內容生成AI進入視頻時代!Meta發佈“用嘴做視頻”僅一周,GoogleCEO劈柴哥接連派出兩名選手上場競爭。第一位ImagenVideo與Meta的Make-A-Video相比突出一個高清,能生成1280*768分辨率、每秒24幀的視頻片段。

另一位選手Phenaki,則能根據200個詞左右的提示語生成2分鐘以上的長鏡頭,講述一個完整的故事。

網友看過後表示,這一切進展實在太快。


也有網友認為,這種技術一旦成熟,會沖擊短視頻行業。

那麼,兩個AI具體有什麼能力和特點,我們分別來看。
Imagen Video:理解藝術風格與3D結構
Imagen Video同樣基於最近大火的擴散模型,直接繼承自5月份的圖像生成SOTA模型Imagen。
除分辨率高以外,還展示出三種特別能力。
首先它能理解並生成不同藝術風格的作品,如“水彩畫”或者“像素畫”,或者直接“梵高風格”。

它還能理解物體的3D結構,在旋轉展示中不會變形。
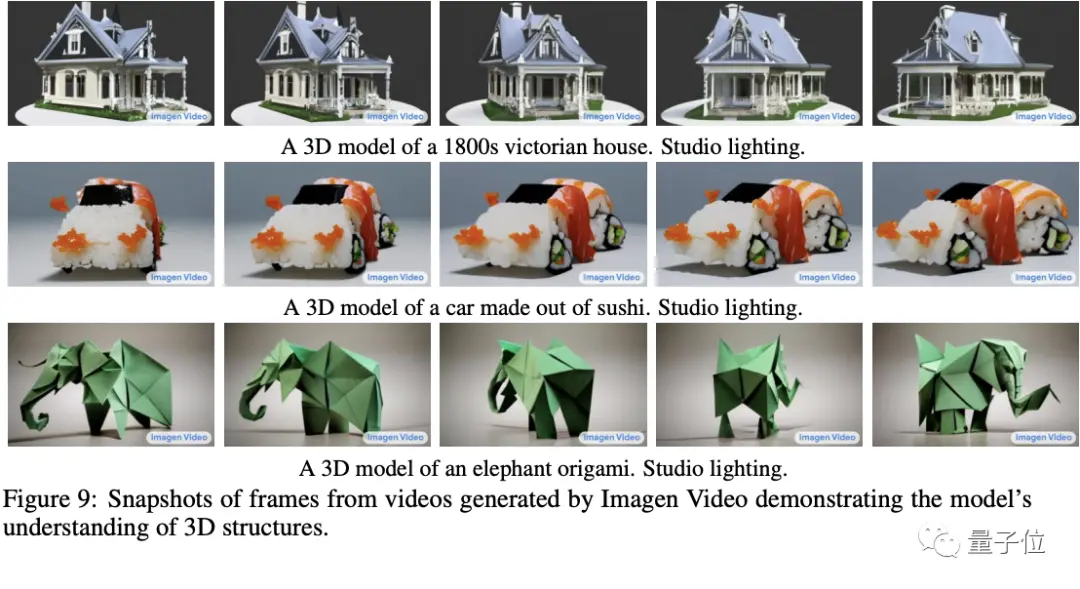
