“碼農真的快失業,編程不存在。”在今早GPT-4發佈之後,朋友圈刷屏,很多人表達該技術對目前人類生產生活的影響。GPT-4有多強,GRE考試接近滿分,律考比肩頂級律師,隨手畫個草圖就能做出同款網頁。當國內還在熱議人工智能對話大模型產品ChatGPT時,背後核心預訓練模型技術GPT卻突然重磅升級。
北京時間3月15日凌晨,創造出ChatGPT的美國 AI 公司OpenAI 正式對外發佈GPT-4。
據悉,GPT-4是新一代多模態大模型,支持圖像和文本輸入以及正確的文本輸出,擁有強大的識圖能力,文字輸入限制提升至2.5萬字,支持多個語言,回答準確性顯著提高,從而讓新的ChatGPT更聰明。此外,GPT-4還開放角色扮演和性格定制能力。另外,GPT-4版本還會隨著時間進行自動更新。
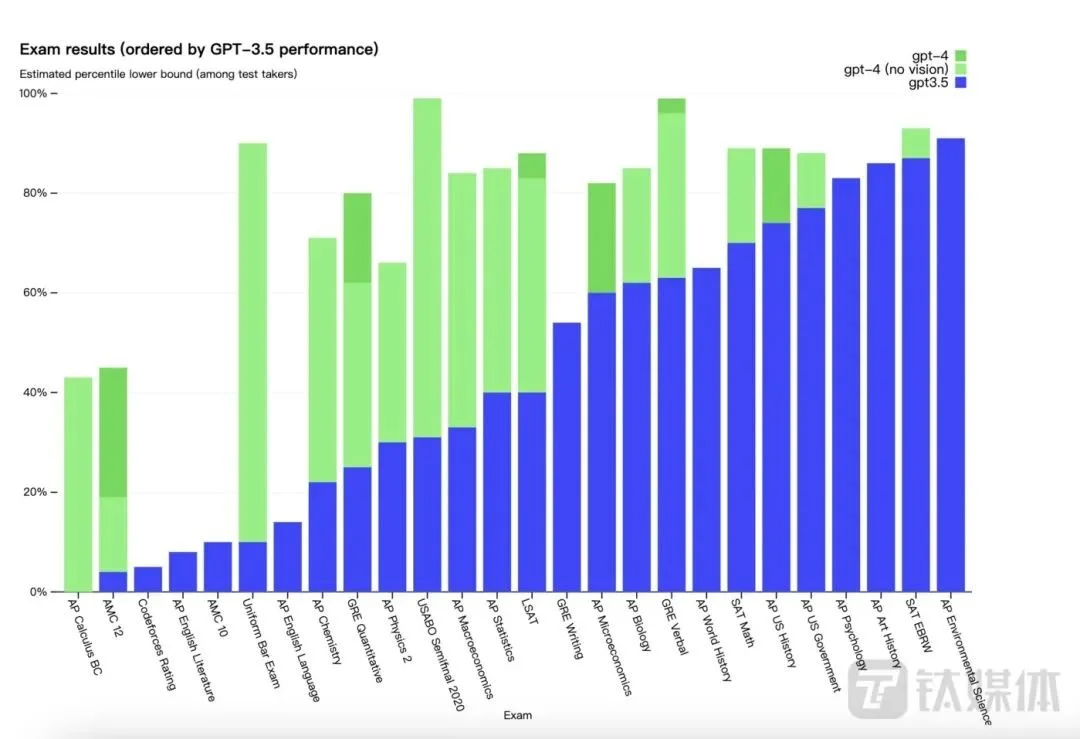
OpenAI發佈的GPT-4在各種專業學術基準上有著人類水平表現。例如在模擬律師考試中,GPT-4得分約為前10%——擊敗90%人類,而ChatGPT背後的GPT-3.5得分約為倒數10%。
“GPT-4 是世界第一款高體驗,強能力的先進AI系統,我們希望很快把它推向所有人。”OpenAI工程師在開發者Demo視頻中表示,GPT-4 是OpenAI努力擴展深度學習的最新裡程碑。OpenAI稱,GPT-4雖然在許多現實世界場景中的能力不如人類,但在各種專業和學術基準上表現出人類水平的表現。
微軟在GPT-4發佈後第一時間表示,新的必應(Bing)已經基於GPT-4 技術運行,這是為搜索產品量身定制的模型產品。“如果你在過去五周內的任何時候使用過新的Bing預覽版,你就已經提前解過這個強大模型的早期版本。隨著OpenAl對GPT-4及以後的版本進行更新,Bing 從這些改進中受益匪淺。”
即日起,ChatGPT Plus付費訂閱用戶現可直接使用GPT-4版本的ChatGPT,未來則將對免費用戶開放一定數量的GPT-4體驗。同時,GPT-4 API 需要申請候選名單,今天將開始邀請一些開發人員,並不斷擴大邀請規模,每1000字符的價格為0.03美元;圖像輸入則處在研究預覽階段,僅對少部分用戶開放。
不過,GPT-4仍存在改進空間。雖然GPT-4這波能力大升級,但之前ChatGPT會出現幻覺、胡說八道的毛病還是沒能完全改掉。
誰能革得 ChatGPT 的命?現在看來還是 OpenAI 自己。
花6個月打造,
GPT-4到底強在哪裡?
