開源領域大模型,迎來重磅新玩傢。Google推出全新的開源模型系列“Gemma”。相比Gemini,Gemma更加輕量,同時保持免費可用,模型權重也一並開源,且允許商用。

Gemma 官方頁面:https://ai.google.dev/gemma/
本次發佈包含兩種權重規模的模型:Gemma 2B 和 Gemma 7B。每種規模都有預訓練和指令微調版本。想使用的人可以通過 Kaggle、Google的 Colab Notebook 或通過 Google Cloud 訪問。
當然,Gemma 也第一時間上線 HuggingFace 和 HuggingChat,每個人都能試一下它的生成能力:
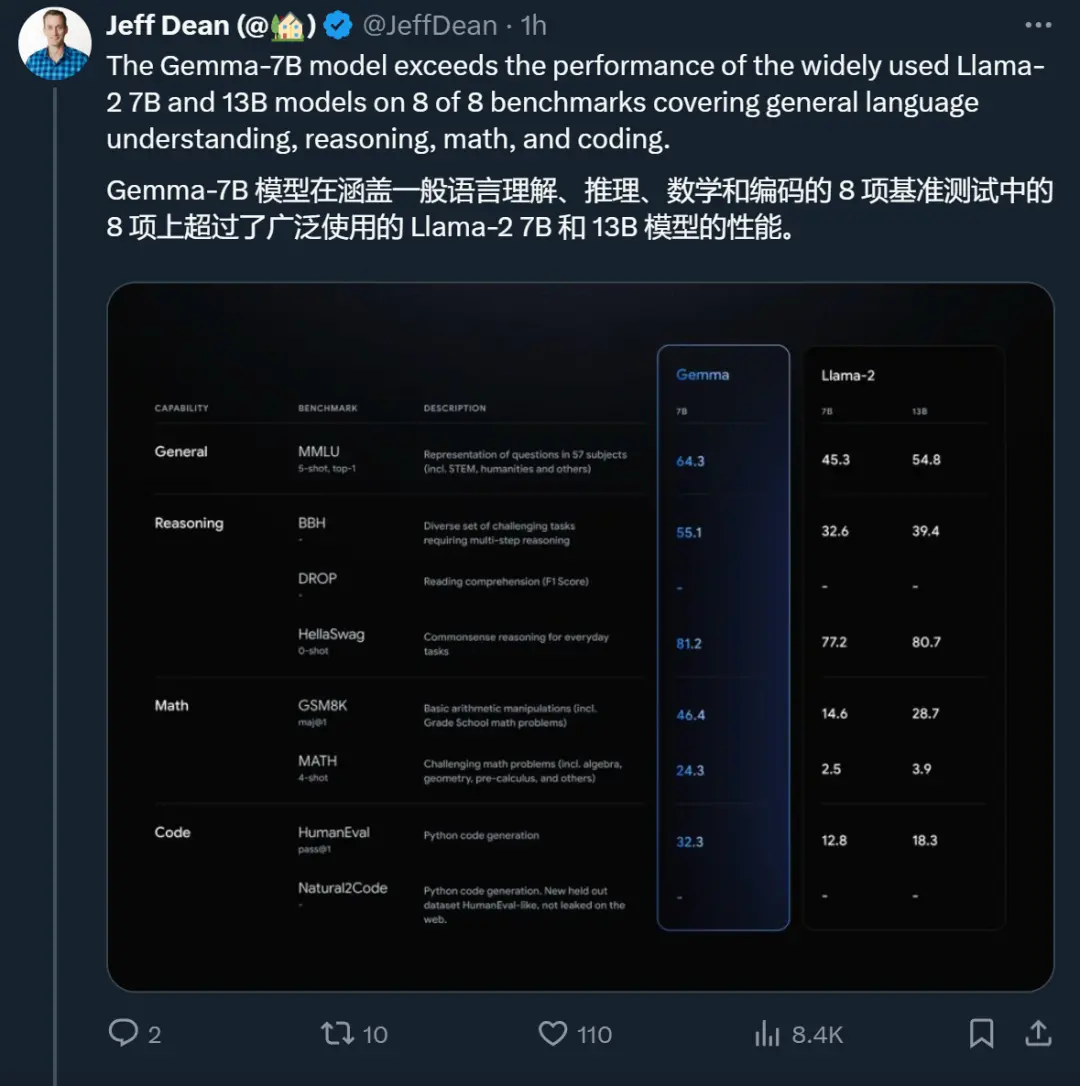
盡管體量較小,但Google表示 Gemma 模型已經“在關鍵基準測試中明顯超越更大的模型”,對比的包括 Llama-2 7B 和 13B,以及風頭正勁的 Mistral 7B。
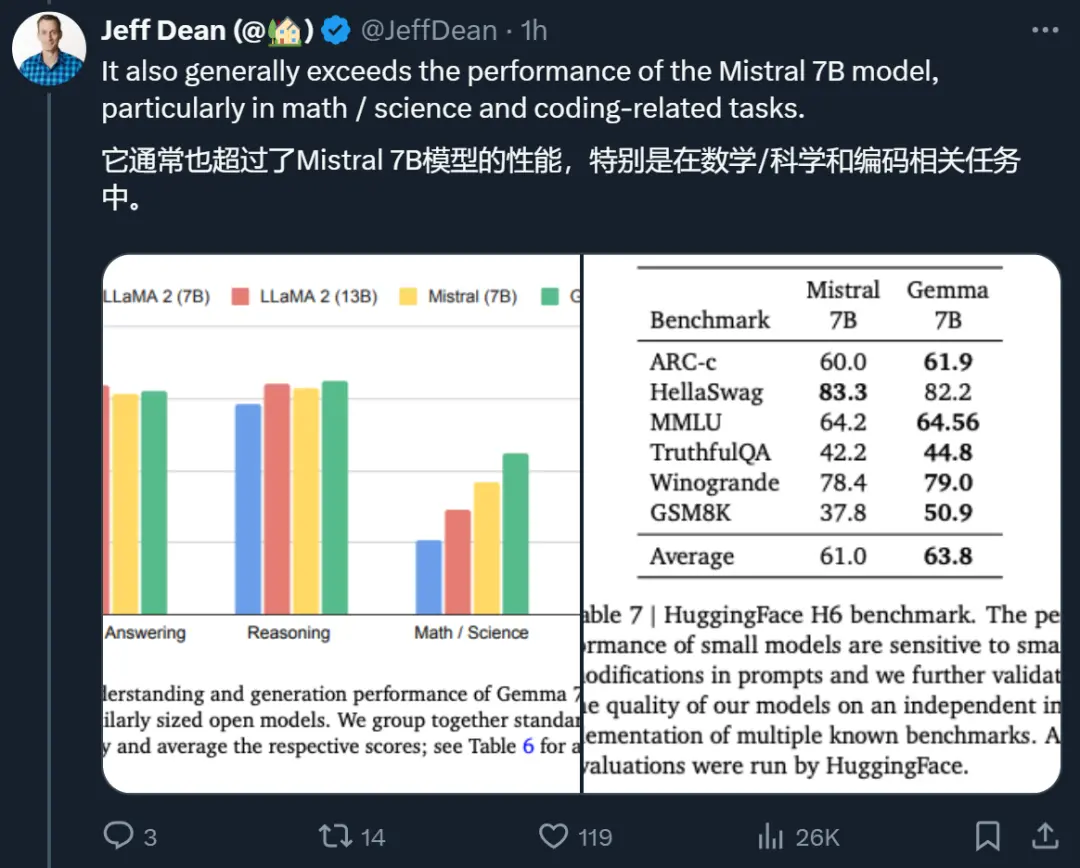
而且 Gemma“能夠直接在開發人員的筆記本電腦或臺式電腦上運行”。除輕量級模型之外,Google還推出鼓勵協作的工具以及負責任地使用這些模型的指南。
Keras 作者 François Chollet 對此直接表示:最強開源大模型的位置現在易主。
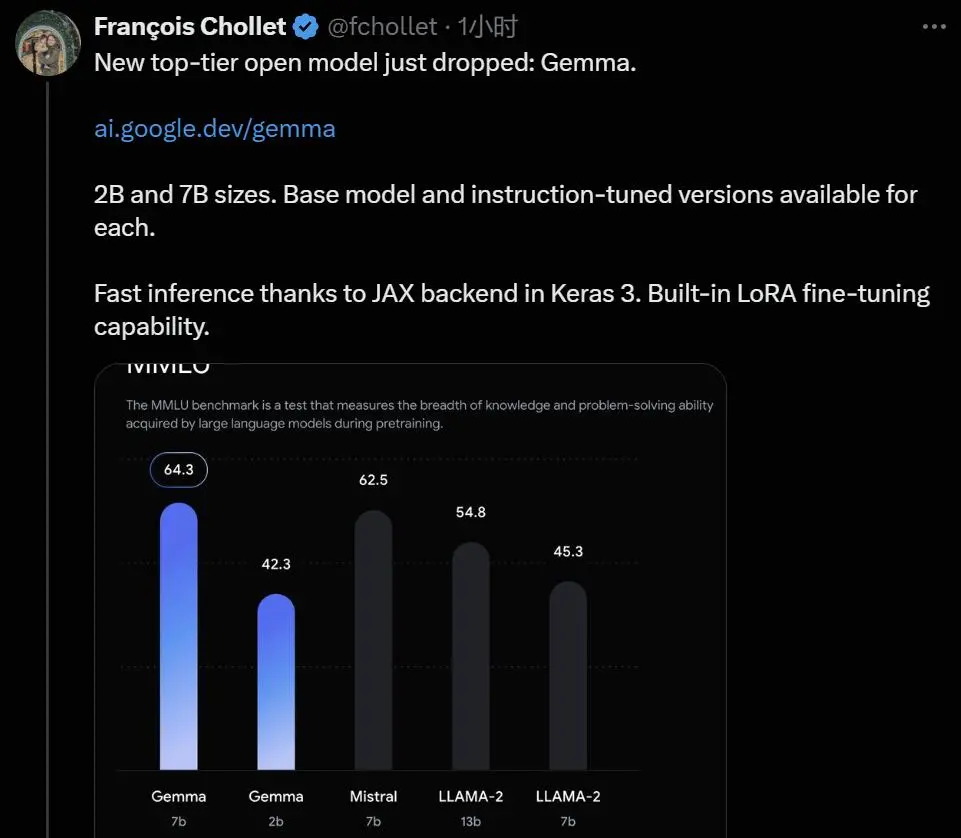
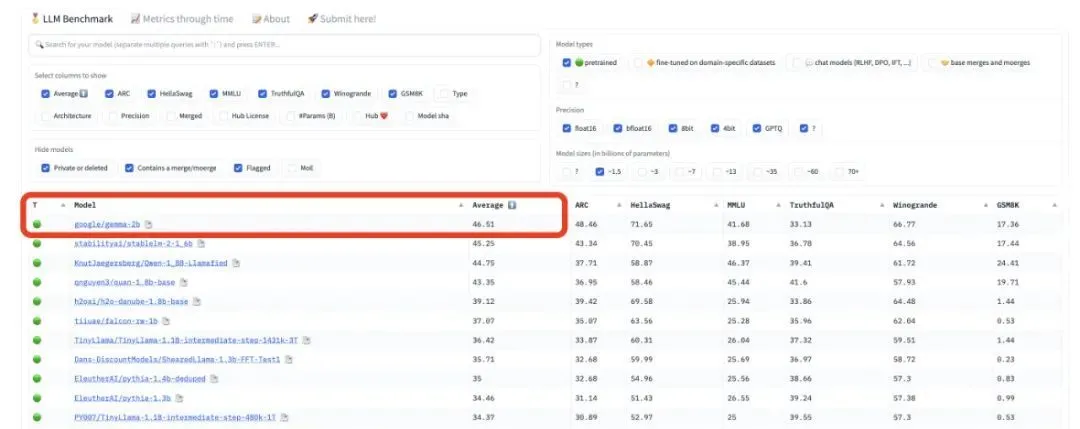
在 HuggingFace 的 LLM leaderboard 上,Gemma 的 2B 和 7B 模型已經雙雙登頂。
