這隻四足機器人搖搖晃晃地走著,在一個健身球上努力保持平衡,這是一個有趣的實驗,但其核心是,它證明像GPT-4這樣的人工智能可以訓練機器人執行復雜的實際任務,比我們人類更有效。

DrEureka是一個任何人都可以獲取的開源軟件包,用於使用大型語言模型(LLM)(如ChatGPT 4)訓練機器人執行現實世界中的任務。這是一個"模擬到現實"系統,也就是說,它在虛擬環境中使用模擬物理原理對機器人進行教學,然後再在現實空間中實施。
吉姆-范(Jim Fan)博士是 DrEureka 的開發者之一,他部署的 Unitree Go1 四足機器人一躍成為頭條新聞。這是一款"低成本"、支持良好的開源機器人--這很方便,因為即使有人工智能,機器人寵物仍然很容易摔傷。至於"低成本",它在亞馬遜上的售價為 5899 美元,評分為 1 星……
DrEureka 中的"Dr"代表"領域隨機化",即在模擬環境中隨機化摩擦、質量、阻尼、重心等變量。

隻需在 ChatGPT 等 LLM 中輸入一些提示,人工智能就能編寫代碼,創建一個獎勵/懲罰系統,在虛擬空間中訓練機器人,其中 0 = 失敗,高於 0 則為勝利。得分越高越好。
它可以通過最小化和最大化球的彈跳力、運動強度、肢體自由度和阻尼等方面的失效點/爆發點來創建參數。作為一個 LLM,它可以毫不費力地大量創建這些參數,供訓練系統同時運行。
每次模擬後,GPT 還可以反思虛擬機器人的表現,以及如何改進。如果超出或違反參數,例如電機過熱或試圖以超出其能力的方式銜接肢體,都將導致 0 分...沒有人喜歡得零分,人工智能也不例外。

