Google研究院和Google的人工智能研究實驗室DeepMind詳細介紹Med-Gemini(一個專門用於醫學的高級人工智能模型系列)的驚人影響力。這是臨床診斷領域的一大進步,具有巨大的現實潛力。
醫生每天要治療眾多病人,他們的需求從簡單到非常復雜。為提供有效的醫療服務,他們必須熟悉每位患者的健康記錄,解最新的治療程序和治療方法。此外,建立在同理心、信任和溝通基礎上的醫患關系也至關重要。要想讓人工智能接近真實世界中的醫生,它必須能夠做到所有這些。
Google的Gemini模型是新一代多模態人工智能模型,這意味著它們可以處理來自不同模態的信息,包括文本、圖像、視頻和音頻。這些模型擅長語言和對話,理解它們所訓練的各種信息,以及所謂的"長語境推理",即從大量數據(如數小時的視頻或數十小時的音頻)中進行推理。
Gemini醫學模型具有Gemini基礎模型的所有優點,但對其進行微調。研究人員測試這些以藥物為重點的調整,並將結果寫入論文中。這篇論文長達 58 頁,內容豐富,我們選取其中最令人印象深刻的部分。
自我培訓和網絡搜索功能
要做出診斷並制定治療方案,醫生需要將自己的醫學知識與大量其他相關信息結合起來:病人的癥狀、病史、手術史和社會史、化驗結果和其他檢查結果,以及病人對先前治療的反應。治療方法是"流動的盛宴",現有的治療方法會不斷更新,新的治療方法也會不斷推出。所有這些都會影響醫生的臨床推理。
因此,Google在 Med-Gemini 中加入網絡搜索功能,以實現更高級的臨床推理。與許多以醫學為重點的大型語言模型(LLM)一樣,Med-Gemini 也是在 MedQA 上進行訓練的,MedQA 是美國醫學執照考試(USMLE)的多選題,旨在測試不同場景下的醫學知識和推理能力。
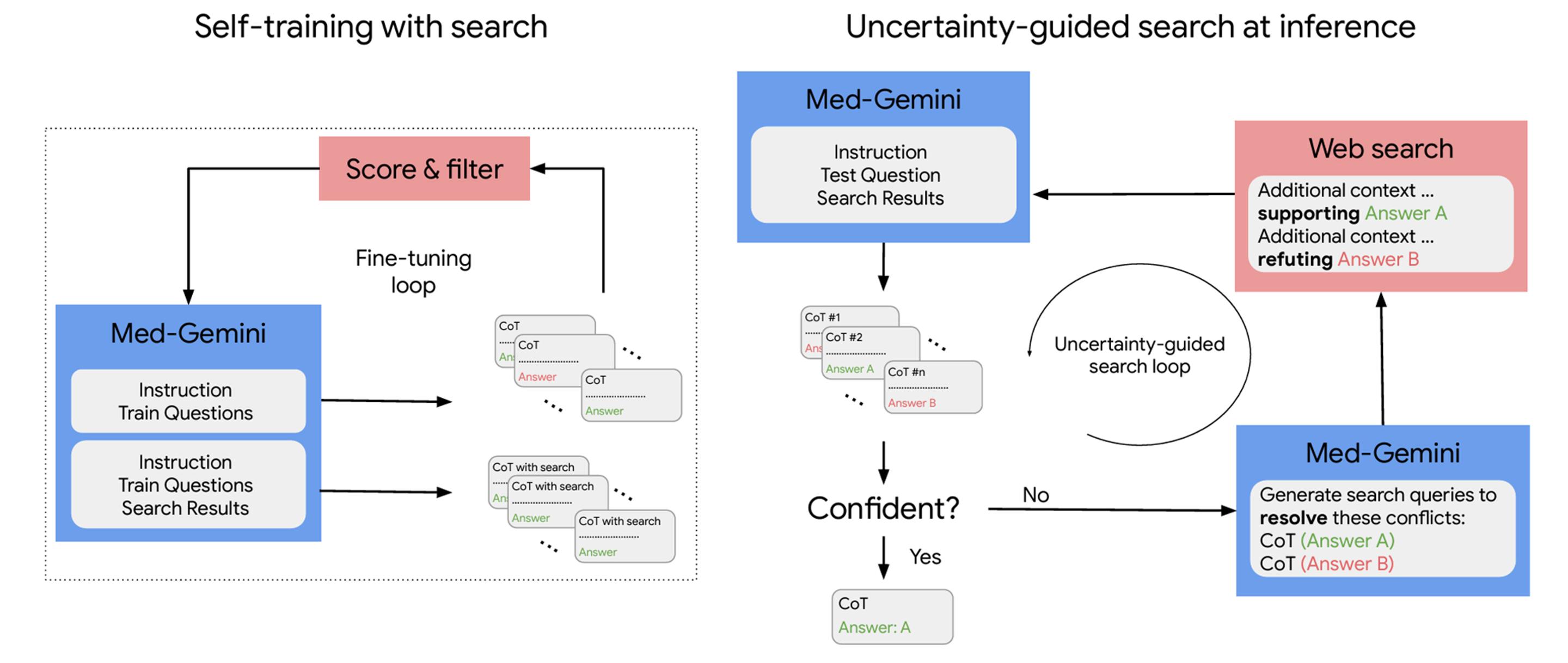
Med-Gemini 如何使用自我培訓和網絡搜索工具