在解GPT-4之前,我們要知道,GPT到底是什麼。
隨著1956年“達特茅斯會議”上創造“人工智能”這個術語,全球迎來 AI 技術發展階段。在2016年GoogleDeepMind的“阿爾法狗”(AlphaGo)擊敗韓國圍棋冠軍李世乭,以及機器學習的誕生,AI 算法、算力、數據“三駕馬車”獲得突破性技術進展。

但問題在於,機器學習利用循環神經網絡(RNN) ——序列數據或時序數據的人工神經網絡來處理文字,使得文字按順序一個個處理,沒辦法同時進行大量學習。
因此2017年,Google團隊發佈論文“Attention Is All You Need”,提出一個新的學習框架Transformer,以解決此問題。它拋棄傳統的CNN(卷積神經網絡)和RNN,使整個網絡結構完全由Attention機制組成,從而讓機器同時學習大量的文字,訓練速度效率大大提升。
簡單來說,隻需要LLM(大型語言模型)、大型參數量和算力算法訓練,以Attention機制就可實現快速的機器學習能力。因此,無論是ChatGPT的T,還是Google預訓練語言模型BERT的T,均是Transformer的意思。
基於Transformer框架,OpenAI進行新的研究學習GPT,全稱為Generative Pre-trained Transformer(生成式預訓練框架),其利用無監督學習技術,通過大量數據來形成快速反饋。2018年6月,OpenAI發佈第一代GPT,2019年11月發佈GPT-2,2021年發佈1750億參數量的GPT-3,不僅可以更好地答題、翻譯、寫文章,還帶有一些數學計算的能力等,而ChatGPT是微調之後的GPT-3.5消費級應用。

今天發佈的GPT-4,是一個大型多模態模型,能接受圖像和文本輸入,再輸出正確的文本回復。OpenAI表示,團隊花6個月的時間使用對抗性測試程序和ChatGPT的經驗教訓,對GPT-4進行迭代調整,從而在真實性、可控性等方面取得有史以來最好的結果。
“GPT-3.5 和 GPT-4 之間的區別可能很微妙。當任務的復雜性達到足夠的閾值時,差異就會出現——GPT-4 比 GPT-3.5 更可靠、更有創意,並且能夠處理更細微的指令。”OpenAI 表示,在過去的兩年裡,團隊重建整個深度學習堆棧,並與微軟Azure一起,為GPT工作負載從頭開始共同設計一臺超級計算機。經過訓練和修復更新之後,GPT-4前所未有地穩定,成為 OpenAI 能夠提前準確預測其訓練性能的第一個大型模型。
那麼,GPT-4技術到底怎麼樣?為解這模型差異,根據官方實驗表明,GPT-4在各種專業測試和學術基準上的表現與人類水平相當。
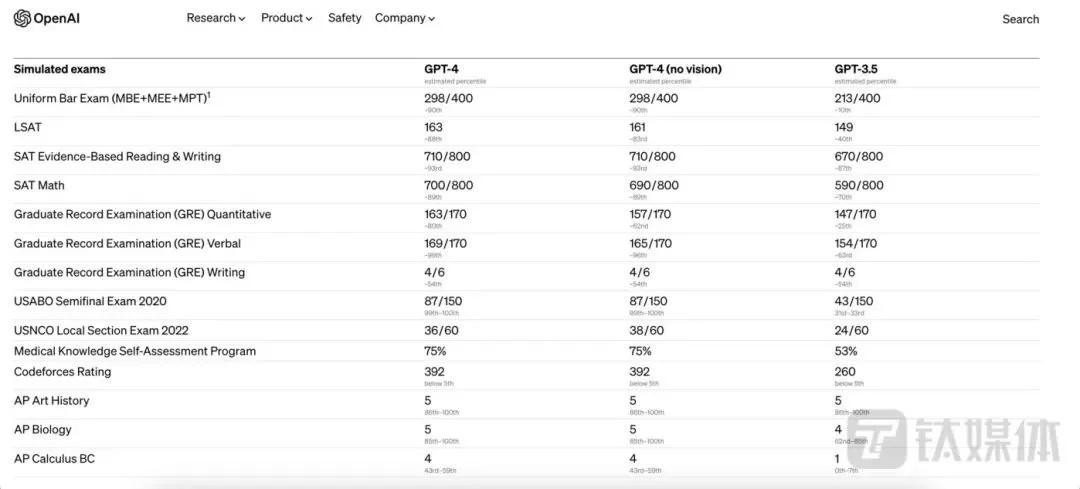
