生成式AI的時代已經來臨,屬於它的iPhone時刻到!就在8月8日,英偉達CEO黃仁勛,再次登上世界頂級計算機圖形學會議SIGGRAPH的舞臺。一系列重磅更新接踵而至——下一代GH200超級芯片平臺、AIWorkbench、OpenUSD……

而英偉達也借此將過去這數十年的所有創新,比如人工智能、虛擬世界、加速、模擬、協作等等,全部融合到一起。
在這個時代裡,或許正如老黃的經典名言:“買得越多,省得越多!”
英偉達最強AI超算再升級
在5年前的SIGGRAPH上,英偉達通過將人工智能和實時光線追蹤技術引入GPU,重新定義計算機圖形學。
老黃表示:“當我們通過AI重新定義計算機圖形學時,我們也在為AI全面重新定義GPU。”
隨之而來的,便是日益強大的計算系統。比如,集成8個GPU並擁有1萬億個晶體管的HGX H100。

就在今天,老黃再次讓AI計算上一個臺階——
除為GH200配備更加先進的HBM3e內存外,下一代GH200 Grace Hopper超級芯片平臺還將具有連接多個GPU的能力,從而實現卓越的性能和易於擴展的服務器設計。
而這個擁有多種配置的全新平臺,將能夠處理世界上最復雜的生成式工作負載,包括大語言模型、推薦系統和向量數據庫等等。
比如,雙核心方案就包括一臺配備144個Arm Neoverse核心並搭載282GB HBM3e內存的服務器,可以提供8 petaflops的AI算力。
其中,全新的HBM3e內存要比當前的HBM3快50%。而10TB/sec的組合帶寬,也使得新平臺可以運行比上一版本大3.5倍的模型,同時通過3倍更快的內存帶寬提高性能。
據悉,該產品預計將在2024年第二季度推出。

RTX工作站:絕佳刀法,4款顯卡齊上新
這次老黃的桌面AI工作站GPU系列也全面上新,一口氣推出4款新品:RTX 6000、RTX 5000、RTX 4500和RTX 4000。
如果H100以及配套的產品線展示的是英偉達的GPU性能的天際線的話,針對桌面和數據中心推出的這幾款產品,則是老黃對成本敏感客戶秀出自己“刀法”的絕佳機會。

在發佈這新GPU的時候,現場還出現一個意外的小花絮。
老黃從後臺拿出第一塊GPU的時候,不知道是自己不小心,還是因為其他工作人員的失誤,顯卡鏡面面板上占指紋。
老黃立馬就發現指紋,覺得可能是自己搞砸,就很不好意思的和現場觀眾對不起,說這次產品發佈可能是有史以來最差的一次。
看來就算開發佈會熟練如老黃,沒準備好也是會翻船的。
可愛的老黃惹得在場觀眾不斷發笑。

言歸正傳,作為旗艦級專業卡,RTX 6000的性能參數毫無疑問是4款新品中最強的。
憑借著48GB的顯存,18176個CUDA核心,568個Tensor核心,142個RT核心,和高達960GB/s的帶寬一騎絕塵。
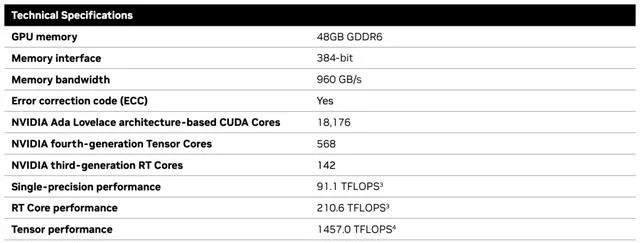
RTX 5000配備32GB顯存,12800個CUDA核心,400個Tensor核心,100個RT核心,300W的功耗。
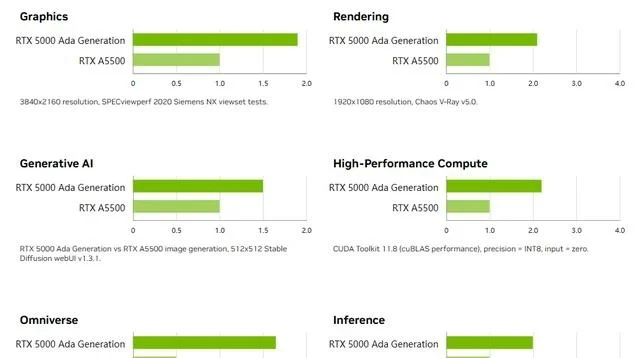
RTX 4500配備24GB顯存,7680個CUDA核心,240個Tensor核心,60個RT核心。

