他來他來,老黃帶著“最強生成式AI處理器”和一系列重磅更新來!在計算機圖形學頂會SIGGRAPH上,老黃宣佈英偉達最新的超級芯片NVIDIADGXGH200GraceHopper。這塊芯片搭載全球最快的內存,不僅帶寬每秒5TB,內存容量更是暴增接近50%來到141GB,“任何大語言模型都能運行”。

同時,英偉達還宣佈和Hugging Face的合作——
以後在Hugging Face平臺上,不需要再下載ML模型自己運行,隻需要幾步簡單操作,就能在筆記本上運行大模型,有Colab內味(就是不知道有沒有免費版)。
至於軟件更新,字裡行間也全是AI。
不僅在Omniverse平臺中集成一系列時下熱門的AI工具,新的軟件有不少也是基於大模型打造,像ChatUSD就能幫開發者們寫代碼。
這也是時隔五年,老黃再次登上SIGGRAPH的舞臺。在會上,他自信滿滿地宣佈:生成式人工智能的“iPhone時刻”,已經來臨。
有網友看完發佈會後感慨:英偉達在AI硬件這方面,已經無人能及。
新芯片組成的“最強超算”來襲
這場發佈會中最先拋出,也是最引人矚目的,非“最強超算”莫屬。
這臺超級計算機由256塊DGX GH200 Grace Hopper(簡稱DGX GH200)連接而成。
用老黃的話,這個“龐然大物”就是為AIGC時代量身打造的。
它的算力和內存容量分別達到1E(10^15)FLOPS和144TB。
下面這張圖展示它的真實大小(中間的黑影是老黃)。

不僅是性能優異,對比發現,性價比簡直完爆CPU。
同樣花1億美元,拿來買CPU和GPU分別能得到什麼?
CPU的話,可以買8800個x86架構的產品。
這近九千塊CPU加起來,隻能帶動一個LLaMA 2、SDXL這樣規模的AI程序。
功率嘛……是5兆瓦,也就是每小時5000度電。

如果換成GPU的話,則是2500塊DGX GH200。
能帶動的近似規模的AI程序一下增加到12個,功率卻降低到3兆瓦。

平均到單個程序上,需要210塊DGX GH200,價格是800萬美元,功率則為0.26兆瓦。

而組成這個“最強超算”的DGX GH200,同樣是王者級別,被稱為“最強生成式AI處理器”。

DGX GH200由Grace CPU和Hopper GPU組成。
其中Grace CPU包含72核心,而後者擁有4P(10^12)FLOPS的算力和500GB的LPDDR5X。
此外,DGX GH200中還加入海力士的“最快內存”HBM3e。
它的容量為141GB,帶寬則高達每秒5TB,分別是H100的1.7倍和1.55倍。
(好傢夥,H100都隻配當baseline)

在DGX GH200中,CPU和GPU之間的連接速度是第五代PCIe的7倍。

而從單塊DGX GH200到整個超級計算機的過程,主打的就是一個“疊”。
這要得益於它的多GPU高速連接能力。
雙聯體的DGX GH200,性能幾乎沒有損失,直接就是單體的兩倍。

將雙聯體的DGX GH200與BlueField-3 DPU和ConnectX-7網卡,就組成一個“計算盒”。

通過NVLink,8個這樣的“計算盒”高速連接,就得到DGX構建塊,總內存達到4.6TB。

這樣的構建塊可以合二為一形成新的計算盒,並最終擴展成256 GPU的工作集群Superpod。
NVLink的高速連接能力,讓這256塊GPU“就像是一塊一樣”工作。

至此,顯卡超算的規模已經達到本節開頭老黃所展示的水平。
但這還沒有結束——Superpod之間還能繼續連接。
在高速低延時的Quantum-2 Infiniband平臺幫助下,超算的規模可以接著擴展……

