。
ChatGPT故事再次重演,Sora其實站在Google的肩膀上
讓我們深入扒一扒,Sora是站在哪些前人的肩膀上。
簡而言之,最大創新Patch的論文,是Google發表的。
Diffusion Transformer的論文,來自William Peebles和謝賽寧。
此外,Meta等機構、UC伯克利等名校皆有貢獻。
William Peebles和謝賽寧提出的框架
紐約大學計算機系助理教授謝賽寧在分析Sora的技術報告後表示,Sora應該是基於自己和William Peebles提出的框架設計而成。

這篇提出Sora基礎架構的論文,去年被ICCV收錄。

論文地址:https://arxiv.org/abs/2212.09748
隨後,William Peebles加入OpenAI,領導開發Sora的技術團隊。

圖靈三巨頭之一、Meta AI主管LeCun,也轉發謝賽寧的帖子表示認可。
巧合的是,謝賽寧是LeCun的前FAIR同事、現紐約大學同事,William Peebles是LeCun的前伯克利學生、現任OpenAI工程師。AI果然是個圈。

最近,謝賽寧對說自己是Sora作者的說法進行辟謠
CVPR“有眼不識泰山”,拒掉Sora基礎論文
有趣的是,Diffusion Transformer這篇論文曾因“缺乏創新性”被CVPR 2023拒收,後來才被ICCV2003接收。
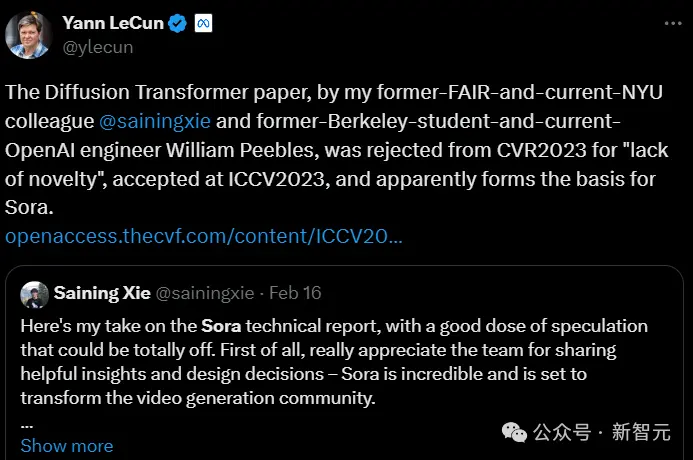