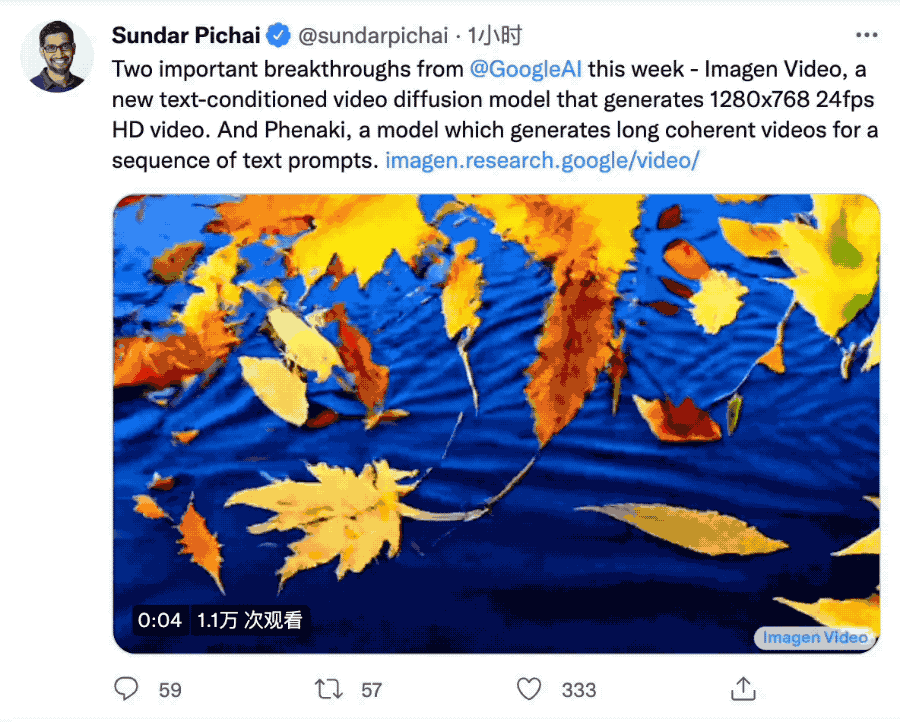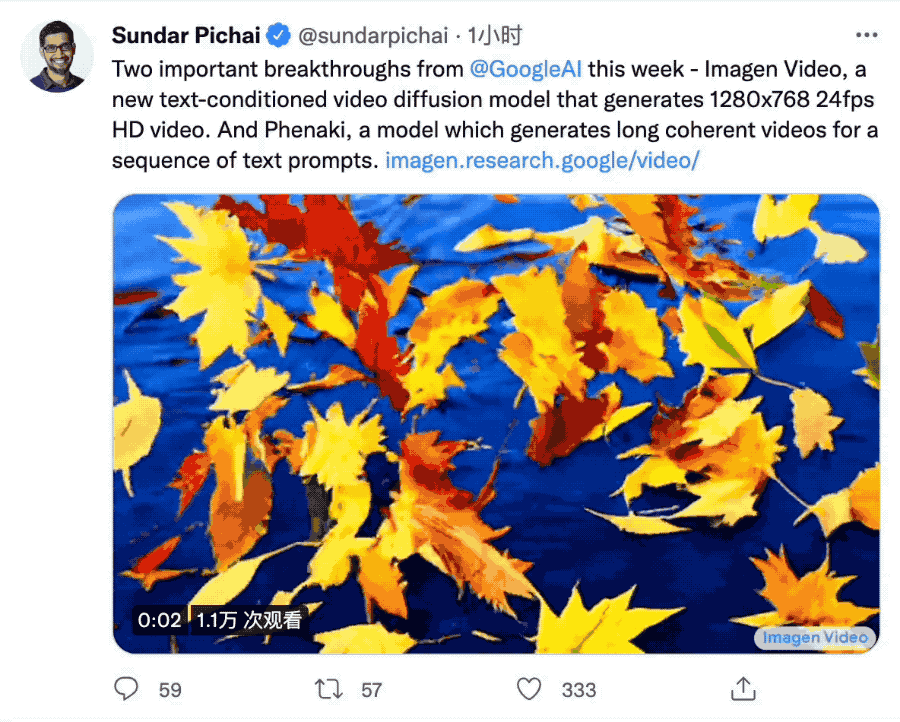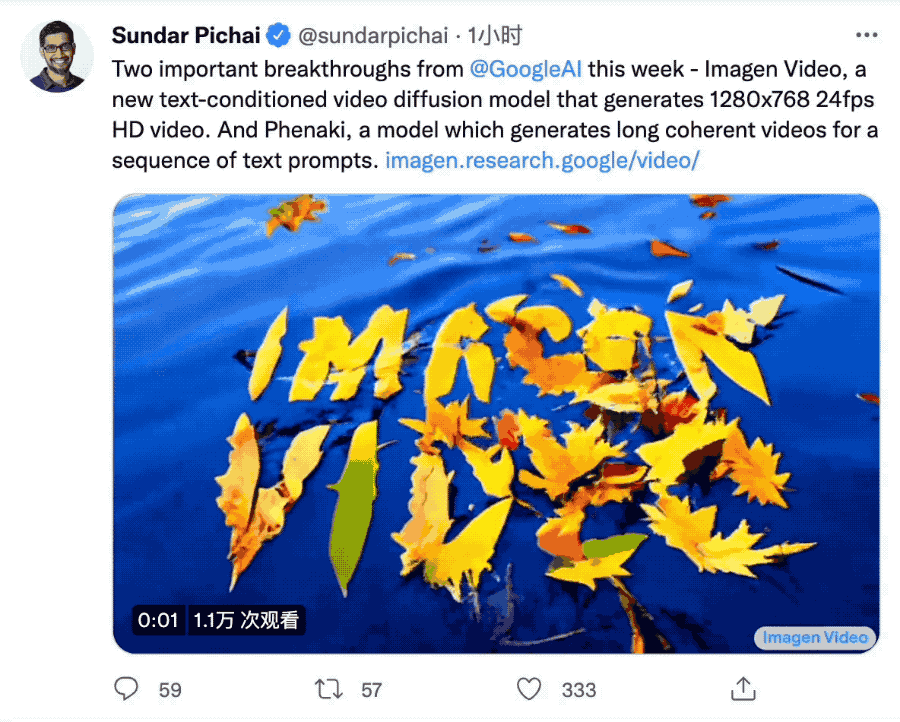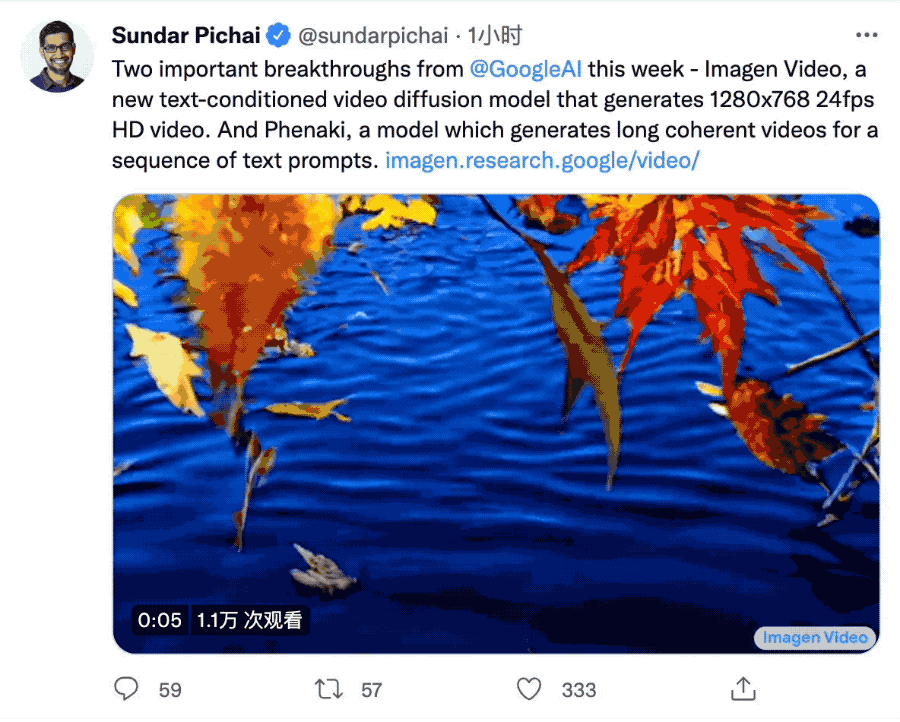
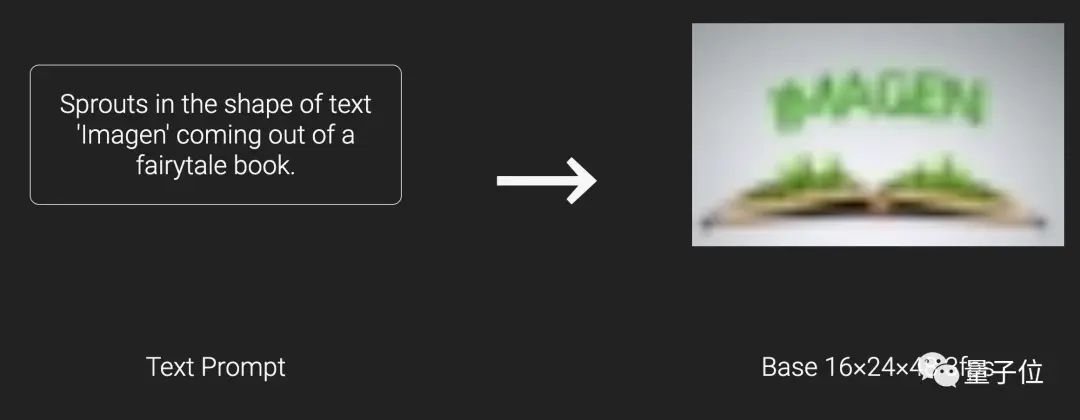
最後它還繼承Imagen準確描繪文字的能力,在此基礎上僅靠簡單描述產生各種創意動畫,