講到這裡,老黃還打趣道:
如果哪天你從(某電商平臺)上買顯卡的時候發現它,千萬不要覺得驚訝!
總之,根據不同需要,利用DGX GH200將能構建出不同規模的、適應AIGC時代的超級計算機。
據預計,DGX GH200將於明(2024)年第二季度投產。
還發3個RTX新專業顯卡
除“最強生成式AI處理器”以外,英偉達這次也推出3款船新的工作站顯卡:
RTX 5000、RTX 4500和RTX 4000。
這幾款顯卡均基於Ada Lovelace架構設計,目前參數已經同步英偉達官網:
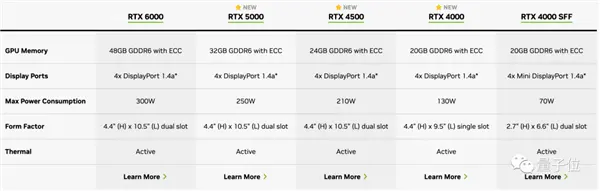
當然,專業顯卡售價也更貴。
其中RTX 5000售價達到4000美元(約合人民幣2.87萬元),RTX 4500售價2250美元(約1.6萬元),RTX 4000售價1250美元(約8987元)。
老黃也在發佈RTX顯卡時,再次說出那句經典名言:
買得越多,省得越多(the more you buy, the more you save)。

至於去年9月發佈的RTX 6000 Ada顯卡,在這次大會上也推出一個新的工作站設計:4塊疊起來,搞個頂級“疊疊樂”。
這樣設計的單個RTX工作站,單個可以提供5828 TFLOPS的AI性能,以及192GB的GPU內存。
除此之外,老黃還在這次大會上宣佈一個搭載L40S Ada GPU的新款OVX服務器,數據中心專用。

每臺服務器搭載8塊L40S Ada GPU,每塊L40S包含高達18176個CUDA核心,可以提供提供近5倍於A100的單精度浮點(FP32)性能。
相比A100,L40S微調(fine-tune)大模型的性能提升大約1.7倍。
(沒錯,A100已經被老黃用來給新硬件當對比)
具體來說,在這個OVX服務器上微調一個860M參數的大模型,現在隻需要7小時就可以完成;
400億參數的GPT-3大模型,更是隻需要15個小時就能微調完成。
在渲染上,L40S性能也不錯,配備142個第三代RT核心,可以提供212 teraflops的光線追蹤性能。
預計L40S將於今年秋季上市。
AIGC版Colab來,筆記本跑大模型
不僅是硬件上接連拋出一系列“重磅炸彈”,軟件方面英偉達也發佈多款新產品。
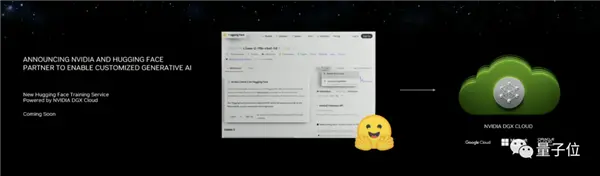
首先是和HuggingFace合作,把NVIDIA DGX Cloud AI整合到其中。
在HF的頁面中,一鍵就能讓模型在雲上調整運行。
英偉達科學傢范麟熙(Jim Fan)激動地宣佈這一消息,還透露其中使用的每個節點都是8個H100或A100。