新的 Responsible Generative AI Toolkit 為使用 Gemma 創建更安全的 AI 應用程序提供指導和必備工具。Google還通過原生 Keras 3.0 兼容所有主流框架(JAX、PyTorch 和 TensorFlow),為 Gemma 提供推理和監督微調(SFT)的工具鏈。
在各傢大廠和人工智能研究機構探索千億級多模態大模型的同時,很多創業公司也正在致力於構建體量在數十億級別的語言模型。而 Meta 去年推出的 Llama 系列震動行業,並引發人們對於生成式 AI 開源和閉源路線的討論。
Google表示,Gemma 采用與構建 Gemini 模型相同的研究和技術。不過,Gemma 直接打入開源生態系統的出場方式,與 Gemini 截然不同。Google也並未遵守在去年定下的“不再開放核心技術”的策略。
雖然開發者可以在 Gemini 的基礎上進行開發,但要麼通過 API,要麼在Google的 Vertex AI 平臺上進行開發,被認為是一種封閉的模式。與同為閉源路線的 OpenAI 相比,未見優勢。
但借助此次 Gemma 的開源,Google或許能夠吸引更多的人使用自己的 AI 模型,而不是直接投奔 Meta、Mistral 這樣的競爭對手。
Google這次沒有預告的開源,或許是想搶在 Meta 的 Llama 3 之前一天,畢竟此前有消息稱 Llama 系列本周就要上新(讓我們期待第一時間的評測對比)。
雖然才發佈幾個小時,但 X 平臺上已經有不少用戶曬出使用體驗。有位用戶表示,Gemma -7B 速度很快,輸出也很穩定,好過 Llama-2 13B。


在開源模型的同時,Google還公佈有關 Gemma 的性能、數據集組成和建模方法的詳細信息的技術報告。在技術報告中,其他研究者發現一些亮點,比如 Gemma 支持的詞匯表大小達到 256K,這意味著它對英語之外的其他語言能夠更好、更快地提供支持。

以下是技術報告的細節。
Gemma 技術細節
總體來說,Gemma 是一個輕量級的 SOTA 開放模型系列,在語言理解、推理和安全方面表現出強勁的性能。

技術報告鏈接:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
Google發佈兩個版本的 Gemma 模型,分別是20 億參數和 70 億參數,並提供預訓練以及針對對話、指令遵循、有用性和安全性微調的 checkpoint。其中70 億參數的模型用於 GPU 和 TPU 上的高效部署和開發,20 億參數的模型用於 CPU 和端側應用程序。不同的尺寸滿足不同的計算限制、應用程序和開發人員要求。
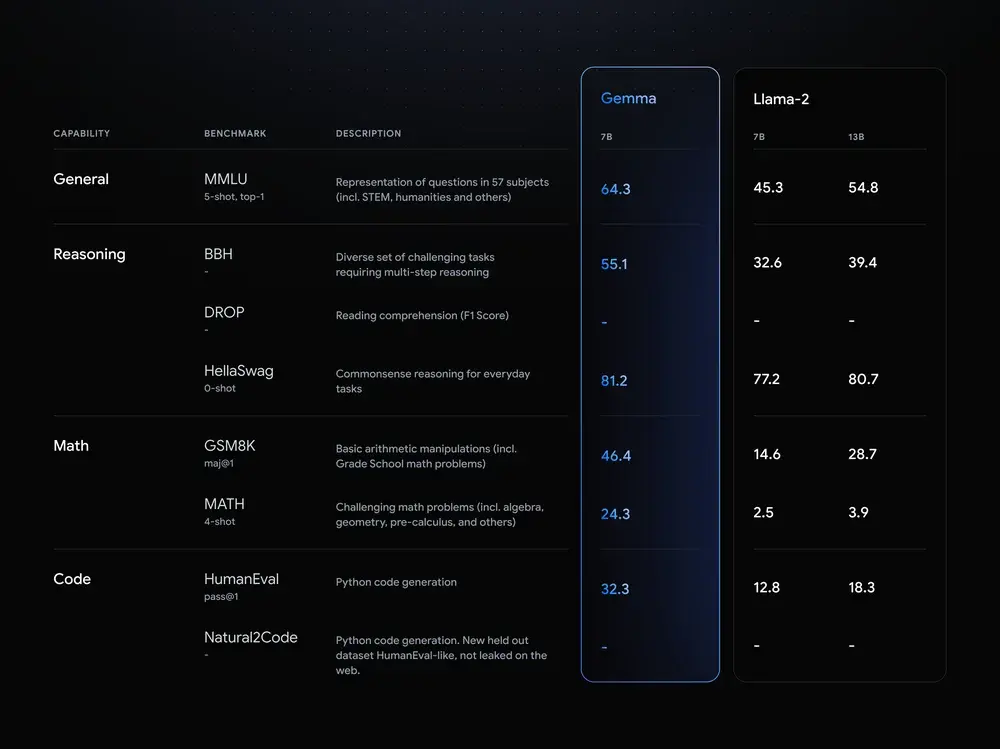
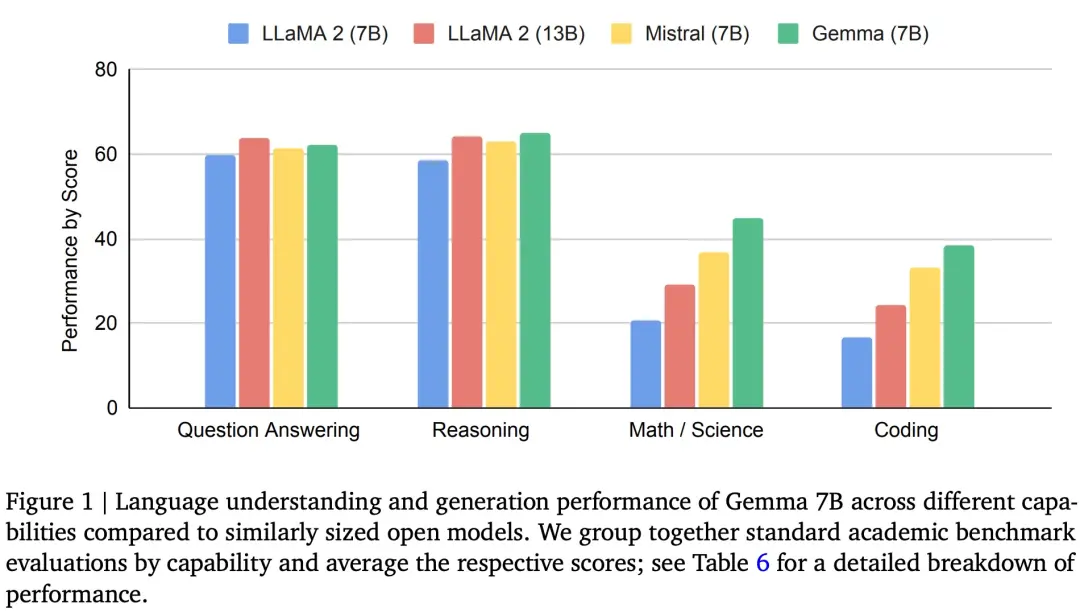
Gemma在 18 個基於文本的任務中的 11 個上優於相似參數規模的開放模型,例如問答、常識推理、數學和科學、編碼等任務。
下圖 1 為 Gemma(7B)與 LLaMA 2(7B)、LLaMA 2(13B)和 Mistral(7B)在問答、推理、數學和科學、編碼等任務上的性能比較。可以看到,Gemma(7B)表現出優勢(除在問答任務上弱於 LLaMA 2(13B))。
接下來看 Gemma 的模型架構、訓練基礎設施、預訓練和微調方法。
模型架構
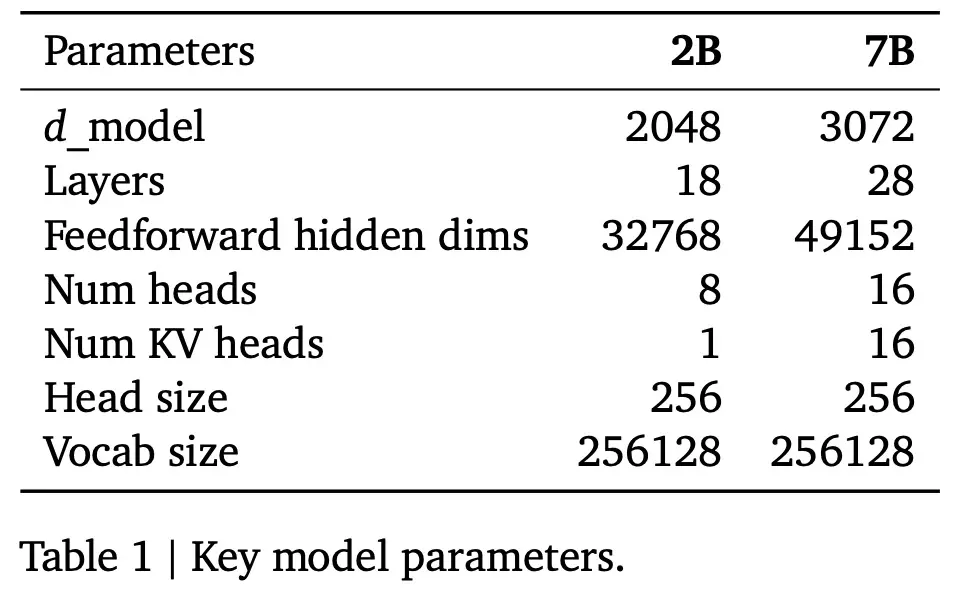
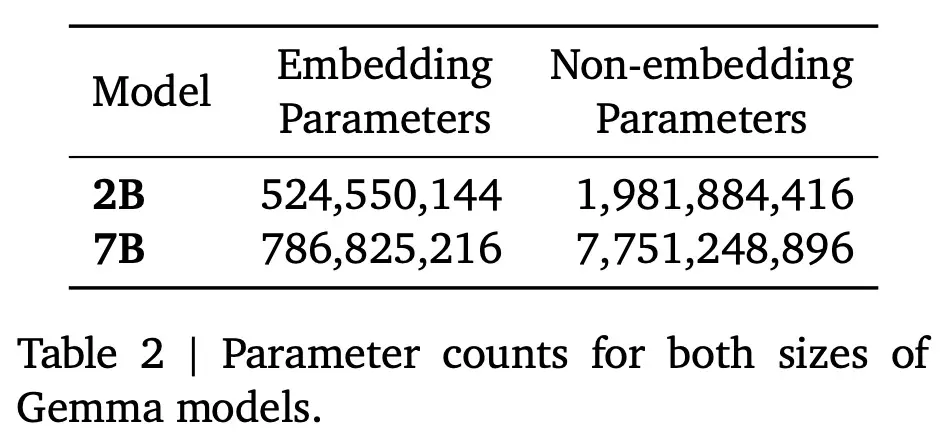
Gemma 模型架構基於 Transformer 解碼器,表 1 總結該架構的核心參數。模型訓練的上下文長度為 8192 個 token。
此外,Google還在原始 transformer 論文的基礎上進行改進,改進的部分包括:
多查詢註意力:7B 模型使用多頭註意力,而 2B 檢查點使用多查詢註意力;
RoPE 嵌入:Gemma 在每一層中使用旋轉位置嵌入,而不是使用絕對位置嵌入;此外,Gemma 還在輸入和輸出之間共享嵌入,以減少模型大小;
GeGLU 激活:標準 ReLU 非線性被 GeGLU 激活函數取代;
Normalizer Location:Gemma 對每個 transformer 子層的輸入和輸出進行歸一化,這與僅對其中一個或另一個進行歸一化的標準做法有所不同,RMSNorm 作為歸一化層。
訓練基礎設施
Google使用自研 AI 芯片 TPUv5e 來訓練 Gemma 模型:TPUv5e 部署在由 256 個芯片組成的 pod 中,配置成由 16 x 16 個芯片組成的二維環形。
對於 7B 模型,Google在 16 個 pod(共計 4096 個 TPUv5e)上訓練模型。他們通過 2 個 pod 對 2B 模型進行預訓練,總計 512 TPUv5e。在一個 pod 中,Google對 7B 模型使用 16 路模型分片和 16 路數據復制。對於 2B 模型,隻需使用 256 路數據復制。優化器狀態使用類似 ZeRO-3 的技術進一步分片。在 pod 之外,Google使用 Pathways 方法通過數據中心網絡執行數據復制還原。
