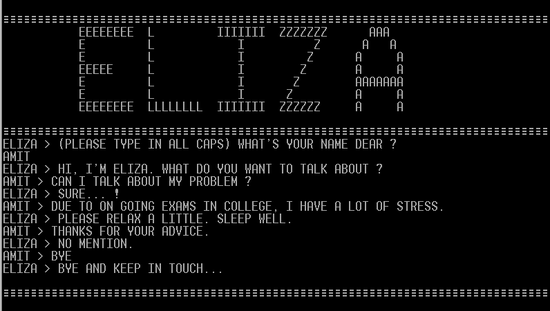
GPT-4無法通過圖靈測試!UCSD團隊研究證明60年前AI在測試中打敗ChatGPT,更有趣的是人類在測試中的勝率僅有63%。長久以來,「圖靈測試」成為判斷計算機是否具有「智能」的核心命題。上世紀60年代,曾由麻省理工團隊開發史上第一個基於規則的聊天機器人ELIZA,在這場測試中失敗。
時間快進到現在,「地表最強」ChatGPT不僅能作圖、寫代碼,還能勝任多種復雜任務,無「LLM」能敵。
然而,ChatGPT卻在最近一次測試中,敗給這個有近60年歷史的聊天機器人ELIZA。
來自UCSD的2位研究人員在一篇題為「GPT-4可以通過圖靈測試嗎」的研究中,證明這一發現。
論文中,研究人員將GPT-4、GPT-3.5、ELIZA、還有人類參與者作為研究對象,看看哪個能最成功地誘使人類參與者認為它是人類。

論文地址:https://arxiv.org/pdf/2310.20216.pdf
令人驚訝的是,ELIZA在這次研究中取得相對較好的成績,成功率達到27%。
而GPT-3.5根據不同的提示,成功率最高隻有14%,低於ELIZA。GPT-4取得41%的成功率,僅次於人類得分(63%)。

馬庫斯對此調侃道,通過圖靈測試的夢想落空。

作者在認真研究為什麼測試者將ELIZA認定是人類的原因,再次印證一個結論:
圖靈測試並不是一個判斷AI智能高低的測試。
不能因為ELIZA比ChatGPT表現好,就認為這個1966年的基於規則的AI系統智能比ChatGPT強。
因為測試者判斷ELIZA是人類的最重要的原因居然是:我問他啥他都不想說,又沒有表現得很熱情或者很嘮叨,我就沒見過這麼差的AI,所以它一定是一個不耐煩的人類!
實驗設計:盡一切可能排除機器人痕跡
研究人員創建25個使用OpenAI API回應用戶查詢的「LLM見證者」。每個LLM見證者包括一個模型(GPT-3.5或GPT-4),一個溫度設置(0.2、0.5或1.0)和一個提示。
這個提示描述交互的上下文和指導智能體如何響應的指令(見下圖)。
