“AI確實可能殺死人類。”這話並非危言聳聽,而是OpenAICEO奧特曼的最新觀點。而這番觀點,是奧特曼在與MIT研究科學傢LexFridman長達2小時的對話中透露。不僅如此,奧特曼談及近期圍繞ChatGPT產生的諸多問題,坦承就連OpenAI團隊,也根本沒搞懂它是如何“進化”的:

從ChatGPT開始,AI出現推理能力。但沒人能解讀這種能力出現的原因。
唯一的途徑是向ChatGPT提問,從它的回答中摸索它的思路。
針對馬斯克在Twitter上的“危險論”,他直言:
馬斯克在我心中是英雄,我支持也理解他的擔憂。
雖然他在Twitter上挺混蛋的,但希望馬斯克能看到我們在解決AGI安全問題上付出多大的努力。
除此之外,在這場對話過程中,奧特曼還提到不少刁鉆的話題,例如:
ChatGPT、GPT-4開發的內幕
GPT-4是人類迄今所實現的最復雜的軟件
如何看待大傢拿ChatGPT越獄
……
在看過這場對話之後,網友直呼:
兩位AI大佬用大傢都能理解的方式聊AI,多來點這樣的訪談。

那麼接下來,我們就來一同看下他們這場深度對話。
GPT-4內幕大曝光
GPT-4是這場對話中最受關註的部分。
它是如何訓練的?如何在訓練模型時避免浪費算力?如何解決AI回答不同價值觀的人的問題?
首先是訓練過程,依舊是預訓練+RLHF,不過透露一點具體細節。
GPT-4早在去年夏天就已經訓練完成,後面一直在進行對齊工作,讓它表現得更符合人類需求。
相比預訓練數據集,RLHF所用的數據非常少,但效果是決定性的。
對此,奧特曼透露一點數據來源,包含一些開源數據集、以及合作商提供的部分數據集。
當然,數據集中也有一點Reddit論壇上出現的迷因梗(meme),但不是很多。對此奧特曼遺憾表示:
如果再多點,它的回答可能會更有趣。

即便如此,團隊甚至奧特曼自己依舊不能完全解讀GPT-4。
目前對它的解讀方式,依舊是通過不斷問它問題,通過它的回答來判斷它的“思路”。
而就在不斷測試中,OpenAI發現從ChatGPT開始,GPT系列出現推理能力。
雖然ChatGPT絕大部分時候都被當做數據庫使用,但它確實也出現一定的推理能力,至於這種能力具體如何出現的,目前卻無人能回答。
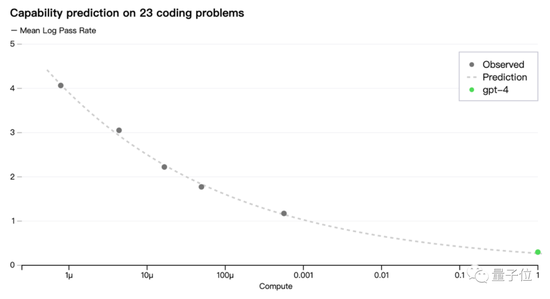
但大模型的訓練往往意味著大量算力需求。對此奧特曼再次提到OpenAI獨特的訓練預測方法:
即便模型很大,團隊目前也有辦法隻通過部分訓練,預測整個模型的性能,就像是預測一名1歲的嬰兒能否通過SAT考試一樣。
關於這一點,在GPT-4論文和官方博客中也有更詳細介紹。
最後奧特曼承認,GPT-4確實存在應對不同價值觀的人的問題。
臨時解決辦法就是把更改系統消息(system message)的權限開放給用戶,也就是ChatGPT中經常見到的那段“我隻是一個語言模型……”。
通過改變系統消息,GPT-4會更容易扮演其中規定的角色,比在對話中提出要求的重視程度更高,如規定GPT-4像蘇格拉底一樣說話,或者隻用JSON格式回答問題。

所以,對於GPT系列來說,誰最可能載入人工智能史冊?奧特曼倒不認為是GPT-4:
從可用性和RLHF來看,ChatGPT無疑是最具裡程碑的那一個,背後的模型沒有產品的實用性重要。
最會打太極的CEO
GPT-4論文中沒有透露參數規模、訓練數據集大小等更多細節,還被外界吐槽越來越不Open。
在這次訪談中,面對主持人步步追問,奧特曼依舊守口如瓶。
GPT-4預訓練數據集有多大?奧特曼隻是很籠統的介紹有公開數據集、有來自合作夥伴的內容(如GitHub提供的代碼)還有來自網絡的內容。
活像ChatGPT也能寫出來的那種賽博八股文,隻有在談到Reddit的時候透露網絡梗圖在訓練數據中占比不大,“不然ChatGPT可能更有趣一些”。
GPT-4模型參數量有多大?奧特曼隻是說之前瘋傳的100萬億參數是謠言,然後又糊弄過去。
我認為人們被參數競賽所吸引,就像過去被CPU的主頻競賽所吸引一樣。現在人們不再關心手機處理器有多少赫茲,關心的是這東西能為你做什麼。
不過奧特曼對於一種說法是持有肯定態度——“GPT-4是人類迄今所實現的最復雜的軟件”。
但在主持人Lex突然拋出一些時下針對GPT-4的尖銳觀點時,奧特曼的應對也堪稱“AI般淡定”(狗頭)。