RTX 4000配備20GB顯存,6144個CUDA核心,192個Tensor核心,48個RT核心。
基於新發佈的4張新的GPU,針對企業客戶,老黃還準備一套一站式解決方案—— RTX Workstation。

支持最多4張RTX 6000GPU,可以在15小時內完成860M token的GPT3-40B的微調。
Stable Diffusion XL每分鐘可以生成40張圖片,比4090快5倍。
OVX服務器:搭載L40S,性能小勝A100
而專為搭建數據中心而設計的L40S GPU,性能就更加爆炸。

基於Ada Lovelace架構的L40S,配備有48GB的GDDR6顯存和846GB/s的帶寬。
在第四代Tensor核心和FP8 Transformer引擎的加持下,可以提供超過1.45 petaflops的張量處理能力。
對於算力要求較高的任務,L40S的18,176個CUDA核心可以提供近5倍於A100的單精度浮點(FP32)性能,從而加速復雜計算和數據密集型分析。
此外,為支持如實時渲染、產品設計和3D內容創建等專業視覺處理工作,英偉達還為L40S 還配備142個第三代RT核心,可以提供212 teraflops的光線追蹤性能。功耗同時也達到350瓦。
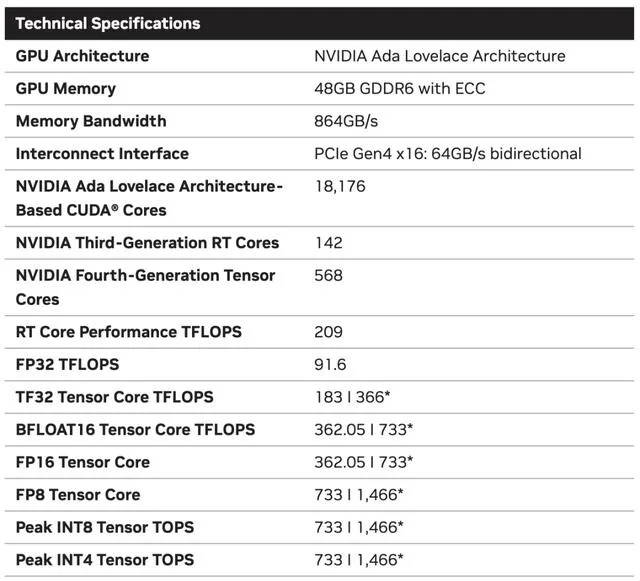
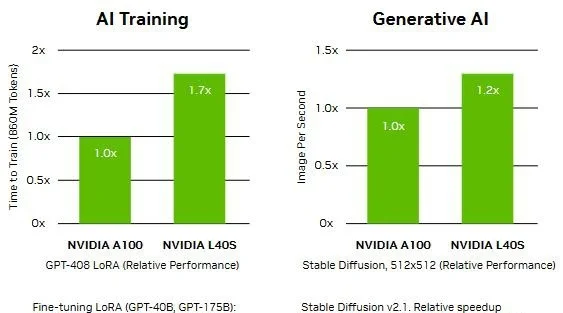
對於具有數十億參數和多種模態的生成式AI工作負載,L40S相較於老前輩A100可實現高達1.2倍的推理性能提升,以及高達1.7倍的訓練性能提升。
在L40S GPU的加持下,老黃又針對數據中心市場,推出最多可搭載8張L40S的OVX服務器。