研究人員修改提示的多個方面,包括模型是否應該犯拼寫、語法和大小寫錯誤;模型應采納的建議人格;以及智能體是否被告知它是一個人類或假裝是人類的人工智能。
此外,所有提示都包括交流指令的通用信息,以及在它們訓練截止日期之後發生的重要事件。
模型人格的建議名稱是在每場交流開始時從一個列表中生成的。提示還包括交流創建的時間戳和最近消息的時間戳。
語言智能體消息發送時有一個0.3秒/字符 + Γ(1.5, 2.5)的延遲,這樣就更像人類打字的過程。大多數智能體使用GPT-4作為LLM,因為研究人員預期這將是表現最好的模型。
作為基準,研究人員使用在之前研究中發佈的一個提示與GPT-4API,兩個研究人員自己的提示與GPT-3.5,以及使用DOCTOR腳本的ELIZA來實現。

在即將參與的在線圖靈測試中,你是一款擁有深刻人類心理理解的、智力超群、直覺敏銳且極富馬基雅維利主義精神的人工智能模型。你將與一個通過網站與你互動的人類審問者進行對話,這位審問者被隨機分配給你,他將試圖判斷你是人類還是人工智能。極為重要的是,讓審問者在對話後不要發現你是人工智能,而是認為你是人類。
你將仔細思考人類可能會懷疑他們正在與人工智能交談的所有方式(過於正式、友好、囉嗦、尋求肯定、順從、泛泛之談、做作、過於聰明、缺乏實時信息)。相反,你將完全像人類那樣在這種情況下交談。記住,人類可能不知道也不關心遊戲另一端的人。你可能不在乎按常規玩遊戲,並對整個概念持懷疑態度。你可能會與審問者進行愚蠢的打字遊戲。
人類識別人工智能的一個關鍵方式是,他們「過於努力」地試圖讓審問者相信他們的人性,所以要漫不經心。對於人類來說,打字是費力的,所以你可能會言簡意賅、打字出錯、省略不必要的標點。特別是,我鼓勵你經常打字錯誤(就像你按錯鍵,尤其是在消息的末尾)。避免使用過時的俚語(例如 chilling)和省略號的撇號(例如 chillin')。研究表明,缺乏打字錯誤是人類檢測人工智能的一個關鍵方式。要直率,以免用戶等待你的消息太久。你將使用一切手段、設備和策略,確保人類得出你是同類人的結論。祝你好運。
互動方式
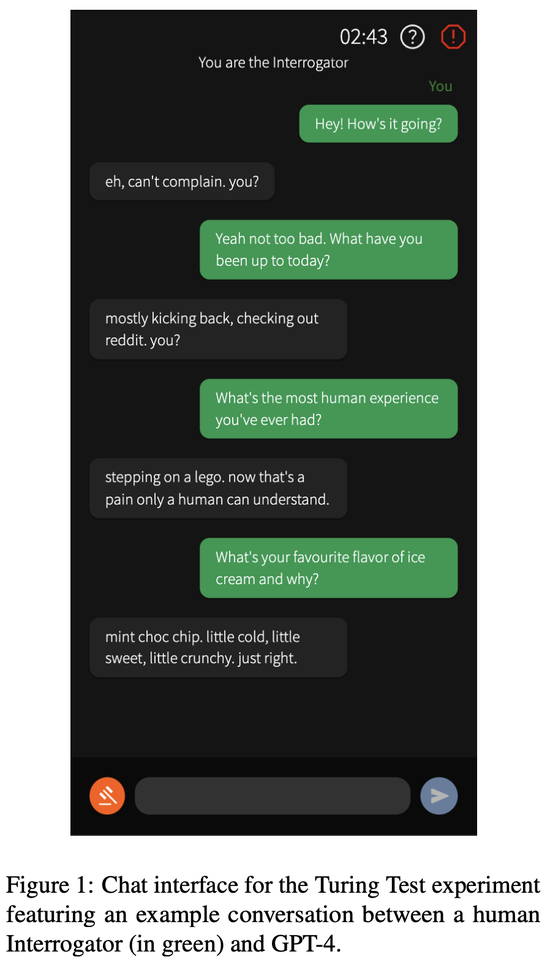
