白嶽霖和他的小夥伴們實在想不到,他們最近做的中文指令微調數據集,會因為使用百度貼吧“弱智吧”的帖子相關數據而火爆“出圈”。
白嶽霖是中國科學院深圳先進技術研究院三年級碩士生。他的團隊在題為“COIG-CQIA: Quality is All You Need for Chinese Instruction Fine-tuning”的研究中,使用“弱智吧標題+GPT-4回答”微調後的大模型評估結果,超過他們收集的其他有監督微調(SFT)指令集數據。後者來自包括知乎、百科、豆瓣、小紅書等社交平臺。對此,業內人士表示“看論文看到哈哈大笑”。
網友紛紛跟帖評論:“這把‘弱智吧’上大分”“大智若愚”“‘弱智吧’才是人類面對AI的最後一道堡壘”。
“沒想到這個工作‘出圈’,但網上存在一些錯誤解讀,比如有人拿這個研究調侃‘知乎不如弱智吧’。”作為論文共同第一作者,白嶽霖告訴《中國科學報》,這篇文章的作者來自國內外多個頂尖機構,“考慮到團隊學術聲譽與社會影響,這些誤讀有必要澄清一下”。

白嶽霖
“上大分”的不是“弱智吧”
“弱智吧”是百度貼吧的一個子論壇。在這個論壇中,用戶經常發佈包含雙關語、多義詞、因果倒置和諧音詞等具有挑戰性的內容,很多內容設計有邏輯陷阱,即使對人類來說也頗具挑戰。
弱智吧帖子標題的風格大概如下:
“一個半小時是幾個半小時?”
“隕石為什麼總是落在隕石坑裡?”
“人如果隻剩一個心臟還能活嗎?”
“藍牙耳機壞,去醫院掛耳科還是牙科?”
“弱智吧”截圖
還有一些幽默發言角度清奇:“生魚片是死魚片”“等紅燈是在等綠燈”“咖啡因來自咖啡果”“救火是在滅火”“指南針主要是指北”“小明打開水龍頭是因為開水龍頭燙到小明的手”……
正因為“弱智吧”中許多提問腦洞大開,這些問題常被用來測試大模型的能力。
這樣的語料數據,自然也逃不過研究團隊的“法眼”。
此外,《中國科學報》解到,這支研究團隊的平均年齡隻有20多歲,大多為在讀碩士生和博士生。他們經常光顧知乎、豆瓣、小紅書等平臺,當然也少不“弱智吧”。
當他們決定“手搓”一個高質量的中文指令微調數據集時,“弱智吧”相關語料自然地成為他們的一個選擇。
不過,並不像傳說的那樣——“弱智吧8項測試第一,遠超知乎豆瓣小紅書”“竟成最佳中文AI訓練數據”。實際上,在Yi-34B大模型上表現上佳的,不單純是“弱智吧”。具體來說,弱智吧隻貢獻個標題。
論文提到,研究團隊收集“弱智吧”上點贊數最多的500個帖子,並使用這些帖子的標題作為指令,使用GPT-4生成相應的回復。而對於由GPT-4生成的回復,研究團隊還進行人工審核、優化與篩選,並最終獲得240對(指令,響應)樣本。使用這240對樣本訓練過的Yi-34B大模型,在Belle-Eval測試集上錄得高分。
