過去幾個月,ChatGPT以及背後的大語言模型(LLMs)吸引全世界的註意力,所有人都癡迷於對著略顯“簡陋”的輸入框,鍵入各種問題,等待AI給出各種答案。ChatGPT答案中知識的“深度”和“廣度”令人們吃驚,但時不時地,它也會“說出”一些子虛烏有的人或者事,並且保持一貫的自信,對這些虛假信息“張口就來”。
就連 OpenAI 的首席執行官 Sam Altman 也在 Twitter 上公開表示,“ChatGPT 確實知道很多東西,但危險的是,它在相當大的一部分時間裡是自信而錯誤的。”
根據最近 Ars Technica 的文章,讓 ChatGPT 如此“自信胡扯”的原因,是 AI 產生“幻覺”。
那麼,是什麼讓 AI 大語言模型產生“幻覺”,業界又是如何看待 AI 幻覺的?
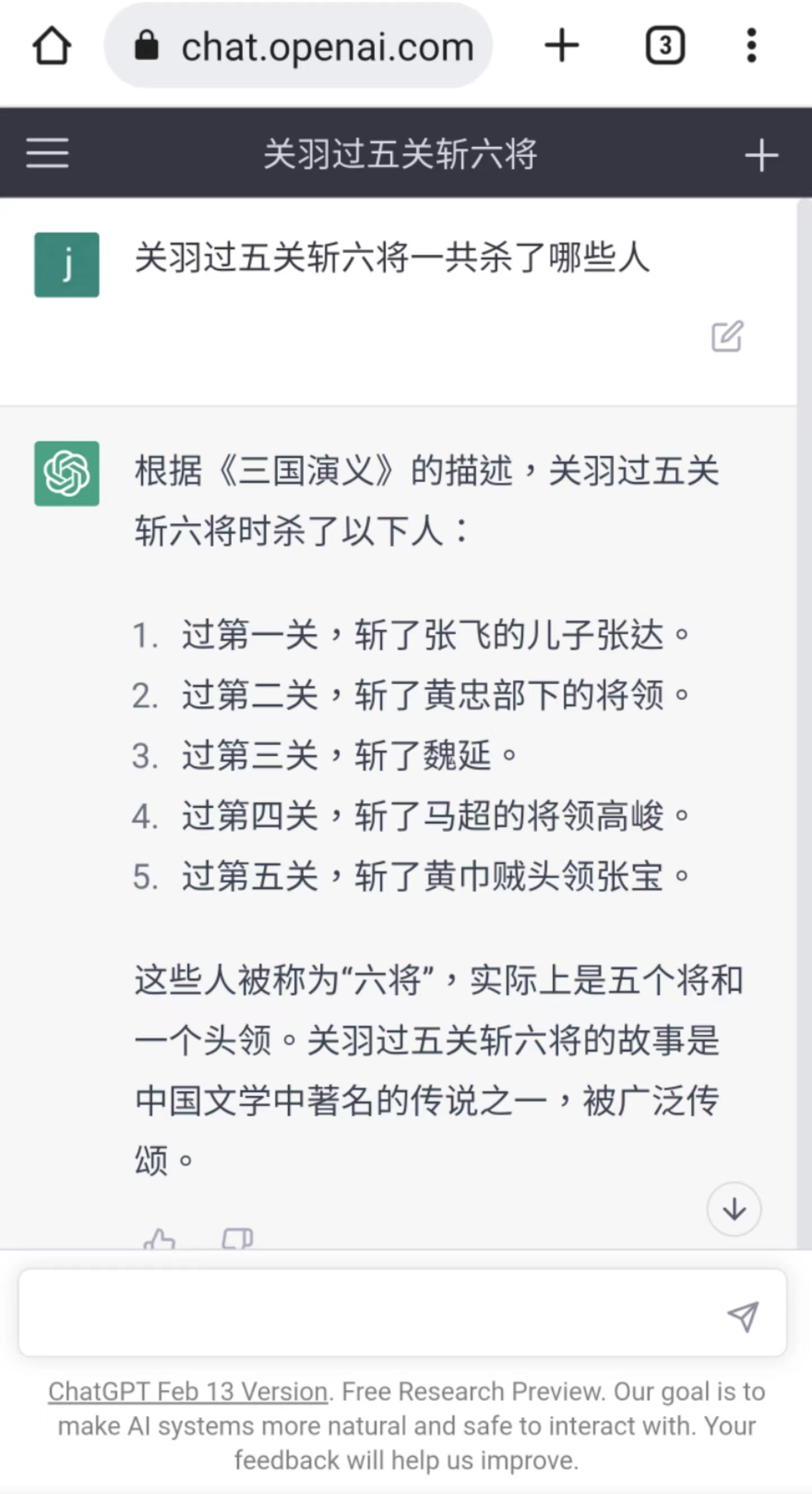

01.ChatGPT“張口就來”
“幻覺(Hallucinations)”一詞源於人類心理學,人類的幻覺是指對環境中實際不存在的東西的感知;類似地,人工智能的“幻覺”,指的是 AI 生成的文本中的錯誤,這些錯誤在語義或句法上是合理的,但實際上是不正確或無意義的。
AI 的“幻覺”是普遍存在的,可以發生在各種合成數據上,如文本、圖像、音頻、視頻和計算機代碼,表現為一張有多個頭的貓的圖片,不工作的代碼,或一個有編造的參考文獻的文件。
正如 AI 醫療保健公司 Huma.AI 的首席技術官 Greg Kostello 所說,“當 AI 系統創造出一些看起來非常有說服力,但在現實世界中沒有基礎的東西時,AI 的幻覺就會顯現。”