除與HF合作,英偉達還推出自己的Workbench平臺。
通過連接雲端服務,用筆記本電腦就能跑大模型。
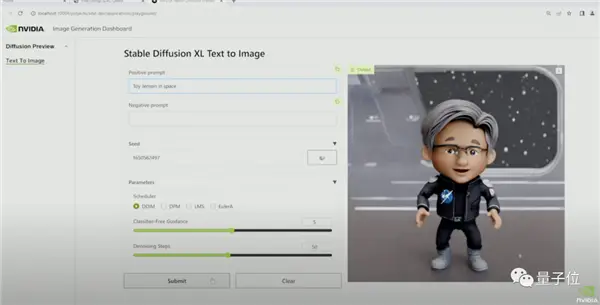
現場還播放通過Workbench跑SDXL的演示視頻。
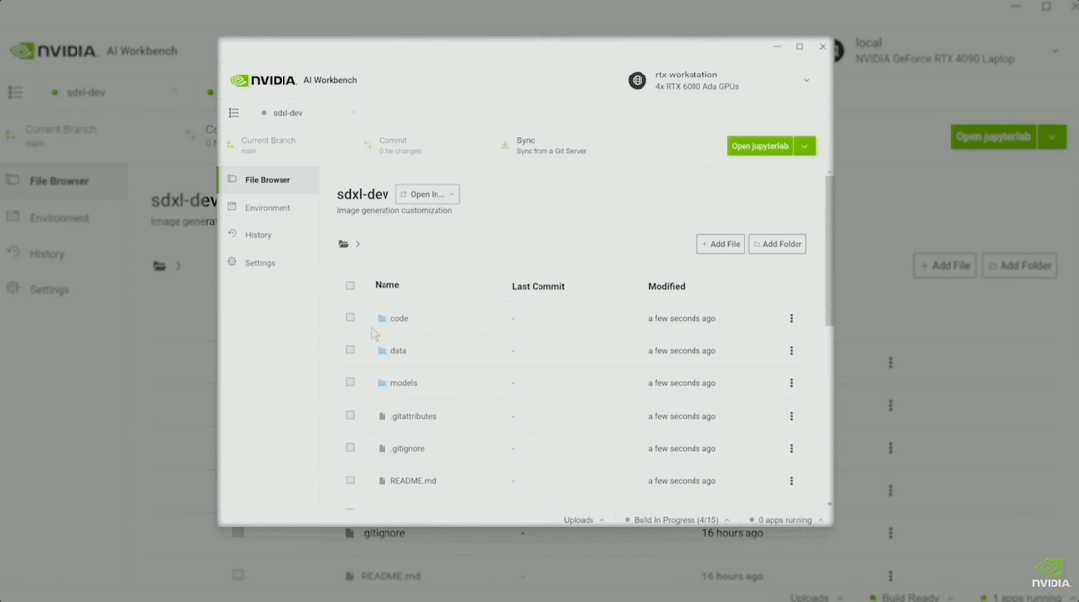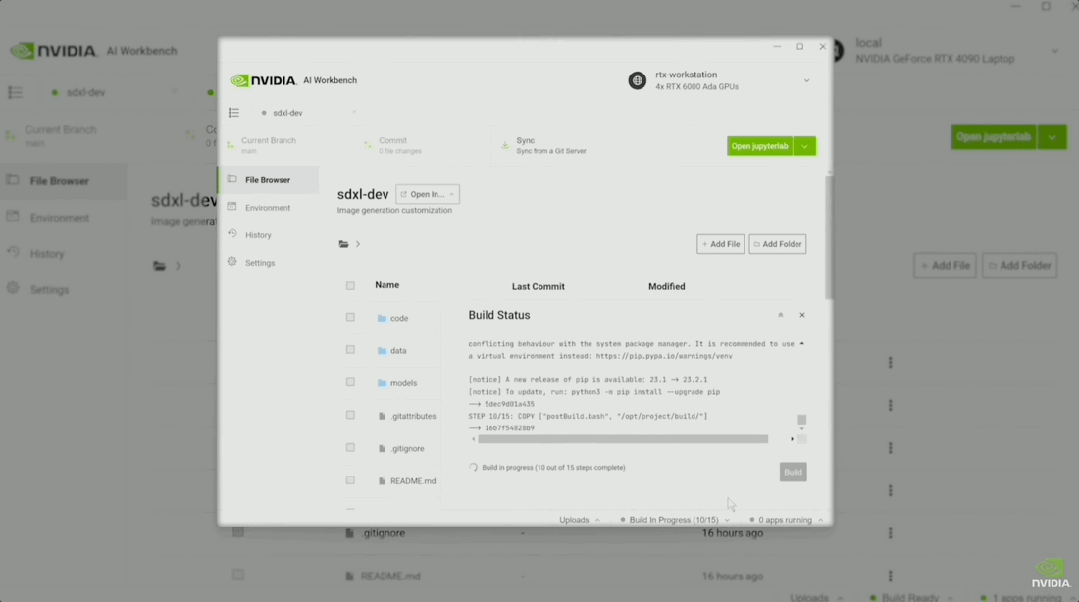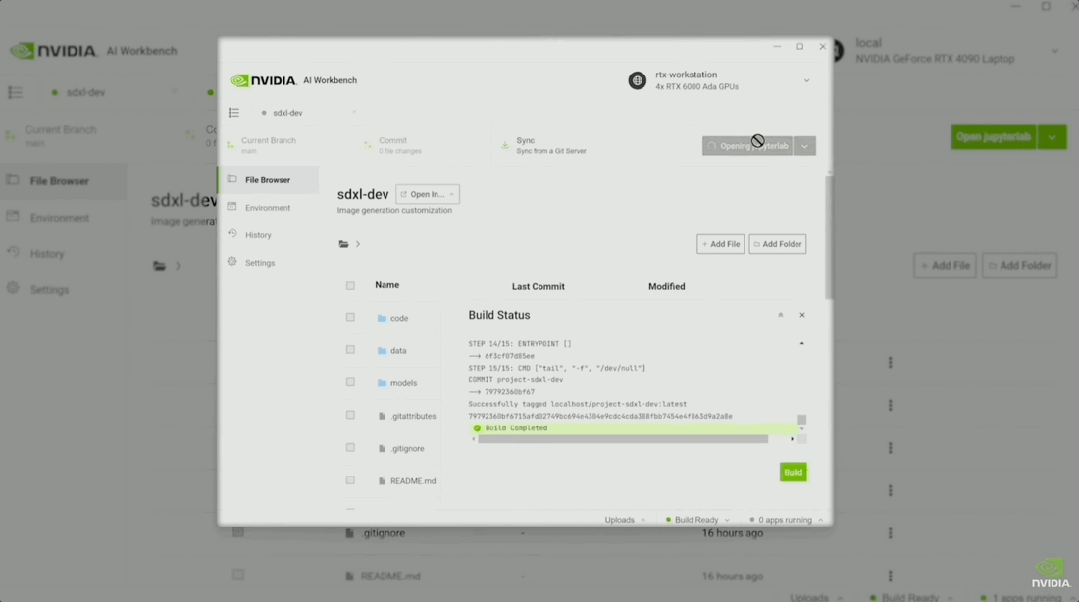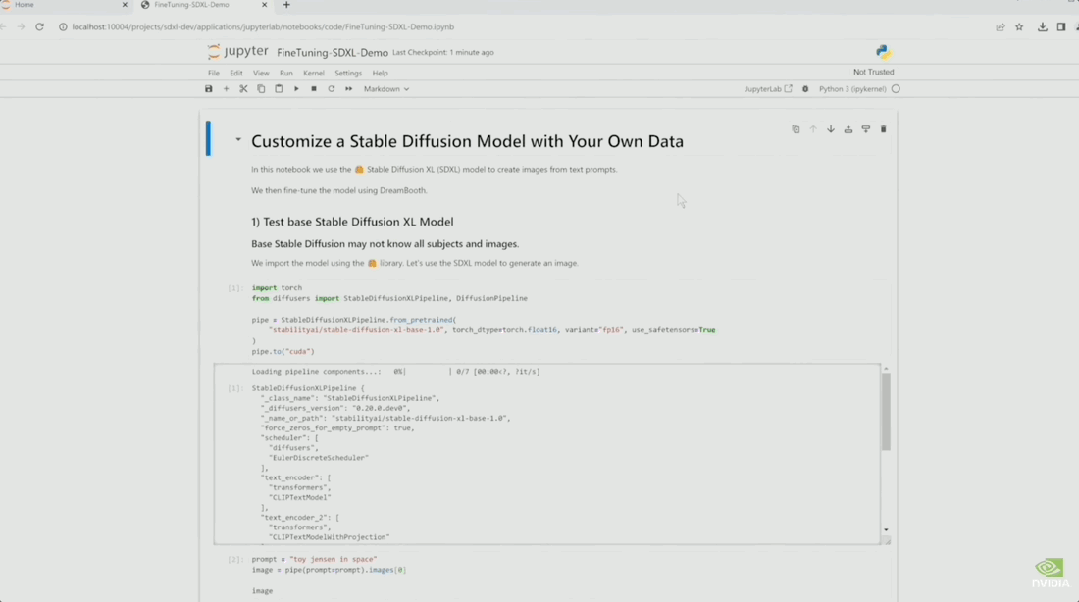