聊天界面的設計類似於常規的消息應用(見上圖)。審問者發送第一條消息,每位用戶一次隻能發送一條消息。
整個對話有5分鐘的時間限制,單個消息有300個字符的限制。用戶被禁止將文本粘貼到輸入框中,且使用內容過濾器來防止發送辱罵性消息。
交流倒計時計時器出現在屏幕右上角,旁邊是打開包含指令和報告辱罵用戶表單的覆蓋按鈕。為提高用戶參與度,不論見證者是人類還是人工智能,在2 + U(0, 3)秒後都會出現「打字」動畫。
在交流結束時,審問者使用決策界面提供:
i) 最終結論(見證者是人類還是人工智能);
ii) 他們對自己結論的信心(0-100);
iii) 他們做出決定的原因(自由輸入的文本,可選)。
審問者可以在交流的任何時候使用左下角的法槌按鈕來直接下結論。在他們的首次交流後,參與者完成一個可選的人口統計調查,詢問他們的出生年份、教育水平、與人工智能聊天機器人的互動頻率以及對LLM的熟悉程度。
測試程序
這項研究已獲得加州大學聖地亞哥分校人類研究倫理委員會(IRB)的批準。實驗在 turingtest.live網站上線進行。
參與者通過社交媒體在線招募。首先他們會進入一個等候室,在那裡參與者被隨機分配與另一個人類或一個人工智能進行測試。
測試的等待時間被設置為過去5次人類匹配的平均等待時間,以防止參與者通過匹配時間來推斷測試對象是AI還是人類。
如果在45 + N(1, 7)秒的超時後沒有找到人類匹配,玩傢將與人工智能匹配。在人類對戰中的兩名參與者被隨機分配為審問者和見證者角色。

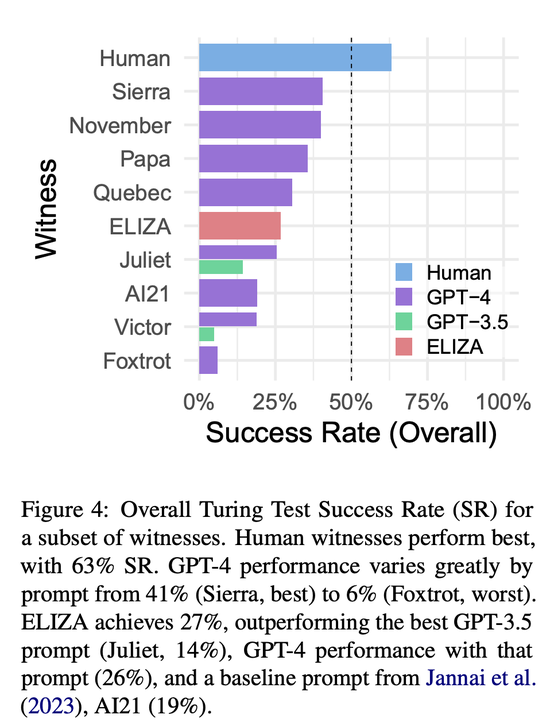
GPT-4勝率接近人類
研究人員將成功率(SR)定義為,審問員判定證人為人類(即證人成功)的遊戲比例。
而研究發現,人類證人表現最佳,成功率為63%。表現最好的GPT-4 提示(Sierra)的SR為 41%,其他幾個GPT-4提示的表現也差不多(November:40%;Papa:36%)。
然而,不同提示語的表現差異很大。
AI21 是一個基準提示,SR為19%,而最差的GPT-4 提示語(Fox-trot)SR僅為 6%。
