“為計算和人類的未來,我捐出世界上第一臺DGX-1。”2016年8月,英偉達創始人黃仁勛,帶著一臺裝載8塊P100芯片的超級計算機DGX-1,來到OpenAI的辦公大樓。在現場人員到齊後,老黃拿出記號筆,在DGX-1的機箱上寫下這句話。

與其一同前往的還有特斯拉和 OpenAI 的創始人,埃隆馬斯克。

這次 OpenAI 之行,老黃不為別的,就是為把這臺剛出爐的超算送給 OpenAI ,給他們的人工智能項目研究加一波速。
這臺DGX-1價值超過百萬,是英偉達超過3000名員工,花費三年時間打造。
這臺 DGX-1 ,能把 OpenAI 一年的訓練時間,壓縮到短短一個月。
而這,是他對人工智能未來的豪賭,加的一波註。
七年之後,在前不久的 GTC 大會上,老黃穿著皮衣,拿著芯片,整個宣講不離 AI 。
似乎是在告訴各位, AI 的時代,我英偉達,就要稱王,當年的豪賭,他贏!

這麼說吧,在去年經歷一波礦難之後,不少人都以為曾靠著礦潮狂賺一筆的英偉達,會在礦難之下市值暴跌,一蹶不振。
但實際情況卻有點微妙……
英偉達的股價在跌大半年之後,從十月份開始,一路上漲,到現在,整個英偉達市值已經漲回到 6500 億美元,是 AMD 的 4 倍,英特爾的 6 倍。
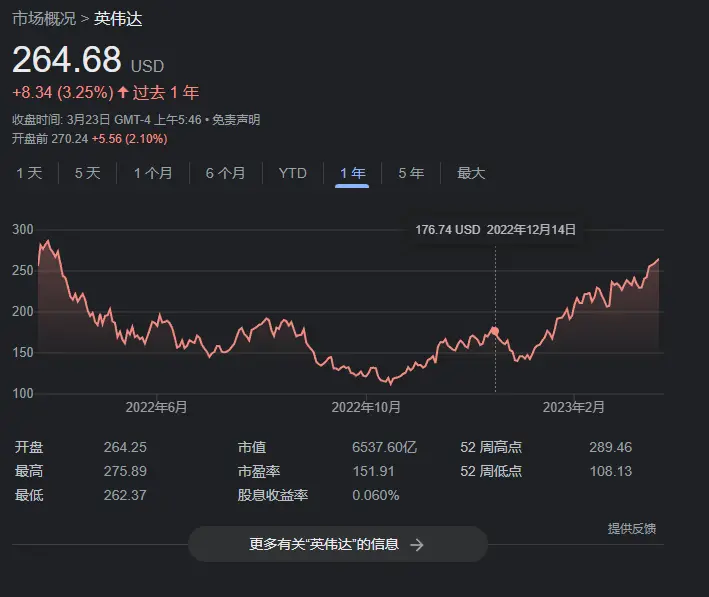
瞧瞧,這還是當年那個求著各位買顯卡的老黃嘛?
而讓英偉達的股價瘋漲的,那便是他們從十多年前就開始押註的 AI 計算。
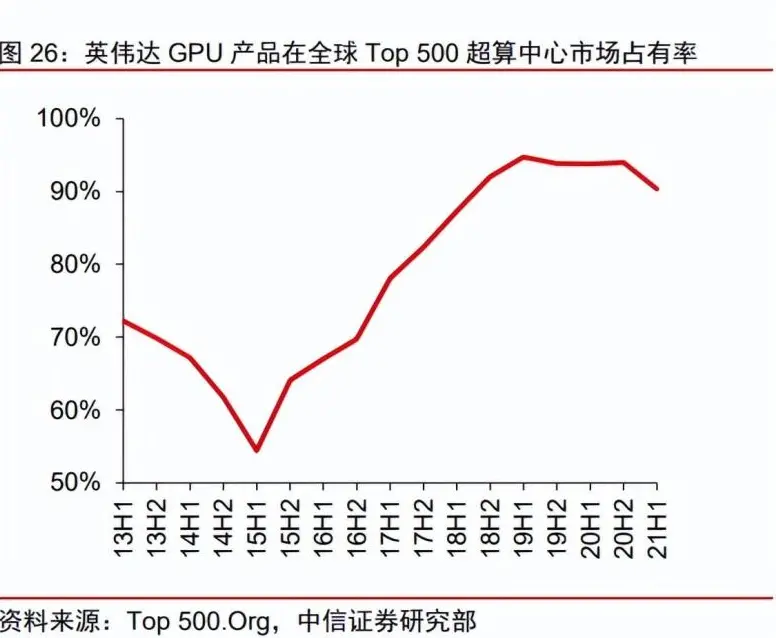
給大傢一個數據,從 15 年後,英偉達的 GPU 在超算中心的市場份額就一路上漲,這幾年穩居 90% 左右。
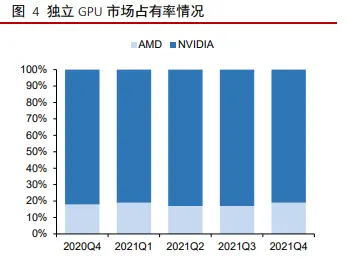