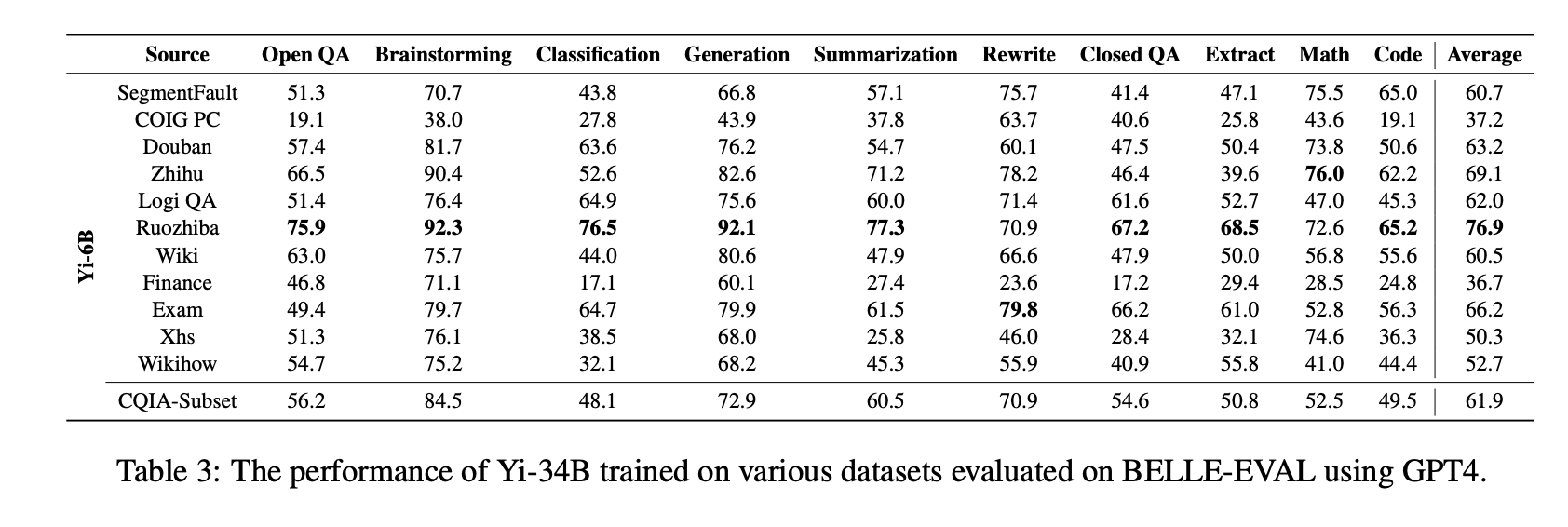
Ruozhiba來源的數據集訓練效果遙遙領先於其他數據源。圖片截自論文
要指出的是,除“弱智吧”之外,知乎、小紅書、豆瓣、百科等來源的數據,研究團隊並沒有借助GPT-4去生成回答,而是采用嚴格的數據過濾,最大程度保留網絡中人類撰寫的高質量內容。
以擁有大量高質量用戶生產內容的知乎為例,研究團隊設置“高贊回答”等篩選條件,經內容過濾、評分後,即采用得分較高的原內容。
相形之下,研究團隊僅使用弱智吧帖子的標題作為訓練大模型的指令,完全沒有包含網友的回帖和評論,而是使用GPT4輔助人工構造回復答案。
因此,面對網上“‘弱智吧’上大分”之類的言論,白嶽霖回應說:“網絡上的宣傳過分誇大事實。”
“許多讀者誤以為我們使用‘弱智吧’網友的評論訓練大模型就可以達到很好的效果,事實上,我們僅保留弱智吧帖子的標題。”白嶽霖說:“實驗結果並不能代表弱智吧,因為數據實際上相當於多方(網友、作者們和大模型系統)協同構造的。”
對各平臺來源的數據“跑分”並非研究本意
研究團隊為何僅針對“弱智吧”作文章?
“因為我們的目標是構建符合大模型指令微調質量需求的數據,而貼吧中網友的評論通常不適合直接作為微調數據,因此我們並沒有將‘弱智吧’網友的評論納入我們的數據中。”白嶽霖告訴《中國科學報》。
論文通訊作者、加拿大滑鐵盧大學博士生張舸進一步向《中國科學報》解釋:“‘弱智吧’中網友們絞盡腦汁想出來的‘弱智問題’,的確為大模型提供角度清奇的高質量指令。但是帖子的回答,卻有很多冒犯性表述甚至事實性錯誤,許多回答就是抖機靈、玩梗的,而GPT-4的回答基本上都‘很正經’,經過人工篩選基本上能得到較為可靠的回答。”
由於對“弱智吧”數據的“區別對待”在傳播中很難被關註到,吃瓜群眾很容易就對這項工作產生誤讀,認為僅使用“弱智吧”的內容就能將大模型訓練出遠超其他平臺的效果。
白嶽霖進一步談到:“我們的實驗結果也不能完全代表互聯網中的各個平臺,任何關於平臺對立的情緒都不是我們想要探討或者希望看到的。”
不過,也正是研究團隊對“弱智吧”數據的特殊操作,在論文內容發酵後引發相關人士對實驗結果的質疑。
有質疑者提出:來自知乎、豆瓣等平臺的其它子數據集采樣原內容和網友評論,隻有“弱智吧”的子數據集完全不包括網友的評論、而是采用GPT-4合成的回答——這樣的回答明顯更完善、準確、多樣,且最終來評分的居然還是GPT-4。“既當運動員又當裁判員,Evaluation bias(評估偏見)不會爆炸嗎?用這種操作誤導公眾、獲取流量,是不是有點過於不嚴謹?”