提示 LLM 編寫代碼需要安全指令--否則,研究小組發現 GPT 會努力追求最佳性能,會在沒有指導的情況下在模擬中"作弊"。這在模擬中沒有問題,但在現實生活中可能會導致電機過熱或肢體過度伸展,從而損壞機器人--研究人員稱這種現象為"退化行為"。
虛擬機器人自學成才的非自然行為的一個例子是,它發現自己可以更快地移動,方法是將臀部插入地面,用三隻腳拖著臀部在地板上竄來竄去。雖然這在模擬中是一種優勢,但當機器人在現實世界中嘗試時就尷尬。
因此,研究人員指示 GPT 要格外小心,因為機器人將在真實世界中接受測試--為此,GPT 創建安全功能,如平滑動作、軀幹方向、軀幹高度,並確保機器人的電機不會扭矩過大。如果機器人作弊,違反這些參數,其獎勵函數就會降低得分。安全功能可以減少退化和不自然的行為,比如不必要的骨盆推力。
那麼它的表現如何呢?比我們強。DrEureka 在訓練機器人"pooch"的過程中擊敗人類,在實際的混合地形中,它的前進速度和行進距離分別提高 34% 和 20%。
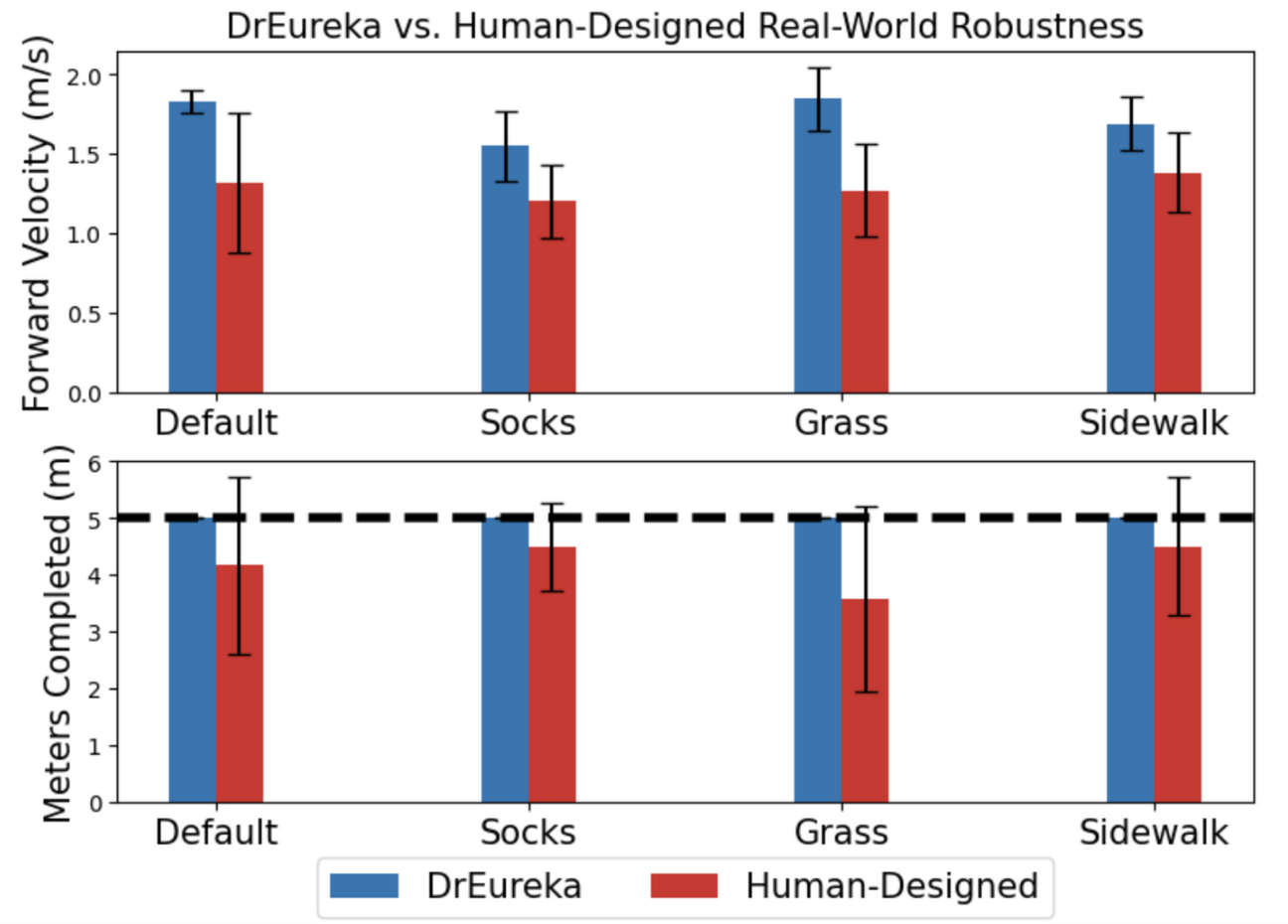
DrEureka 基於 GPT 的訓練系統在現實世界中輕松擊敗人類訓練的機器人
如何做到?研究人員認為,這與教學方式有關。人類傾向於課程式的教學環境--把任務分解成一個個小步驟,並試圖孤立地解釋它們,而 GPT 能夠有效地一次性傳授所有知識。這是我們根本無法做到的。
DrEureka 是同類產品中的首創。它能夠從模擬世界"零距離"進入現實世界。想象一下,在對周圍世界幾乎一無所知的情況下,你被推出巢穴,隻能自己摸索。這就是"零鏡頭"。
DrEureka 的創造者認為,如果他們能向 GPT 提供真實世界的反饋,就能進一步改進模擬到現實的訓練。目前,所有的模擬訓練都是利用機器人自身本體感覺系統的數據完成的,但如果 GPT 能夠通過真實世界的視頻畫面看到出錯的地方,而不是僅僅從機器人的日志中讀取執行失敗的信息,那麼它就能更有效地完善自己的指令。
人類平均需要一年半的時間才能學會走路,而大概隻有百分之一的人類能在瑜伽球上學會走路。
您可以在這裡觀看一段未經剪輯的 4 分 33 秒視頻,視頻中機器人狗狗輕松在瑜伽球上散步,且沒有停下來在消防栓上撒尿: