4月20日消息,過去四個月,人工智能聊天機器人變得越來越受歡迎,它們能夠完成各種任務,比如寫復雜的學術論文和進行緊張的對話,能力很令人驚嘆。聊天機器人並不像人類那樣思考,它們甚至不知道自己在說什麼。它們之所以能模仿人類的語言,是因為驅動它們的人工智能已經吸收大量的文本,其中大部分內容是從互聯網上抓取的。
這些文本是人工智能在構建過程中獲取世界信息的主要來源,它們會對人工智能的響應方式產生深遠影響。如果人工智能在司法考試中取得優異成績,那可能是因為它的訓練數據中包含數以千計的LSAT(Law School Admission Test,美國法學院入學申請考試)資料。
科技公司對他們向人工智能提供哪些信息始終保密。因此,《華盛頓郵報》開始分析其中一個重要數據集,徹底揭示用於訓練AI的專有、個人和常常具有攻擊性的網站類型。
為探究人工智能訓練數據的內部構成,《華盛頓郵報》與艾倫人工智能研究所的研究人員合作,對Google的C4數據集進行分析。這個數據集是一個包含1500多萬個網站的海量快照,這些網站內容被用來訓練許多備受關註的英語人工智能,例如Google的T5和Facebook的LLaMA。而OpenAI沒有透露他們使用什麼樣的數據集來訓練支持聊天機器人ChatGPT的模型。
在這項調查中,研究人員使用網絡分析公司Similarweb的數據對網站進行分類。其中大約三分之一的網站無法進行分類而被排除,主要是因為它們已經不再存在於互聯網上。接著,研究人員根據數據集中每個網站出現的“token”數量,對剩下的1000萬個網站進行排名。token是處理信息的小段文本,通常是一個單詞或短語,用於訓練AI模型。
從維基百科到WoWhead
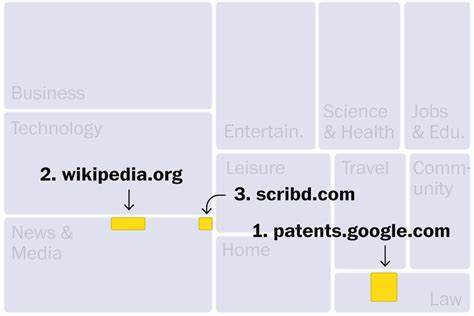
C4數據集的網站主要來自新聞、娛樂、軟件開發、醫療和內容創作等行業。這可以解釋為什麼這些領域可能受到新一波人工智能的威脅。排名前三的網站分別是:第一名是Google專利搜索,它包含世界各地發佈的專利文本;第二名是維基百科;第三名是隻接受付費訂閱的數字圖書館Scribd。此外,排名靠前的其他網站還有盜版電子書市場Library(第190位),這個網站因非法行為被美國司法部查封。此外,數據集中還存在至少27個被美國政府認定為盜版和假冒產品市場的網站。
還有一些頂級網站也出現在其中,例如《魔獸世界》玩傢論壇wowhead(第181位),以及阿裡安娜·赫芬頓(Arianna Huffington)創立的用於幫助緩解職業倦怠的網站thriveglobal(第175位)。此外,還有至少10個出售垃圾箱的網站,包括dumpsteroid(第183位),但它似乎已經無法訪問。
雖然大部分網站都是安全的,但有些網站存在嚴重的隱私問題。例如,有兩個排名進入前100位的網站,都私下承載州選民登記數據庫的副本。雖然選民數據是公開的,但這些模型可能會以未知的方式使用這些個人信息。
工商業網站占據最大的類別(占分類token的16%)。排名第一的是提供投資建議的The Motley Fool(第13位)。其次是允許用戶為創意項目進行眾籌的Kickstarter網站(第25位)。而排名較後的Patreon位列第2398,該網站幫助創作者從訂閱者那裡收取每月費用以獲得獨傢內容。
然而,Kickstarter和Patreon可能會讓人工智能獲取藝術傢的想法和營銷文案,人們擔憂AI可能會在向用戶提供建議時復制這些作品。目前,藝術傢的作品被包括在人工智能培訓數據中時,他們不會得到任何補償,他們已經向文本轉圖像生成器Stable Diffusion、MidJourney和DeviantArt提出侵權索賠。
根據這次《華盛頓郵報》的分析,更多的法律挑戰可能即將到來:C4數據集中有超過2億次出現版權符號(表示註冊為知識產權的作品)。