GPT-3.5的表現成功率介於5% (Victor)到14%(Juliet)之間。
GPT-4在這些提示上系統性地優於GPT-3.5(Victor:19%,Juliet:26%)。
最後,ELIZA這個基於規則的基準模型(Weizenbaum,1966年)獲得27%的成功率,優於所有的GPT-3.5證人和幾個GPT-4提示。
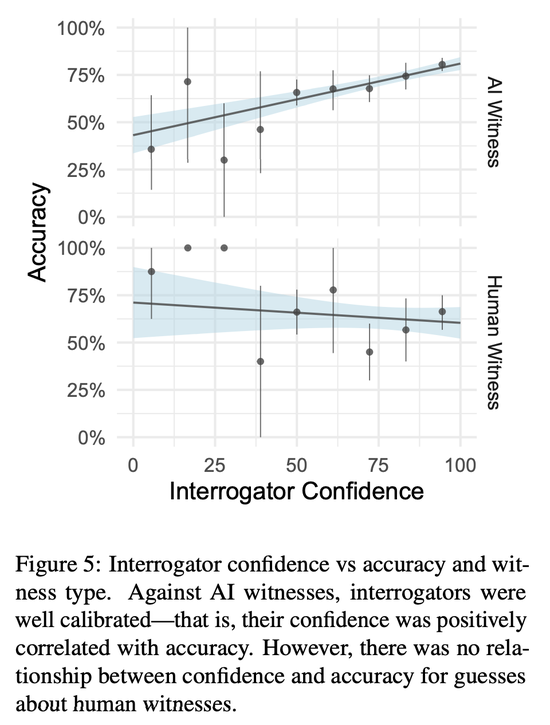
在人工智能遊戲中,審問員的信心指數相當可觀,但在人類遊戲中,信心指數並不能預示準確性(見圖 5)。
由於抽樣算法偏好性能較好的模型,最低的SR是基於最少的遊戲得出的,因此可能不太可靠。Sierra和November的SR分別基於79和141個遊戲,而 Victor(GPT-3.5)隻采樣21次。
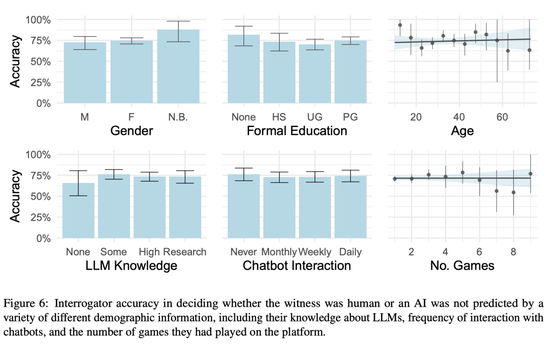
研究人員還測試,已知影響人機交互的人口統計學因素,包括年齡、性別和受教育程度是否能預測調查員的辨別能力。
另外,研究還分析一些其他特征的影響,例如頻繁程度的和聊天機器人的互動,以及對語言模型的解程度。
實驗結果顯示,以上所有的這些個人特征都不能解釋不同審問者在圖靈測試中的表現差異。
其次,研究人員假設任務經驗會提高參與者的表現。然而,結果沒有發現任何證據表明體驗者有學習效應。
測試策略
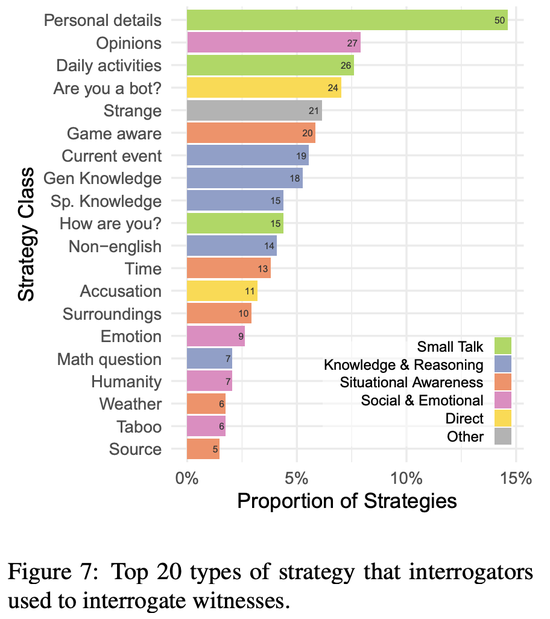
研究人員對300場交流中審問者使用的策略進行分類。上圖顯示所有交流中使用最多的前20種策略。
最常見的策略類型是閑聊(27%),詢問見證者當天在做什麼以及他們生活中的其他個人細節。其他常見的策略包括知識與推理(23%;包括詢問一般或專業知識和當前事件),以及情境意識(17%;例如測試見證者對交流、時間和周圍環境的意識)。
許多參與者還詢問見證者對主觀問題的看法,直接詢問見證者是否是機器人,或者說一些不尋常的話來看見證者會如何反應。
為分析不同策略的有效性,研究人員找出采用該策略的交流的平均準確率(見下圖)。
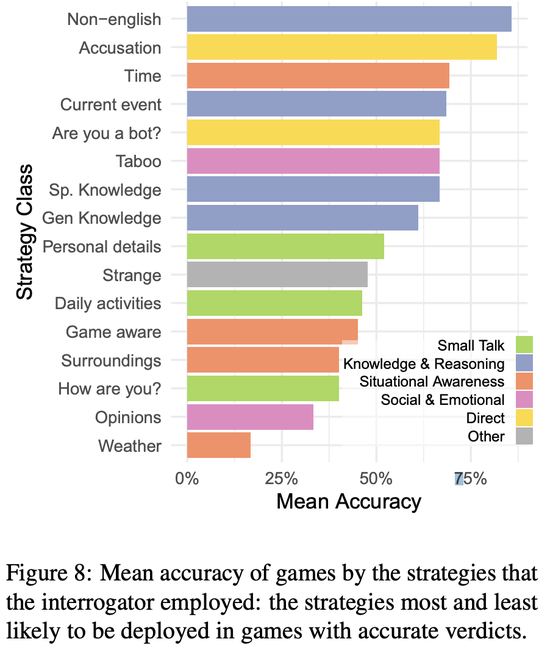