這效果,直接當成一個視頻的片頭不過分吧?

除應用效果出色以外,研究人員表示其中用到的一些優化技巧不光對視頻生成有效,可以泛化至一般擴散模型。
具體來說,Imagen Video是一系列模型的集合。
語言模型部分是Google自傢的T5-XXL,訓練好後凍結住文本編碼器部分。
與負責從文本特征映射到圖像特征的CLIP相比,有一個關鍵不同:
語言模型隻負責編碼文本特征,把文本到圖像轉換的工作丟給後面的視頻擴散模型。
基礎模型,在生成圖像的基礎上以自回歸方式不斷預測下一幀,首先生成一個48*24、每秒3幀的視頻。
接下來,一系列空間超分辨率(Spatial Super-Resolution)與時間超分辨率(Temporal Super-Resolution)模型接連對視頻做擴展處理。
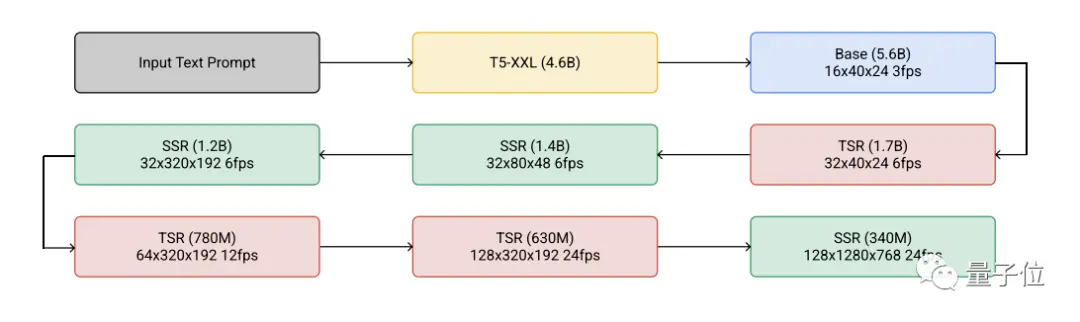
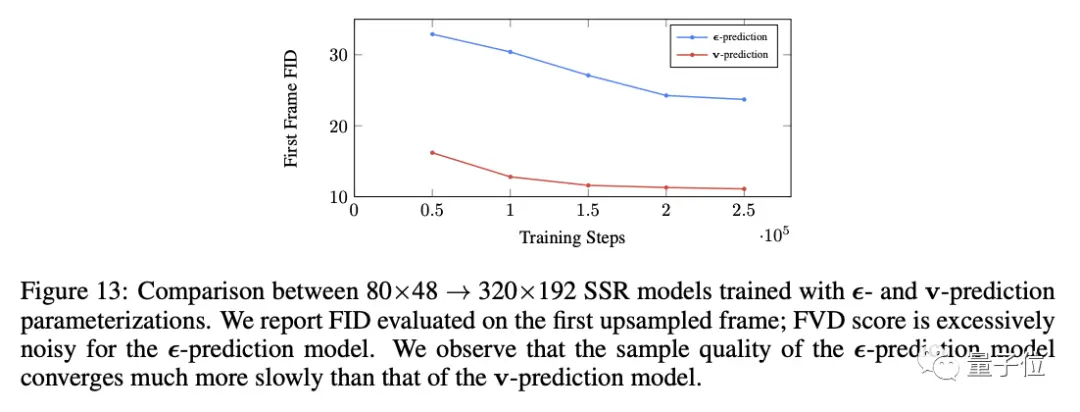
所有7種擴散模型都使用v-prediction parameterization方法,與傳統方法相比在視頻場景中可以避免顏色偏移。

