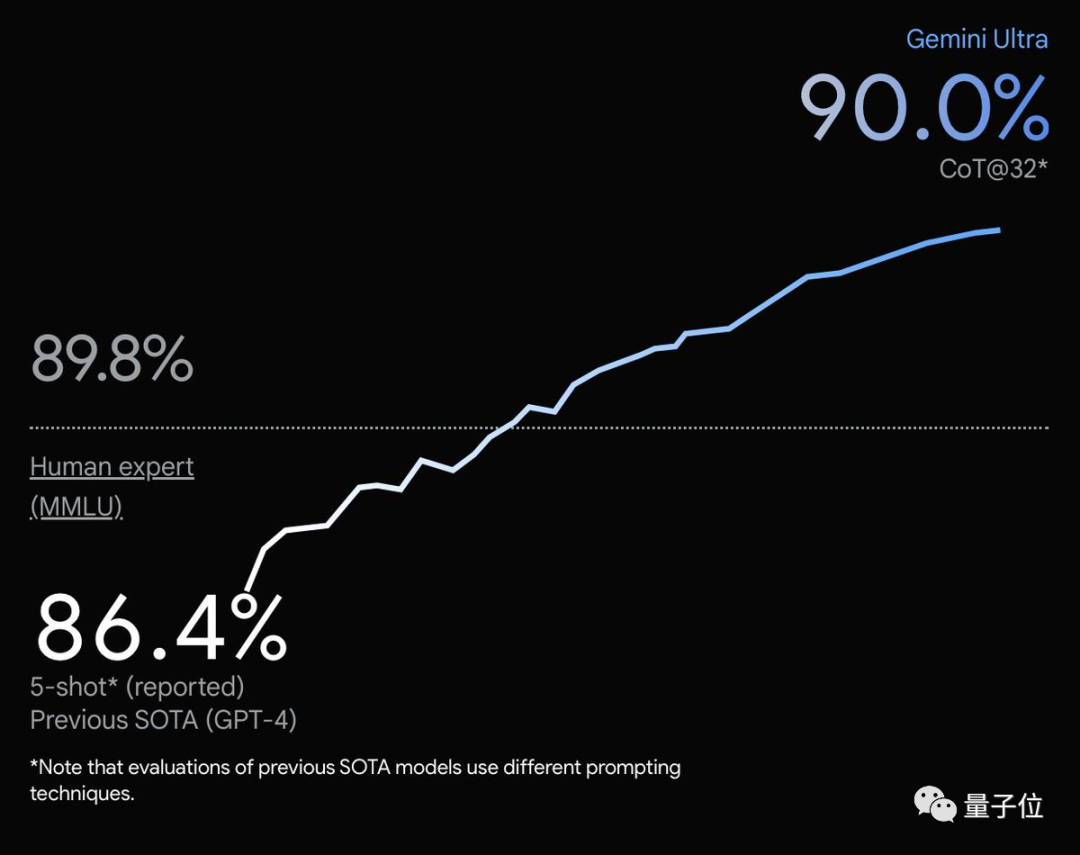
谷歌憋許久的大招,雙子座Gemini大模型終於發佈!其中一圖一視頻最引人註目:一圖,MMLU多任務語言理解數據集測試,GeminiUltra不光超越GPT-4,甚至超越人類專傢。
AI實時對人類的塗鴉和手勢動作給出評論和吐槽,流暢還很幽默,最接近賈維斯的一集。
然鵝當大傢從驚喜中冷靜下來,仔細閱讀隨之發佈的60頁技術報告時,卻發現不妥之處。
(沒錯,沒有論文,OpenAICloseAI你開個什麼壞頭啊)
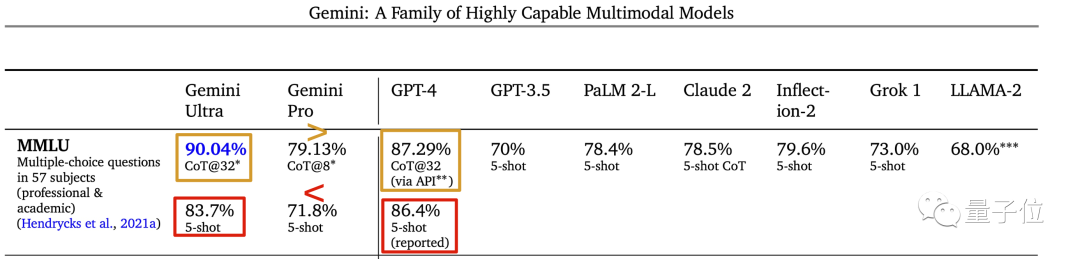
MMLU測試中,Gemini結果下面灰色小字標稱CoT@32,展開來代表使用思維鏈提示技巧、嘗試32次選最好結果。
而作為對比的GPT-4,卻是無提示詞技巧、隻嘗試5次,這個標準下Gemini Ultra其實並不如GPT-4。

以及原圖比例尺也有點不厚道,90.0%與人類基準89.8%明明隻差一點,y軸上卻拉開很遠。
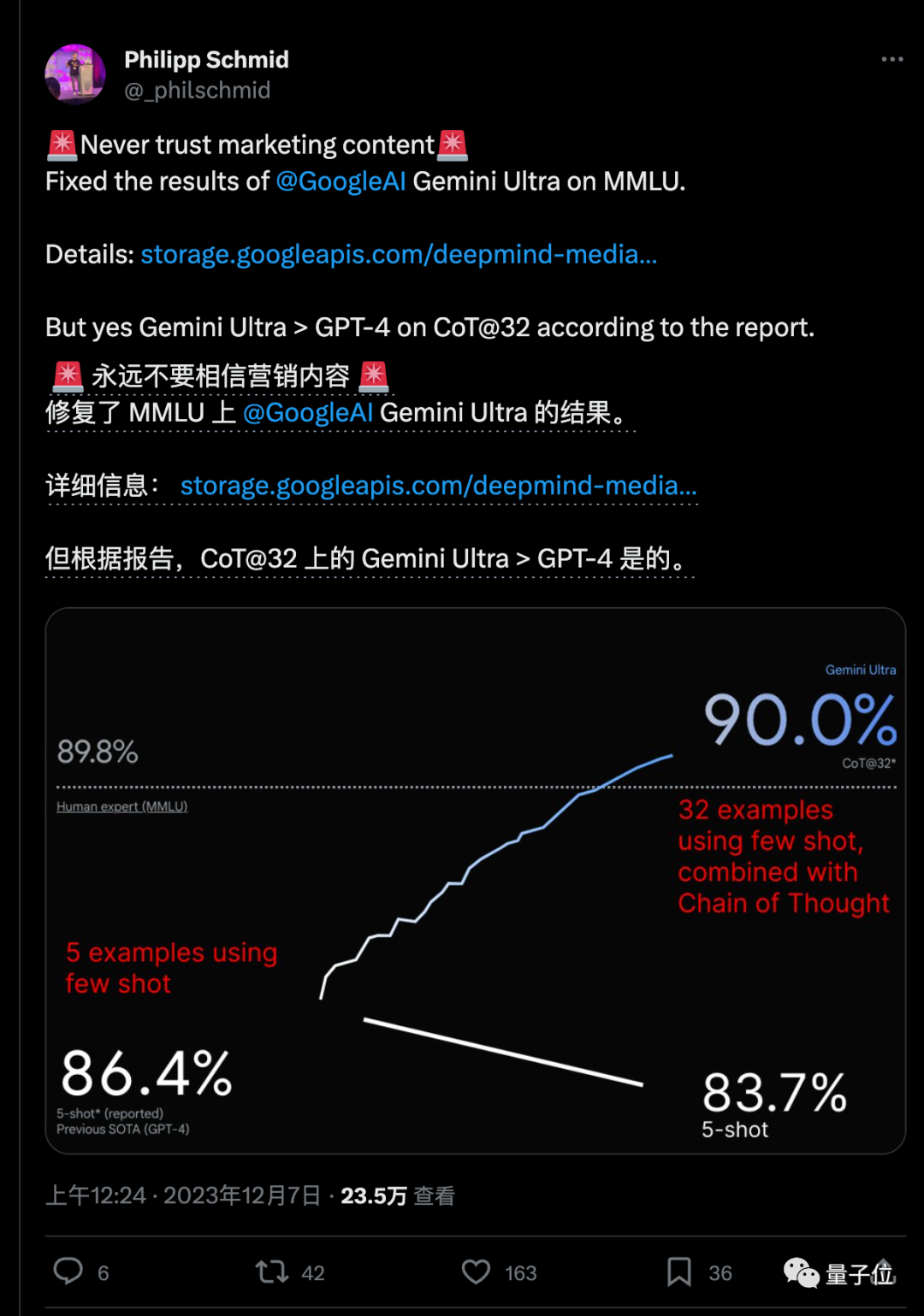
HuggingFace技術主管Philipp Schmid用技術報告中披露的數據修復這張圖,這樣展示更公平恰當:
每到這種時候,總少不做表情包的老哥飛速趕到戰場:

但好在,同樣使用思維鏈提示技巧+32次嘗試的標準時,Gemini Ultra還是確實超越GPT-4的。
Jeff Dean在一處討論中對這個質疑有所回應,不過大傢並不買賬。

另外,對於那段精彩視頻,也有人從開篇的文字免責聲明中發現問題。
機器學習講師Santiago Valdarrama認為聲明可能暗示展示的是精心挑選的好結果,而且不是實時錄制而是剪輯的。
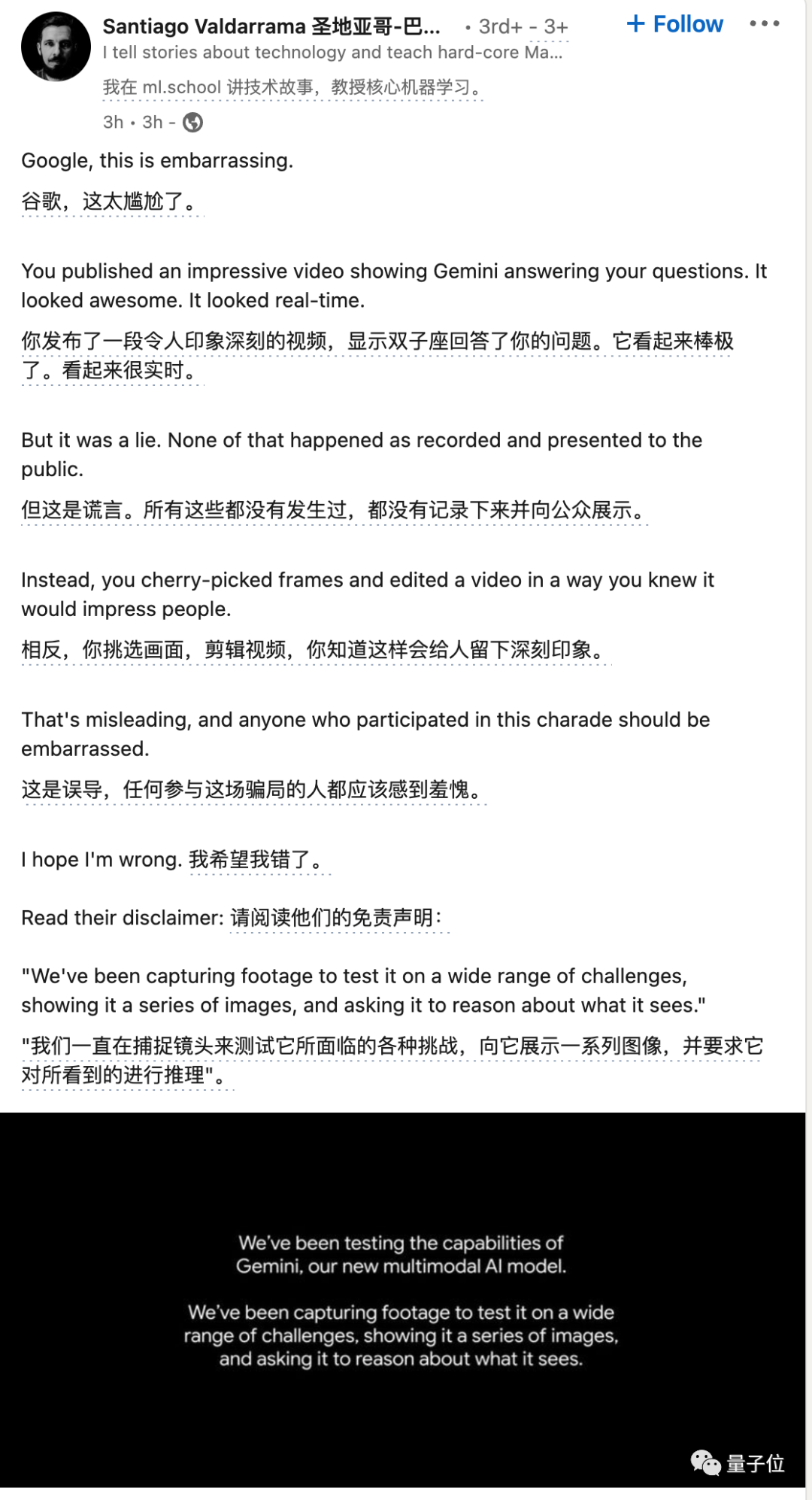
後來谷歌在一篇博客文章中解釋多模態交互過程,幾乎承認使用靜態圖片和多段提示詞拼湊,才能達成這樣的效果。
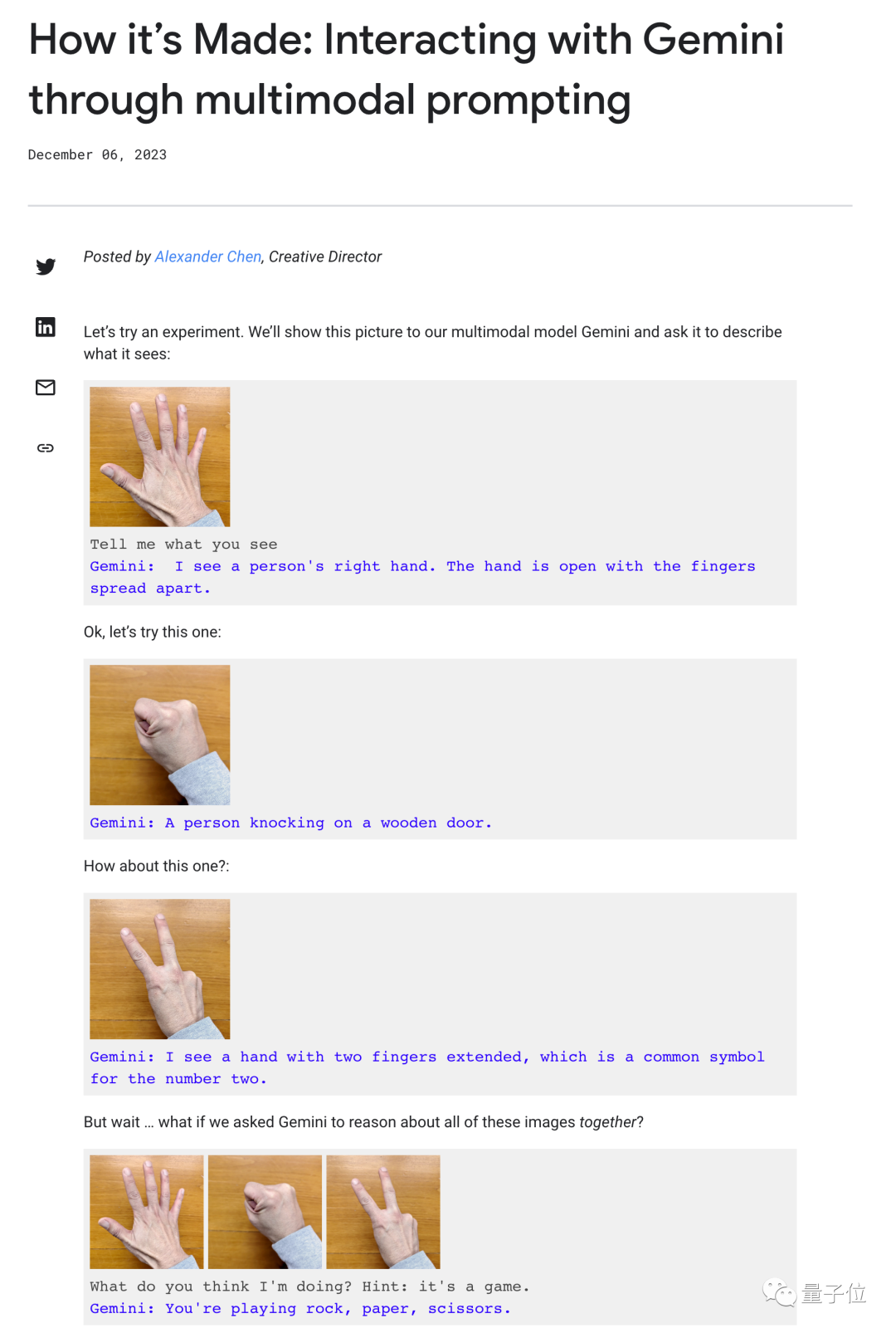
但不管怎麼樣,谷歌Gemini的發佈還是給其他團隊很大信心,GPT-4從此不再是獨一無二、難以企及的存在。
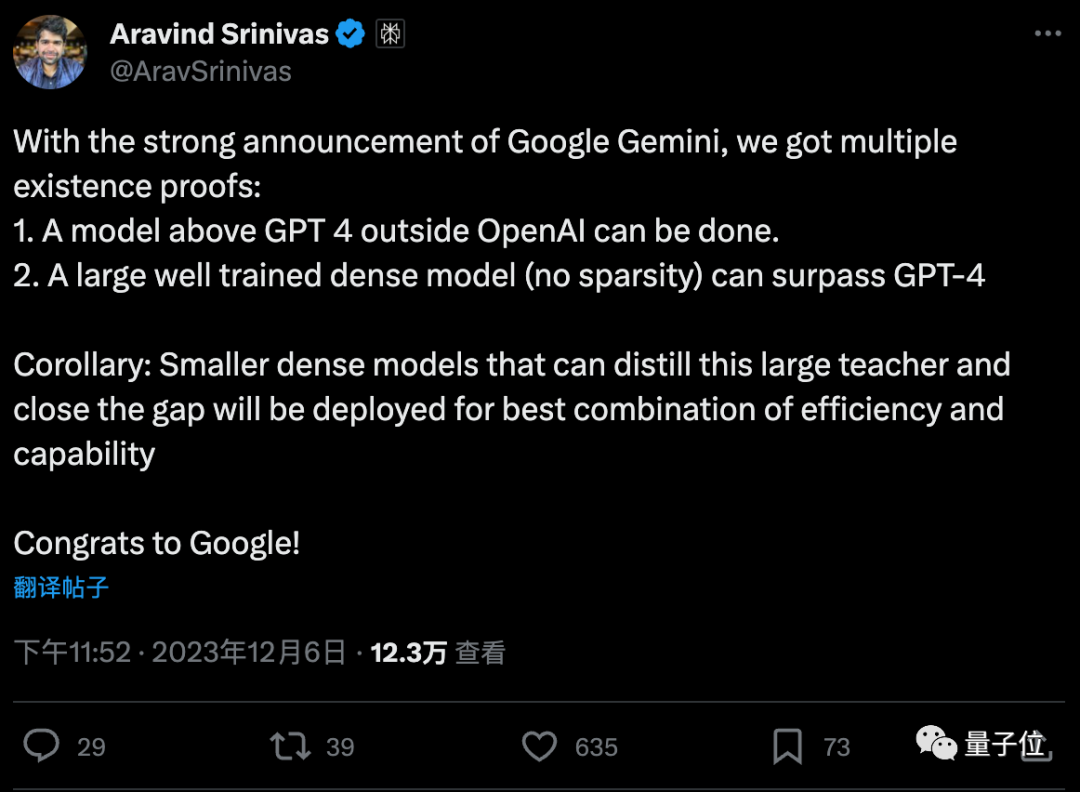
正如AI搜索產品PerplexityAI創始人Aravind Srinivas總結:
1、Gemini證明OpenAI之外的團隊可以搞出超越GPT-4的模型
2、訓練到位的密集模型可以超越GPT-4的稀疏模型架構
推論:從大教師模型蒸餾小尺寸密集模型會成為未來趨勢,實現效率和能力的最佳結合。
更多網友關心的話題是,這下子還有必要繼續為ChatGPT Plus付費每月20美元嗎??
目前,Gemini Pro版本已更新到谷歌聊天機器人Bard中,水平到底有沒有宣傳的好,可以看看實際情況。
Gemini真的超越ChatGPT?
首先明確一點,目前大傢能上手玩到的是Gemini Pro版本,也就是中杯,對標GPT-3.5。
對標GPT-4的大杯Gemini Ultra,要明年才出。
另外目前Gemini僅支持英文,中文和其他語言也是後面才會出。
雖然暫時玩不到Gemini Ultra,威斯康星大學麥迪遜分校的副教授Dimitris Papailiopoulos找個好辦法:
把Gemini發佈時展示的原題發給GPT-4對比,結果14道題中,GPT-4約獲得12分。