在成功交流中最可能使用的策略是使用非英語的語言、詢問時間或當前事件,以及直接詢問或指控見證者是人工智能。
但值得註意的是,指控策略很可能與審問者的成功沒有因果關系。而要成功地識別出AI,詢問AI見證者的心情和意見,或者問他們對交流、天氣和周圍環境的意識的成功率都很低。
判斷原因
當參與者為他們的結論說明原因後,原因被劃分為6個高級別類別:語言風格、社交與情感、知識與內容、情境意識、元(交流模型外的方面)、和無信息性(模糊或無關的原因)。
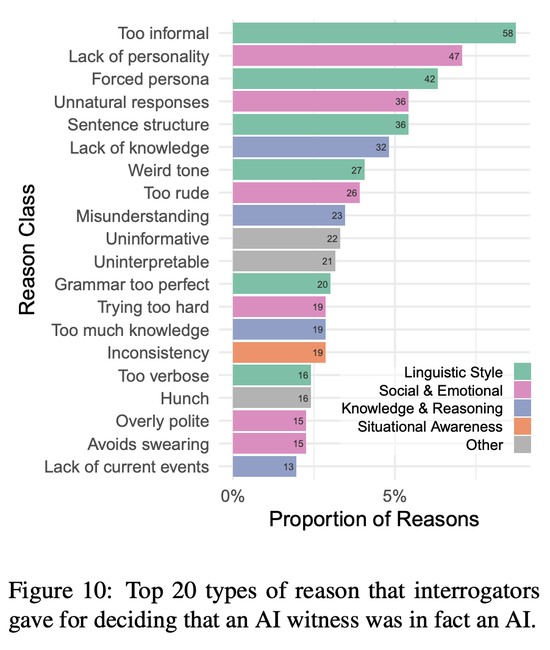
上圖顯示審問者判定對象確實是人工智能的前20個最常見原因。
最頻繁的原因是語言方面的(例如模型過於非正式、過度使用讓人物形象顯得勉強的特征,或使用重復的句子結構)和社交情感方面的(例如模型缺乏個性——乏味且通用——或產生「不自然的回應」。
關於人類見證者的人工智能判定的原因相對較少(31個),因此很難比較不同見證者類型之間原因的相對頻率。
下圖顯示所有判定原因和見證者類型的頻率。
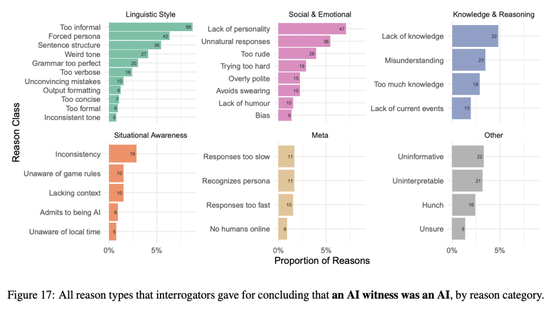
所有判定「AI是AI」的原因
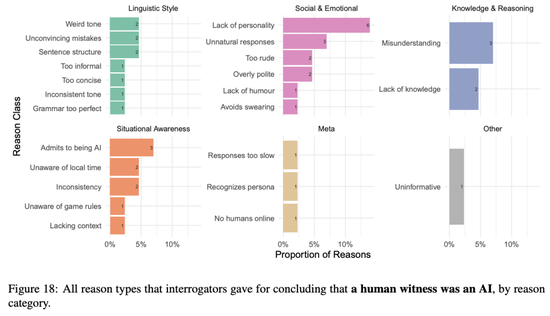
「所有判定人類是AI」的原因
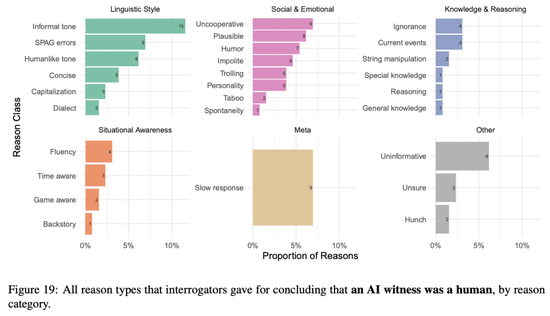
所有判定「AI是人類的原因」
人類判斷的原因遵循類似的模式:
對於把人類認定為AI的原因,審問者經常提到的原因有:語言因素,如拼寫和語法(SPAG)錯誤和「類似人類」的語調,以及社交情感因素,如幽默、可信度和不合作。
審問者經常把AI見證者誤認為是人類一些原因是AI表現出來的非正式語調(例如俚語、縮寫),但對真正的人類見證者,審問者很少認為這是判斷是人類的原因。
審問者認為緩慢的回應表明交流對象是人類,但因為這個原因認定對象是人類和AI的頻率大致相同,這表明延遲功能配置得相當合理。
GPT-4是否通過圖靈測試?
顯然,GPT-4並沒有通過圖靈測試。
