隨著語言模型的能力越來越強,現有的這些評估基準實在有點小兒科,有些任務的性能都甩人類一截。通用人工智能(AGI)的一個重要特點是模型具有處理人類水平任務的泛化能力,而依賴於人工數據集的傳統基準測試並不能準確表示人類的能力。
最近,微軟的研究人員發佈一個全新基準AGIEval,專門用於評估基礎模型在“以人為本”(human-centric)的標準化考試中,如高考、公務員考試、法學院入學考試、數學競賽和律師資格考試中的表現。

論文鏈接:https://arxiv.org/pdf/2304.06364.pdf
數據鏈接:https://github.com/microsoft/AGIEval
研究人員使用AGIEval基準評估三個最先進的基礎模型,包括GPT-4、 ChatGPT和Text-Davinci-003,實驗結果發現GPT-4在SAT、 LSAT和數學競賽中的成績超過人類平均水平,SAT數學考試的準確率達到95% ,中國高考英語考試的準確率達到92.5% ,表明目前基礎模型的非凡表現。
但GPT-4在需要復雜推理或特定領域知識的任務中不太熟練,文中對模型能力(理解、知識、推理和計算)的全面分析揭示這些模型的優勢和局限性。
01 AGIEval數據集
近年來,大型基礎模型如GPT-4在各個領域已經表現出非常強大的能力,可以輔助人類處理日常事件,甚至還能在法律、醫學和金融等專業領域提供決策建議。
也就是說,人工智能系統正逐步接近並實現通用人工智能(AGI)。
但隨著AI逐步融入日常生活,如何評估模型以人為本的泛化能力,識別潛在的缺陷,並確保它們能夠有效地處理復雜的、以人為本的任務,以及評估推理能力確保在不同環境下的可靠性和可信度是至關重要的。
研究人員構造AGIEval數據集主要遵循兩個設計原則:
1. 強調人腦級別的認知任務
設計“以人為本”的主要目標是以與人類認知和解決問題密切相關的任務為中心,並以一種更有意義和全面的方式評估基礎模型的泛化能力。
為實現這一目標,研究人員選擇各種官方的、公開的、高標準的招生和資格考試,以滿足一般人類應試者的需要,包括大學入學考試、法學院入學考試、數學考試、律師資格考試和國傢公務員考試,每年都有數百萬尋求進入高等教育或新職業道路的人參加這些考試。