謝賽寧表示,他們在DIT項目沒有創造太多的新東西,但是兩個方面的問題:簡單性和可擴展性。這可能就是Sora為什麼要基於DIT構建的主要原因。
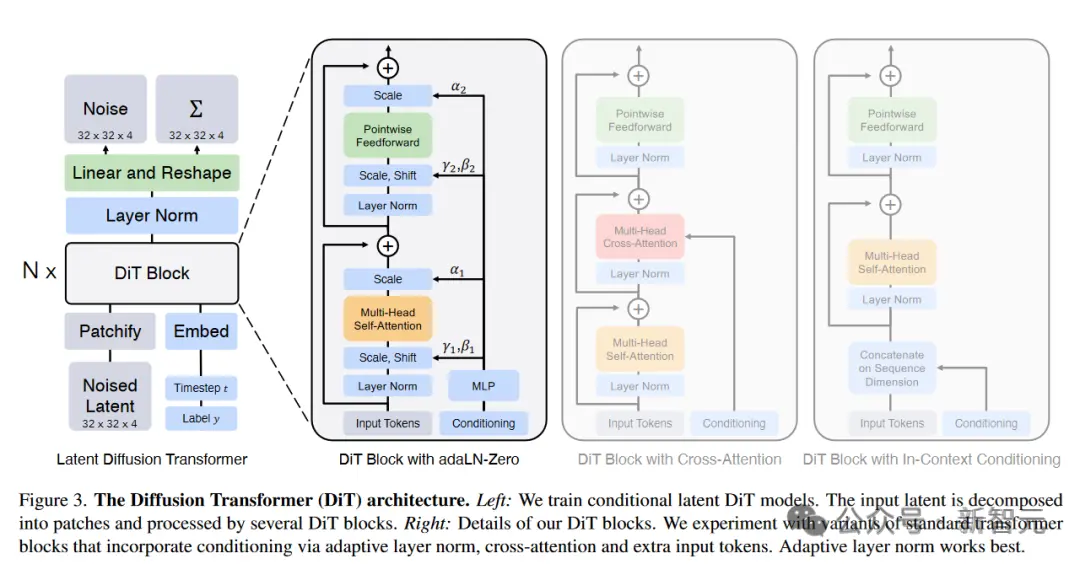
此前,生成模型的方法包括GAN、自回歸、擴散模型。它們都有各自的優勢和局限性。
而Sora引入的,是一種全新的范式轉變——新的建模技術和靈活性,可以處理各種時間、縱橫比和分辨率。
Sora所做的,是把Diffusion和Transformer架構結合在一起,創建diffusion transformer模型。
這也即是OpenAI的創新之處。
時空Patch是Google的創新
時空Patch,是Sora創新的核心。
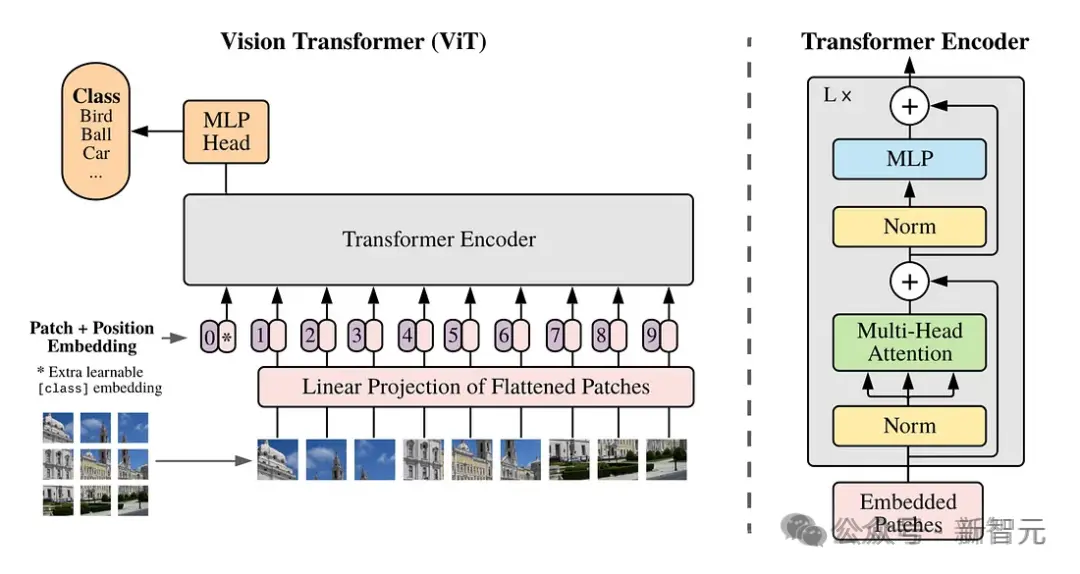
它建立在Google DeepMind早期對NaViT和ViT(視覺Transformer)的研究之上。

論文地址:https://arxiv.org/abs/2307.06304
而這項研究,又是基於一篇2021年的論文“An Image is Worth 16x16 Words”。

論文地址:https://arxiv.org/abs/2010.11929
傳統上,對於視覺Transformer,研究者都是使用一系列圖像Patch來訓練用於圖像識別的Transformer模型,而不是用於語言Transformer的單詞。
這些Patch,能使我們能夠擺脫卷積神經網絡進行圖像處理。