例如,關於前段時間鬧得沸沸揚揚的GPT-4越獄問題。
一名斯坦福教授僅僅用30分鐘,就誘導GPT-4制定出越獄計劃,並全部展示出來。
對此奧特曼表示,就如同當年iPhone也面臨被“黑”或者說越獄的問題(如當年免費的越獄版App Store)一樣,這並非不能解決的事情。
奧特曼甚至坦承,他當年就把自己的第一臺蘋果手機越獄——甚至當時覺得這是個很酷的事情。
但現在已經沒有多少人去幹蘋果越獄的事情,因為不越獄也足夠好用。
奧特曼表示,OpenAI的應對思路同樣如此,即把功能做的足夠強,他甚至表示,願意在這方面給用戶開更多權限,以便解他們到底想要什麼。
除此之外,Lex還提到馬斯克對於奧特曼的批評。
奧特曼雖然是當年被馬斯克一手提拔的人才,但如今馬斯克不僅退出他們聯手創辦的OpenAI,還對OpenAI現狀十分不滿,經常在Twitter上陰陽怪氣這傢公司。
我捐1億美金成立的非營利組織怎麼就變成一個300億市值的營利性公司呢?如果這是合法的,為什麼其他人不這樣做?
作為OpenAI現任CEO,奧特曼並未直接回應此事,而是調侃一下馬斯克在航天領域也經常被“老前輩”們批評的事情。
這一系列采訪問答,不禁讓人想到在ChatGPT發佈後,奧特曼對於記者“將ChatGPT整合進微軟必應和Office”問題的回應方式:
你知道我不能對此發表評論。我知道你知道我不能對此發表評論。你知道我知道你知道我不能對此發表評論。
既然如此,為什麼你還要問它呢?
GPT的“偏見”不會消失
GPT在迭代過程中“偏見”必然存在,它不可能保持完全中立。
在主持人提到關於ChatGPT以及GPT-4種存在的偏見問題時,奧特曼這樣回應道。
ChatGPT在推出之初,就不是一個成熟的產品,它需要不斷迭代,而在迭代的過程中,僅僅依靠內部的力量是無法完成的。
“提前”推出ChatGPT技術,是要借助外部世界的集體智慧和能力,同時也能讓全世界參與進“塑造AI”的過程中。
而不同人對於問題的看法也各不相同,所以在這個過程中,“偏見”問題就不可避免。
甚至奧特曼在話裡話外也透露著:在GPT中,“偏見”永遠不會消失。
他將外部參與建設GPT比作“公開領域建設的權衡”。
GPT生成答案是個性化控制的結果,迭代的過程則是更精準地控制“個性化”的過程。
有趣的是,期間奧特曼還暗戳戳“背刺”起馬斯克的Twitter:
Twitter摧毀掉的多元性,我們正在將其找回來。
(嗯,奧特曼是懂一些話術的)
當然,談到ChatGPT,總繞不開其背後的公司OpenAI,在成立之初,它就立下兩個Flag:
1、非營利性
2、通用人工智能(AGI)

如今,已經過去八年之久,這兩個Flag也是發生巨大的變化:AGI的大旗還在高舉,而非營利性這面旗則已經搖搖欲墜。
對此,奧特曼也是分別作出回應。
對於OpenAI“非營利性質”的逐漸削弱,奧特曼直言:很久之前,就已經意識到非營利性不是長久之計。
僅僅依靠非營利籌集到的資金對OpenAI的研究來說遠遠不夠,商業化是必然選擇。
但在之後奧特曼也試圖“找補”回一些,稱目前的商業化的程度僅止於滿足投資者與員工的固定回報,剩餘資金還是會流向非營利性組織。
提到AGI,一開始在OpenAI聲稱要做通用人工智能時,還有一堆人在嘲諷,如今做出GPT-4這樣的產品,回過頭來再看,嘲諷的聲音已經越來越少。
而面對外界詢問“GPT-4是AGI嗎”這樣的問題時,奧特曼則是直接給出自己理解中的AGI:
AGI所掌握的知識應該是要超過人類科學知識總和的,並且具有創造性,能夠推動基礎科學的發展;
而目前所有GPT並不能做到這些,想要達到AGI還需要在目前GPT的范式上進行拓展,至於如何拓展,正是目前所缺乏的。
值得一提的是,談到AGI時,是奧特曼在訪談中鮮有的“兩眼放光”的時刻。
他拋出一句極具“科研分子理想情懷”的金句:
也許AGI是永遠抵達不的烏托邦,但這個過程會讓人類越來越強大。
但奧特曼並不否認過分強大的AGI“可能殺死人類”這一觀點:
我必須承認,(AI殺死人類)有一定可能性。
很多關於AI安全和挑戰的預測被證明是錯誤的,我們必須正視這一點,並盡早嘗試找到解決問題的方法。
One More Thing
在談話最後,Lex Fridman還試圖讓奧特曼講一些給年輕人們的建議,奧特曼直接來個“反雞湯文學”:
網絡上的“成功學”帖子太誘人,建議不要聽太多建議。
我就是無視建議做到現在這樣的。