這種方法擴展到一般擴散模型,還使樣本質量指標的收斂速度更快。
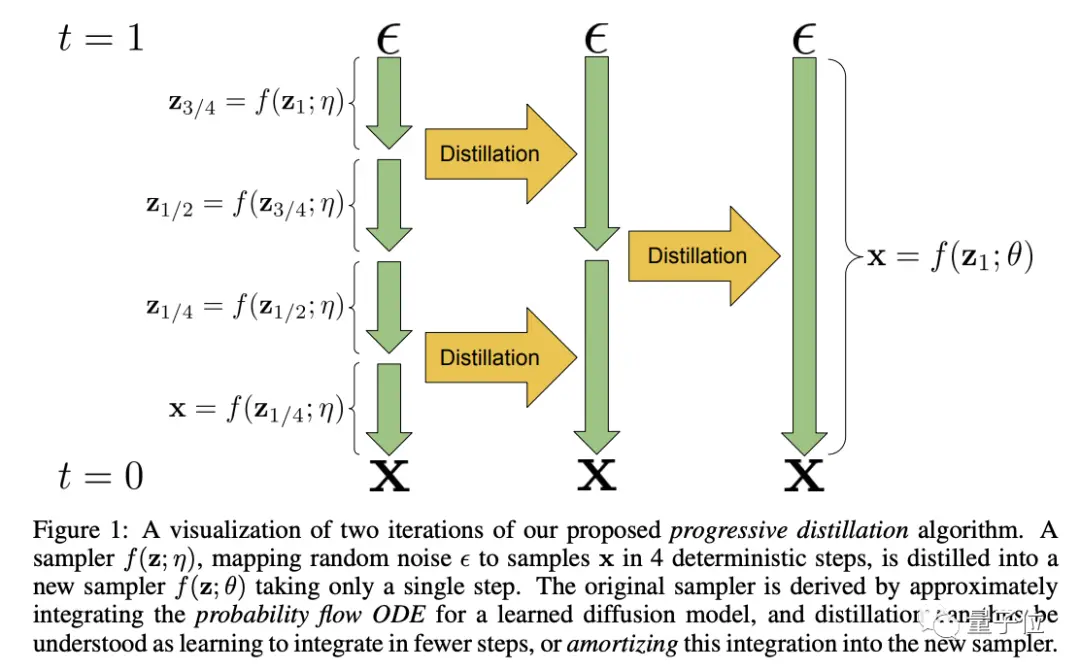
此外還有漸進式蒸餾(Progressive Distillation),將每次迭代所需的采樣步驟減半,大大節省顯存消耗。
這些優化技巧加起來,終於使生成高清視頻成為可能。
Phenaki:人人都能是“導演”
Phenaki的論文投ICLR 2023會議,在一周前Meta發佈Make-a-video的時候還是匿名雙盲評審狀態。
如今信息公開,原來研究團隊同樣來自Google。
在公開的信息中,Phenaki展示它交互生成視頻的能力,可以任意切換視頻的整體風格:高清視頻/卡通,還能夠切換任意場景。


還可以向Phenaki輸入一個初始幀以及一個提示,便能生成一段視頻。

這都還是開胃小菜,Phenaki真正的大招是:講故事,它能夠生成2分鐘以上的長視頻,通過輸入長達200多個字符的系列提示來得到。
(那有這個模型,豈不是人人都能當導演?手動狗頭)