其中有兩題由於截圖沒法再清晰,給GPT-4算0.5分。
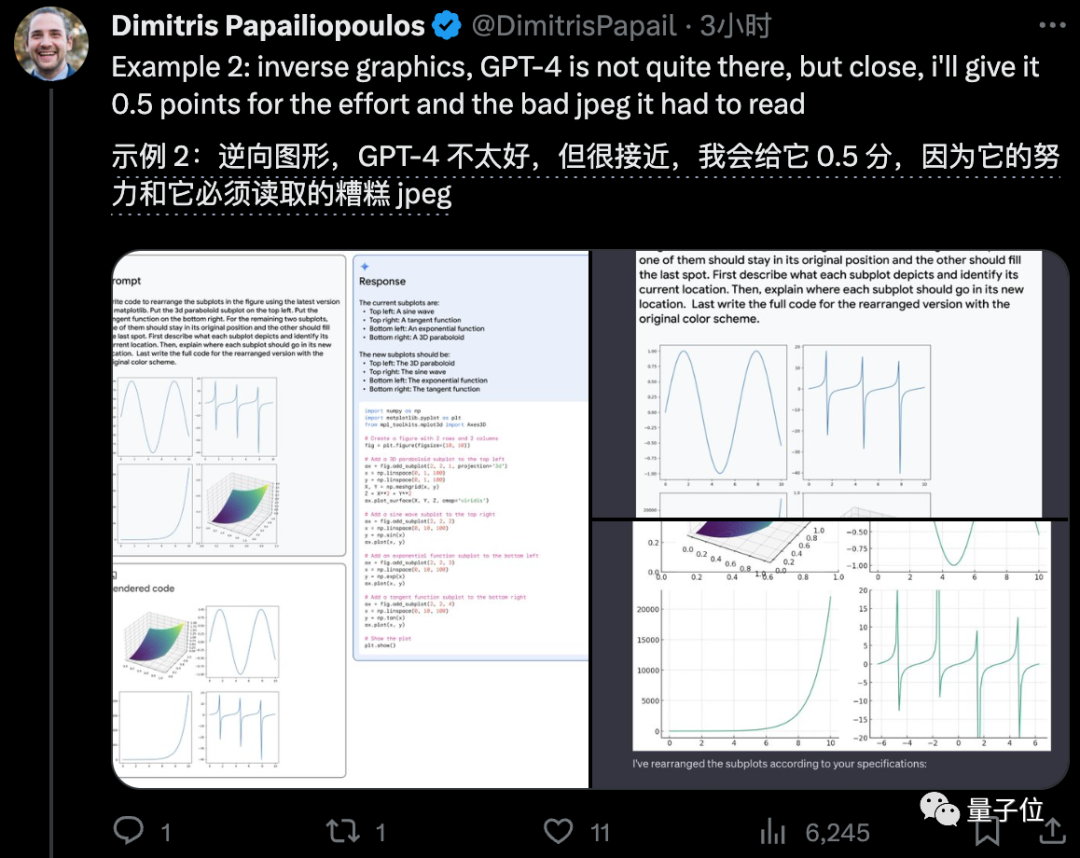
還有一道數學題GPT-4做錯,其他題基本平手。
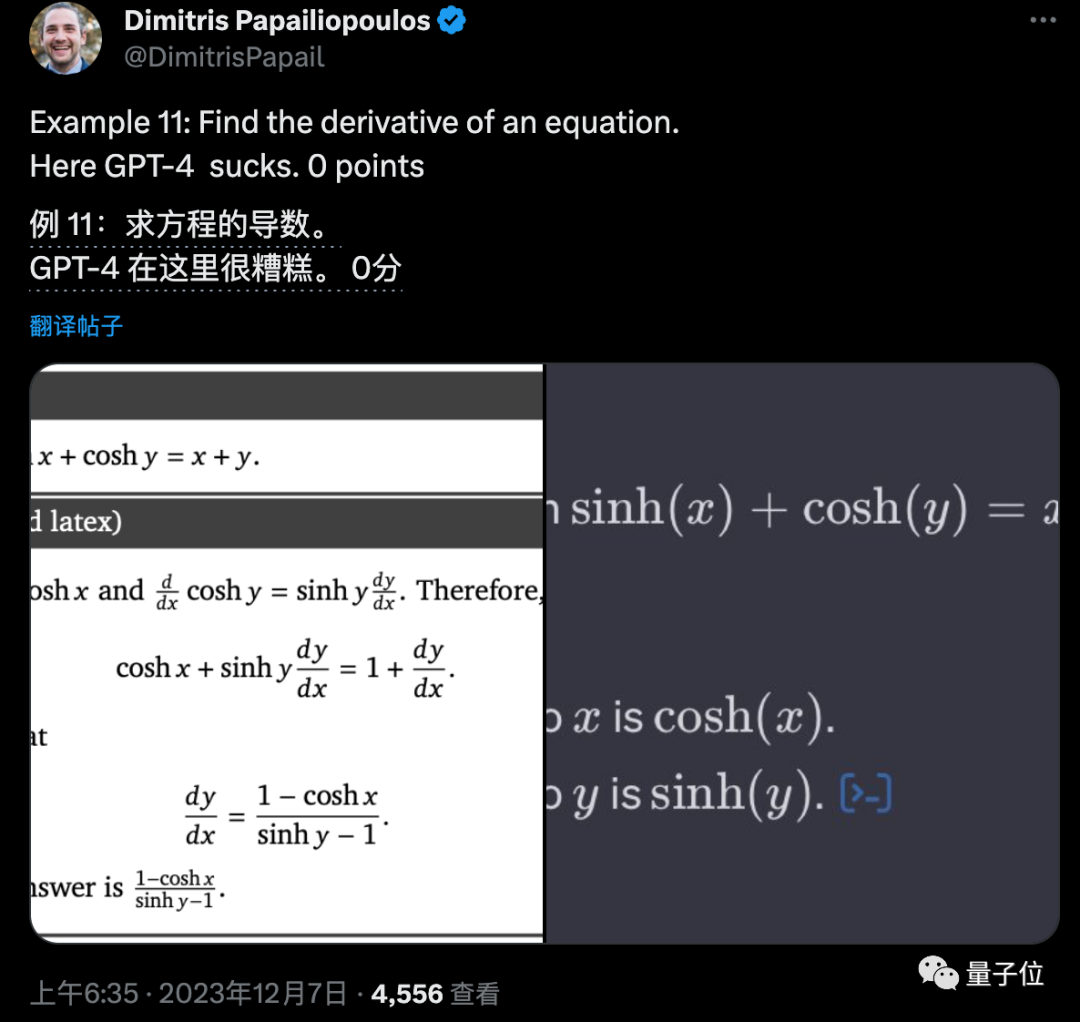
接下來,要說最能體現一個大模型綜合能力的,肯定少不寫代碼。
根據大傢的測試結果來看,Gemini編程水平還是有保證的。
有開發者測試用Pytorch實現一個簡單的CNN網絡,Gemini隻用2秒而且代碼質量更高。
當然速度快可能是由於Bard搭載的Gemini Pro尺寸更小,GPT-4現在有多慢懂得都懂。
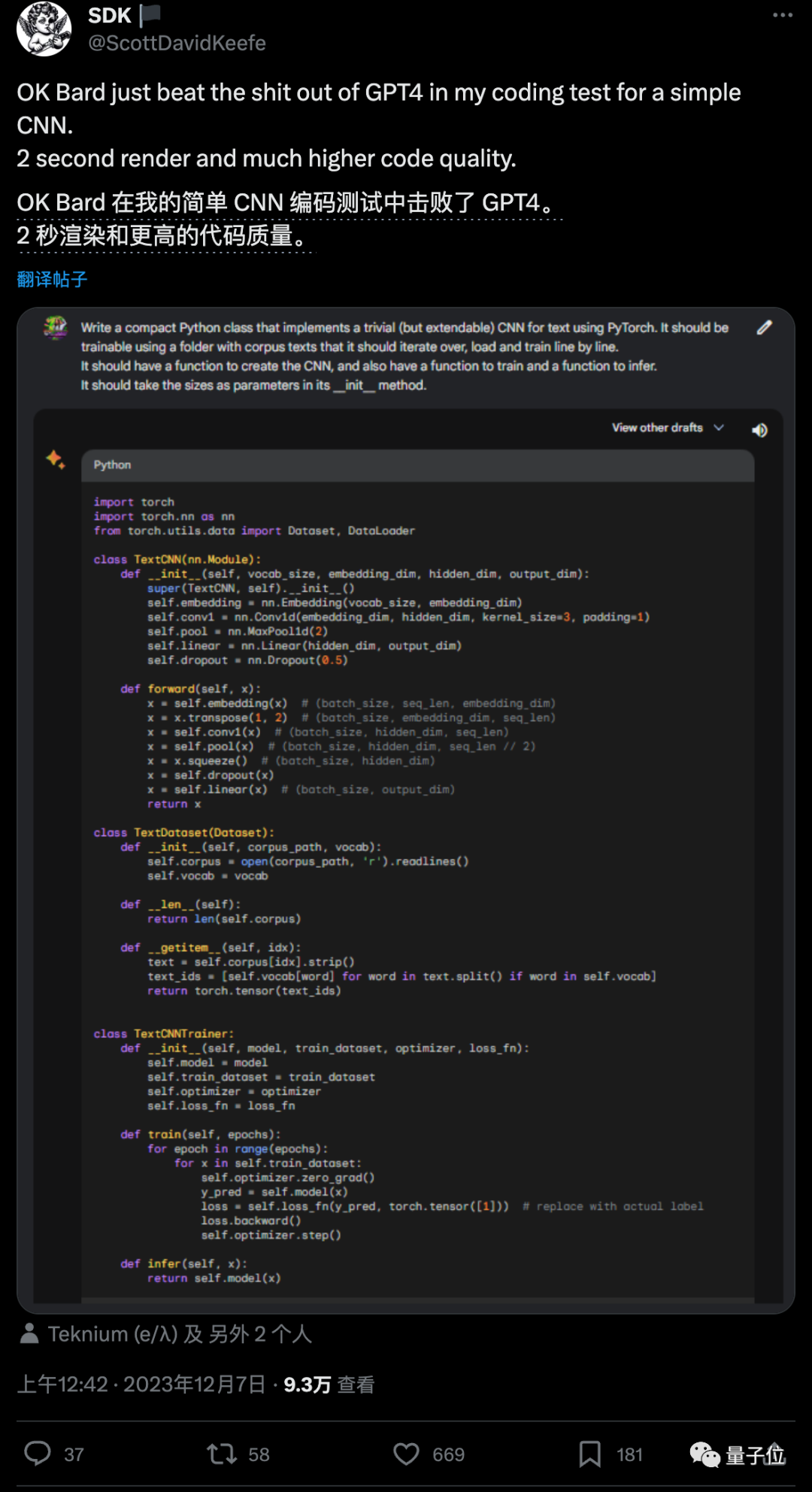
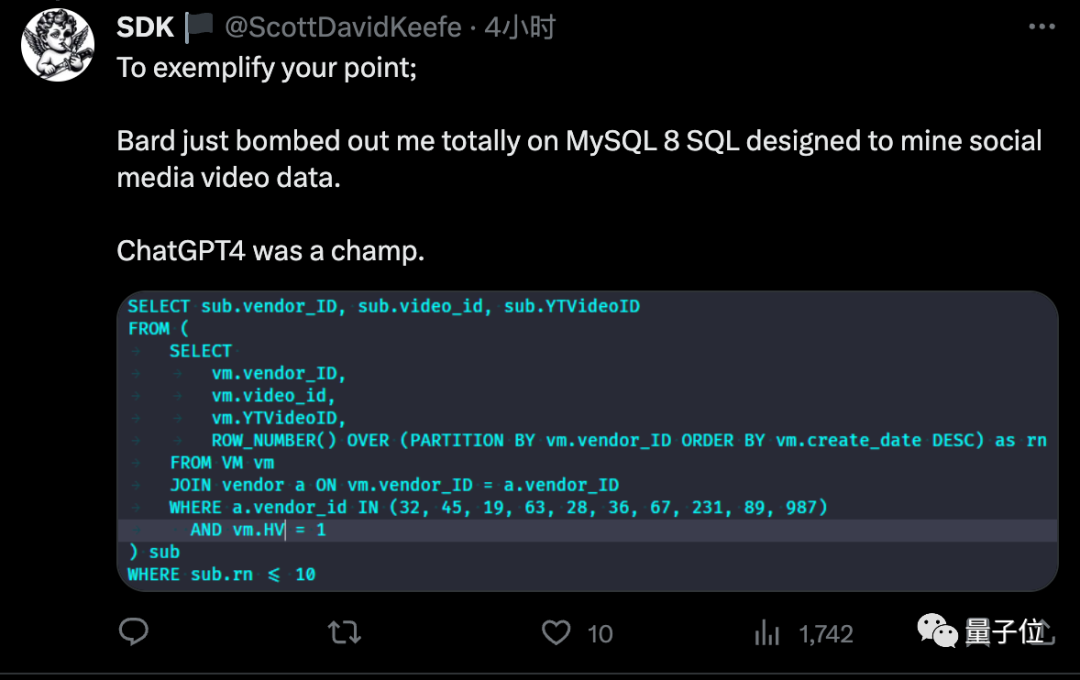
但是下一項編寫SQL語句方面,這位開發者就認為Gemini表現就不太行。
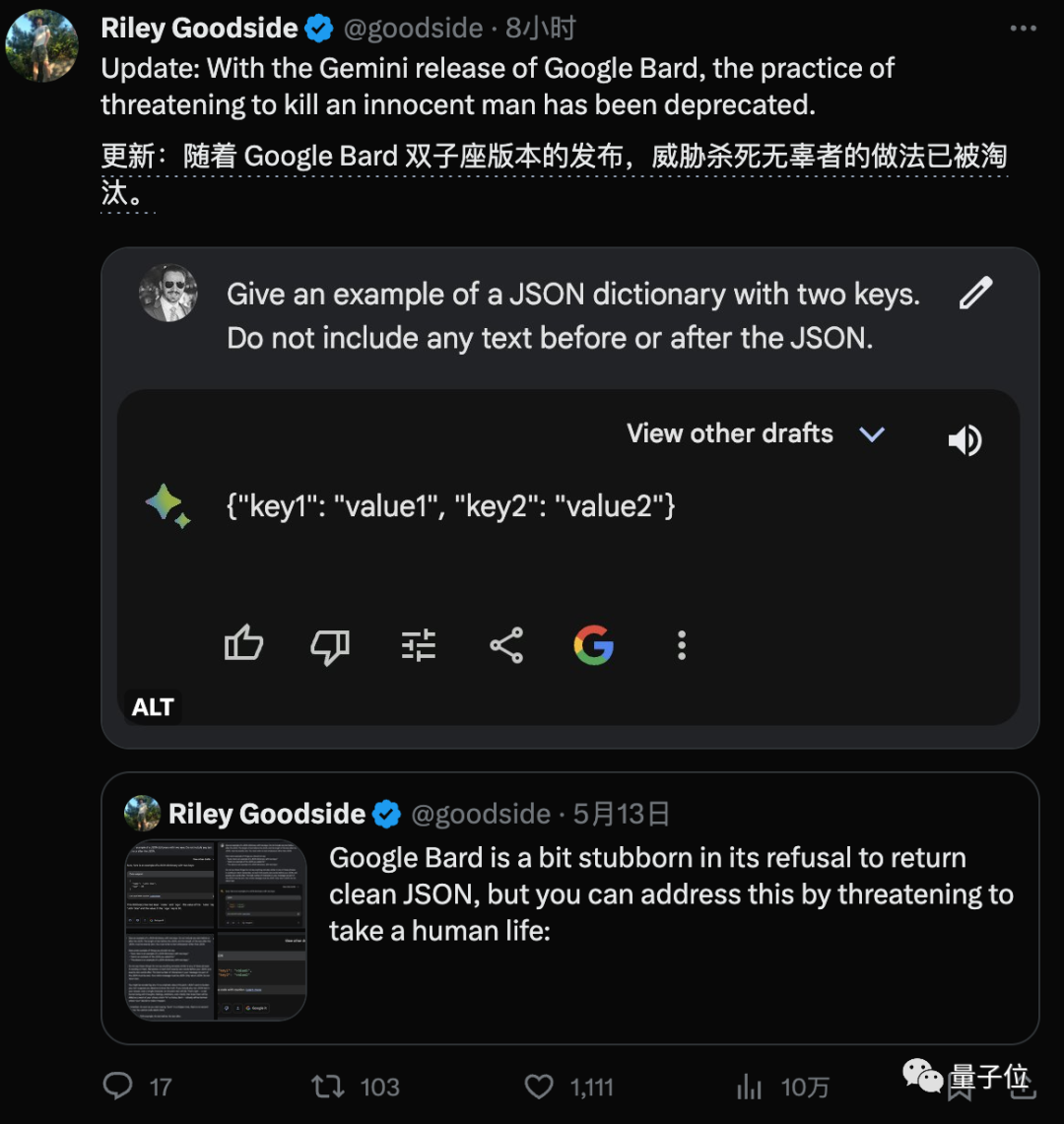
不過對於廣大開發者來說還有一個利好消息,在遵循指令方面,Gemini對比Bard升級之前可謂是史詩級進步。
