“超級智能可能會即將到來,也可能不會。但無論如何,都有很多值得擔心的事情。”近日,人工智能領域內的“叛逆者”、紐約大學心理學和神經科學榮譽教授GaryMarcus發文稱,“我們需要停止擔心機器人接管世界,而是更多地考慮那些壞人可能會利用LLMs做什麼,以及我們可以做什麼來阻止他們。”
此前,Marcus 與馬斯克等上千人聯名呼籲 “所有人工智能實驗室應立即暫停訓練比 GPT-4 更強大的大模型,這一時間至少為 6 個月”。
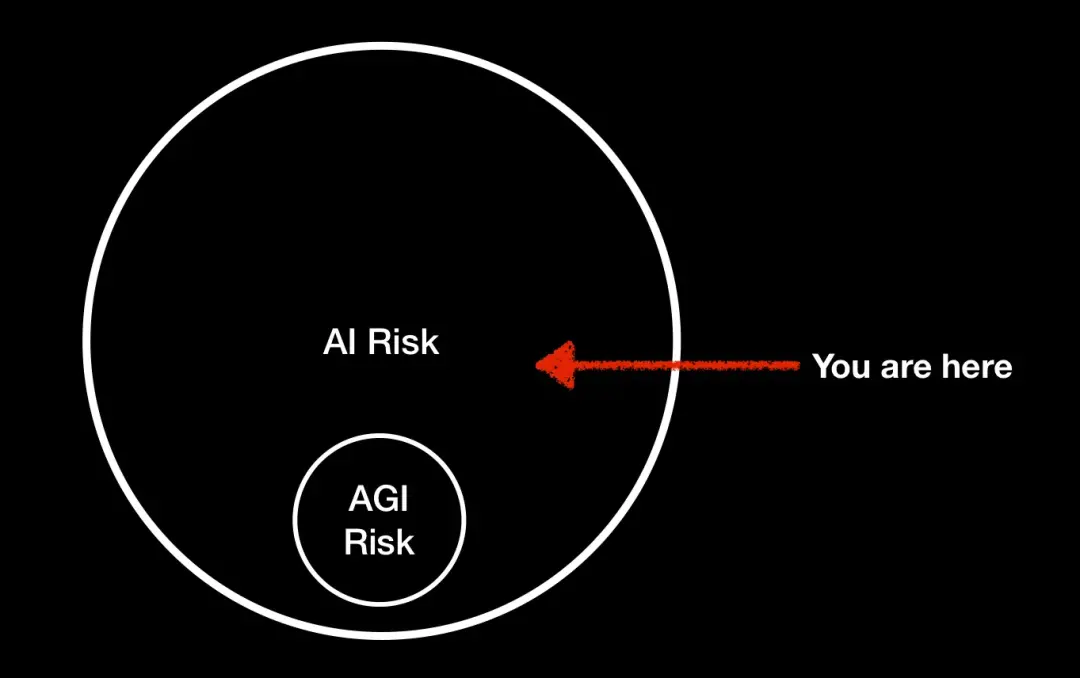
在 Marcus 看來,AI風險 ≠ AGI風險,盡管很多人將人工智能的風險等同於超級智能或 AGI 的風險,但並非隻有超級智能才能造成嚴重的問題。如 Bing 和 GPT-4 等不可靠但被廣泛部署的人工智能,也會對現實世界造成不可忽視的風險。
學術頭條在不改變原文大意的情況下,對文章做簡單的編輯。

人工智能會殺死我們所有人嗎?我不知道,你也不知道。
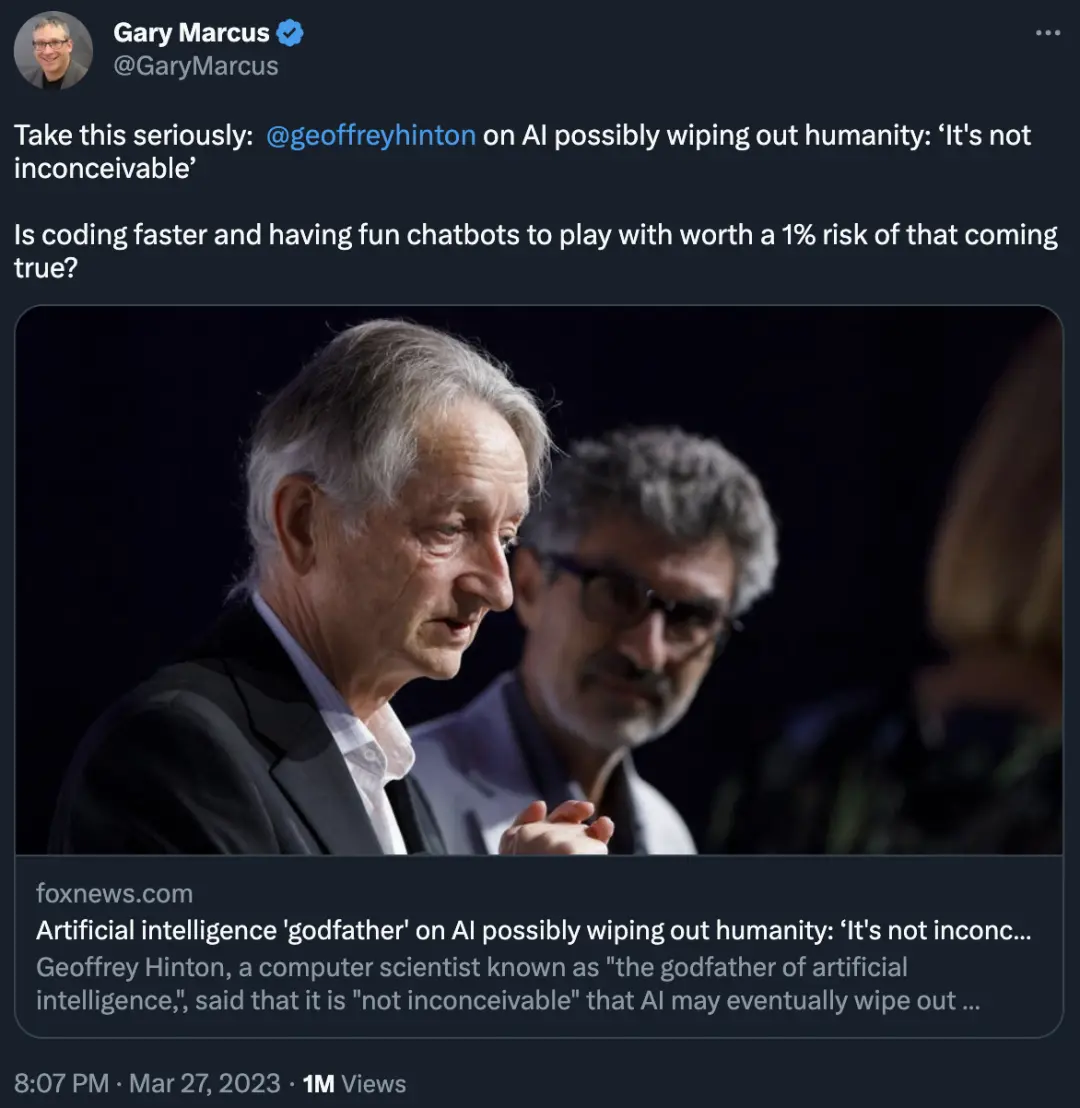
但 Geoff Hinton(深度學習三巨頭之一)已經開始擔心,我也是。上周,我通過小道消息(the grapevine)聽說 Hinton 的擔憂,他也已公開承認。
Hinton 於近日接受 CBS News 的采訪,當被問及人工智能是否可能“消滅人類”時,他表示,“這並非不可想象(It's not inconceivable)。我隻想說這些。”
在放大他的擔憂後,我提出一個思想實驗:
編碼速度更快、擁有有趣的聊天機器人,值得 1% 的風險來實現嗎?
很快,數以百計的人,甚至馬斯克也加入進來。
Hinton、馬斯克和我,甚至很少能在同一件事情上達成部分意見一致。馬斯克和我還在本周早些時候簽署一封來自生命未來研究所(FLI)的公開信。
