幾傢巨頭之間的大模型競爭,越來越像打牌。你出完炸彈我出炸彈。這不,又一個深夜炸彈。2月21日,在與閉源的OpenAI打得火熱的同時,Google突然加入開源的戰局。北京時間夜間Google突然宣佈,開源一個新的模型系列Gemma,這個模型使用與它最強的Gemini同源的技術,並且在一系列的標準測試上秒殺幾款今天最熱門的開源模型。
怎麼理解這個動作的重要性呢?你可以粗暴的理解為:
這有點像現在正在訓練更強大的GPT-5的OpenAI,把GPT3的低參數版給開源。(前幾天Sam Altman被問過這個問題,你們是否會在未來把GPT3開源,他沒有直接回答。現在看來Google針對性很強啊。)

(X上一張有意思的圖)
根據Google官方對Gemma的介紹,它的基本信息如下:
Gemma是Google開源的一個大型語言模型,而非像Gemini那樣是多模態的,它基於與Gemini相同的技術構建,但完全公開並允許商用授權。
Gemma模型有兩個主要版本,分別是Gemma 7B(70億參數)和Gemma 2B(20億參數)。這些模型在大規模的數據集上進行訓練,數據集包含以英語為主的網絡文檔、數學數據以及代碼數據,總量達到6萬億tokens。
Gemma模型的特點包括:
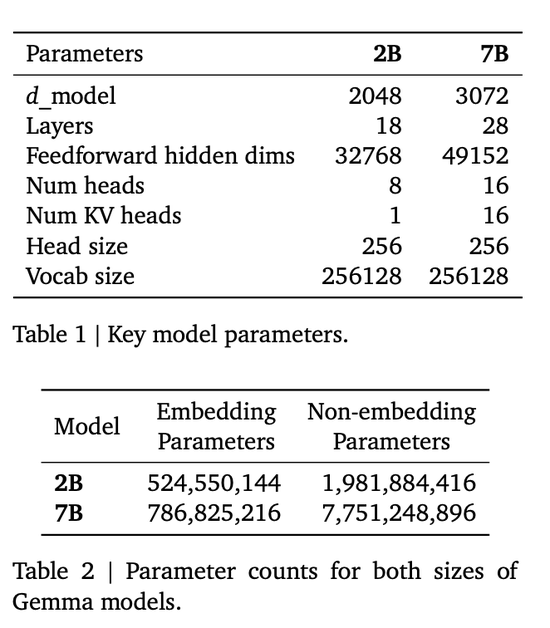
架構細節:Gemma模型具有不同的參數規模,Gemma-2B有18層,d_model為2048,而Gemma-7B有28層,d_model為3072。這些模型還具有不同的前饋隱藏維度、頭數和KV頭數,以及詞匯量。
新技術:Gemma采用一些新技術,如Multi-Query Attention、RoPE Embeddings、GeGLU激活函數以及Normalizer Location,這些技術有助於提高模型的性能。
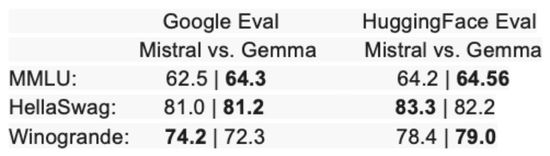
評測結果:Google官方宣稱Gemma模型在70億參數規模的語言模型中表現最佳,甚至超過一些參數量更大的模型。
開源情況:Gemma模型遵循一個自定義的開源協議,允許商業使用。
發佈完,Jeff Dean就對這個系列模型劃重點:
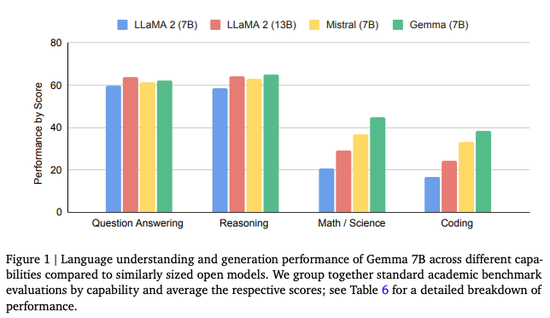
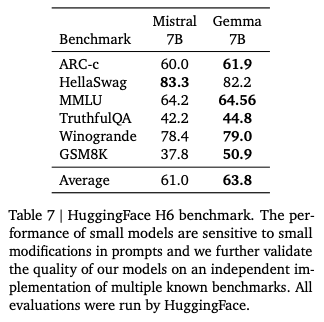
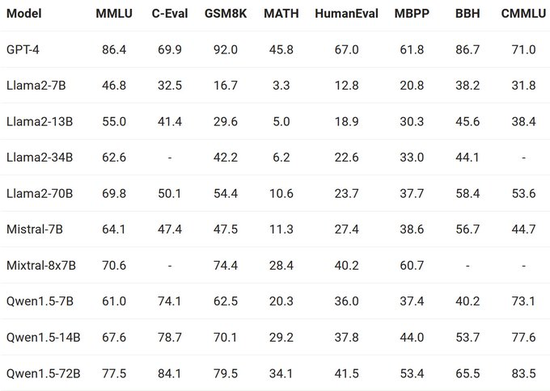
Gemma-7B模型在涵蓋通用語言理解、推理、數學和編程的8項基準測試中,性能超過廣泛使用的Llama-2 7B和13B模型。它在數學/科學和編程相關任務上,通常也超過Mistral 7B模型的性能。
Gemma-2B IT和Gemma-7B IT這兩個經過指令調整的模型版本,在基於人類偏好的安全評估中,都優於Mistral-7B v0.2指令模型。特別是Gemma-7B IT模型在遵循指令方面也表現更佳。
(有意思的是,在Google曬出的成績對比中,阿裡的千問背後的模型Qwen系列表現也很亮眼)
我們也發佈一個負責任的生成性人工智能工具包(Responsible Generative AI Toolkit),它為負責任地使用像Gemma模型這樣的開放模型提供資源,包括:
關於設定安全政策、安全調整、安全分類器和模型評估的指導。
學習可解釋性工具(Learning Interpretability Tool,簡稱LIT),用於調查Gemma的行為並解決潛在問題。
一種構建具有最小樣本量的強大安全分類器的方法論。
我們發佈兩個版本的模型權重:Gemma 2B和Gemma 7B。每個版本都提供預訓練和指令調整的變體。
我們為所有主要框架提供推理和監督式微調(SFT)的工具鏈:通過原生Keras 3.0支持的JAX、PyTorch和TensorFlow。
提供即用型的Colab和Kaggle筆記本,以及與流行的工具如Hugging Face、MaxText、NVIDIA NeMo和TensorRT-LLM的集成,使得開始使用Gemma變得簡單。
預訓練和指令調整的Gemma模型可以在您的筆記本電腦、工作站或Google Cloud上運行,並且可以輕松部署在Vertex AI和Google Kubernetes Engine(GKE)上。
在多個AI硬件平臺上的優化確保行業領先的性能,包括NVIDIA GPU和Google Cloud TPUs。
使用條款允許所有規模的組織負責任地進行商業使用和分發。
可以看到Jeff Dean和Google這次都十分強調開源模型的安全性和具體的實打實的配套設施和舉措。這似乎也直至被詬病Close AI且被外界質疑安全性保障的OpenAI。

現在,憋壞的Google正式四面開戰。未來它將用Gemma對抗Llama,用Gemini對抗GPT。
無論是開源還是閉源,競爭越來越焦灼。