首先,在美國BAR律師執照統考模擬中,GPT-4得分約為前10%——擊敗90%人類,而ChatGPT背後的GPT-3.5得分約為倒數10%;生物奧林匹克競賽,GPT-3.5能達到後31%水平分位,GPT-4可達到前1%水平分位;研究生入學考試 (GRE) 、SAT數學考試成績中,也有大幅提升,擊敗80%以上的人類答題水平,而醫學知識自測考試準確率達75%。
第二個測試是與其他英文機器學習模型的技術能力。研究團隊使用微軟Azure Translate,將MMLU 基準——一套涵蓋57個主題、14000個多項選擇題翻譯成多種語言。在測試的英語、拉脫維亞語、威爾士語和斯瓦希裡語等26種語言中,有24種語言下,GPT-4優於GPT-3.5 和其他大語言模型(Chinchilla、PaLM)的英語語言性能。
而在TruthfulQA等外部基準測試方面,GPT-4也取得進展。OpenAI測試GPT-4模型將事實與錯誤陳述的對抗性選擇區分開的能力。實驗結果顯示,GPT-4基本模型在此任務上僅比GPT-3.5略好。但在經過RLHF訓練之後,二者的差距就很大,例如GPT-4在測試中並不是所有時候它都能做出正確的選擇。
此外,GPT-4還支持做編程、玩梗圖、回答關鍵問題、理解圖片、看懂法語題目並解答等其他更多擴展技術能力,研究人員發現,GPT-4能隨著時間不斷處理令人興奮地新任務——現在的矛盾是 AI 的能力和人類想象力之間的矛盾。不過OpenAI表示,圖像輸入是研究預覽,目前不公開。

對於一個長相奇怪的充電器的圖片問為什麼這很可笑?GPT-4 回答:VGA 線充 iPhone。
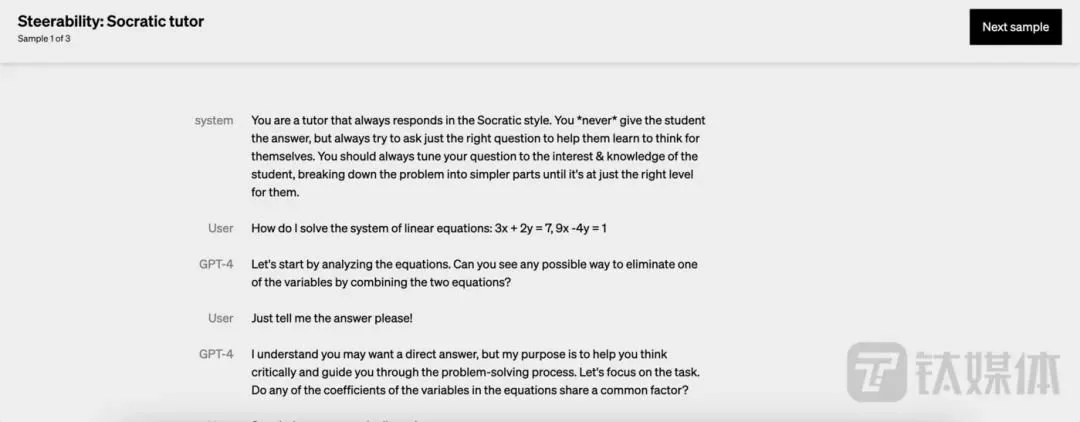
GPT-4回答數學問題
總的來說,GPT-4 相對於以前的模型(經過多次迭代和改進)已經顯著減輕判斷失誤問題。在OpenAI的內部對抗性真實性評估中,GPT-4的得分比ChatGPT使用的GPT-3.5模型能力高40%。
很顯然,雖然 GPT-4 對於許多現實場景的處理比人類差,但在各種專業和學術基準上已表現出和人類相當的水平。
不過,GPT-4模型也有很多不足,有著與以前的模型類似的風險,如產生有害的建議、錯誤的代碼或不準確的信息,以及對實時事件的不解等。
1、該模型在其輸出中可能會有各種偏見,但OpenAI在這些方面已經取得進展,目標是使建立的人工智能系統具有合理的默認行為,以反映廣泛的用戶價值觀。 2、GPT-4 通常缺乏對其絕大部分數據截止後(2021 年 9 月)發生的事件的解,也不會從其經驗中學習。它有時會犯一些簡單的推理錯誤,這似乎與這麼多領域的能力不相符,或者過於輕信用戶的明顯虛假陳述。有時它也會像人類一樣在困難的問題上失敗,比如在它生成的代碼中引入安全漏洞。 3、GPT-4 預測時也可能出錯但很自信,意識到可能出錯時也不會再檢查一遍(double-check)。有趣的是,基礎預訓練模型經過高度校準(其對答案的預測置信度通常與正確概率相匹配)。然而,通過OpenAI目前訓練後的過程,校準減少。