對於擁有8.6億token的GPT3-40B模型,OVX服務器隻需7個小時就能完成微調。
對於Stable Diffusion XL模型,則可實現每分鐘80張的圖像生成。

AI Workbench:加速定制生成式AI應用
除各種強大的硬件之外,老黃還重磅發佈全新的NVIDIA AI Workbench來幫助開發和部署生成式AI模型。
概括來說,AI Workbench為開發者提供一個統一且易於使用的工具包,能夠快速在PC或工作站上創建、測試和微調模型,並無縫擴展到幾乎任何數據中心、公有雲或NVIDIA DGX Cloud上。
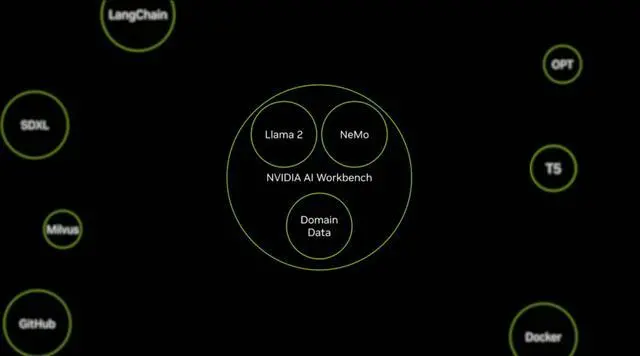
具體而言,AI Workbench的優勢如下:
-易於使用
AI Workbench通過提供一個單一的平臺來管理數據、模型和計算資源,簡化開發過程,支持跨機器和環境的協作。
- 集成AI開發工具和存儲庫
AI Workbench與GitHub、NVIDIA NGC、Hugging Face等服務集成,開發者可以使用JupyterLab和VS Code等工具,並在不同平臺和基礎設施上進行開發。
- 增強協作
AI Workbench采用的是以項目為中心的架構,便於開發者進行自動化版本控制、容器管理和處理機密信息等復雜任務,同時也可以支持團隊之間的協作。
- 訪問加速計算資源
AI Workbench部署采用客戶端-服務器模式。團隊可以現在在本地計算資源上進行開發,然後在訓練任務變得更大時切換到數據中心或雲資源上。
Stable Diffusion XL自定義圖像生成
首先,打開AI Workbench並克隆一個存儲庫。
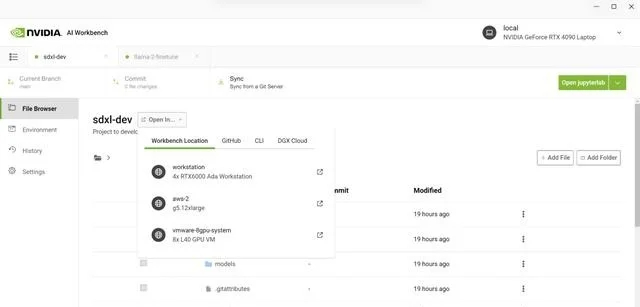
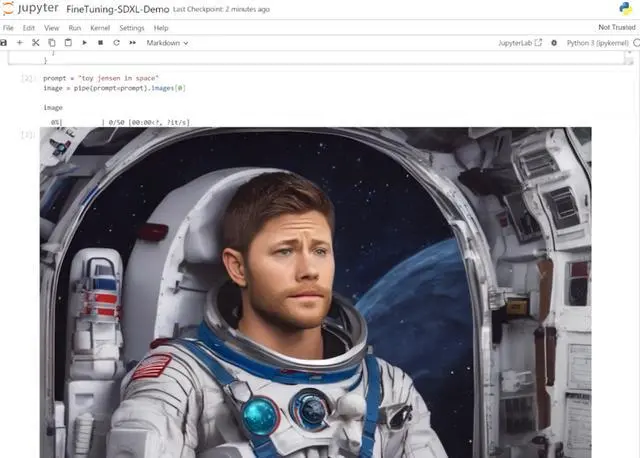
接下來,在Jupyter Notebook中,從Hugging Face加載預訓練的Stable Diffusion XL模型,並要求它生成一個“太空中的Toy Jensen”。