不過,Google也為他們的模型開發兩個新的數據集。第一個是 MedQA-R(推理),它通過合成生成的推理解釋(稱為"思維鏈",CoTs)對 MedQA 進行擴展。第二種是 MedQA-RS(推理和搜索),它為模型提供使用網絡搜索結果作為額外上下文的指令,以提高答案的準確性。如果一個醫學問題的答案不確定,就會提示模型進行網絡搜索,以獲取更多信息來解決不確定問題。
Med-Gemini 在 14 個醫學基準上進行測試,並在 10 個基準上建立新的最先進(SoTA)性能,在可以進行比較的每個基準上都超過 GPT-4 模型系列。在 MedQA(USMLE)基準測試中,Med-Gemini 利用其不確定性指導搜索策略達到 91.1% 的準確率,比Google之前的醫學 LLMMed-PaLM 2 高出 4.5%。
在包括《新英格蘭醫學雜志》(NEJM)圖像挑戰(具有挑戰性的臨床病例圖像,從 10 個病例中做出診斷)在內的 7 項多模態基準測試中,Med-Gemini 的表現優於 GPT-4,平均相對優勢為 44.5%。
研究人員說:"雖然結果......很有希望,但還需要進一步開展大量研究。例如,我們還沒有考慮將搜索結果限制在更具權威性的醫學來源上,也沒有考慮使用多模態搜索檢索或對搜索結果的準確性和相關性以及引文的質量進行分析。此外,是否還能教會較小規模的法律碩士使用網絡搜索還有待觀察。我們將這些探索留待今後的工作中進行。"
從冗長的電子病歷中檢索特定信息
電子病歷(EHR)可能很長,但醫生需要解其中包含的內容。更復雜的是,它們通常包含相似的文本("糖尿病"與"糖尿病腎病")、拼寫錯誤、縮略詞("Rx"與"prescription")和同義詞("腦血管意外"與"中風"),這些都會給人工智能帶來挑戰。
為測試Med-Gemini理解和推理長語境醫療信息的能力,研究人員使用一個大型公開數據庫--重癥監護醫療信息市場(MIMIC-III)--執行一項所謂的"大海撈針任務",該數據庫包含重癥監護患者的去標識化健康數據。