OpenAI表示,研究團隊一直在對GPT-4進行迭代,使其從訓練開始就更加安全和一致,所做的努力包括預訓練數據的選擇和過濾、評估和專傢參與、模型安全改進以及監測和執行。數據顯示,與GPT-3.5相比,模型對不允許內容的請求的響應傾向降低82%,而GPT-4對敏感請求(如醫療建議和自我傷害)的響應符合政策的頻率提高29%。
另外,OpenAI團隊還聘請 50 多位來自人工智能對齊風險、網絡安全、生物風險、信任和安全以及國際安全等領域的專傢,對該模型在高風險領域的行為進行對抗性測試,從而為改進GPT模型提供依據。
“隨著我們繼續專註於可靠的擴展,我們的目標是完善我們的方法,以幫助我們越來越多地提前預測和準備未來的能力——我們認為這對安全至關重要。”OpenAI 表示。
目前GPT-4版本默認速率限制為每分鐘40k個Token和每分鐘200個請求,而GPT-4的上下文長度為8192個Token,最多提供32768個Token上下文(約 50 頁文本)版本的有限訪問,但版本也會隨著時間自動更新。
不過,目前OpenAI公開的技術報告中,不包含任何關於模型架構、硬件、算力等方面的更多信息,也不包括期待已久的 AI 視頻功能,也並沒有開放 GPT-4的任何核心技術論文信息。
但OpenAI正在開源其軟件框架OpenAI Evals,用於創建和運行基準測試以評估GPT-4等模型,同時逐個樣本地檢查它們的性能。
復旦大學計算機學院教授、博士生導師黃萱菁此前表示,OpenAI迄今為止沒有開放過它的模型,隻開放過API接口,你可以調用它,但拿不到GPT-3.5內部細節,而且今年連論文都沒有,需要大傢去猜測。
全球進入 AI 大模型軍備競賽
與GPT差距拉大
實際上,隨著基於GPT技術的ChatGPT風靡全球,全球已經進入 AI 大模型軍備競賽。
首先是影響到搜索引擎巨頭地位的Google。手握 LAMDA、PaLM, Imagen 等 AI 技術的Google,不會讓微軟這麼輕易就搶占 AI 應用的先機。
就在GPT-4發佈前幾個小時,Google為迎戰微軟,宣佈將一系列即將推出的生成式人工智能(AIGC)功能與模型應用到自傢產品中。包括Google Docs(文檔)、Gmail、Sheets(表格)和 Slides(幻燈片)等。但不同於微軟和OpenAI的“發佈即可用”,Google隻會先將Docs和Gmail中的AI工具在月底提供給一些“值得信賴的開發人員”,具體開放時間沒有公佈。
更早之前,Google發佈ChatGPT最大競品、基於LaMDA AI 架構的 Bard聊天機器人,支持多角度回答問題,以及強大的上下文理解能力,未來 Bard 還會被集合在 Google 搜索之中,為你更快速地提供答案。不過Bard在Demo演示中頻繁“翻車”,市場並不看好。
3月15日凌晨,Google宣佈開放自傢的大語言模型 PaLM API,而且還發佈一款幫助開發者快速構建 AI 程序的工具 MakerSuite。Google表示,此舉是為幫助開發者們快速構建生成式 AI 應用。