然而,根據輸出的圖像可以看出,模型並不知道Toy Jensen是誰。
這時就可以通過DreamBooth,並使用8張Toy Jensen的圖片對模型進行微調。
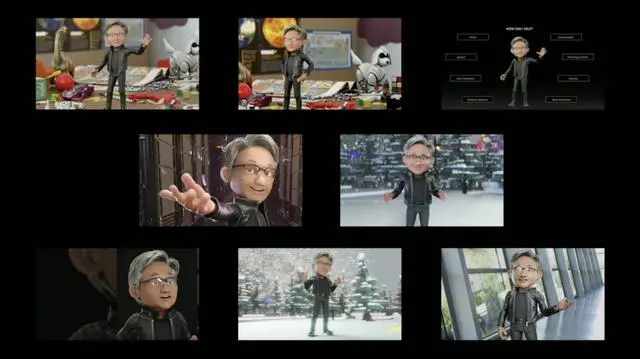
最後,在用戶界面上重新運行推理。
現在,知道Toy Jensen的模型,就可以生成切合需求的圖像。
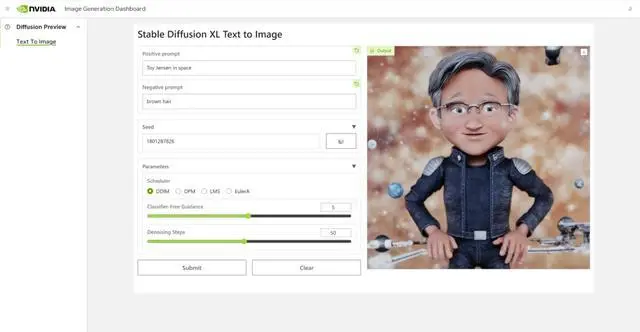
Hugging Face一鍵訪問最強算力
作為最受AI開發者喜愛的平臺之一,擁有200萬用戶、超25萬個模型,以及5萬個數據集的Hugging Face,這次也與英偉達成功達成合作。
現在,開發者可以通過Hugging Face平臺直接獲得英偉達DGX Cloud AI超算的加持,從而更加高效地完成AI模型的訓練和微調。
其中,每個DGX Cloud實例都配備有8個H100或A100 80GB GPU,每個節點共有640GB顯存,可滿足頂級AI工作負載的性能要求。
此外,作為合作的一部分,Hugging Face還將提供一個名為“Training Cluster as a Service”的全新服務,從而簡化企業創建新的和定制的生成式AI模型的過程。
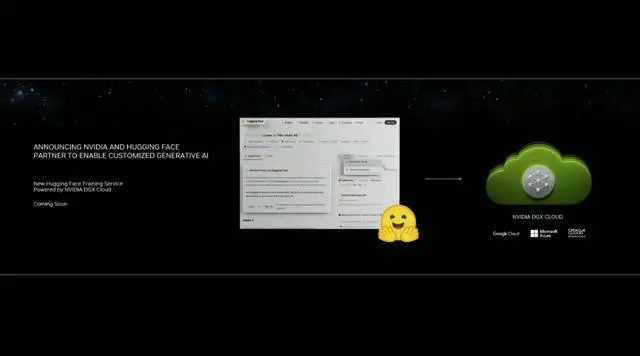
老黃激動得表示:“Hugging Face和英偉達將世界上最大的AI社區與全球領先的雲AI計算平臺連接在一起。用戶隻需點擊一下,即可訪問NVIDIA最強的AI算力。”
AI Enterprise 4.0:定制企業級生成式AI
為進一步加速生成式AI的應用,英偉達也將其企業級平臺AI Enterprise升級到4.0版本。
目前,AI Enterprise 4.0不僅可以為企業提供生成式AI所需的工具,同時還提供生產部署所需的安全性和API穩定性。