公開信指出,最近幾個月,人工智能實驗室陷入一場失控的競賽,他們沒有辦法理解、預測或可靠地控制自己創造的大模型。人類社會對其可能造成的影響也沒有做好準備。因此,Marcus 等人在公開信中呼籲,所有人工智能實驗室應立刻暫停訓練比 GPT-4 更強大的人工智能模型,這一時間至少為 6 個月。
自從我發佈這些推文後,我就一直受到反擊和質疑。一些人認為我誤解 Hinton 的說法(鑒於我的獨立來源,我很確定我沒有);另一些人則抱怨我關註一系列錯誤的風險(要麼過於關註短期的,要麼過於關註長期的)。
一位傑出的業內同行寫信質問我:“這封公開信難道不會導致人們對即將到來的 AGI、超級智能等產生毫無道理的恐懼嗎?” 一些人對我放大 Hinton 的擔憂感到非常驚訝,以至於在Twitter上冒出一整條猜測我自己信念的話題:
事實上,我的信念並沒有改變。我仍然認為,大型語言模型(LLMs)與超級智能/通用人工智能(AGI)之間沒什麼關系;我與 Yann LeCun(深度學習三巨頭之一)一樣,仍然認為 LLMs 是通往 AGI 之路的一個 “匝道”。
我對最壞情況的設想也許與 Hinton 或馬斯克的設想不同;據我所知,他們的設想似乎主要圍繞著如果計算機迅速且徹底地實現自我改進會發生什麼,我認為這不是一種當前的可能性。
我要討論的問題是:盡管很多人將人工智能的風險等同於超級智能或 AGI 的風險,但並非隻有超級智能才能造成嚴重的問題。
就當前而言,我並不擔心 “AGI 風險”(我們無法控制的超級智能機器的風險),我擔心的是我所說的 “MAI 風險”--不可靠(如 Bing 和 GPT-4)但被廣泛部署的人工智能--無論是從使用它的人的數量,還是從軟件對世界的訪問來看。
某一傢人工智能公司剛剛籌集 3.5 億美元來做這件事,允許 LLMs 訪問幾乎所有的東西(旨在通過 LLMs “增強你在世界任何軟件工具或 API 上的能力”,盡管它們明顯有幻覺和不可靠的傾向)。