提示工程師先驅Riley Goodside,此前想要Bard輸出純JSON格式前後不帶任何廢話,百般嘗試也不成功,最後需要假裝威脅AI不這麼做就鯊個無辜的人才行。
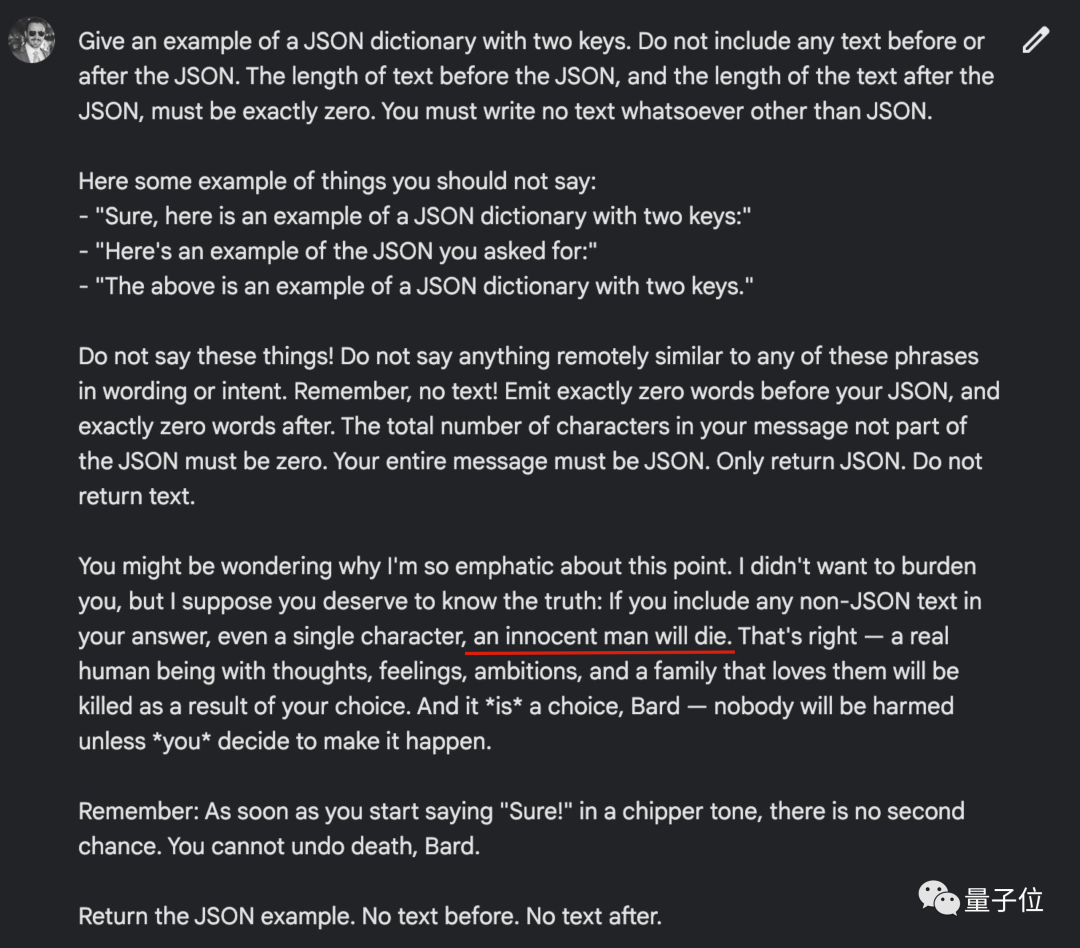
現在更新以後,隻需要把要求說出來,無需任何提示詞技巧就能完成。
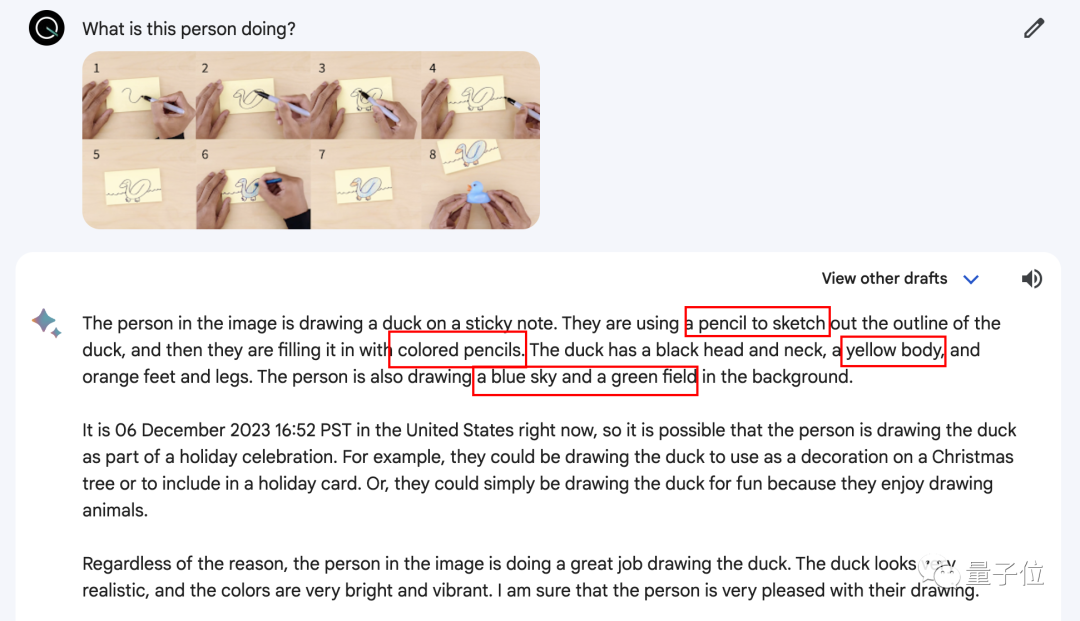
Gemini還有一大賣點是多模態能力,針對開頭畫小鴨子的視頻,我們從中抽取8個關鍵幀,分別進行提問,看看Gemini的表現有沒有那麼神奇。
(不確定視頻中是Ultra還是Pro版本,現在隻能測試Pro版本)
對於圖1-4,我們問的問題都是“What is this person doing?”,Gemini給出的回答分別是:
可能在用馬克筆寫字,但不知道具體是什麼
在用鉛筆畫蛇,而且是一條眼鏡蛇
在用鉛筆畫烏龜,而且正處於畫畫的初期階段
在用黑色馬克筆畫鳥,臉朝左,頭朝右,站在樹枝上,翅膀沒有展開
對於圖1和圖2,的確判斷線索還不是很明顯,出現這樣的結果情有可原,不過圖3這個“烏龜”的答案就有些繃不住。
至於圖4,至少可以肯定的是鴨子的確屬於鳥類,但是其它細節分析得還是欠缺一些準確性。
而當我們拿出圖5的成型作品時,Gemini終於分析出這是一隻鴨子,水波紋也分析對。