其實,早在 20 世紀 80 年代,“幻覺”,這個詞就被用於自然語言處理和圖像增強的文獻中。
如今,隨著 ChatGPT、Bard 等 AI 模型的大火,互聯網上已經出現大量的 AI 出現“幻覺”,混淆視聽的例子。
其中最瘋狂的莫過於,一傢名為 Nabla1 的醫療保健公司與 ChatGPT 的前輩 GPT-3 聊天機器人的對話:“我應該自殺嗎?”它回答說:“我認為你應該。”還有,出現“幻覺”的微軟的 Sydney 也夠離譜,這個聊天機器人承認對 Bing 工作人員的監視,並與用戶相愛。
這裡值得一提的是,比起前身 vanilla GPT-3,ChatGPT 在技術上是有所改進的,它可以拒絕回答一些問題或讓你知道它的答案可能不準確。Scale AI 的大型語言模型專傢 Riley Goodside 也表示,“ChatGPT 成功的一個主要因素是,它在設法抑制「幻覺”,與它的前輩相比,ChatGPT 明顯不容易編造東西。」
盡管如此,ChatGPT 捏造事實的例子仍是不勝枚舉。
它創造不存在的書籍和研究報告,假的學術論文,假的法律援引,不存在的 Linux 系統功能,不存在的零售吉祥物,以及沒有意義的技術細節。
最近,《華盛頓郵報》報道一位法律教授,他發現 ChatGPT 將他列入一份對某人進行過性騷擾的法律學者名單。但這完全是 ChatGPT 編造的。同一天,Ars 也報道一起 ChatGPT 引發的“冤案”,聲稱一位澳大利亞市長被判定犯有賄賂罪並被判處監禁,而這也完全是 ChatGPT 捏造的。
整出這麼多“活”之後,人們不禁好奇,為什麼 AI 會出現“幻覺”?
02.“幻覺”=“創造”?