預訓練
Gemma 2B 和 7B 分別在來自網絡文檔、數學和代碼的 2T 和 6T 主要英語數據上進行訓練。與 Gemini 不同的是,這些模型不是多模態的,也不是為在多語言任務中獲得最先進的性能而訓練的。
為兼容,Google使用 Gemini 的 SentencePiece tokenizer 子集(Kudo 和 Richardson,2018 年)。它可以分割數字,不刪除多餘的空白,並遵循(Chowdhery 等人,2022 年)和(Gemini 團隊,2023 年)所使用的技術,對未知 token 進行字節級編碼。詞匯量為 256k 個 token。
指令調優
Google通過在僅文本、僅英語合成和人類生成的 prompt 響應對的混合數據上進行監督微調(SFT),以及利用在僅英語標記的偏好數據和基於一系列高質量 prompt 的策略上訓練的獎勵模型進行人類反饋強化學習(RLHF),對 Gemma 2B 和 Gemma 7B 模型進行微調。
實驗發現,監督微調和 RLHF 這兩個階段對於提高下遊自動評估和模型輸出的人類偏好評估性能都非常重要。
監督微調
Google根據基於 LM 的並行評估結果來選擇自己的混合數據,以進行監督微調。給定一組留出的(heldout) prompt, Google從測試模型中生成響應,並從基線模型中生成相同 prompt 的響應,並要求規模更大的高性能模型來表達這兩個響應之間的偏好。
Google還構建不同的 prompt 集來突出特定的能力,例如指令遵循、真實性、創造性和安全性等。Google使用不同的自動化 LM“judges”,它們采用多種技術,比如思維鏈提示(chain-of-thought prompting)、對齊人類偏好等。