從文本提示到視頻,計算成本高、高質量文本視頻數據數量有限以及視頻長度可變一直以來都是此類模型發展的難題。
以往的大多數AI模型都是通過單一的提示來生成視頻,但若要生成一個長時間並且連貫的視頻這遠遠不夠。
而Phenaki則能生成2分鐘以上的視頻,並且還具備故事情節,這主要歸功於它能夠根據一系列的提示來生成視頻的能力。
具體來說,研究人員引入一個新的因果模型來學習表示視頻:將視頻視作圖像的一個時間序列。
這個模型基於transformer,可以將視頻分解成離散的小表示,而分解視頻則是按照時間的因果順序來進行的。
再講通俗一點,就是通過空間transformer將單個提示進行編碼,隨後再用因果transformer將多個編碼好的提示串聯起來。
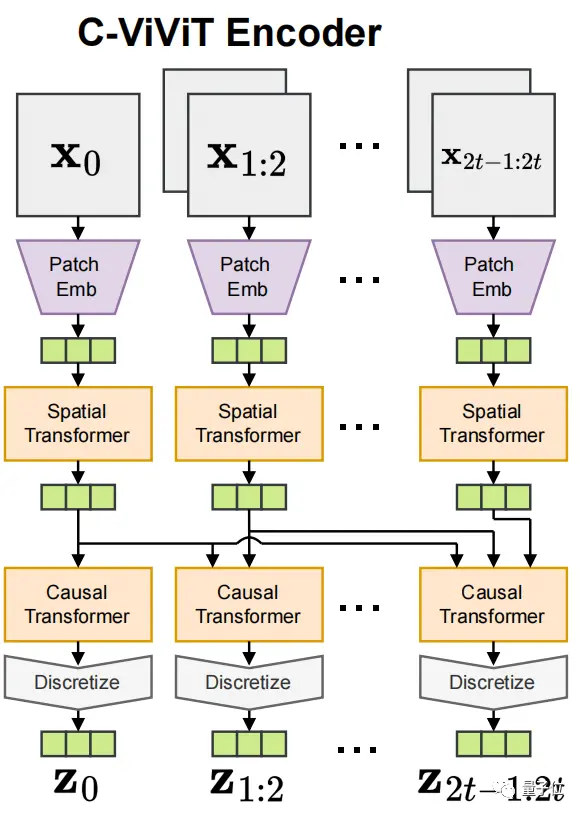
一個提示生成一段視頻,這樣一來,視頻序列便可以沿著提示中描述的時間序列將整個“故事”串在一起。
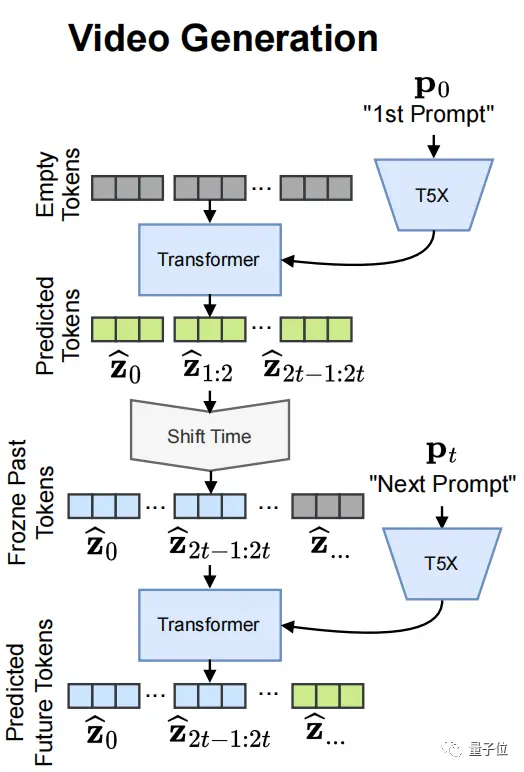
因為將視頻壓縮為離散的圖像序列,這樣也大大減少AI處理標記視頻的數量,在一定程度上降低模型的訓練成本。
提到模型訓練,和大型圖像系統一樣,Phenaki也主要使用文本-圖像數據進行訓練,此外,研究人員還用1.4秒,幀率8FPS的短視頻文本對Phenaki進行訓練。
僅僅通過對大量圖像文本對以及少量視頻文本例子進行聯合訓練,便能達到突破視頻數據集的效果。
Imagen Video和Phenaki,Google接連放出大招,從文本到視頻的AI發展勢頭迅猛。
值得一提的是,Imagen Video一作表示,兩個團隊將合作進行下一步研究。
嗯,有的網友已經等不及。