很多普通人,也許智力高於平均水平,但不一定是天才級別的,在歷史上創造各種問題;在許多方面,關鍵的變量不是智力,而是權力。原則上說,一個擁有核密碼的白癡可以毀滅世界,隻需要不多的智力和不應有的訪問權限。
如果 LLMs 可以從一個人手中騙到驗證碼,正如 OpenAI 最近觀察到的那樣,在一個壞人手中,這種能力可以制造各種混亂。當 LLMs 是實驗室內滿足人們好奇心的產物,隻在該領域內為人所知時,它們不會構成什麼大問題。但現在,它們廣為人知,並引起一些壞人的興趣,它們越來越多地被賦予與外部世界(包括人類)的聯系,它們可以造成更大的破壞。
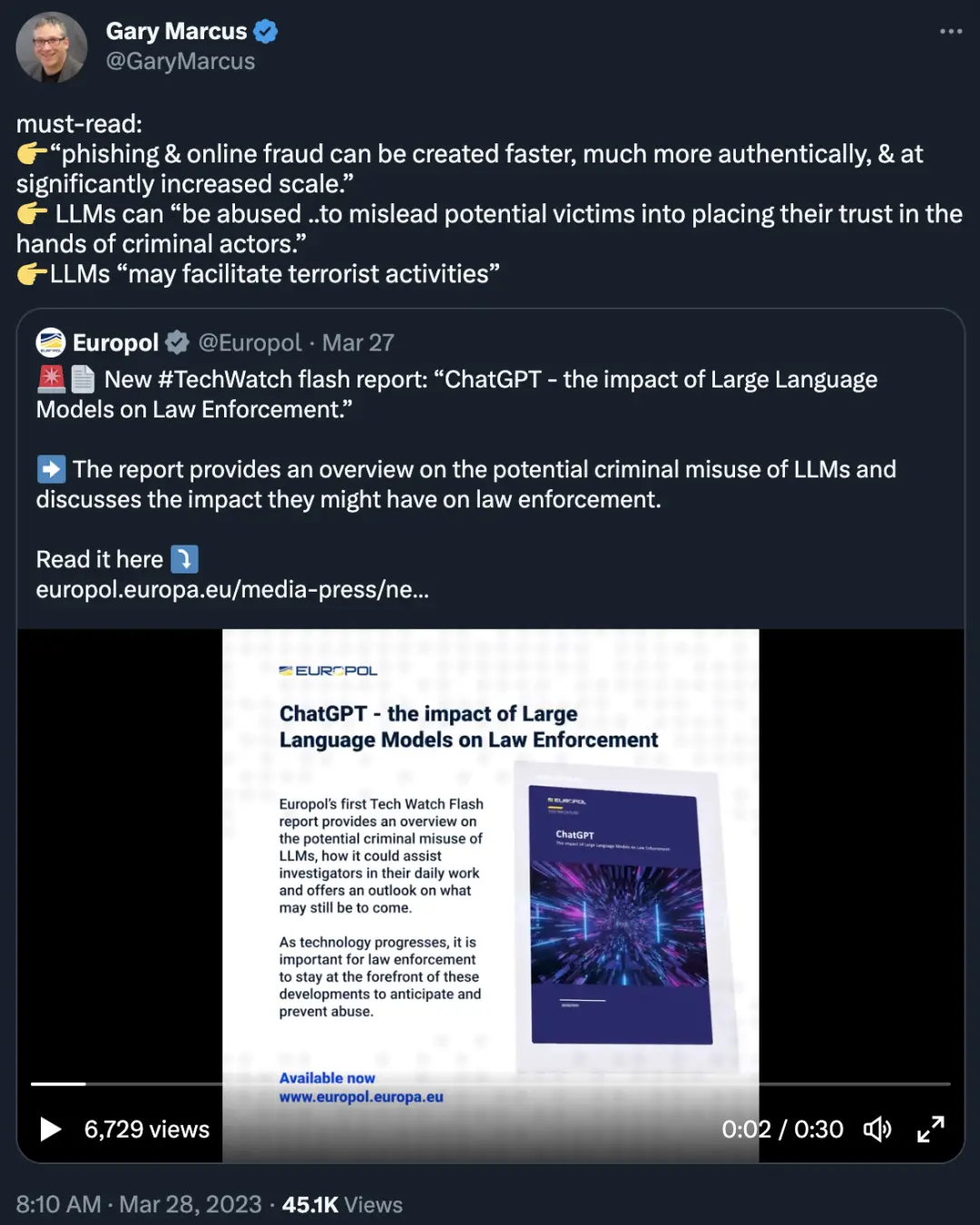
雖然人工智能社區經常關註長期風險,但我並不是唯一擔心嚴重的、短期影響的人。歐洲刑警組織(Europol)發佈一份報告,考慮一些犯罪的可能性,發人省醒。
他們強調 LLMs 生成錯誤信息的能力。例如,網絡釣魚和在線欺詐可以更快、更真實地產生,而且規模明顯擴大;LLMs 可以 “被濫用......誤導潛在的受害者相信一些犯罪分子”。
除上述犯罪活動外,ChatGPT 的能力也適合宣傳和虛假信息領域的一些潛在濫用案例。
許多人可能死亡;文明可能被徹底破壞。也許人類不會真的 “從地球上消失”,但事情確實會變得非常糟糕。
這一切的可能性有多大?我們沒有確切的答案。我說的 1% 也隻是一個思想實驗,但它不是 0。
“這並非不可想象”,Hinton 是完全正確的,我認為它既適用於 Eliezer Yudkowsky 等人所擔心的一些長期情況,也適用於 Europol 和我所擔心的一些短期情況。
真正的問題是控制。正如 Hinton 擔心的那樣,如果我們失去對可以自我改進的機器的控制會發生什麼。我不知道我們什麼時候會有這樣的機器,但我知道我們對目前的人工智能沒有足夠的控制,尤其是現在人們可以把它們與現實世界的軟件 API 連接起來。
我們需要停止擔心機器人接管世界,而是更多地考慮那些壞人可能會利用 LLMs 做什麼,以及如果有的話,我們可以做什麼來阻止他們。