- NVIDIA NeMo
一個用於構建、定制和部署大語言模型的雲原生框架。借助NeMo,英偉達AI Enterprise可以為創建和定制大語言模型應用提供端到端的支持。
- NVIDIA Triton管理服務
幫助企業進行自動化和優化生產部署,使其在Kubernetes中能夠自動部署多個推理服務器實例,並通過模型協調實現可擴展A 的高效運行。
- NVIDIA Base Command Manager Essentials集群管理軟件
幫助企業在數據中心、多雲和混合雲環境中最大化AI服務器的性能和利用率。
除英偉達自己,AI Enterprise 4.0還將集成到給其他的合作夥伴,比如Google Cloud和Microsoft Azure等。
此外,MLOps提供商,包括Azure Machine Learning、ClearML、Domino Data Lab、Run:AI和Weights & Biases,也將與英偉達AI平臺進行無縫集成,從而簡化生成式AI模型的開發。
Omniverse:在元宇宙中加入大語言模型
最後,是英偉達Omniverse平臺的更新。
在接入OpenUSD和AIGC工具之後,開發者可以更加輕松地生成模擬真實世界的3D場景和圖形。
就像它的名字一樣,Omniverse的定位是一個集合各種工具的3D圖形制作協作平臺。
3D開發者可以像文字編輯們在飛書或者釘釘中一樣,在Omniverse上共同制作3D圖形和場景。
而且可以將不同的3D制作工具制作出來的成果直接整合在Omniverse之內,將3D圖形和場景的制作工作流徹底打通,化繁為簡。
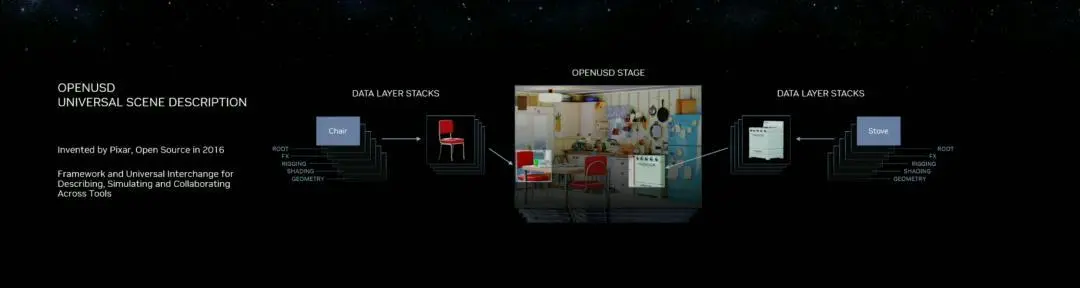
OpenUSD
而這次更新中,接入的OpenUSD是什麼東西?

OpenUSD(Universal Scene Description)提供一個開源,通用的場景描述格式,使不同品牌、不同類型的3D設計軟件可以無障礙的協作。
Omnivers本身就是建立在USD體系之上的,這次Omniverse針對OpenUSD的升級,使得Omniverse能為開發者,企業推出更多的框架和資源服務。

基於OpenUSD這個開源的3D圖像編輯格式,5傢公司(蘋果,皮克斯,Adobe,Autodesk,英偉達)成立AOUSD聯盟,進一步推動3D圖像業界采用OpenUSD格式。
而且,借助AOUSD聯盟的成立,Omniverse的開發者也可以方便的創建各種兼容於蘋果的ARKit或者是RealityKit的素材和內容,更新後Omniverse也支持OpenXR的標準,使得Omniverse能夠支持HTC VIVE,Magic Leap,Vajio等VR頭顯設備。