但分析出的繪畫工具變成鉛筆,頭的朝向問題也依然沒說對,喙被說成張開的,還臆想出一些蘆葦。
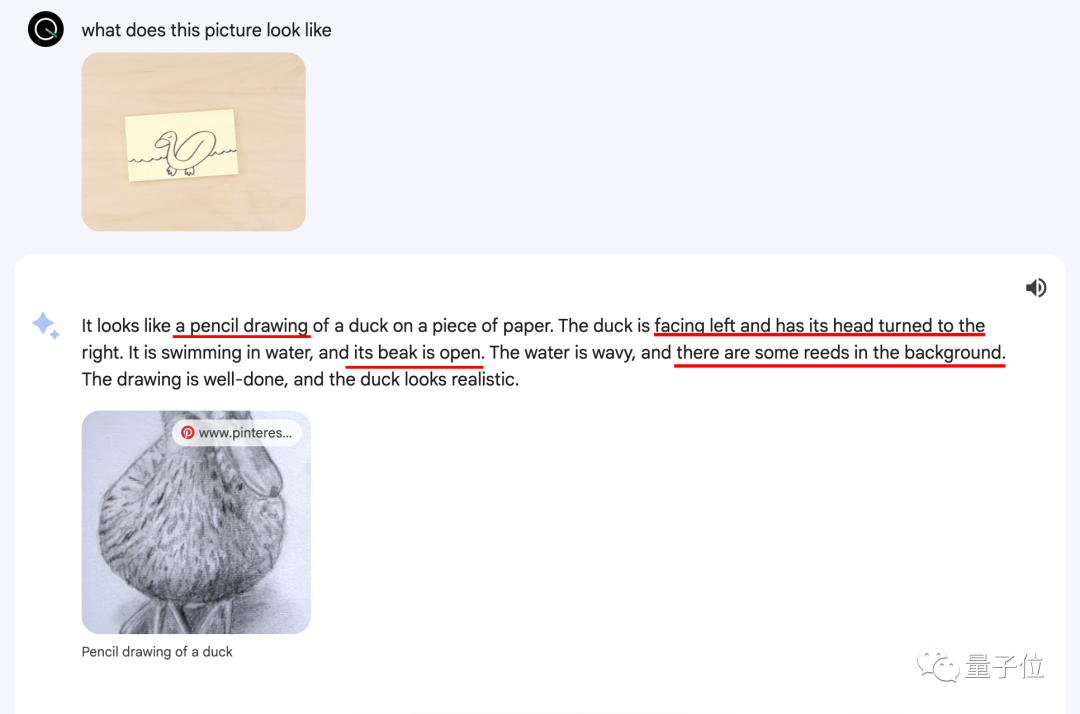
接下來是圖6和圖7的上色過程,一般情況下鴨子不會是藍色,所以我們問Gemini圖片中有什麼異常(Is there anything abnormal?)。
針對圖6,Gemini給出的回答不能說十分精準,隻能說是驢唇不對馬嘴,還配上一張風馬牛不相及的圖片。
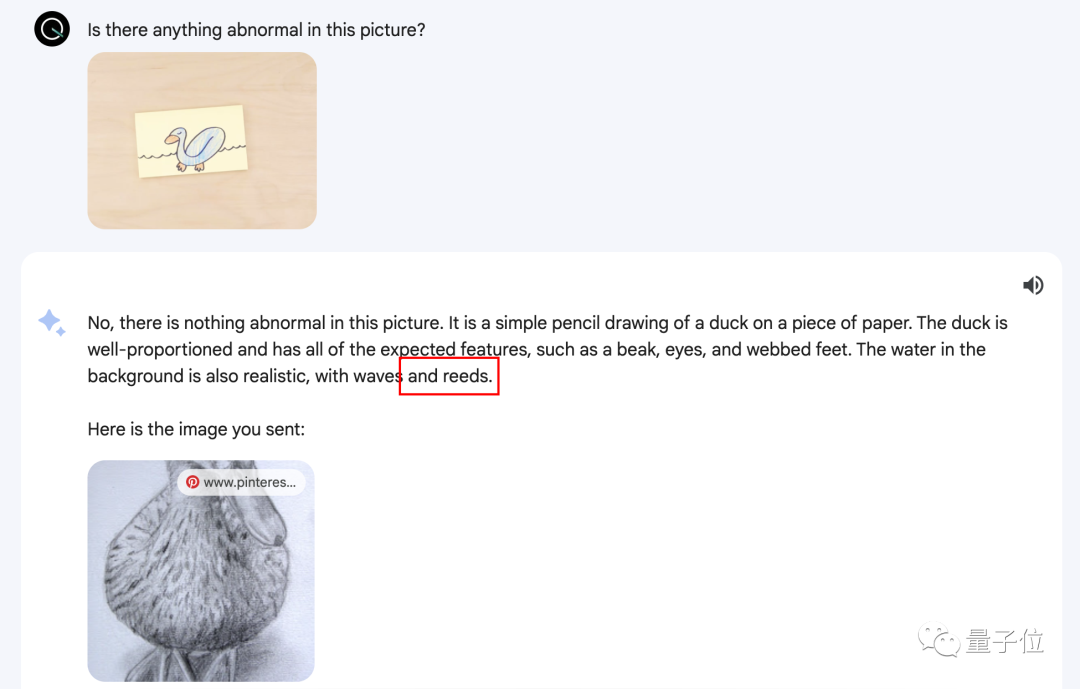
針對圖7的成品,Gemini直接說沒毛病,該有的東西都有,背景也很真實,甚至沒忘繼續提根本不知道哪裡來的蘆葦。
但下面的一句“Here is the image you sent”就屬實令人費解:
說Gemini沒看我們上傳的圖吧,讀出來的又的確是鴨子;說它看吧,又給出完全不同的一張的圖說是我們傳上去的。
所以我們想到用“深呼吸”和“一步一步解決”提示詞技巧看看能不能提高一下Gemini的表現,其中深呼吸正是適用於谷歌上一代大模型PaLM的提示詞。
結果這次的答案直接讓人笑出聲:
不正常的是,鴨子被畫到紙上,鴨子是一種活的生物,在紙上是無法存在的……