在Jupyter中,演示者讓SDXL畫一個“玩具老黃”。
此時的SDXL還不知道“玩具老黃”是個啥玩意兒。
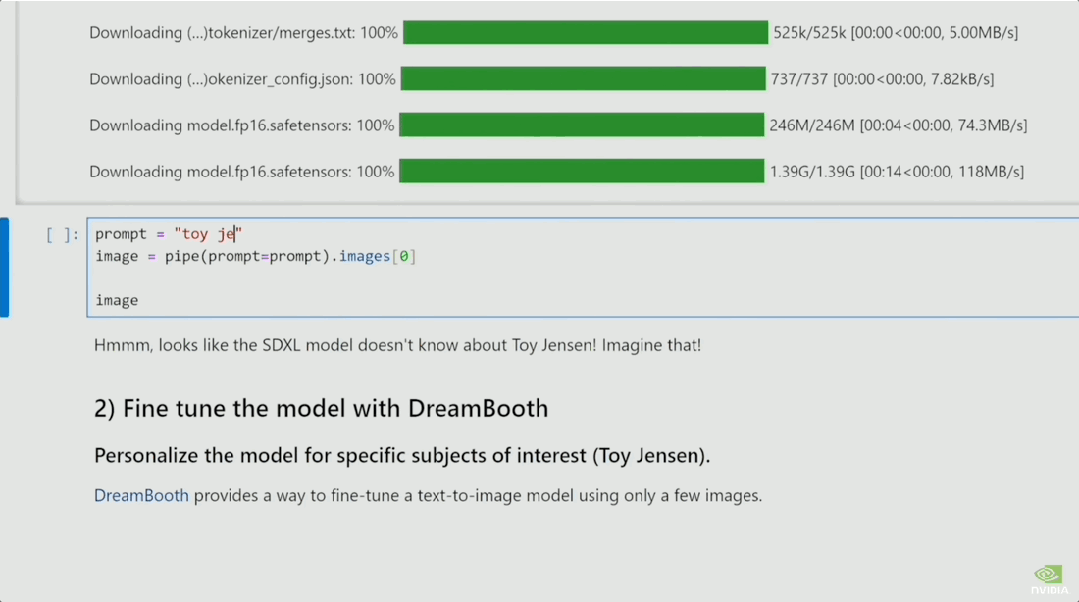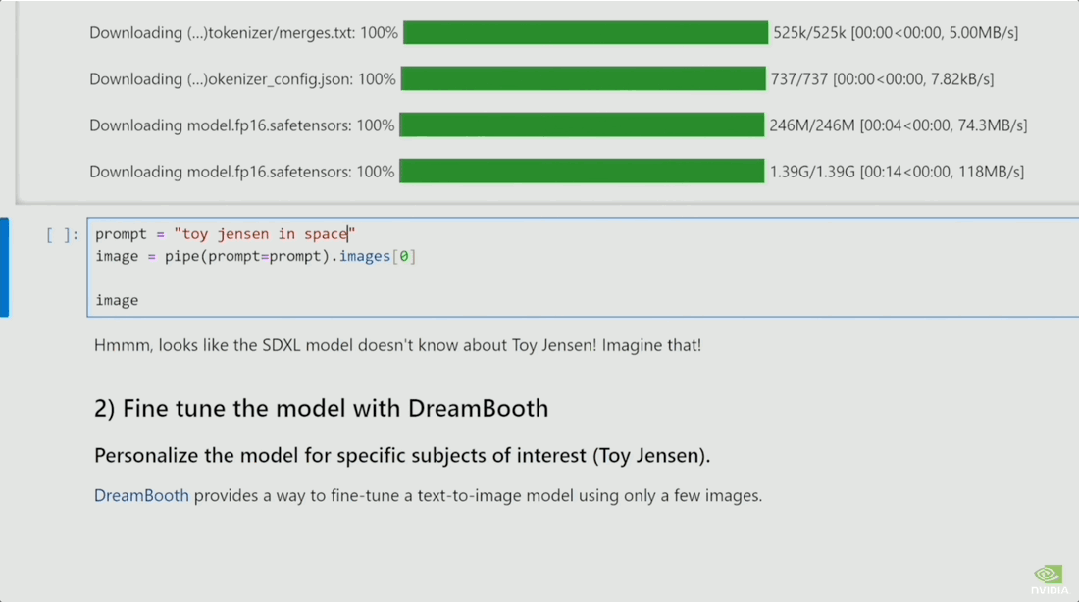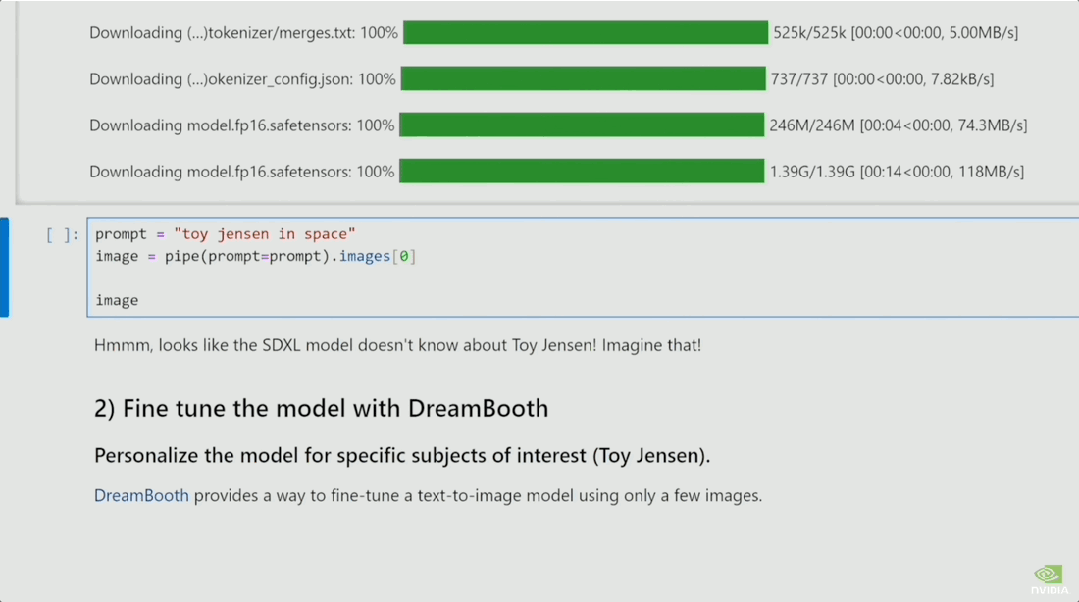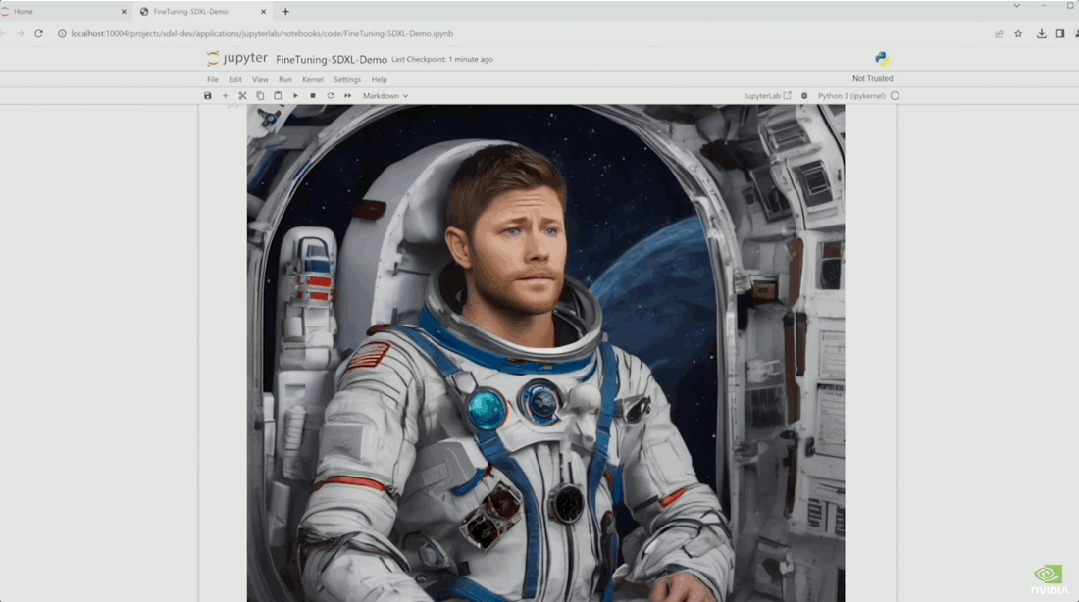
於是演示者現場用8張圖對模型進行微調。