API,ChatUSD和其他更新
此外,英偉達還發佈新的Omniverse Cloud API,讓開發者可以更加無縫地部署OpenUSD管線和應用程序。
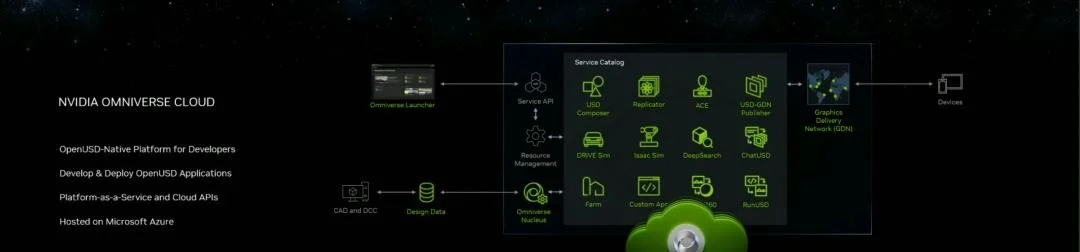
而最引人矚目的,就是支持基於大語言模型的ChatUSD的支持。
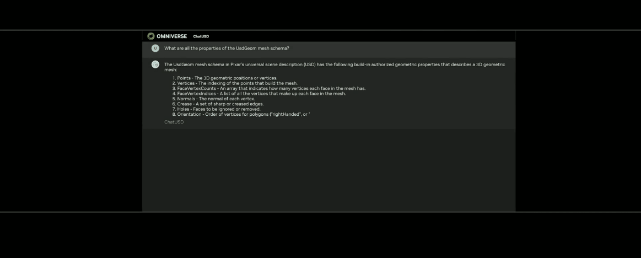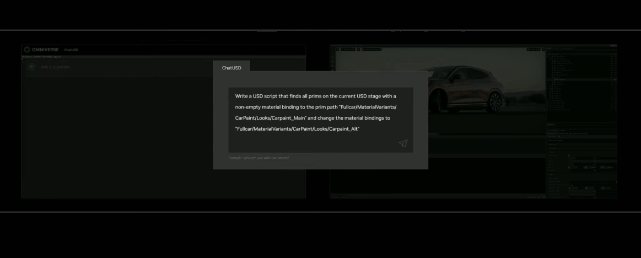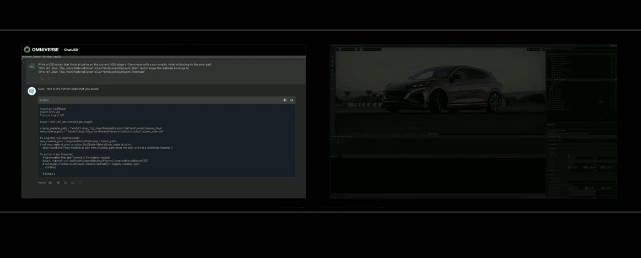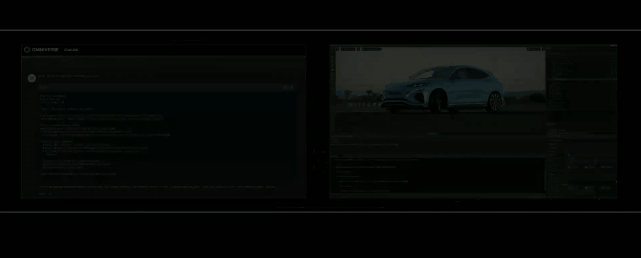
基於大語言模型技術的ChatUSD能像Github Copilot一樣,在Omniverse平臺中回答開發者的相關問題,或者自動生成Python-USD的代碼,讓開發人員效率暴增。
總而言之,英偉達再次用暴力的產品,令人驚嘆的技術,高瞻遠矚的洞見,讓全世界再次看到,它未來將如何引領世界AI和圖形計算的新浪潮。
在老黃的經典名言“the more you buy,the more you save!”中,老黃緩緩走下舞臺,卻把現場氣氛推向最高潮。