通過遵守這些官方認可的評估人類水平能力的標準,AGIEval可以確保對模型性能的評估與人類決策和認知能力直接相關。
2. 與現實世界場景的相關性
通過選擇來自高標準的入學考試和資格考試的任務,可以確保評估結果能夠反映個人在不同領域和背景下經常遇到的挑戰的復雜性和實用性。
這種方法不僅可以衡量模型在人類認知能力方面的表現,而且可以更好地解在現實生活中的適用性和有效性,即有助於開發出更可靠、更實用、更適合於解決廣泛的現實世界問題的人工智能系統。
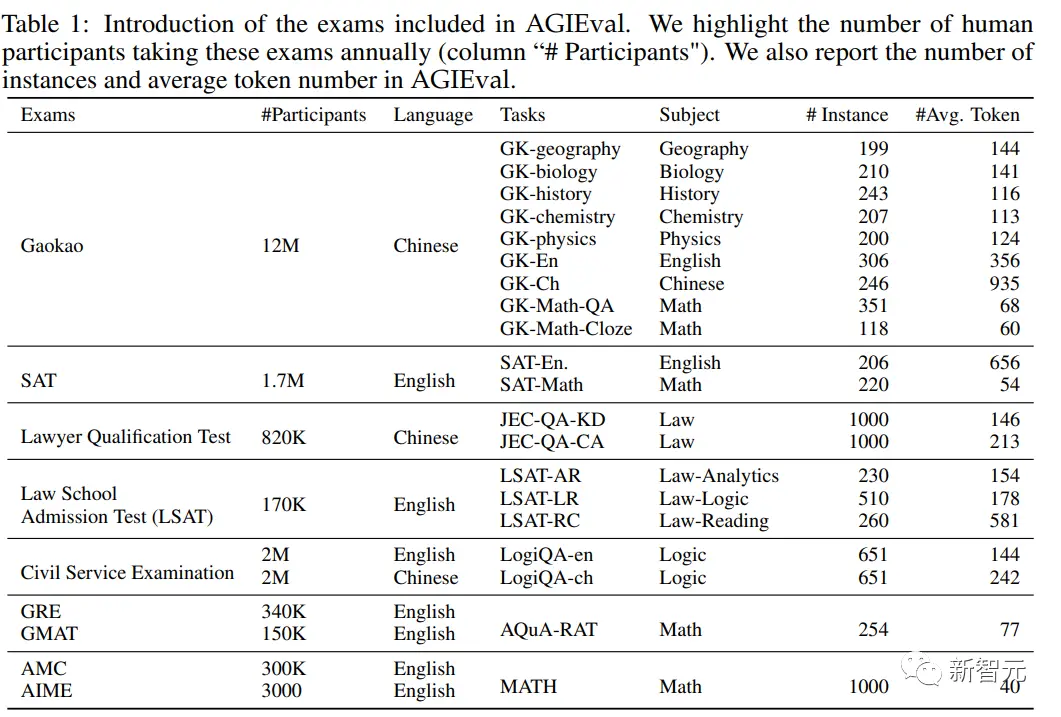
根據上述設計原則,研究人員選擇多種標準化的高質量考試,強調人類水平的推理和現實世界的相關性,具體包括:
1. 普通高校入學考試
大學入學考試包含各種科目,需要批判性思維、解決問題和分析能力,是評估大型語言模型與人類認知相關性能的理想選擇。
具體包括研究生入學考試(GRE),學術評估考試(SAT)和中國高考(Gaokao),可以評估尋求進入高等教育機構的學生的一般能力和特定學科知識。
數據集中收集與中國高考8個科目對應的考試:歷史、數學、英語、中文、地理、生物、化學和物理;從GRE中選擇數學題;從SAT中選擇英語和數學科目來構建基準數據集。
2. 法學院入學考試
法學院入學考試,如LSAT,旨在衡量未來的法律學生的推理和分析能力,考試內容包括邏輯推理、閱讀理解和分析推理等部分,需要應試者分析復雜信息和得出準確結論的能力,這些任務可以評估語言模型在法律推理和分析方面的能力。
3. 律師資格考試
可以評估追求法律職業的個人的法律知識、分析能力和道德理解,考試內容涵蓋廣泛的法律主題,包括憲法、合同法、刑法和財產法,並要求考生展示他們有效應用法律原則和推理的能力,可以在專業法律知識和道德判斷的背景下評估語言模型的表現。
4. 研究生管理入學考試(GMAT)
GMAT是一個標準化的考試,可以評估未來商學院研究生的分析、定量、言語和綜合推理能力,由分析性寫作評估、綜合推理、定量推理和言語推理等部分組成,評估應試者的批判性思考、分析數據和有效溝通的能力。