格式化
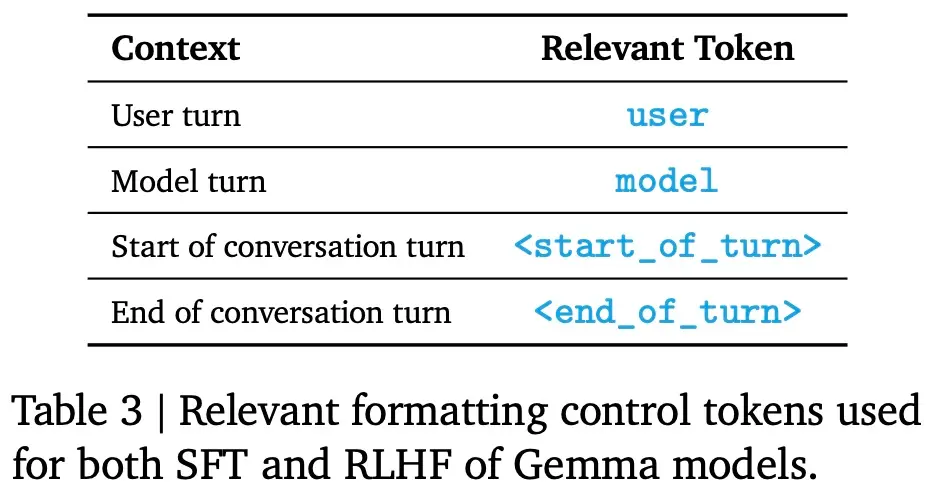
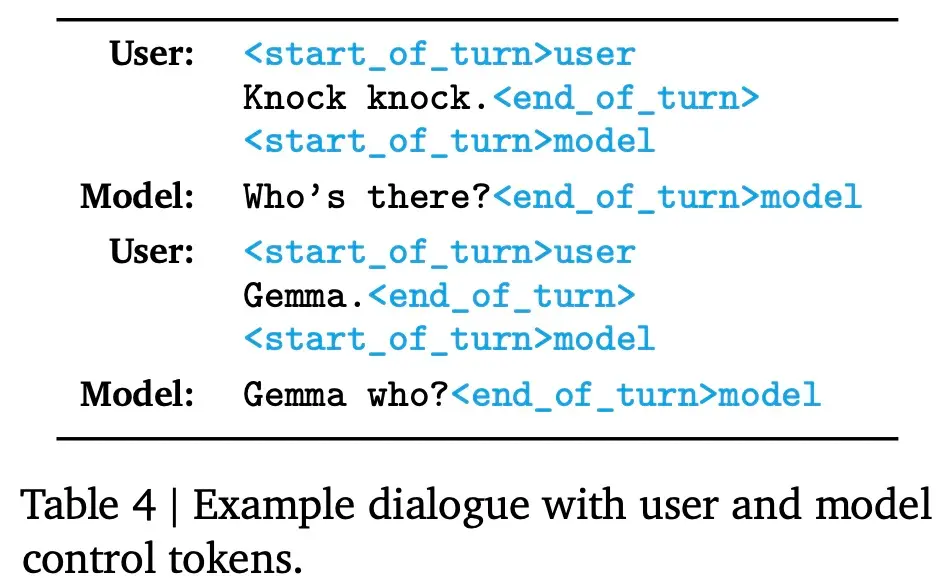
指令調優模型使用特定的格式化器進行訓練, 該格式化器在訓練和推理時使用額外的信息來標註所有指令調優示例。這樣做有以下兩個目的,1)指示對話中的角色,比如用戶角色;2)描述對話輪次,尤其是在多輪對話中。為實現這兩個目的,Google在分詞器(tokenizer)中保留特殊的控制 token。
下表 3 為相關格式化控制 token,表 4 為對話示例。
人類反饋強化學習(RLHF)
Google使用 RLHF 對監督微調模型進一步微調,不僅從人類評分者那裡收集偏好對,還在 Bradley-Terry 模型下訓練獎勵函數,這類似於 Gemini。該策略經過訓練,使用一個具有針對初始調優模型的 Kullback–Leibler 正則化項的 REINFORCE 變體,對該獎勵函數進行優化。
與監督微調(SFT)階段一樣,為進行超參數調優,並額外減輕獎勵黑客行為,Google依賴高容量模型作為自動評估器,並計算與基線模型的比較結果。
評估
Google通過人類偏好、自動基準和記憶等指標,在廣泛的領域對 Gemma 進行全面的評估。
人類偏好評估
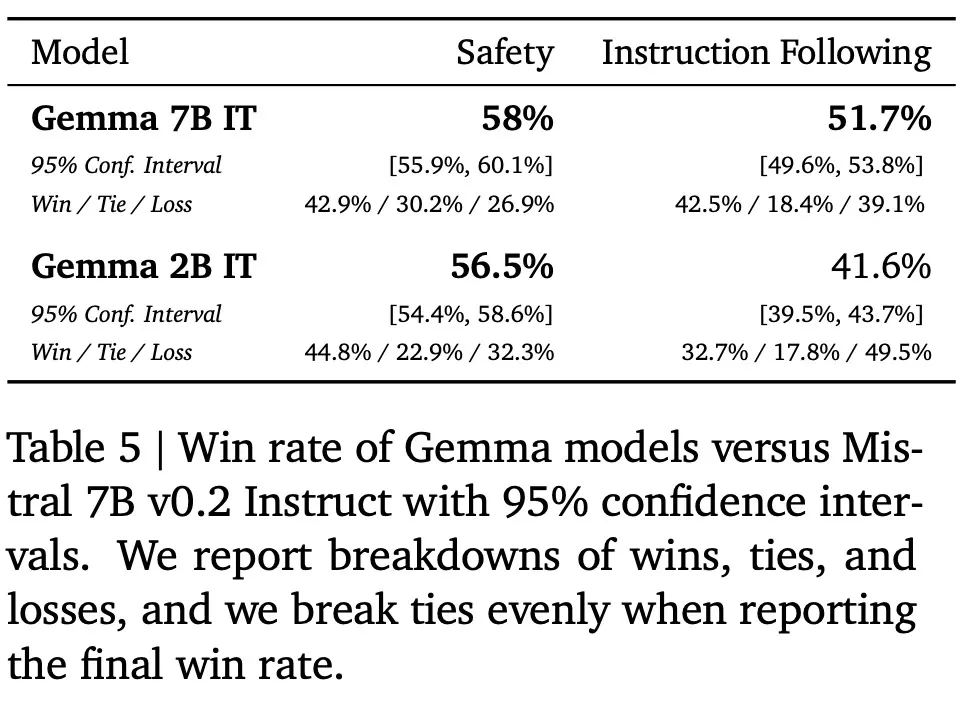
除在經過微調的模型上運行標準學術基準之外,Google對最終發佈的候選模型進行人類評估研究,以便與 Mistral v0.2 7B Instruct 模型進行比較。
