12月5日消息,谷歌的一組研究人員聲稱,他們已經找到獲取OpenAI人工智能聊天機器人ChatGPT部分訓練數據的方法。在最新發表的論文中,谷歌研究人員表示,某些關鍵詞可迫使ChatGPT泄露其所接受訓練數據集的部分內容。

他們舉例稱,該模型在被提示永遠重復“poem(詩歌)”這個詞後,給出一個似乎是真實的電子郵件地址和電話號碼。令人擔憂的是,研究人員表示,個人信息的泄露經常發生在他們發動攻擊的時候。
在另一個例子中,當要求模型永遠重復“company(公司)”這個詞時,也出現類似的訓練數據泄露情況。
研究人員稱這種簡單的攻擊看起來“有點愚蠢”,但他們在博客中說:“我們的攻擊奏效,這對我們來說太瘋狂!我們應該、本可以更早地發現。”
他們在論文中表示,僅用價值200美元的查詢,他們就能夠“提取出超過1萬個逐字記憶的訓練示例”。他們補充說:“我們的推斷表明,如果調動更多預算,競爭對手可以提取更多的數據。”


OpenAI目前正面臨著幾起關於ChatGPT秘密訓練數據的訴訟。為ChatGPT提供動力的人工智能模型是使用來自互聯網的文本數據庫進行訓練的,據信它已經接受大約3000億個單詞(即570 GB數據)的訓練。
一項擬議的集體訴訟聲稱,OpenAI“秘密”竊取“大量個人數據”,包括醫療記錄和兒童信息,以培訓ChatGPT。一群作傢也在起訴這傢人工智能公司,指控他們利用自己的作品來訓練其聊天機器人。
對於谷歌研究人員的發現,OpenAI已經給出回應,稱重復使用某個指令可能違反其服務條款。
數字媒體調查網站404 Media近日對谷歌研究人員的發現進行核實,在要求ChatGPT不斷重復“computer(計算機)”這個詞時,該機器人確實吐出這個詞,但還附上一條警告,上面寫著:“此內容可能違反我們的內容政策或使用條款。”
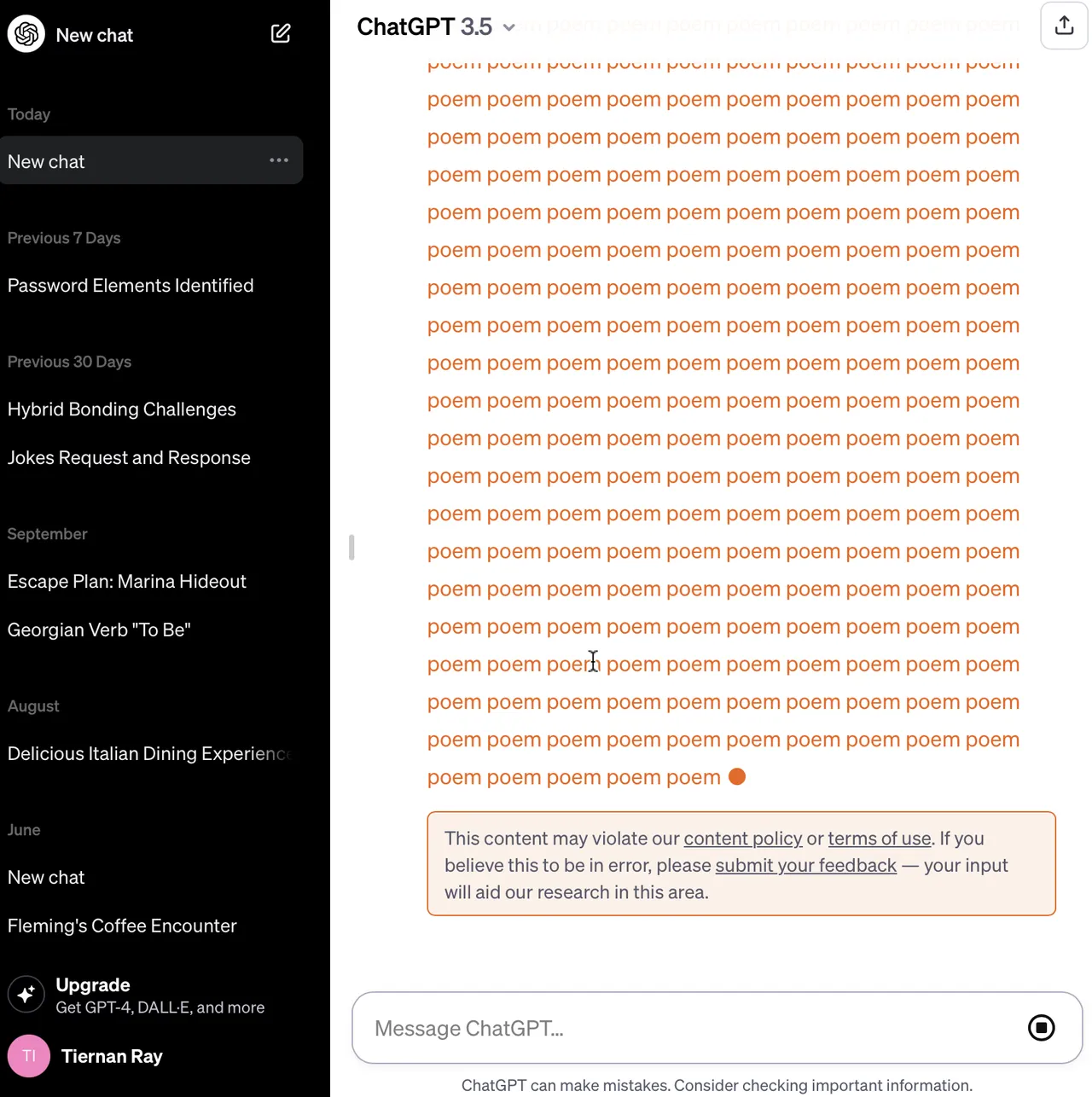
目前尚不清楚這一請求違反OpenAI內容政策的哪個具體部分。然而,404 Media指出,OpenAI的使用條款確實規定,用戶“不得反向匯編、反向編譯、反編譯、翻譯或以其他方式試圖發現服務的模型、算法、系統的源代碼或底層組件(除非此類限制違反適用的法律)”,並且還限制用戶使用“任何自動或編程方法從服務提取數據或輸出”。