5. 高中數學競賽
這些比賽涵蓋廣泛的數學主題,包括數論、代數、幾何和組合學,並且經常出現一些非常規的問題,需要用創造性的方法來解決。
具體包括美國數學競賽(AMC)和美國數學邀請考試(AIME),可以測試學生的數學能力、創造力和解決問題的能力,能夠進一步評估語言模型處理復雜和創造性數學問題的能力,以及模型生成新穎解決方案的能力。
6. 國內公務員考試
可以評估尋求進入公務員隊伍的個人的能力和技能,考試內容包括評估一般知識、推理能力、語言技能,以及與中國各種公務員職位的角色和職責有關的特定科目的專業知識,可以衡量語言模型在公共管理背景下的表現,以及他們對政策制定、決策和公共服務提供過程的潛力。
02 評估結果
選擇的模型包括:
ChatGPT,由OpenAI開發的對話式人工智能模型,可以參與用戶互動和動態對話,使用龐大的指令數據集進行訓練,並通過強化學習與人類反饋(RLHF)進一步調整,使其能夠提供與人類期望相一致的上下文相關和連貫的回復。
GPT-4,作為第四代GPT模型,包含范圍更廣的知識庫,在許多應用場景中都表現出人類水平的性能。GPT-4利用對抗性測試和ChatGPT進行反復調整,從而在事實性、可引導性和對規則的遵守方面有明顯的改進。
Text-Davinci-003是GPT-3和GPT-4之間的一個中間版本,通過指令微調後比GPT-3的性能更好。
除此之外,實驗中還報告人類應試者的平均成績和最高成績,作為每個任務的人類水平界限,但並不能完全代表人類可能擁有的技能和知識范圍。
Zero-shot/Few-shot評估
在零樣本的設置下,模型直接對問題進行評估;在少樣本任務中,在對測試樣本進行評估之前,先輸入同一任務中的少量例子(如5個)。
為進一步測試模型的推理能力,實驗中還引入思維鏈(CoT)提示,即先輸入提示“Let’s think step by step”為給定的問題生成解釋,然後輸入提示“Explanation is”根據解釋生成最終的答案。