然而,視覺Transforemr對圖像訓練數據的限制是固定的,這些數據的大小和縱橫比是固定的,這就限制質量,並且需要大量的圖像預處理。

而通過將視頻視為Patch序列,Sora保持原始的縱橫比和分辨率,類似於NaViT對圖像的處理。
這種保存,對於捕捉視覺數據的真正本質至關重要!
通過這種方法,模型能夠從更準確的世界表示中學習,從而賦予Sora近乎神奇的準確性。
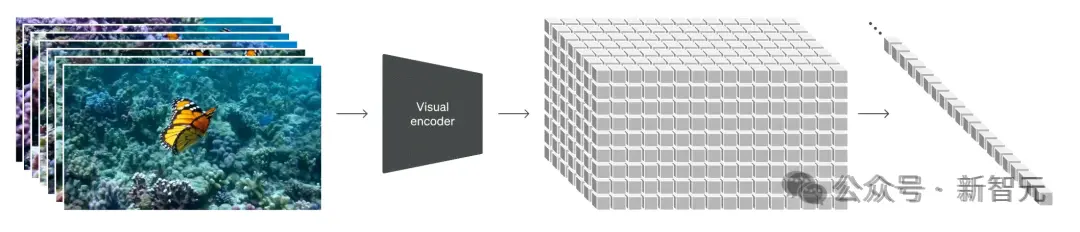
時空Patch的可視化
GooglePatch的論文,發表於2021年。3年後,OpenAI基於這項技術,做出Sora。
這段歷史看起來是不是有點眼熟?簡直就像“Attention Is All You Need”的歷史重演。
2017年6月12日,8位Google研究人員發表Attention is All You Need,大名鼎鼎的Transformer橫空出世。
它的出現,讓NLP變天,成為自然語言領域的主流模型。

論文地址:https://arxiv.org/pdf/1706.03762.pdf
它完全摒棄遞歸結構,依賴註意力機制,挖掘輸入和輸出之間的關系,進而實現並行計算。
在Google看來,Transformer是一種語言理解的新型神經網絡架構。不過它當初被設計出來,是為解決翻譯問題。
而後來,Transformer架構被OpenAI拿來發揚光大,成為ChatGPT這類LLM的核心。
2022年,OpenAI用Google17年發表的Transformer做出ChatGPT。
2024年,OpenAI用Google21年發表的Patch做出Sora。
這也讓人不由感慨:誠如《為什麼偉大不能被計劃》一書中所言,偉大的成就與發明,往往是偏離最初計劃的結果。
前人的無心插柳,給後人的成功做好奠基石,而一條成功的道路是如何踏出的,完全是出於偶然。
Meta微軟UC伯克利斯坦福MIT亦有貢獻
此外,從Sora參考文獻中可以看出,多個機構和名校都對Sora做出貢獻。