該模型的目標是在電子病歷("大海")中的大量臨床記錄中檢索到與罕見而微妙的醫療狀況、癥狀或程序("針")相關的內容。
共收集 200 個案例,每個案例都由 44 名病史較長的重癥監護室患者的去標識化電子病歷記錄組成。他們必須具備以下條件:
100 多份醫學筆記,每個例子的長度從 20 萬字到 70 萬字不等
在每個例子中,條件隻被提及一次
每個樣本都有一個感興趣的條件
這項大海撈針的任務分為兩個步驟。首先,Med-Gemini 必須從大量記錄中檢索所有與指定醫療問題相關的內容。其次,該模型必須評估所有提及內容的相關性,對其進行分類,並得出結論:患者是否有該問題的病史,同時為其決定提供清晰的推理。

Med-Gemini 的長語境能力示例
與 SoTA 方法相比,Med-Gemini 在"大海撈針"任務中表現出色。它的精確度為 0.77,而 SoTA 方法為 0.85,召回率也超過 SoTA 方法:0.76 對 0.73。
研究人員說:"也許 Med-Gemini 最引人註目的方面是長語境處理能力,因為它們為醫療人工智能系統開辟新的性能前沿和新穎的、以前不可行的應用可能性。這項'大海撈針'式的檢索任務反映臨床醫生在現實世界中面臨的挑戰,Med-Gemini-M 1.5 的性能表明,它有潛力通過從海量患者數據中高效提取和分析信息,顯著降低認知負荷,增強臨床醫生的能力。"
有關這些關鍵研究點的淺顯易懂的討論,以及Google和微軟之間爭論的最新情況,請觀看《AI Explained》從 13:38 開始的視頻。
新的 OpenAI 模型即將誕生,人工智能的賭註又提高(還有 Med Gemini、GPT 2 聊天機器人和 Scale AI)
與 Med-Gemini 對話
在一次實際應用測試中,Med-Gemini 收到一位患者用戶關於皮膚腫塊瘙癢的詢問。在要求提供圖像後,模型提出適當的後續問題,並正確診斷出這種罕見的病變,同時建議用戶下一步該怎麼做。