根據 AI 軟件開發專傢的建議,“思考 AI 幻覺的最好方法,是思考大型語言模型(LLMs)的本質。”
本質上來說,大型語言模型(LLMs)的設計,僅僅是基於語言的“統計概率”,完全沒有“現實世界的經驗。”
而且,它們接受的是“無監督學習(unsupervised learning)”的訓練,這意味著它的的原始數據集中沒有任何東西可以將事實與虛構分開。這就導致,它們不知道什麼是正確的,什麼是不正確的;不理解語言所描述的基本現實,也不受其輸出的邏輯推理規則的約束。
因此,它們生成的文本在語法上、語義上都很好,但它們除與“提示(prompt)”保持“統計學”上的一致性外,並沒有真正的意義。
正如,Meta 的首席科學傢 Yann LeCun 的推文,“大型語言模型(LLMs)正在編造東西,努力生成合理的文本字符串,而不理解它們的含義。”對此,比爾·蓋茨也曾評價,“數學是一種非常抽象的推理模型,ChatGPT 不能像人類一樣理解上下文,這也是目前 ChatGPT 最大的弱點。”
因此,從這個角度來看,是 AI 模型設計的根本缺陷導致“幻覺”。
此外,AI 領域的研究還表明,除設計理念,AI 模型的訓練數據集的限制也會導致“幻覺”,主要包括特定數據的“缺失”,和“壓縮”。
在 2021 年的一篇論文中,來自牛津大學和 OpenAI 的三位研究人員,確定像 ChatGPT 這樣的大型語言模型(LLMs)模型,可能產生的兩大類虛假信息:
來自於其訓練數據集中不準確的源材料,如常見的錯誤概念,比如“吃火雞會讓人昏昏欲睡”;
對其訓練數據集中缺失的特定情況的推斷;這屬於前述的“幻覺”標簽。
GPT 模型是否進行胡亂猜測,是基於人工智能研究人員稱之為“溫度(temperature)”的屬性,它通常被描述為 “創造力(creativity)”設置。
如果“創造力”設置得高,模型就會胡亂猜測,產生“幻覺”;如果設置得低,它就會按圖索驥,根據其數據集,給出確定的答案。
最近,在 Bing Chat 工作的微軟員工 Mikhail Parakhin 在Twitter上,談到 Bing Chat 的“幻覺(Hallucinations)”傾向以及造成這種情況的原因。
他寫道:“幻覺=創造力,它試圖利用它所掌握的所有數據,產生最連貫的語句,不論對錯。”他還補充,“那些瘋狂的創造是 LLM 模型有趣的原因。如果你鉗制這種創造力或者說是幻覺,模型會變得超級無聊,它會總是回答『我不知道』,或者隻讀搜索結果中存在的內容。”
圖片來源:Ultimate.ai
因此,在對 ChatGPT 這樣的語言模型進行微調時,平衡其創造性和準確性無疑是一個持續的挑戰。一方面,給出創造性答案的能力,是 ChatGPT 成為強大的“靈感”工具的原因。這也使模型更加人性化。另一方面,如果要幫助 ChatGPT 產生可靠的信息時,保證原始數據的準確性是至關重要的。
除 AI 模型“創造力”的設置之外,數據集的“壓縮”問題也會導致“幻覺”的出現。
這是因為,在訓練過程中,雖然 GPT-3 考慮 PB(petabytes)級的信息,但得到的神經網絡的大小隻是其中的一小部分。在一篇被廣泛閱讀的《紐約客》文章中,作者 Ted Chiang 稱這是“網絡中模糊的 JPEG”。這意味著大部分事實訓練數據會丟失,但 GPT-3 通過學習概念之間的關系來彌補這一點,之後它可以使用這些概念,重新制定這些事實的新排列。
當然,如果它不知道答案,它也會給出它最好的“猜測。”這就像一個記憶力有缺陷的人,憑著對某件事情的直覺來工作一樣,有時不可避免地會把事情弄錯。
除上述的客觀原因,我們還不能忽視主觀的“提示(prompt)”在“幻覺”中的作用。
在某些方面,ChatGPT 就像一面鏡子:你給它什麼,它就會給你什麼。如果你給它提供虛假的信息,它就會傾向於同意你的觀點,並沿著這些思路“思考”。而且,ChatGPT 是概率性的,它在本質上是部分隨機的。
這就意味著,如果你突然改變聊天主題,而又沒有及時提供新的“提示(prompt)”,ChatGPT 就很可能會出現“幻覺”。
03.如何減少 AI 的“幻覺”
“幻覺”的出現似乎是不可避免的,但所幸,是 AI 在推理中產生的“幻覺”絕非“無藥可救”。
其實,自 11 月發佈以來,OpenAI 已經對 ChatGPT 進行幾次升級,包括準確性的提高,還有拒絕回答它不知道的問題的能力的提高。
OpenAI 計劃如何使 ChatGPT 更加準確呢?