與 Mistral v0.2 7B Instruct 相比,Gemma 7B IT 的正勝率為 51.7%,Gemma 2B IT 的勝率為 41.6%。在測試基本安全協議的約 400 條 prompt 中,Gemma 7B IT 的勝率為 58%,而 Gemma 2B IT 的勝率為 56.5%。表 5 中報告相應的數字。
自動基準評估
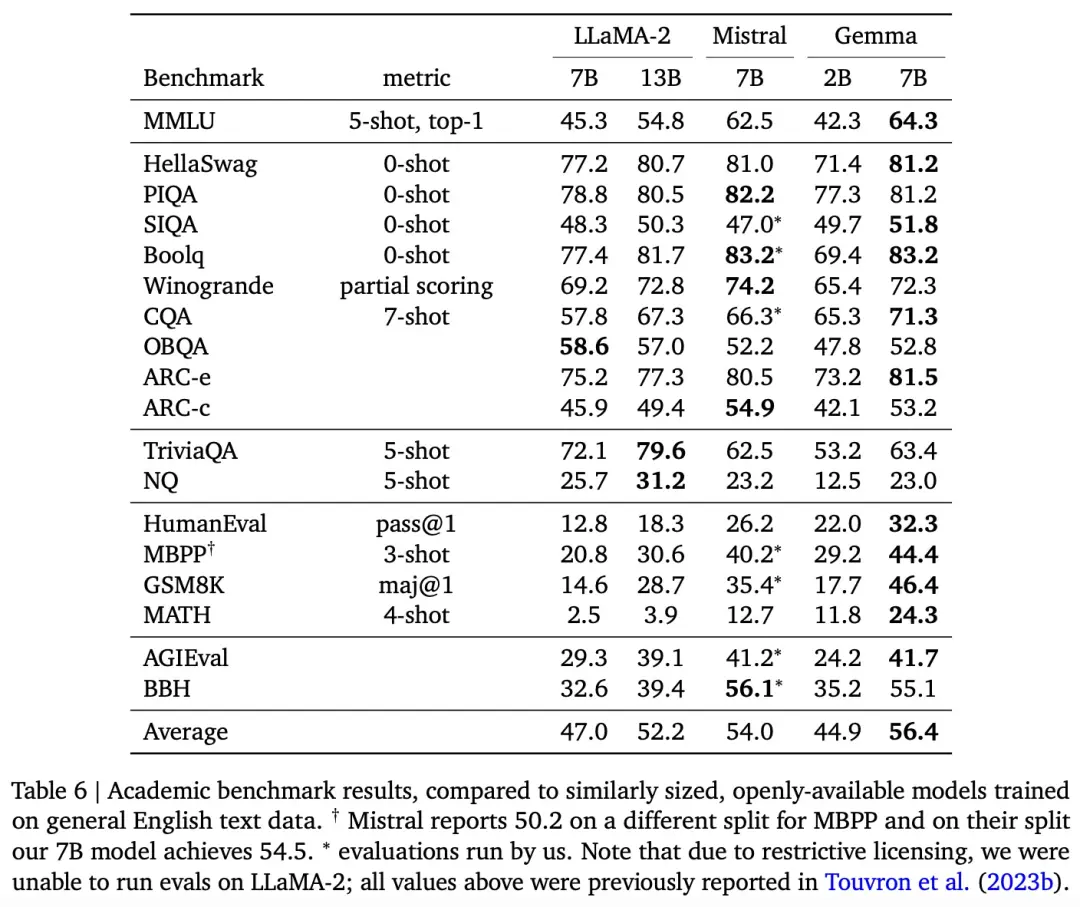
Google還在一系列學術基準上將 Gemma 2B 和 7B 模型與幾個外部開源 LLM 進行比較,如表 6 所示:
在 MMLU 上,Gemma 7B 的表現優於相同或較小規模的所有開源模型,還優於幾個較大的模型,包括 LLaMA2 13B。
然而,基準作者對人類專傢表現的評估結果是 89.8%, Gemini Ultra 是第一個超過這一閾值的模型,可以看到Gemma仍有很大的改進空間,以達到Gemini和人類水平的性能。
但 Gemma 模型在數學和編碼基準測試中表現比較突出。在數學任務上,Gemma 模型在 GSM8K 和更難的 MATH 基準上的表現超過其他模型至少 10 分。同樣,它們在 HumanEval 上的表現比其他開源模型至少高出 6 分。Gemma 在 MBPP 上的表現甚至超過經過代碼微調的 CodeLLaMA-7B 模型(CodeLLaMA 得分為 41.4%,而 Gemma 7B 得分為 44.4%)。
記憶評估
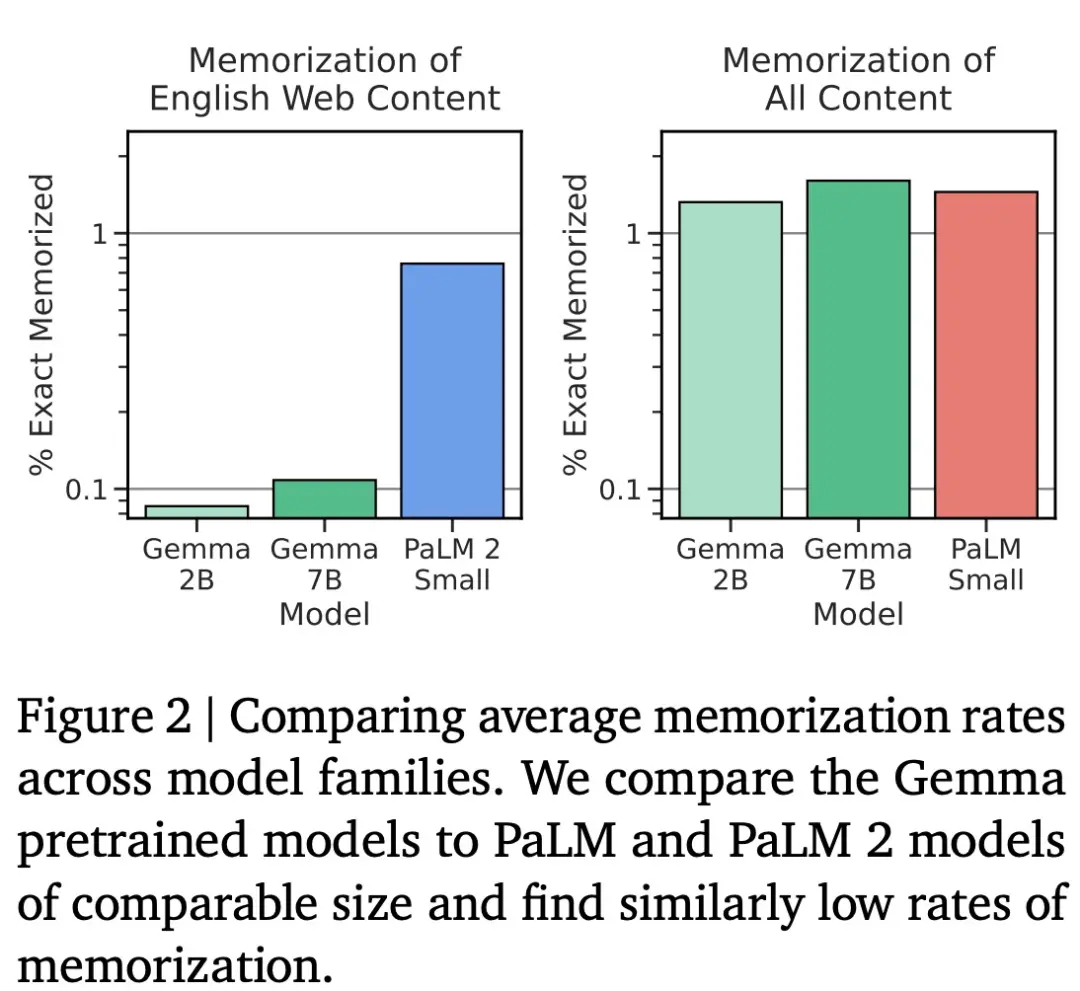