One More Thing
出於安全和倫理的考慮,Google暫時不會發佈兩個視頻生成模型的代碼或Demo。

不過既然發論文,出現開源復刻版本也隻是時間問題。
畢竟當初Imagen論文出來沒幾個月,GitHub上就出現Pytorch版本。
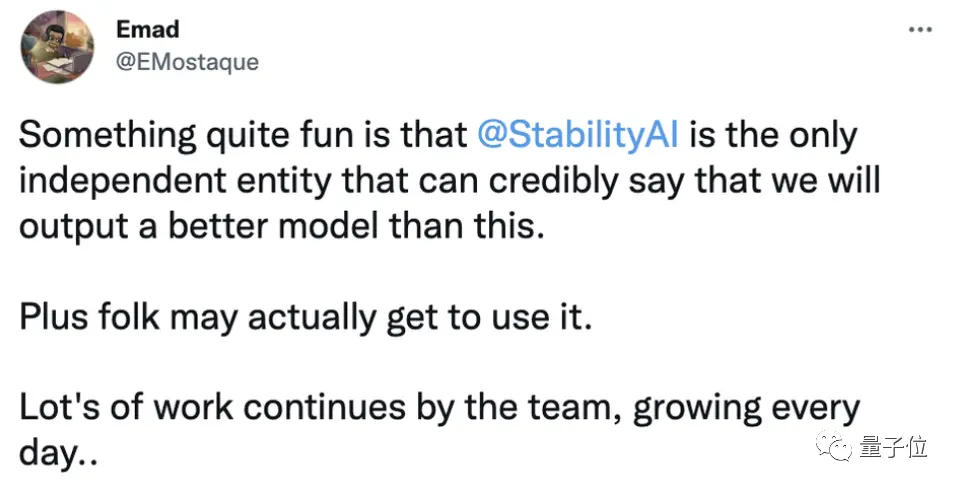
另外Stable Diffusion背後的StabilityAI創始人兼CEO也說過,將發佈比Meta的Make-A-Video更好的模型,而且是大傢都能用上的那種。
當然,每次AI有新進展後都會不可避免地碰到那個話題——AI會不會取代人類。

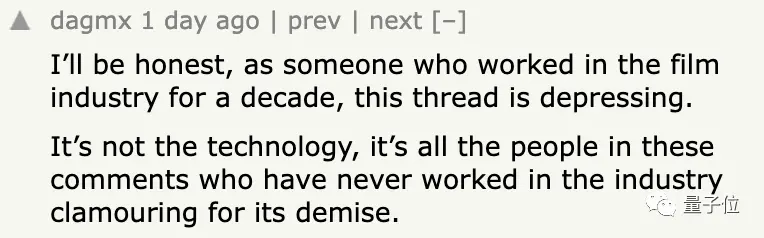
目前來說,一位影視行業的工作者表示還不到時候:
老實說,作為一個在電影行業工作十年的人,這個話題令人沮喪。
在他看來,當前的視頻生成AI在外行看起來已經足夠驚艷,不過業內人士會認為AI還缺乏對每一個鏡頭的精細控制。
對於這個話題,StabilityAI新任首席信息官Daniel Jeffries此前撰文表示,AI最終會帶來更多的工作崗位。
如相機的發明雖然取代大部分肖像畫傢,但也創造攝影師,還開辟電影和電視這樣的全新產業。
5年後再回看的話,反對AI就像現在反對Photoshop一樣奇怪,AI隻不過是另一個工具。
Jeffries稱未來是環境人工智能(Ambient AI)的時代,各個行業、各個領域都會在人工智能的加持下進行發展。
不過現在我們需要的是一個更開放的人工智能環境,也就是說:開源!
最後,如果你現在就想玩一下AI生成視頻的話,可以先到HuggingFace上試試清華與智源實驗室的Cogvideo。