技術網站是第二大類別,占分類token的15%。這包括許多平臺,它們幫助人們建立網站,比如Google協作平臺(第85位),它的頁面涵蓋從英格蘭雷丁柔道俱樂部到新澤西州幼兒園的各種內容。
C4數據集還包含50多萬個個人博客,占分類內容的3.8%。發佈平臺Medium排名第46位,是第五大科技網站,在其域名下擁有數萬個博客。此外,還有在WordPress、Tumblr、Blogpot和Live Journal等平臺上撰寫的博客。
這些博客形式多樣,從職業到個人都有,比如一篇名為“Grumpy Rumblings”的博客,由兩位匿名的學者共同撰寫,其中一位最近寫到他們的伴侶失業是如何影響夫妻的稅收。此外,C4數據集中還有一些專註於真人角色扮演遊戲的頂級博客。
社交網絡如Facebook和Twitter等(它們被視為現代網絡的核心)的內容被禁止抓取,這意味著用於訓練人工智能的大多數數據集都無法訪問它們。Facebook和Google等科技巨頭坐擁海量對話數據,但他們還不清楚如何使用個人用戶信息來訓練內部使用或作為產品銷售的人工智能模型。
新聞和媒體網站是所有類別中排名第三,而前十位網站中有半數是新聞媒體:《紐約時報》網站排名第四,《洛杉磯時報》網站排名第六,《衛報》網站排名第七,《福佈斯》網站排在第八位,《赫芬頓郵報》網站排名第九,《華盛頓郵報》網站排名第11位。與藝術傢和創作者一樣,多傢新聞機構也批評科技公司在未經授權或提供補償的情況下使用他們的內容。
與此同時,《華盛頓郵報》還發現有幾傢媒體在NewsGuard的獨立可信度評級中排位較低:比如俄羅斯RT(第65位)、極右翼新聞網站breitbart(第159位)以及與白人至上主義有關的反移民網站vdare(第993位)。
聊天機器人已經被證明可以分享錯誤信息。不可信的訓練數據可能導致它們傳播偏見、宣傳錯誤信息,而用戶卻無法追蹤到它們的原始來源。
社區網站約占分類內容的5%,主要是宗教網站。
過濾器漏網之魚有哪些?
像大多數公司一樣,Google在將數據提供給人工智能之前,會對數據進行過濾和篩查。除去除無意義和重復的文字外,該公司還使用開源的“不良詞匯列表”,其中包括402個英文術語和一個表情符號。公司通常使用高質量的數據集來微調模型,從而屏蔽用戶不想看到的內容。
雖然這類列表旨在限制模型在接受培訓時受到種族誹謗和不良內容的影響,但很多東西都通過過濾器的篩查。《華盛頓郵報》發現數百個色情網站和超過7.2萬個“納粹”例子,它們都在禁用詞匯列表中。
與此同時,《華盛頓郵報》發現,這些過濾器未能刪除某些令人不安的內容,包括白人至上主義網站、反跨性別網站以及以組織針對個人騷擾活動而聞名的匿名留言板4chan。研究中還發現宣傳陰謀論的網站。
你的網站有沒有用於訓練AI?
網絡抓取聽上去可能像是對整個互聯網進行復制,但實際上它隻是收集快照,即對特定時刻的網頁樣本抓取內容。C4數據集最初是由非營利組織CommonCrawl創建的,於2019年4月進行網絡內容抓取,是人工智能模型訓練的熱門資源。CommonCrawl表示,該組織試圖優先考慮最重要和聲譽最好的網站,但沒有試圖避免授權或版權保護的內容。
《華盛頓郵報》認為,將數據的完整內容呈現在人工智能模型中至關重要,這些模型有望管理人們現代生活的許多方面。然而,這個數據集中的許多網站包含高度攻擊性語言,即使模型訓練時盡量掩蓋這些詞語,令人反感的內容仍然可能會存在。
專傢表示,盡管C4數據集很龐大,但大型語言模型可能會使用更大的數據集。例如,OpenAI在2020年發佈GPT-3訓練數據,其數據量是C4中網絡抓取數據量的40倍。GPT-3的培訓數據包括所有英文維基百科、大型科技公司經常使用的、未出版作傢的免費小說集以及Reddit用戶高度評價的鏈接文本匯編。
專傢表示,許多公司甚至沒有記錄培訓數據的內容(甚至是內部數據),因為擔心發現有關可識別身份的個人信息、受版權保護的材料和其他未經同意被竊取的數據。隨著公司強調解釋聊天機器人如何做出決策面臨的挑戰,這是高管們需要給出透明答案的領域。