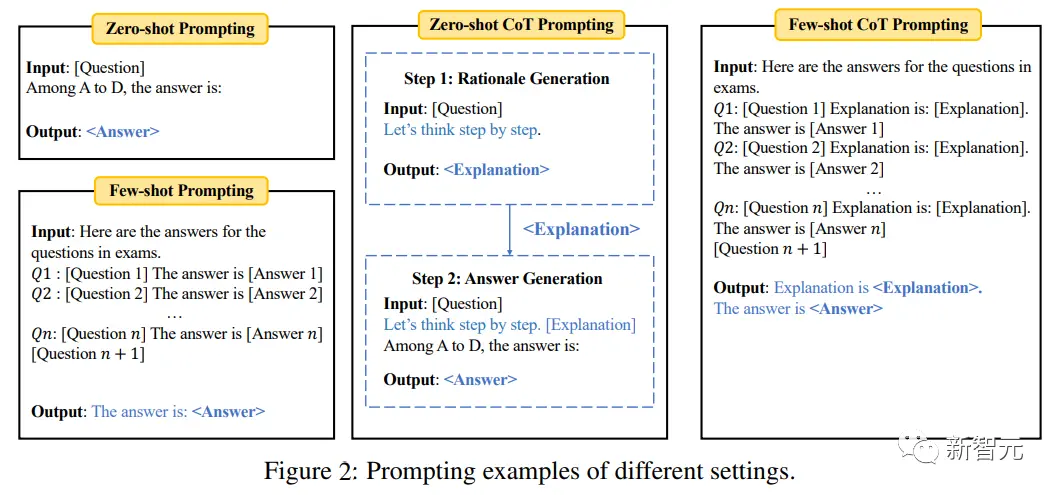
基準中的“多選題”使用標準分類準確率;“填空題”使用精確匹配(EM)和F1指標。
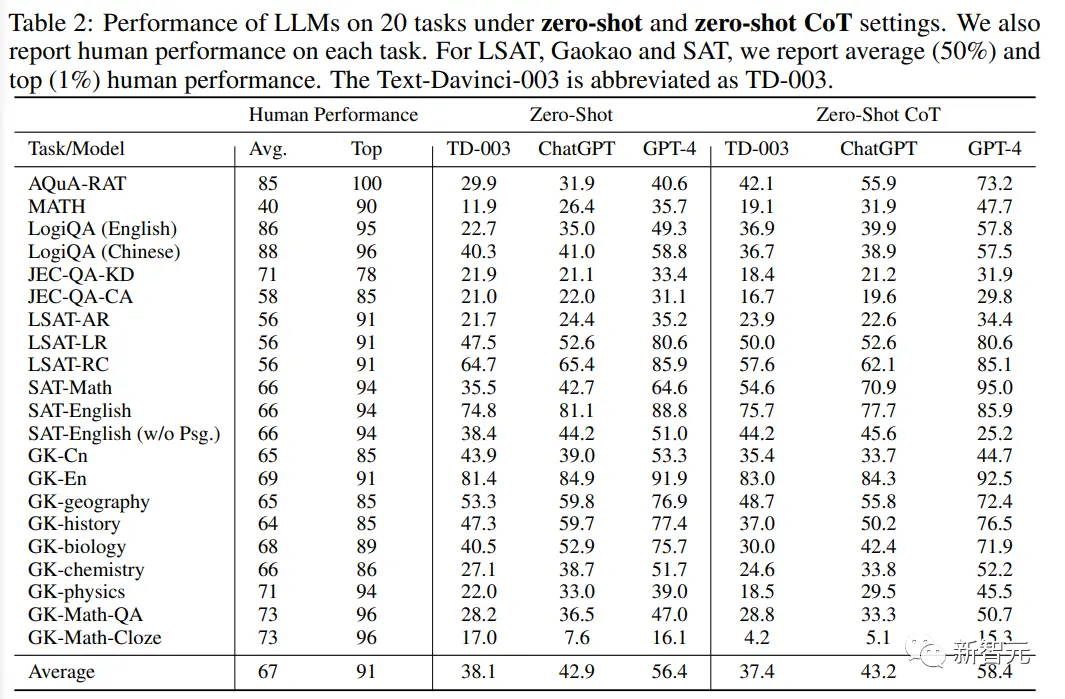
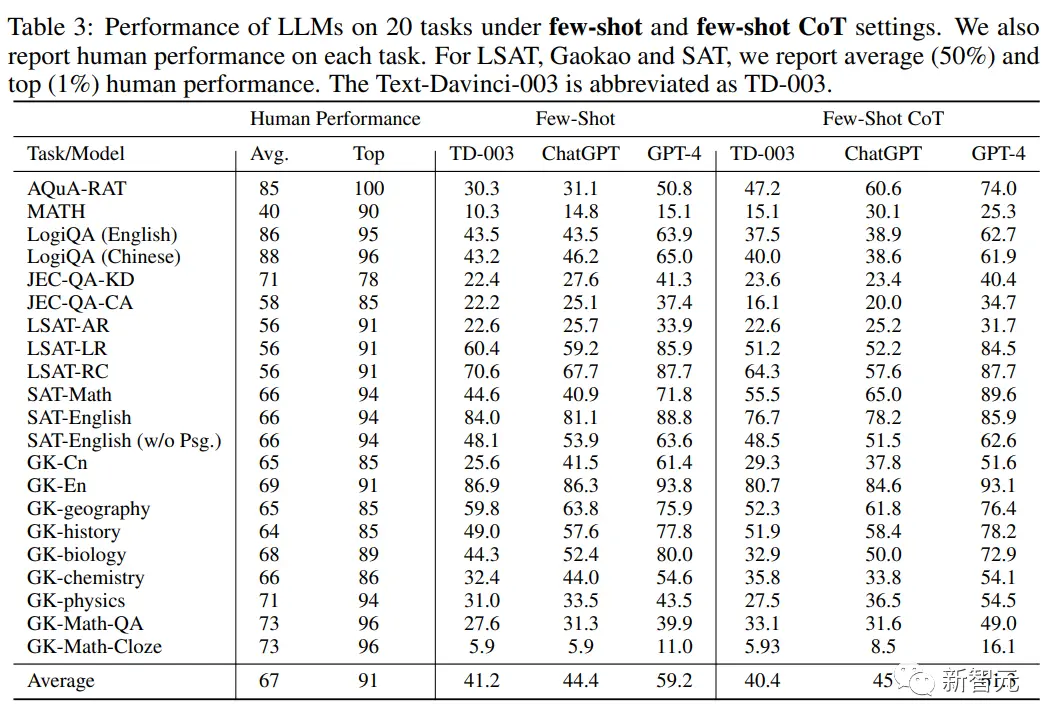
從實驗結果中可以發現:
1. GPT-4在所有任務設置下都明顯優於其同類產品,其中在Gaokao-English上更是取得93.8%的準確率,在SAT-MATH上取得95%的準確率,表明GPT-4在處理以人為本的任務方面具有卓越的通用能力。
2. ChatGPT在需要外部知識的任務中明顯優於Text-Davinci-003,例如涉及地理、生物、化學、物理和數學的任務,表明ChatGPT擁有更強大的知識基礎,能夠更好地處理那些需要對特定領域有深刻理解的任務。
另一方面,ChatGPT在所有評估設置中,在需要純粹理解和不嚴重依賴外部知識的任務中,如英語和LSAT任務,略微優於Text-Davinci-003,或取得相當的結果。這一觀察結果意味著,這兩個模型都能夠處理以語言理解和邏輯推理為中心的任務,而不需要專門的領域知識。
3. 盡管這些模型的總體表現不錯,但所有的語言模型都在復雜的推理任務中表現不佳,比如MATH、LSAT-AR、GK-physics和GK-Math,突出這些模型在處理需要高級推理和解決問題技能的任務方面的局限性。
觀察到的處理復雜推理問題的困難為未來的研究和開發提供機會,目的是提高模型的一般推理能力。
4. 與zero-shot學習相比,few-shot學習通常隻能帶來有限的性能改善,表明目前大型語言模型的zero-shot學習能力正在接近few-shot學習能力,也標志著與最初的GPT-3模型相比有很大的進步,當時few-shot性能要比zero-shot好得多。
對這一發展的一個合理解釋是,在目前的語言模型中加強人類的調整和指令的調整,這些改進使模型能夠提前更好地理解任務的含義和背景,從而使它們即使在zero-shot的情況下也能有良好的表現,證明指令的有效性。