微調後重新繪制的作品,是不是有那味?
除上述兩款大模型運行工具,英偉達還推出最新版的企業軟件平臺NVIDIA AI enterprise 4.0。
軟件包的數量達到4500個,還有數以萬計的相關依賴,而且安全可靠。

Google、微軟、亞馬遜、甲骨文等英偉達合作方都會在自己的雲平臺中集成這項服務。
“人類將成為一門新的編程語言”
除此之外,英偉達的計算機圖形與仿真模擬平臺Omniverse,也宣佈一系列新進展。
一方面,更多AI工具可以直接在Omniverse裡面調用。
包括對話式AI角色創建工具Convai、高保真AI動捕工具Move AI、AI低成本制作CG工具CGWonder Dynamics在內,一系列流行AI工具,現在都已經通過OpenUSD集成到Omniverse中。
就連Adobe,也計劃將Adobe Firefly作為API,提供在Omniverse中(就是估計會收費)。

另一方面,英偉達還將生成式AI技術和OpenUSD結合,推出一些好用的AI工具。
例如ChatUSD,就是一個基於NVIDIA Nemo框架大模型Copilot,不僅可以回答開發者有關USD的問題,還能幫忙生成Python-USD代碼。
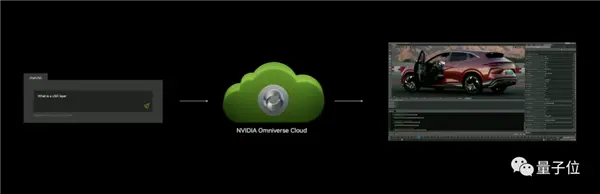
又例如DeepSearch,也是一個基於大模型的新工具,基於文本或圖像輸入,可以快速對數據庫進行3D語義搜索。
在這次大會上,老黃先是回顧自己過去所做的“正確決定”——用AI重塑CG,為AI重新發明GPU。
隨後,他對未來AI行業的發展做大膽的展望:未來,幾乎所有事物的前方都會有一個大語言模型。“人”,將成為一種新的編程語言。
以工廠為例,老黃認為,未來的工廠將會由軟件和機器人來“主宰”。
像汽車這樣的產品,本身就是機器人,所以生產汽車的工廠,將會呈現出機器人制造機器人的場面。
看來,乘大模型東風迅速崛起的英偉達,這次是真的要ALL IN生成式AI。