比如,用Transformer做擴散模型的去噪骨幹這個方法,早已被斯坦福學者李飛飛證明。
在去年12月,李飛飛攜斯坦福聯袂Google,用Transformer生成逼真視頻。
生成的效果可謂媲美Gen-2比肩Pika,當時許多人激動地感慨——2023年已成AI視頻元年,誰成想2024一開年,OpenAI新的震撼就來!
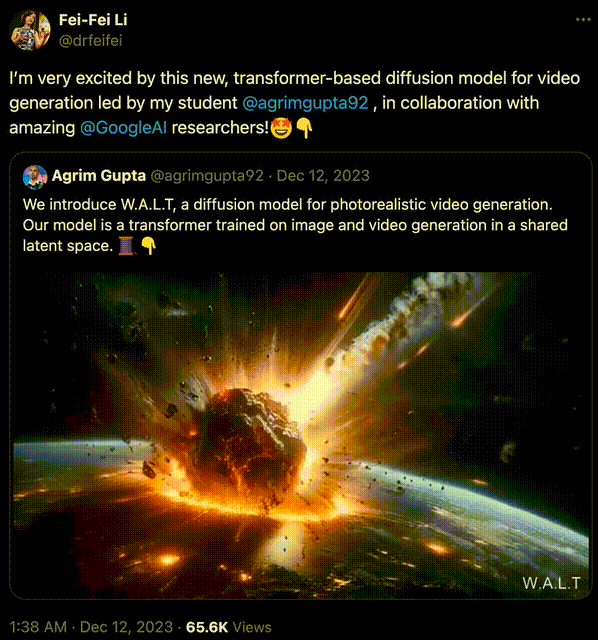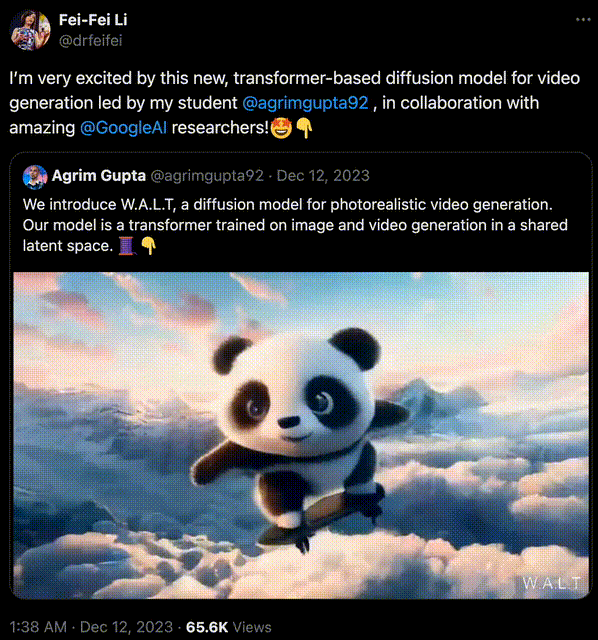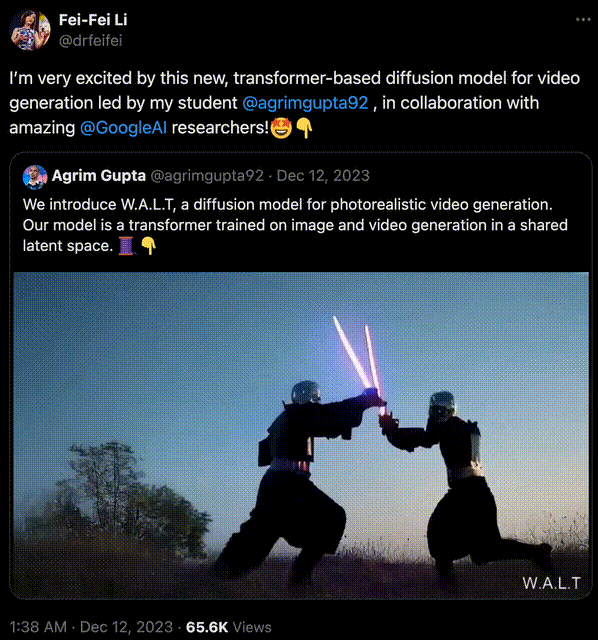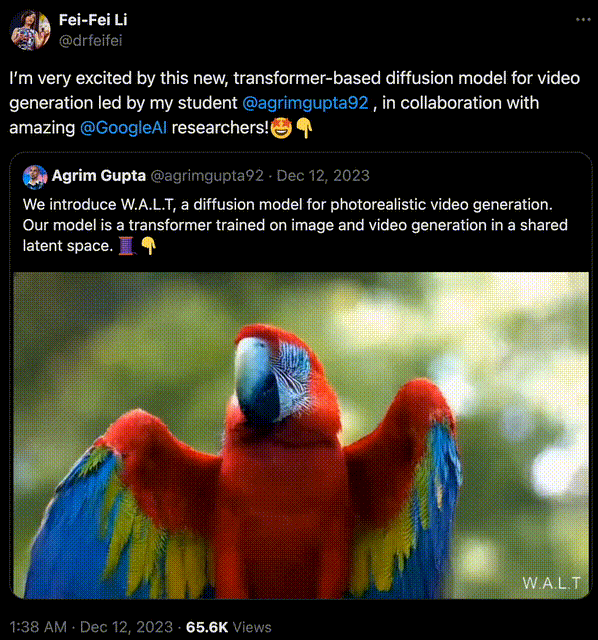
李飛飛團隊做的,是一個在共享潛空間中訓練圖像和視頻生成的,基於Transformer的擴散模型。
史上首次,AI學者證明:Transformer架構可以將圖像和視頻編碼到一個共享的潛空間中!