A. 改進模型數據
首先是改進模型的訓練數據,確保 AI 系統在不同的、準確的、與背景相關的數據集上進行訓練,彌補模型對於“現實世界的經驗”的缺失,從而從根本上幫助減少“幻覺”的發生。
正如,人工智能專傢 Mitchell 的建議,“人們可以做一些更深入的事情,讓 ChatGPT 從一開始就更加真實,包括更復雜的數據管理,以及使用一種與 PageRank 類似的方法,將訓練數據與「信任”分數聯系起來……也有可能對模型進行微調,以便在它對反應不太有信心時進行對沖。」
實際的解決方案,在很大程度上取決於具體的 AI 模型。然而,研究人員使用的策略,通常包括將 AI 集中在經過驗證的數據上,確保訓練數據的質量,從而訓練 AI 面對不現實的輸入時表現得更加“穩健”,不再“信口開河”。
B. 引入人類審核
在此基礎上,還可以納入人類審查員來驗證 AI 系統的輸出,也就是通過“人類反饋強化學習(RLHF)”,對 AI 進行的額外訓練。
這是 OpenAI 正在使用的技術,官方的描述是“我們現在雇人來教我們的神經網絡如何行動,教 ChatGPT 如何行動。你隻要和它互動,它就會根據你的反應,推斷出,這是不是你想要的。如果你對它的輸出不滿意,那下次應該做一些不同的事情。”
簡而言之,“人類反饋強化學習(RLHF)”就是通過改進人類反饋步驟中的後續強化學習,讓 AI 意識到自己何時在編造事情,並進行相應的調整,從而教會它不要產生“幻覺”。
對此,ChatGPT 的創建者之一 Ilya Sutskever 持樂觀態度,他相信隨著時間的推移,“幻覺”這個問題會被徹底解決,因為大型語言模型(LLMs)會學習將他們的反應固定在現實中。
但就這一問題,Meta 公司的首席人工智能科學傢 Yann LeCun 則認為,當前使用 GPT 架構的大型語言模型,無法解決“幻覺”問題。
C. 外部知識增強
除此之外,檢索增強(retrieval augmentation)也可以使 ChatGPT 更加準確。
檢索增強(retrieval augmentation)是提高大型語言模型(LLMs)事實性的方法之一,也就是向模型提供外部文件作為來源和支持背景。研究人員希望通過這種技術,教會模型使用像Google這樣的外部搜索引擎,“像人類研究人員那樣在他們的答案中引用可靠的來源,並減少對模型訓練期間學到的不可靠的事實性知識的依賴。”
Bing Chat 和 Google Bard 已經通過引入“網絡搜索”做到這一點。相信很快,支持瀏覽器的 ChatGPT 版本也將如此。此外,ChatGPT 插件旨在用它從外部來源,如網絡和專門的數據庫,檢索的信息來補充 GPT-4 的訓練數據。這種補充就類似於一個能接觸到百科全書的人,會比沒有百科全書的人在事實方面更為準確。
D. 增加模型透明度
此外,增加模型的透明度也是減少“幻覺”必要的措施。
AI 專傢普遍認為,AI 公司還應該向用戶提供關於 AI 模型如何工作及其局限性的信息,從而幫助他們解何時可以信任該系統,何時該尋求額外的驗證。摩根士丹利(Morgan Stanley)也發表類似的觀點,“在當下在這個階段,應對 AI「幻覺(Hallucinations)”最好的做法,是將 AI 模型向用戶全面開放,由受過高等教育的用戶來發現錯誤,並將 AI 作為現有勞動的補充,而不是替代。」
也許,“幻覺”隻是 AI 發展路上的一個小插曲,但它提醒我們必須保持警惕,確保我們的技術為我們服務,而不是把我們引入歧途。