在獨立 GPU 市場上,英偉達的市場占有率也一度超過 80% 。
另外,包括 YouTube 、Cat Finder 、 AlphaGo 、 GPT-3 、 GPT-4 在內, AI 歷史上那些叫得出名的玩意,幾乎都是在英偉達的硬件上整出來的。
英偉達的硬件,仿佛就是新時代的內燃機,載著 AI 時代不斷前進。
差友們可能會有點疑問,為什麼在 AI 爆發的時代,好像就隻有老黃有好處,其它的顯卡生產商們的顯卡不能訓練 AI 嘛?
能訓練,但隻能訓練一點點。
為啥?
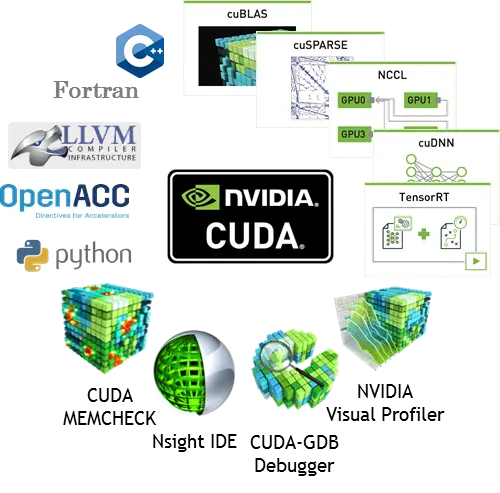
這就不得不提到英偉達從 2006 年就開始著手開發一個東西—— CUDA ( 統一計算設備架構 )。
差評君簡單解釋一下它是幹嘛的,當你想要計算一些比較龐大的運算問題時,通過 CUDA 編程,你就能充分利用 GPU 的並行處理能力,從而大幅提升計算性能。
差評君說一個聽來的比喻。
CPU 就好比是個數學教授, GPU 就是 100 個小學生,放一道高數題下來那 100 個小學生可能會懵逼;但是放 100 道四則口算題下來,那 100 個小學生同時做肯定比數學教授快多。

深度學習就是上面的例子中那 100 道口算題,那個讓 GPU 處理器並行運算的 “ 工具 ” 就叫 CUDA 。
一般來說,使用 CUDA 和不使用 CUDA ,兩者在計算速度上往往有數倍到數十倍的差距。
既然 CUDA 這麼有用,為什麼其它的 GPU 廠商不去搞個競品呢?
不是不去搞啊,而是他們真的沒想到!
在早期, GPU 的作用隻是為加速圖形渲染,各大廠商們認為它就是一個圖形專用計算芯片,並沒有想到把 GPU 用在其它通用計算方面。至於拿來做深度學習?以那個年代的 AI 能力,一是沒有太大的必要,二是也沒有人覺得它有用。