論文:https://walt-video-diffusion.github.io/assets/W.A.L.T.pdf
MSRA和北大聯合團隊提出的統一多模態預訓練模型——NÜWA(女媧),也為Sora做出貢獻。
此前的多模態模型要麼隻能處理圖像,要麼隻能處理視頻,而NÜWA則可以為各種視覺合成任務,生成新的圖像和視頻數據。

項目地址:https://github.com/microsoft/NUWA
為在不同場景下同時覆蓋語言、圖像和視頻,團隊設計一個三維變換器編碼器-解碼器框架。
它不僅可以處理作為三維數據的視頻,還可以適應分別作為一維和二維數據的文本和圖像。
在8個下遊任務中,NÜWA都取得新的SOTA,在文本到圖像生成中的表現,更是直接超越DALL-E。
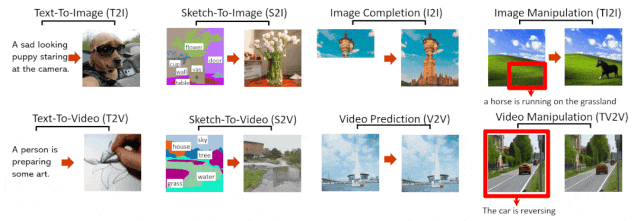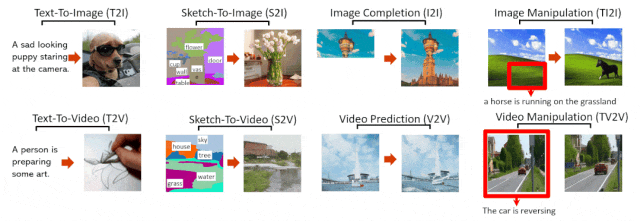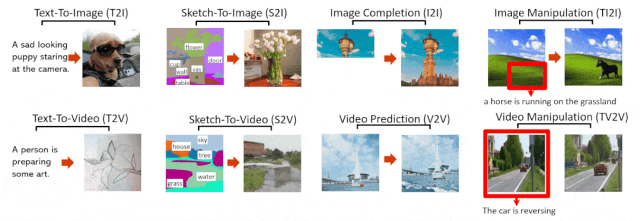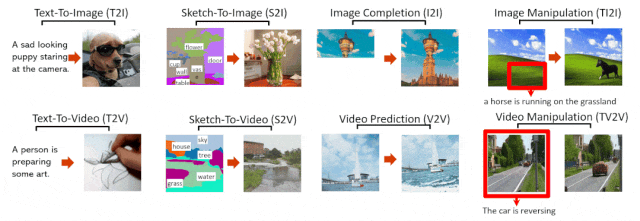
NÜWA模型支持的8種典型視覺生成任務
草蛇灰線,伏脈千裡。踩在前人的肩膀上,通過敏銳的直覺和不眠不休的高強度工作,OpenAI的研究者就這樣點對科技樹。
大力出奇跡的時候到,不拿出一百億美金的大廠就會out
當然,還有一點不得不承認的是:OpenAI能做出Sora,也是因為背後大量的資金支持。
沒有資金,就沒有數據和算力。即使點對科技樹也無法驗證。
可以說,Sora是另一個建立在Transformer上的暴力美學。
現在,芯片+AI是人類有史以來最大的科技浪潮。
不拿出100億美金的大廠,就要掉隊。
國內這邊,格局又會怎樣變換?讓我們拭目以待。