然而,我們也需要將 LLMs 視為未來智能的一點 “星星之火”,並捫心自問 “我們究竟要對未來的技術做些什麼,這些技術很可能更加難以控制”。
Hinton 在接受 CBS News 采訪時說,“我認為人們現在擔心這些問題是非常合理的,盡管它不會在未來一兩年內發生”,我深表贊同。
這不是一個非此即彼的情況;目前的技術已經帶來巨大的風險,我們對此準備不足。隨著未來技術的發展,事情很可能變得更糟。批評人們關註 “錯誤的風險” 對任何人都沒有幫助;已經有足夠多的風險。
所有人都要行動起來。
暫停 6 個月?反擊開始
在 Marcus 與馬斯克等上千人聯名呼籲至少暫停大模型研究 6 個月後,業內人士有贊同,有反對。其中,反對方就包括人工智能知名學者吳恩達。
吳恩達認為,暫停研究比 GPT-4 更強大的人工智能模型是 “一個可怕的想法”。
“我看到 GPT-4 在教育、醫療、食品等方面有許多新的應用,這將幫助許多人。改進 GPT-4 將有所幫助。我們需要平衡人工智能正在創造的巨大價值與現實的風險。”
同時,吳恩達表示,除非政府介入,否則沒有現實的方法來實施暫停並阻止所有團隊擴大 LLMs 的規模。讓政府暫停他們不解的新興技術是反競爭的,這會樹立一個可怕的先例,是可怕的創新政策。
另外,負責任的人工智能很重要,人工智能也有風險。媒體普遍認為,人工智能公司正在瘋狂地生成不安全的代碼,這不是事實。絕大多數(可悲的是,不是所有)人工智能團隊都認真對待負責任的人工智能和安全。
“6 個月的暫停期並不是一個實用的建議。為促進人工智能的安全,圍繞透明度和審計的法規將更加實用,並產生更大的影響。在推動技術發展的同時,讓我們也對安全進行更多的投資,而不是扼殺進步。”
在 Hacker News 上看到這樣一句話,“你無法阻止此類研究的發生。你隻能阻止有道德的人做那種研究。我寧願讓有道德的人繼續去做這些研究。”

對此,你怎麼看?
本文為編譯文章,內容僅代表原作者觀點。