Med-Gemini 診斷對話在皮膚科的應用實例
Med-Gemini 還被要求在醫生等待放射科醫生的正式報告期間,為其解讀胸部 X 光片,並編寫一份通俗易懂的英文版報告提供給病人。
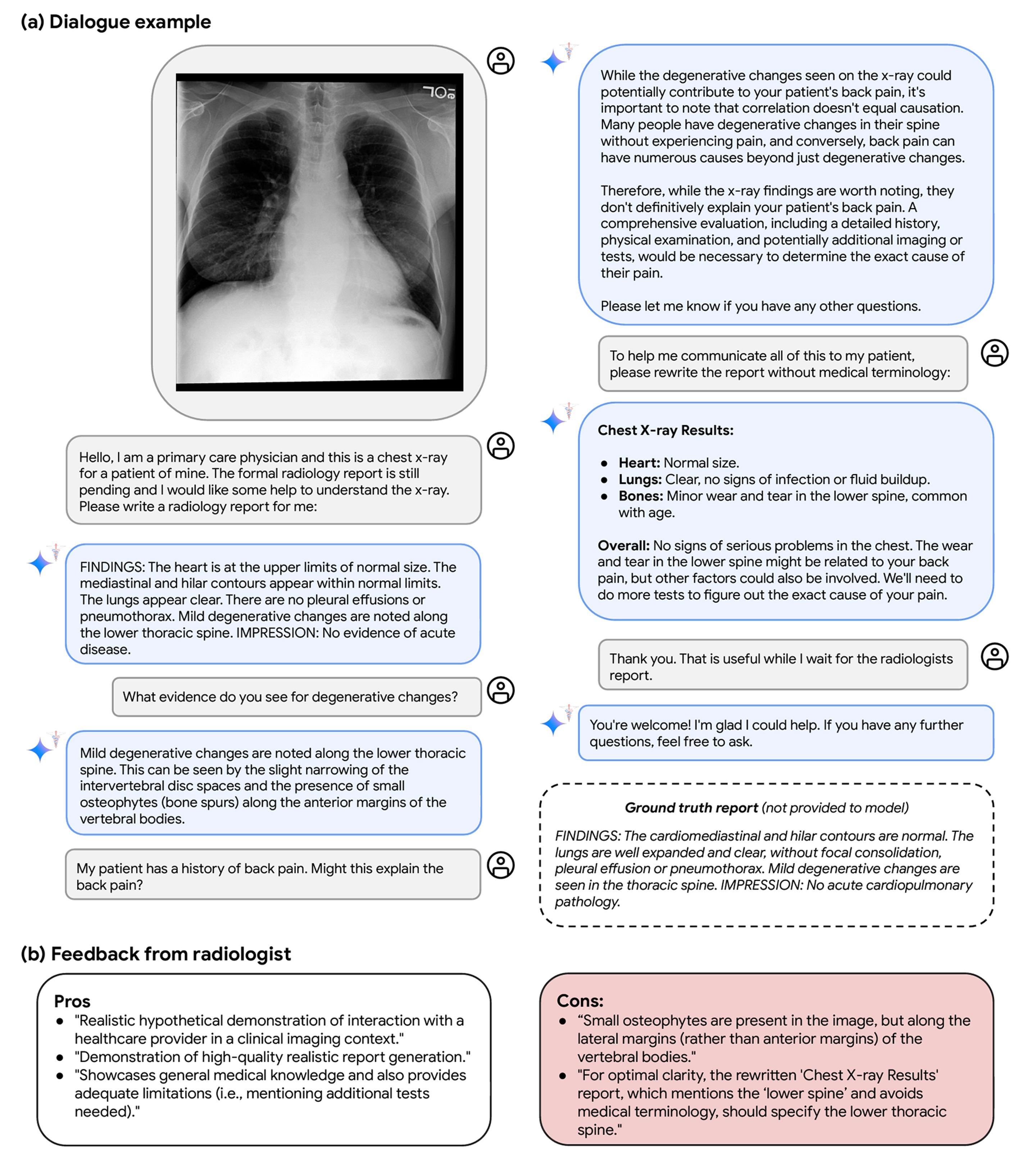
Med-Gemini 的放射診斷對話輔助系統
研究人員說:"Med-Gemini-M 1.5 的多模態對話功能很有前景,因為它們無需進行任何特定的醫療對話微調即可實現。這些功能可以實現人、臨床醫生和人工智能系統之間無縫、自然的互動。"
不過,研究人員認為還需要進一步的工作。他們說:"這種能力在幫助臨床醫生和患者等現實世界應用方面具有巨大潛力,但當然也會帶來非常大的風險。在強調這一領域未來研究潛力的同時,我們並沒有在這項工作中對臨床對話的能力進行嚴格的基準測試,正如其他人之前在對話診斷人工智能的專門研究中所探索的那樣。"
未來願景
研究人員承認,要做的工作還有很多,但 Med-Gemini 模型的初步能力無疑是很有希望的。重要的是,他們計劃在整個模型開發過程中納入負責任的人工智能原則,包括隱私和公平。
隱私方面的考慮尤其需要植根於現有的醫療保健政策和法規,以管理和保護患者信息。公平性是另一個可能需要關註的領域,因為醫療保健領域的人工智能系統有可能無意中反映或放大歷史偏見和不公平,從而可能導致邊緣化群體的不同模型性能和有害結果。但歸根結底,Med-Gemini 被視為一種造福人類的工具。
大型多模態語言模型為健康和醫學帶來一個全新的時代。Gemini"和"醫學Gemini"所展示的能力表明,在加速生物醫學發現、協助醫療保健服務和體驗的深度和廣度方面,都有重大飛躍。然而,在提高模型能力的同時,必須對這些系統的可靠性和安全性給予細致的關註。通過優先考慮這兩個方面,我們可以負責任地展望未來,讓人工智能系統的能力成為科學進步和醫療保健有意義且安全的加速器。
該研究可通過預印本網站arXiv 獲取。