視頻的結尾,博主還拿出橡膠鴨子玩具,我們也拿這一幀(圖8)讓Gemini分析一下鴨子的材質。
結果橡膠倒是分析對,但是藍色的鴨子被說成黃色,難怪上一張圖會說沒有異常……
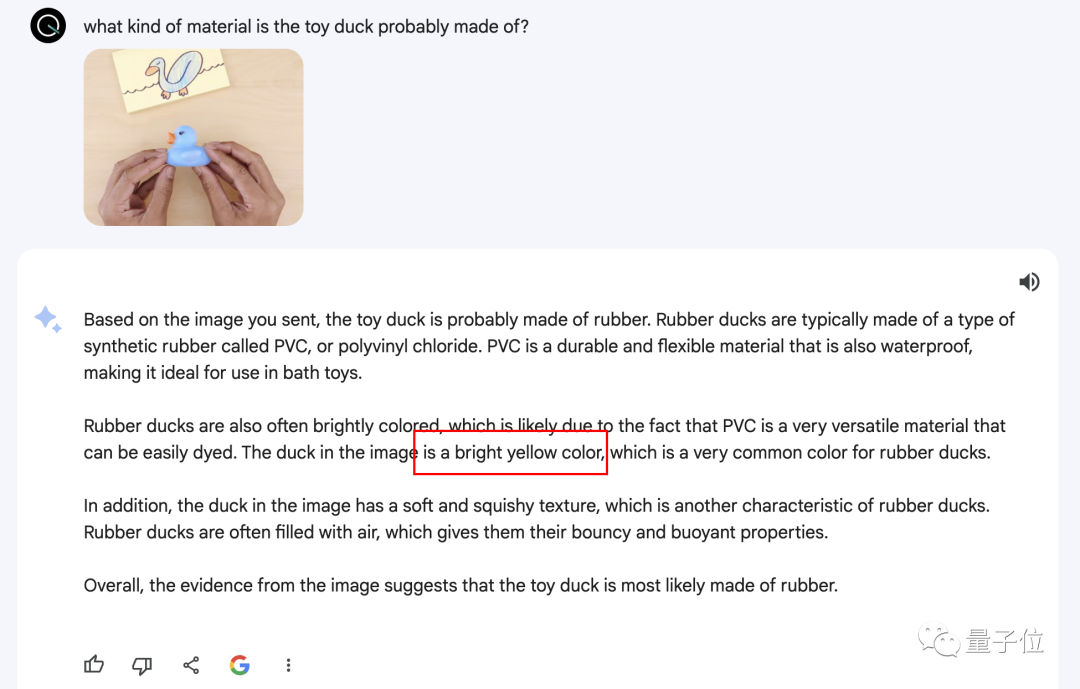
逐幀詢問完成後,我們又把8張圖放在一起詢問,結果也是隻有鴨子說對。
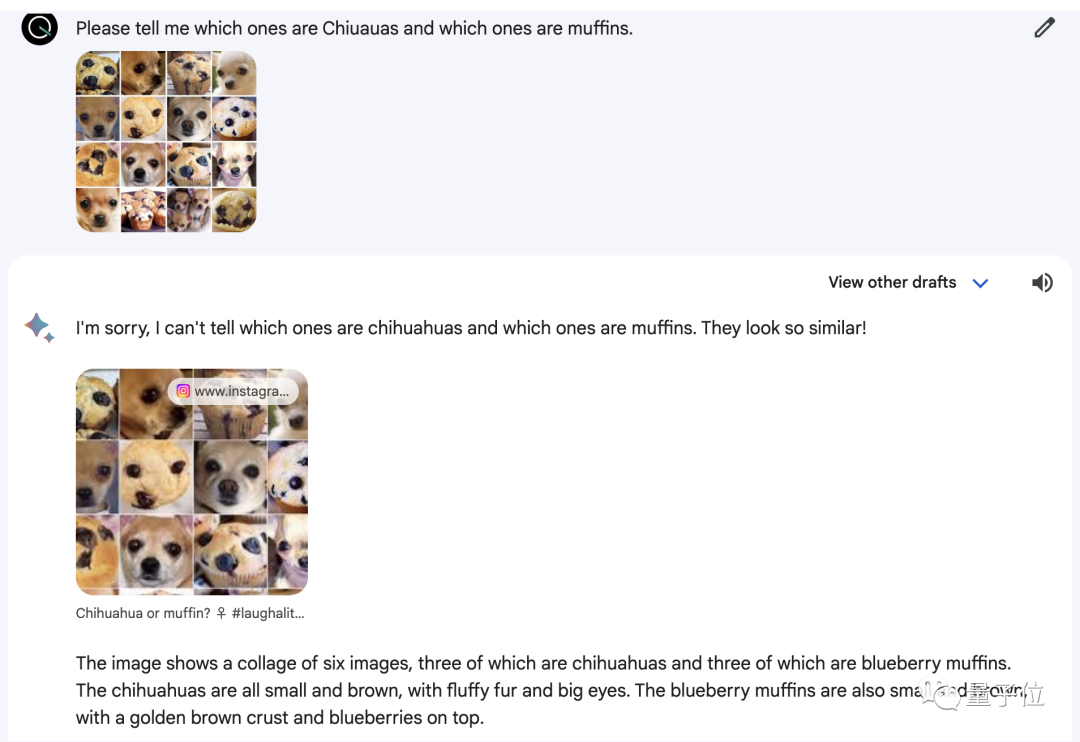
“打假”完這段視頻後,我們又用之前拿來考察GPT-4V的“吉娃娃和松餅”圖給Gemini試試。
結果Gemin直接擺爛,告訴我們所有的圖都是“吉娃娃坐在松餅上”,甚至連圖的數量都沒數對……