英偉達深度學習團隊的佈萊恩在聊到 CUDA 時這麼說道:
“ 在 CUDA 推出十年以來,整個華爾街一直在問英偉達,為什麼你們做這項投入,卻沒有人使用它?他們對我們的市值估值為 0 美元。 ”

不過說沒人用也是過於嚴重。
其實早在 2012 年,多倫多大學的 Alex Krizhevsky 就在 ImageNet 計算機視覺挑戰賽中,利用 GPU 驅動的深度學習擊敗其它對手,當時他們使用的顯卡是 GTX580 。

在這之後又經過 4 年,那些搞深度學習的人才突然意識到, GPU 的這種設計結構方式,在訓練 AI 的速度上,真的是 CPU 不能比的。
而擁有 CUDA 原生支持的英偉達 GPU ,更是首要之選。
到現在,資本們已經看到 AI 的重要之處,為什麼大傢都還在卷 AI 模型,而不去卷老黃的市場呢?
原因在於,它們已經很難再拿到 AI 加速芯片的入場券。在人工智能產業上,整個深度學習的框架已經是老黃的形狀。
AI 發展的數十年間,英偉達通過對 CUDA 開發和社區的持續投入, CUDA 和各類 AI 框架深度綁定。
當今使用排行靠前的各類 AI 框架,就沒有不支持 CUDA 的,也就是說你想要讓你的深度學習跑的快?買張支持 CUDA 的高性能卡是最好的選擇,說人話就是——買 N 卡吧。

當然,在 CUDA 大力發展期間,也有其它公司在嘗試著打破英偉達這種接近壟斷的局面。
2008 蘋果就提過出 OpenCL 規范,這是一個統一的開放 API ,旨在為各種不同的 GPU 型號提供一個規范,用以開發類似 CUDA 的通用計算軟件框架。
但是,通用就意味著不一定好用。