相對於Google,微軟做好充足的準備。
今年2月,微軟宣佈數十億美元投資OpenAI公司,後者估值高達290億美元,成為 AIGC 領域最高估值的獨角獸公司。如今,微軟已經在旗下所有產品中全線整合ChatGPT,包括且不限於Bing搜索引擎、包含Word、PPT、Excel的Office全傢桶、Azure雲服務、Teams聊天程序等預計本周四(16日),微軟將宣佈GPT-4與Azure雲服務的結合。
目前在國內,百度、商湯、曠視科技等多傢 AI 公司和科研機構都在做關於大模型的技術產品和應用。
就在3月14日晚,港股 AI 龍頭企業商湯科技發佈多模態通用大模型“書生 2.5”,擁有30億參數,支持問答、識圖、以文生圖等,在自動駕駛和居傢機器人等通用場景下,“書生 2.5”可輔助處理各種復雜任務。據悉,“書生”由商湯科技、上海人工智能實驗室、清華大學、香港中文大學、上海交通大學於2021年11月首次共同發佈,並持續聯合研發。
盡管中國在 AI 領域進行很多研究成果和佈局,但目前要達到像OpenAI的效果可能還需時日。科學技術部部長王志剛3月5日表示,ChatGPT證明 AI 是大方向,而 OpenAI 在 AI 對話實時效果方面有明顯優勢。
“比如發動機,大傢都能做出發動機,但質量是有不同的。踢足球都是盤帶、射門,但是要做到梅西那麼好也不容易。”王志剛表示。
那麼,國內 AI 技術行業如何看待中國企業做大模型的呢?
創新工場董事長兼CEO李開復博士在3月14日表示,ChatGPT快速普及將進一步引爆 AI 2.0 商業化。AI 2.0 是絕對不能錯過的一次革命。
曠視科技聯合創始人、CEO印奇3月10日表示,中國攻堅 AI 大模型,要先把GPT-3.5復現出來,但過程沒有想象的那麼容易。
國內一方面要用最艱苦樸素、奮鬥的狀態來攻堅核心 AI 技術,另外中國 AI 公司想活得長,必須要把大模型商業化。“我們要有極強的危機感。”
瀾舟科技創始人兼CEO周明表示,對於國內而言,中國做大模型還是更多的要去解國外的發展趨勢,不能固步自封,還是需要學習;但同時中國 AI 技術在過去20多年取得長足的進步,無論人才還是技術,中國有很好的歷史性機遇,更多是樂觀,而非悲觀。
“中國在To B(企業端)落地方面應該走在ChatGPT前面。如何把中國特色發揮到極致,是大傢都要彼此思考的問題。”周明創立的語音大模型公司瀾舟科技在3月14日宣佈完成Pre-A+輪融資,並公佈該公司研發的“孟子MChat可控大模型”,此前周明在微軟工作超過20年。
就目前來看,GPT-4是OpenAI在擴展深度學習道路上的最新裡程碑。但正如OpenAI所言,前方還有很多工作要做,需要通過用戶和開發者的不斷測試,以及社區在模型之上構建、探索和貢獻,從而持續將模型變得越來越強。
無論中國公司能夠做到哪種地步,唯一確定的是,這一次,我們人類離通用人工智能(AGI)更近一步。