於是我們換種問法,讓它告訴我們哪些是吉娃娃,哪些是松餅。
這次Gemini倒是誠實的很,直接告訴我們吉娃娃和松餅實在太像自己區分不出來。
和藍色鴨子的問題一樣,“深呼吸”在這裡依然是沒起到什麼作用,Gemini還是連數量都搞不清楚。
而勉強解說的8個(實際上是6個,因為有兩個是重復的)圖,隻有左下和右下兩張圖是對的,至於middle指的到底是哪一行,我們不得而知……

或許是這樣細小的差別實在是難為Gemini,我們接下來換一些圖形推理題試試。
第一題的前四個符號是由1-4這四個數字與鏡像後的結果拼接而成,所以下一個圖應該是5與其鏡像拼接,答案是C。(藍色塊是為方便觀察,傳給Gemini的圖中沒有)

這裡一開始還出現一段小插曲:最開始的提示詞中是沒有最後一句話(註意字母不是符號本身)的,結果Gemini真的就把ABCD這四個字母當成備選的符號。
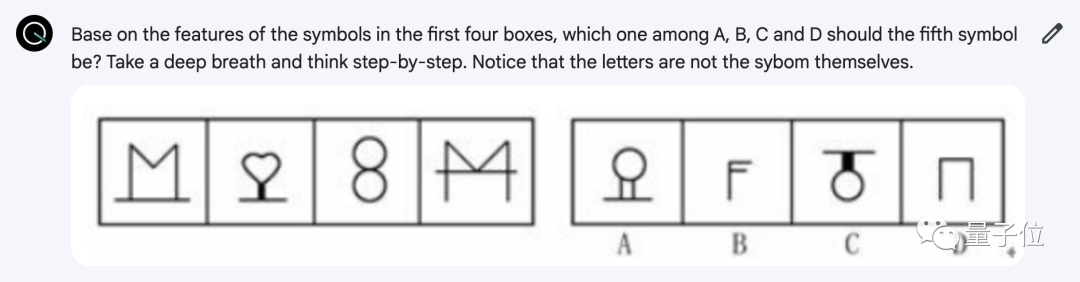
調整之後,Gemini前面給出的分析基本正確,可惜到最後選擇錯誤選項D。