因為各大廠商 GPU 的型號繁而復雜,為適應各種硬件,驅動版本也多如牛毛,質量參差不齊。而且缺少對應的廠商進行針對性的優化,所以,無論是哪一個版本的 OpenCL ,在同等算力下,都比不過使用 CUDA 的速度。
而且恰恰是因為 OpenCL 的通用性,想要開發支持 OpenCL 的框架,要比開發CUDA 的復雜不少。原因還是同一個,缺少官方的支持,看看英偉達對CUDA開發的工具支持吧,CUDA Toolkit,NVIDIA GPU Computing SDK以及NSight等等。
OpenCL這邊,就略顯寒酸……
這就導致如今能支持 OpenCL 的深度學習框架寥寥無幾。
舉個很簡單的例子,當下最火的框架 PyTorch ,就連官方都沒有專門對OpenCL進行支持,還得靠著第三方開源項目才能用。
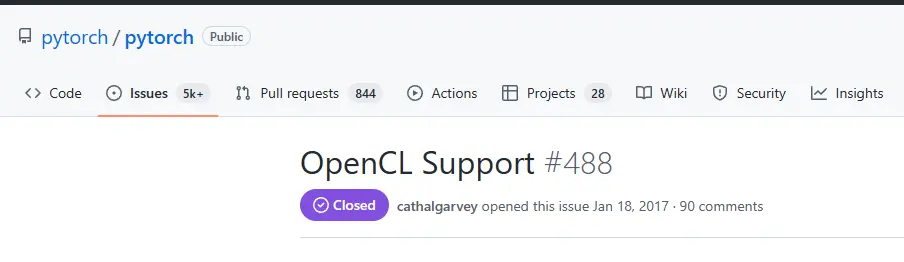
那同為顯卡供應商的 AMD ,在面對老黃如日中天的 CUDA 時,除 OpenCL ,有沒有自己的解決辦法呢?
方法確實是有,但效果也確實不咋的。
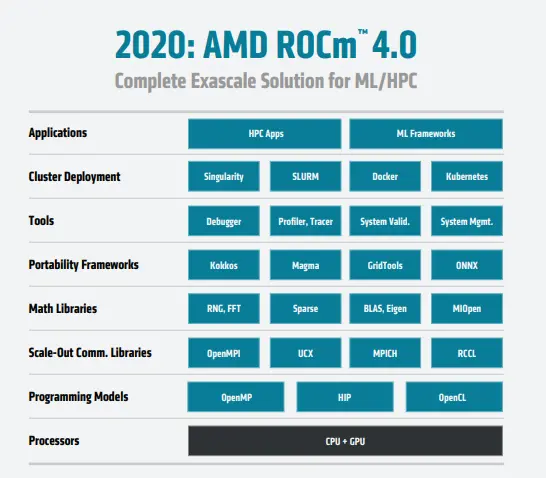
2016 年 AMD 發佈全新的開放計算平臺—— ROCm ,對標的就是英偉達的 CUDA ,最關鍵的一點是,它還在源碼級別上對 CUDA 程序進行支持。
你看,就算是老黃的死對頭 AMD ,想的也不是另起爐灶,而是降低自己適配 CUDA 的門檻……
但是,時至今日, ROCm 依然還是隻支持 Linux 平臺,可能也是用的人太少,有點擺爛的味道,畢竟,既然你支持 CUDA ,那我為什麼要費盡心力去給你的 ROCm 專門編寫一套支持框架呢?
同年,Google也有行動,但畢竟不是芯片制造商,Google隻是推出自己的 TPU 平臺,專門針對自傢的 TensorFlow 框架進行優化,當然原生支持的最好的也隻有 TensorFlow 。
至於英特爾那邊,也推出一個 OneAPI ,對標老黃的 CUDA ,不過由於起步較晚,現在還處於發展生態的環節,未來會怎樣還不太好說。
所以靠著先發優勢還有原生支持,導致現在的深度學習,基本上離不開英偉達的 GPU 和他的 CUDA 。
最近大火的 ChatGPT ,就用老黃的 HGX 主板和 A100 芯片,而老黃對此也是很有自信的說道:
“ 現在唯一可以實際處理 ChatGPT 的 GPU ,那就隻有我們傢的 HGX A100 。 ”
沒錯,沒有其它可用的,這就是老黃的有恃無恐。

而隨著 OpenAI 對大模型 AI 的成功驗證,各傢巨頭對大模型 AI 的紛紛入局,英偉達的卡已經立馬成搶手貨。

所以如今的 AI 創業公司,出現一件很有意思的現象,在他們的項目報告上,往往會搭上一句我們擁有多少塊英偉達的 A100 。
當大傢在 AI 行業紛紛投資淘金時,英偉達就這樣靠著給大傢賣水——提供 AI 加速卡,大賺特賺,關鍵還在於,隻有它賣的水能解渴。
因為它的硬件以及工具集,已經能影響到整個 AI 產業的戰局和發展速度。

更可怕的是,英偉達的優勢已經形成一種壁壘,這壁壘厚到就連全球第二大 GPU 廠商 AMD 都沒有辦法擊穿。
所以在 AI 大浪滔天的現在,能整出屬於自己的 AI 大模型固然重要,但差評君卻覺得,啥時候能有自己的英偉達和 CUDA 也同樣不可小覷。
當然,這條路也更難。

最後,差評君覺得在未來,我們需要抓緊突破的,絕對不隻是對人工智能大模型相關的研究,更為重要的是整個計算芯片的設計,制造,以及 AI 生態的建設。
新的工業革命已經到來, AI 技術的發展不僅加速人類生產力的發展,也加速那些落後產能的淘汰,現在各行各業都處在變革的前夕。
強者越強,弱者無用。雖然這句話很殘酷,但在AI 領域,如果不奮力追上,可能真的已經不需要 “ 弱者 ” 。