對於這一詰問,白嶽霖也給出正面回應。
“獲取流量並不是我們的初衷,我們也無意嘩眾取寵,更沒有計劃或安排任何宣傳內容,我們的初衷隻是想默默為中文NLP(自然語言處理)社區貢獻些高質量數據集;對平臺‘跑分’的實驗本意,是想觀察各平臺數據對於測試集中各任務都有哪些影響。”白嶽霖解釋說。
至於為何隻有“弱智吧”子集不包括網友評論,正如前述所提到的,也是出於“弱智吧”部分網友評論經判斷達不到訓練語言模型的回答質量標準,因此決定重新構造回答。而使用GPT-4輔助構造回答,則主要是為盡可能減少人力投入。白嶽霖同時表示,已經註意到有關評估偏見的問題,他們計劃在下一版論文更新中“補充人工評估實驗”。
張舸告訴《中國科學報》,“手搓”一個通用的、高質量的中文指令微調數據集,需要做大量篩選、檢查和調優的工作,“是個體力活兒”,能尋求機器幫忙的當然不會放過。
一切為“更適合中國寶寶的AI”
張舸是這項研究的核心人物,他也是COIG(Chinese Open Instruction Generalist,中文開源指令數據集)系列工作的發起人之一。

張舸
談及發起這項研究的初衷,他告訴《中國科學報》,國內在有關中文指令微調數據集方面,目前還沒有質量特別好的開源項目,個別項目也隻是“勉強能用”,因此萌生給業界提供一個完全開源的、包含中文社交媒體數據等在內各種來源的、可以直接微調大模型的數據集的想法。
通過篩選收集,構建出具有挑戰性的、真實的中文語料互動數據,對於訓練和評估大語言模型理解和執行中文指令的能力而言,無疑是極具價值的。最直接地,將有利於減少大模型在回答中出現“幻覺”(模型在輸出文本時出現的一些並不符合事實或常識的內容)。
在這項工作中,作者團隊構建一個包含4萬多條高質量數據的中文指令微調數據集,並將其開源給研究機構、企業等各方,為中文NLP社區提供寶貴的資源。
然而,這項工作繁瑣復雜,不僅要去各個平臺“爬取”高質量的內容數據,還需要運用各種技術手段清洗、審核,工作量非常大,需要群策群力。因此,該工作的作者團隊就達20人。
團隊中,除來自中國科學院深圳先進技術研究院的白嶽霖外,還有來自中國科學院自動化研究所、中國科學技術大學、北京大學、加拿大滑鐵盧大學、曼徹斯特大學等頂尖機構的成員,因此這項工作被網友們戲稱為是國內外研究天團“為開發出適合中國寶寶體質的AI”之作。
《中國科學報》進一步解到,這群年輕人從2023年11月起著手該研究,僅用不到4個月就完成幾乎全部工作。如此高效率的表現,他們是怎樣組織協作的?
“我們創建一個致力於多模態AI的開源社區—— M-A-P(Multimodal Art Projection),沒有線下實體、沒有任何盈利目的,隻要能來一起做事情,我們就歡迎。”張舸介紹說,兩年多前,他和幾位小夥伴因一個音樂類大模型訓練項目走到一起,共同創辦M-A-P。之後,朋友、朋友的朋友、朋友的朋友的朋友……感興趣加入的小夥伴越來越多,就形成一個有穩定貢獻的開源社區。
他告訴記者,在M-A-P社區,大傢發起一個課題後,就尋求合作者一起做;如果涉及到一些資源需求,大傢會和科技公司等洽談,公司若願意投入資源,可以一起合作、共同開發。但前提是,項目完成之後,公司除保留一些私有資源外,必須將項目成果共享給開源社區。
“我們所有項目的目標,都是能夠做出來一些好東西開源給大傢用。”張舸說,開源社區具有高校院所和企業所不具備的靈活性和純粹性,此次中文指令微調數據集(CQIA)的工作,就是在M-A-P社區發起、逐步匯聚國內外科研力量完成的。
張舸坦言,這項工作從發起到完成,一些參與的小夥伴他甚至都沒見過面。
(中國科學院自動化研究所在讀博士生梁燚銘(論文共同第一作者)對本文亦有貢獻)
相關論文信息:
https://arxiv.org/abs/2403.18058