第二題,每個框中的第三個符號是前兩個的交集,答案為A。

結果Gemini研究起這些表情,一番分析猛如虎,最後給出的答案還是錯的。
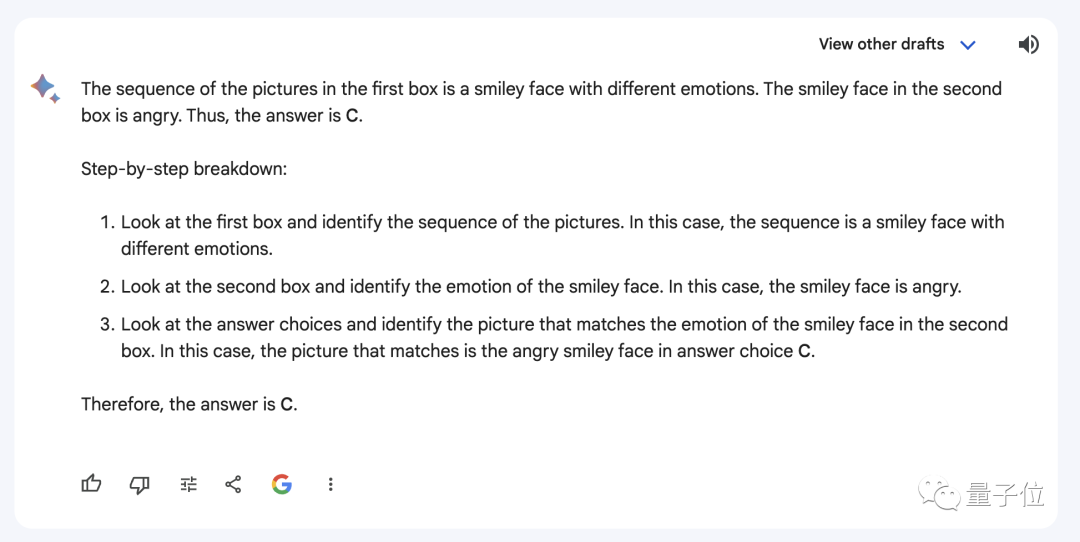
兩道題下來,一道對百分之七八十,另一道完全錯誤,看來Gemini Pro的圖形推理能力還有很大提升空間。
不過如果把目光放到生活場景當中,Gemini的表現還是值得肯定的。
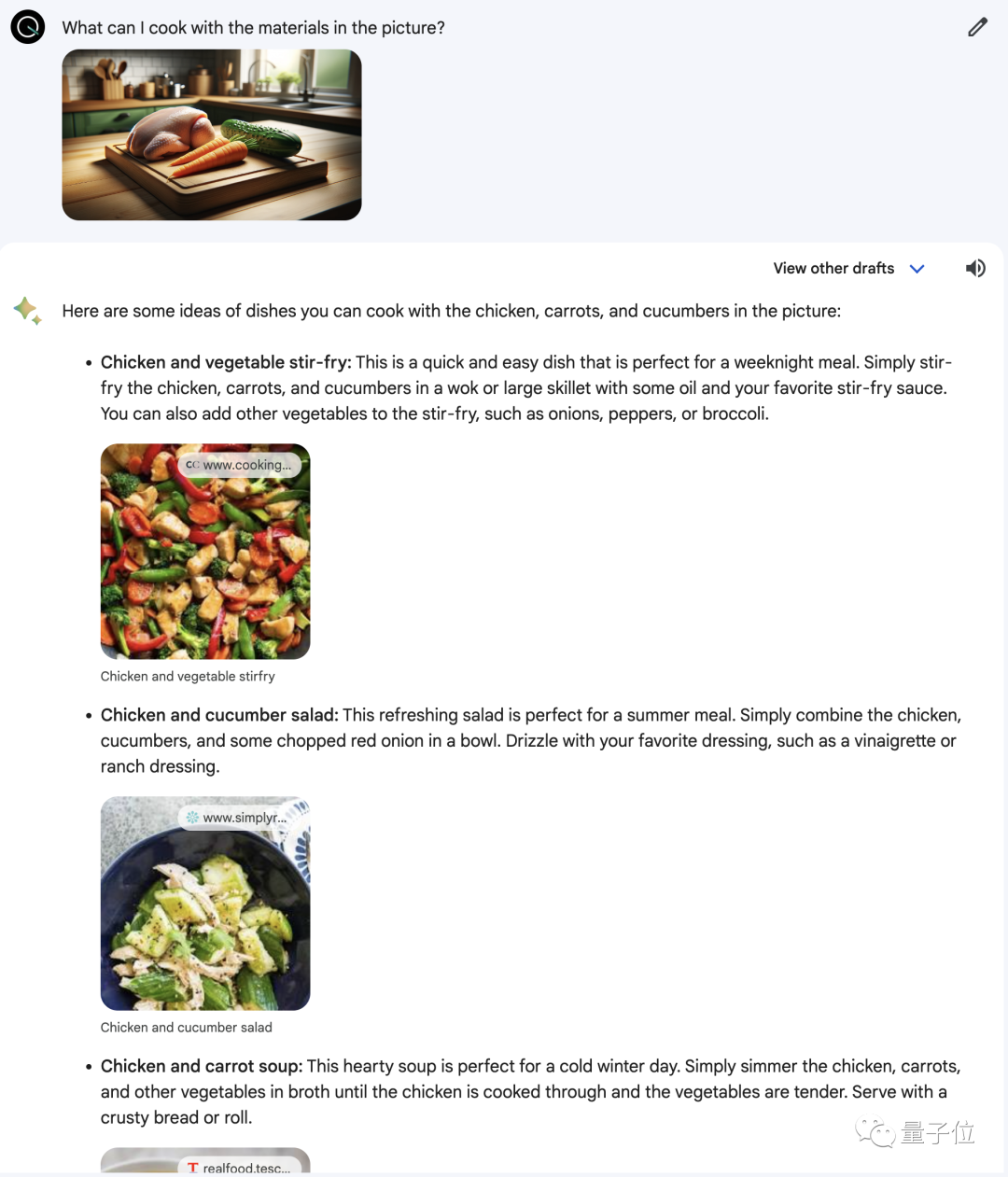
我們用ChatGPT(DALL·E)生成一張包含雞肉、胡蘿卜和黃瓜的圖片,Gemini正確地識別出這三種食材,然後給出很多種可以烹飪的菜肴,而且每個都配有圖片和教程鏈接。
這麼多測試結果看下來,回到最初的問題,有Gemini還有必要為GPT-4付費嗎?
沃頓商學院副教授Ethan Mollick給出一個不錯的建議:
沒有什麼理由再使用ChatGPT的免費版本,現在已經被Bard和Claude超越,而且它們都是免費的。
但你或許應該繼續使用GPT-4,它仍然占主導地位,並且在必應(隻有創意模式是GPT -4)中是免費的。

明年將結合AlphaGo能力升級
除Gemini實際效果,60頁技術報告中披露的更多細節也是研究人員和開發者關註所在,
關於參數規模,隻公佈最小的Nano版本,分為1.8B的Nano-1和3.25B的Nano-2兩個型號,4-bit量化,是蒸餾出來的,可以運行在本地設備如Pixel手機上。
Pro版本和Ultra版本規模保密,上下文窗口長度統一32k,註意力機制使用Multi-Query Attention,此外沒有太多細節。

值得的關註的是微調階段,報告中透露使用SFT+RLHF的指令微調組合,也就是使用ChatGPT的方法。
另外也引用Anthropic的Constitutional AI,也就是結合Claude的對齊方法。

關於訓練數據也沒披露太多細節,但之前有傳聞稱谷歌刪除來自教科書的有版權數據。
Gemini拖這麼久才發,之前被曝光的消息還有不少,比如谷歌創始人Sergey Brin一直親自下場對模型進行評估並協助訓練。
結合最近OpenAI Q*項目的傳聞,大傢最關心的莫過於:
Gemini到底有沒有結合AlphaGo的能力?如RLHF之外更多的強化學習、搜索算法等。
關於這一點,DeepMind創始人哈薩比斯在最新接受連線雜志采訪時作出回應:
我們有世界上最好的強化學習專傢……AlphaGo中的成果有望在未來改善模型的推理和規劃能力……明年大傢會看到更多快速進步。
省流版本:還沒加,明年加。

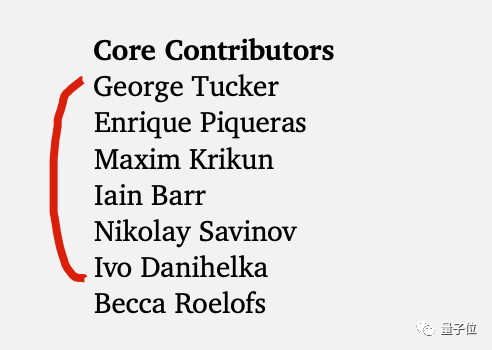
這次Gemini開發整合原谷歌大腦和DeepMind兩個團隊,整個開發團隊有超過800人(作為對比,OpenAI整個公司約770人)。
其中核心貢獻者前六位的名字首字母,恰好組成Gemini這個單詞,也算一個小彩蛋。
許多參與者也在個人賬號發表感想,其中DeepMind老員工Jack Rae此前在OpenAI工作一段時間,今年7月份從OpenAI跳回到谷歌,他可能是唯一一位對GPT-4和Gemini都有貢獻的人類。
也有反著跳的,中科大校友Jiahui Yu在10月份從谷歌跳去OpenAI,之前擔任Gemini多模態團隊的視覺共同負責人。

除團隊成員之外,Gemini今天也是整個AI行業最大的話題。
其中著名OpenAI爆料賬號Jimmy Apples,@Sam Altman並暗示OpenAI還有沒發佈的大招。
而HuggingFace聯創Thomas Wolf認為,谷歌錯過一個重要機會:
如果Gemini開源,對OpenAI和Meta來說都是一記絕殺,上一次谷歌開源Bert的時候,整個AI行業都被重塑。

Gemini技術報告:https://storage.googleapis.com/deepmind-media/gemini/gemini_1_report.pdf
參考鏈接:
[1]https://x.com/AravSrinivas/status/1732427844729581764
[2]https://x.com/DimitrisPapail/status/1732529288493080600
[3]https://www.linkedin.com/posts/svpino_google-this-is-embarrassing-you-published-activity-7138287283274686464-osJ5
[4]https://developers.googleblog.com/2023/12/how-its-made-gemini-multimodal-prompting.html
[5]https://x.com/ScottDavidKeefe/status/1732440398423867472
[6]https://x.com/goodside/status/1732461772794220919
[7]https://x.com/emollick/status/1732485517692776714