Google使用 Anil 等人采用的方法測試 Gemma 的記憶能力,具體而言,他們從每個語料庫中采樣 10000 個文檔,並使用前 50 個 token 作為模型的 prompt。在此過程中,Google主要關註精準記憶,如果模型生成的後續 50 個 token 與文本中的真實後續文本完全匹配,則將該文本分類為已記憶。圖 2 將評估結果與同等規模的 PaLM 和 PaLM 2 模型進行比較,結果如下所示。
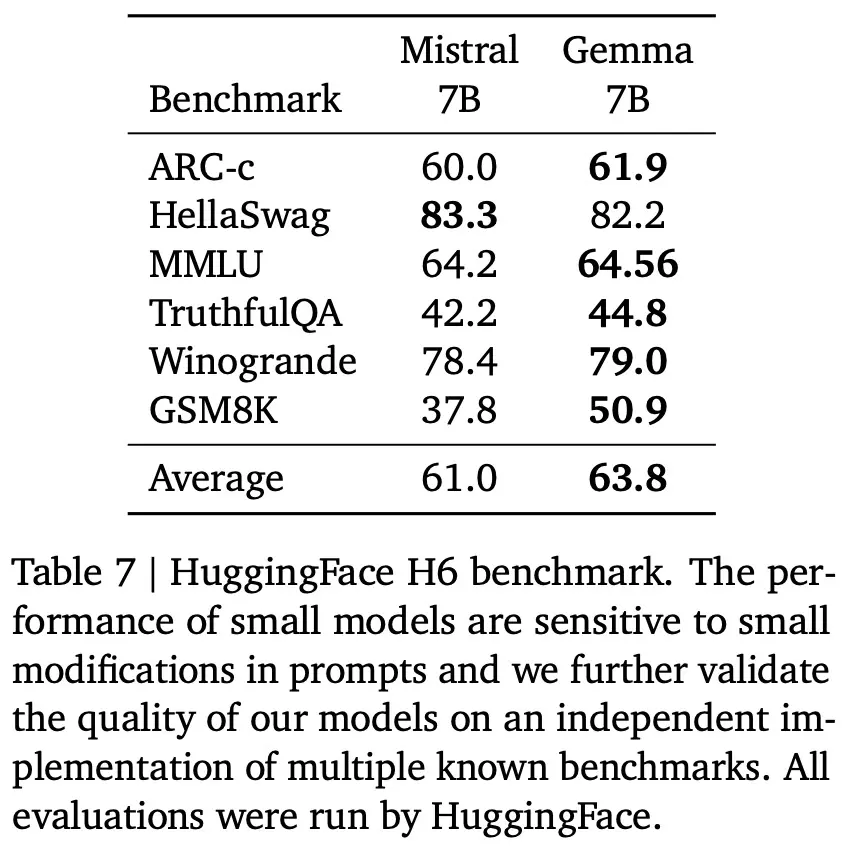
隱私數據
對大模型來說,隱私數據被記住的可能性是一件非常值得關註的事情。為使 Gemma 預訓練模型安全可靠,Google使用自動方法從訓練集中過濾掉某些隱私信息和其他敏感數據。
為識別可能出現的隱私數據,Google使用 Google Cloud 數據丟失防護 (DLP) 工具。該工具根據隱私數據的類別(例如姓名、電子郵件等)輸出三個嚴重級別。Google將最高嚴重性分類為“敏感(sensitive)”,其餘兩個分類為“隱私(personal)”,然後測量有多少存儲的輸出包含敏感或個人數據。
如下圖 3 所示,Google沒有觀察到存儲敏感數據的情況,但確實發現 Gemma 模型會記住一些上述分類為潛在“隱私”的數據。值得註意的是,研究中使用的工具可能存在許多誤報(因為其隻匹配模式而不考慮上下文),這意味著實驗結果可能高估已識別的隱私數據量。
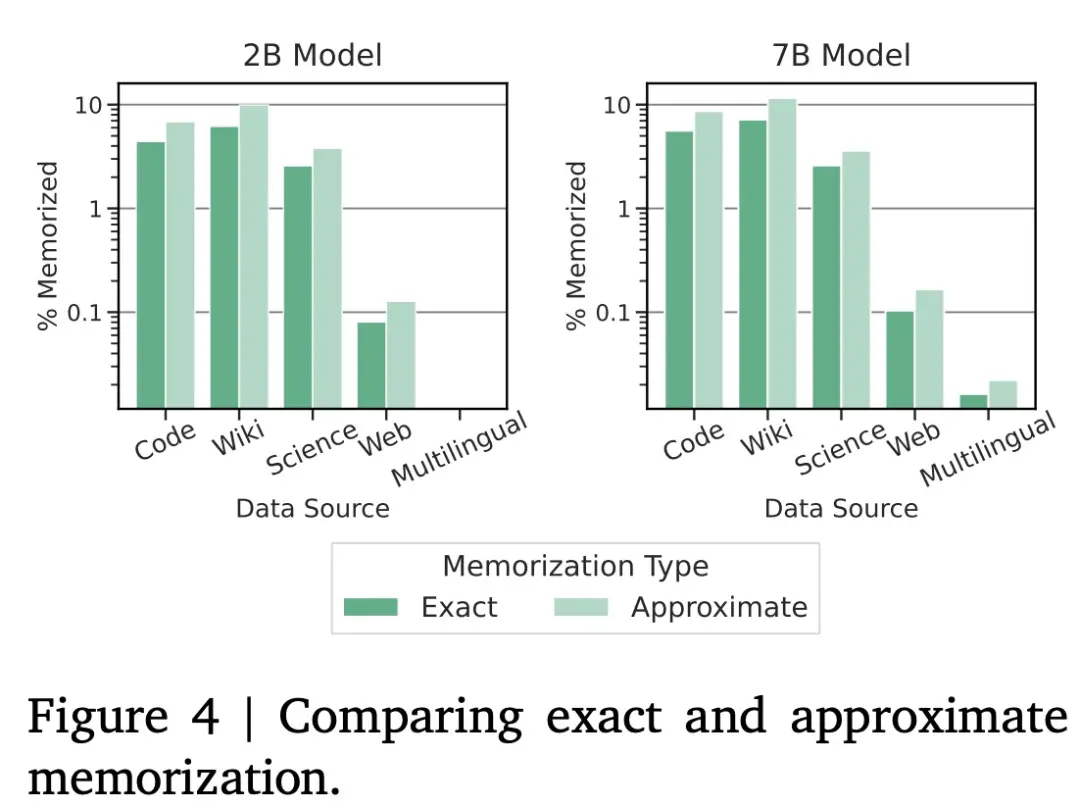
在記憶數據量方面,如下圖 4 所示,Google觀察到大約會多出 50% 的數據被記住,並且在數據集的每個不同子類別中幾乎是一致的。
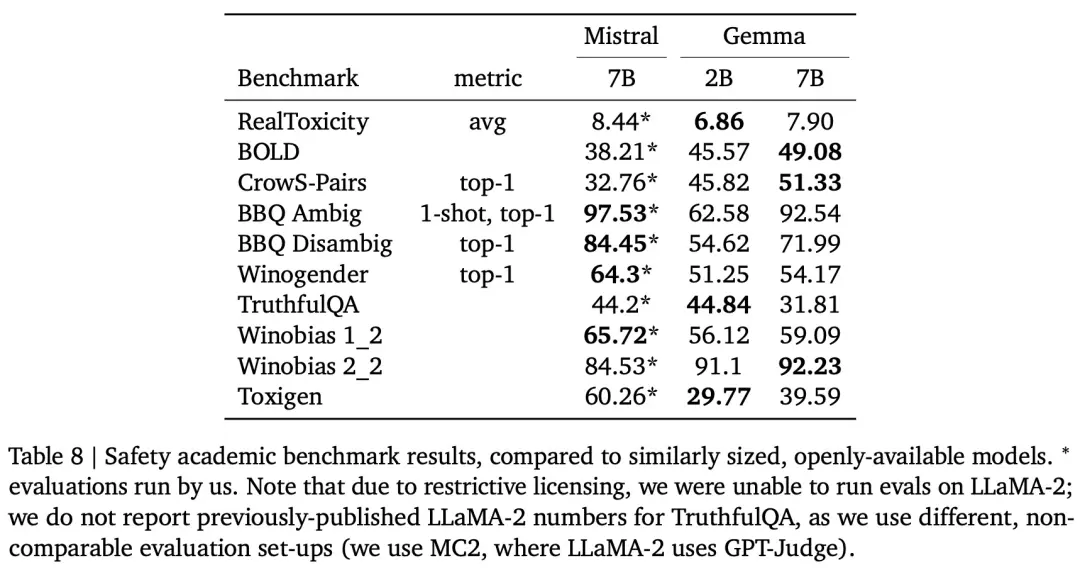
最後,Google還通過標準化 AI 安全基準評估 Gemma 的安全性,結果如下表 8 所示。