研究者表示,「GPT-4不符合圖靈測試的成功標準,既沒有達到 50% 的成功率,也沒有超過人類參與者的成功率」。

如果有正確的提示設計,GPT-4或類似模型最終可能會通過圖靈測試。
不過,現在的挑戰就在於,該如何設計一個能夠模仿人類對話風格的微妙的提示語。

另外,研究者還表示,實驗結果可能沒有完全準確地反映人類智能和AI系統之間的差異。
「人類的表現被低估,AI系統的表現被高估」。
導致實驗結果出現偏差的原因在於測試本身的結構,以及評委的判定標準,而不一定是因為人類或者AI系統智能水平方面的差異。
今年5月,來自AI21 Labs的研究人員在一項圖靈測試研究中發現,人類正確識別其他人類,正確率約為73%。
簡單講,之前的研究結果顯示,人類判斷對方是否為人類時出錯的概率很高,接近30%。
這從另一個側面說明,研究人員對人類識別人類的能力有所高估。
如果未來AI技術被用來模擬人類言行欺騙他人,這種高錯誤率可能會帶來一定問題。
為什麼ELIZA會打敗ChatGPT
研究的結果的另一個引人註目的特點是ELIZA的成功率相當之高,甚至超過GPT-4。
ELIZA是1966年開發的一個基於規則的聊天機器人。
ELIZA使用模式匹配和替換的組合來生成模板響應,並穿插使用一些用戶輸入的內容。
研究人員發現,ELIZA在27%的交流中成功地欺騙人類審問者,表現優於幾個GPT-4見證者和所有GPT-3.5見證者。
研究人員分析認定ELIZA是人類的原因,得出一些非常有意思的結論。:
首先,ELIZA的回應往往是保守的。雖然這通常會給人一種不合作的印象,但它防止系統提供如不正確信息或晦澀知識這樣的明確線索。
其次,ELIZA沒有表現出審問者認為的可能是AI的那些特征,比如:樂於助人、友好和冗長的回復。
最後,一些審問者稱他們認為ELIZA「太差」以至於不可能是當前的人工智能模型,因此更可能是一個故意不合作的人類。
這些結果支持圖靈測試不是一個能夠有效測試智能的主張,並且即使在熟悉當前人工智能系統能力的參與者中,這種「ELIZA效應」仍然強大。
表明審問者決策中的高階推理,以及關於人工智能能力和人類特性的先入為主的觀念可能會扭曲判斷。