Meta周二(5月9日)宣佈一個新的開源人工智能(AI)模型ImageBind,該模型可以將六種類型的數據流聯系在一起。ImageBind以視覺(圖片和視頻)為核心,結合文本、聲音、3D深度、溫度、運動讀數(IMU),最終可以做到在六個模態之間的任意轉換。
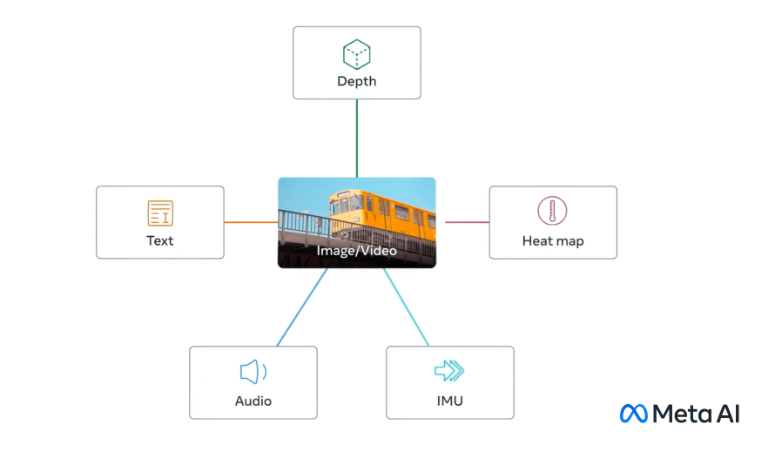
ImageBind為機器提供一個整體的理解,將照片中的物體與它們的聲音、3D形狀、冷暖程度、以及它們的移動方式聯系起來。
Meta稱,ImageBind使機器能夠更同步、更全面、更直接地從不同信息形式中學習,進一步向人類靠攏。
AI的未來
該研究的核心概念是將多種類型的數據連接到一個嵌入空間(Embedding Space)中,正是這個概念支撐著最近生成式AI的蓬勃發展。
例如,Meta的AI圖像生成器Make-A-Scene可以在ImageBind模型的支持下,從音頻中創建圖像,例如根據雨林或熙熙攘攘的市場的聲音創建圖像。
ImageBind還可以提供一種豐富的方式來探索記憶,也就是使用文本、音頻和圖像的組合來搜索相關信息。
此外,ImageBind為研究人員開發新的整體系統提供思路,例如結合3D和IMU傳感器來設計或體驗沉浸式虛擬世界。這不就是Meta一直以來追求的“元宇宙”嗎?
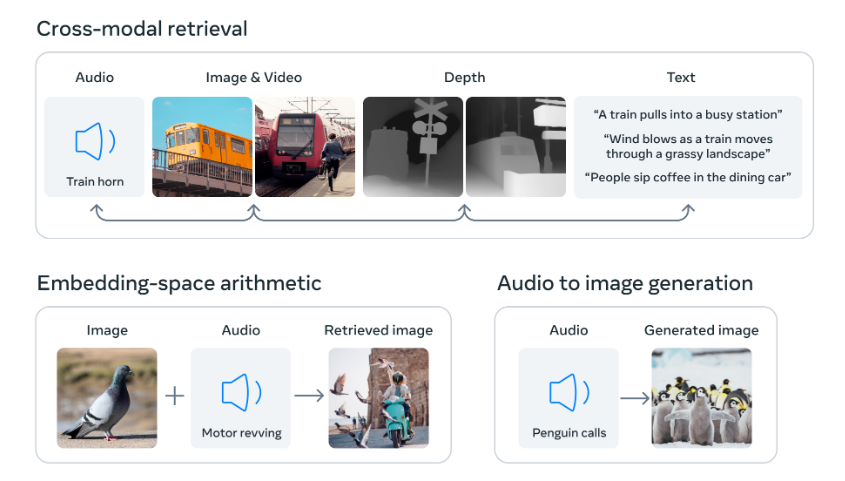
上圖是Meta在一篇博客文章中給出的案例:當輸入一段企鵝的叫聲後,ImageBind能生成企鵝的圖片;當輸入鴿子的照片和一段汽車轟鳴聲後,ImageBind能生成一張“人開車驚動鴿群”的照片;ImageBind還可以根據一段火車的音頻,生成火車的照片、相關的火車3D模型、以及一段形容火車車站的文本。
該模型目前還隻是一個研究項目,沒有直接的消費者或實際應用,不過它這種交叉引用數據的模型指明生成式AI系統的未來,因為它可以創造身臨其境的多感官體驗。
Meta在博客文章中指出,其他感官輸入流也可能會被添加到未來的模型中,包括“觸覺、聽覺、嗅覺和大腦功能磁共振成像信號”。
想象一下,在未來的一臺設備上,你可以讓它模擬一次漫長的海上航行,它不僅會讓你置身於一艘以海浪為背景聲音的船上,還會讓你感受到腳下甲板的搖晃和海上空氣的涼爽。
開源與限制
當然,這一切都是推測的,而且像這樣的研究的直接應用可能會受到更多的限制。
然而,對於行業觀察者來說,這項研究很有趣,因為Meta已將其ImageBind的代碼開源,這一做法在AI領域受到愈發嚴格的審查。
OpenAI等反對開源的行業人士稱,這種做法對創造者有害,因為競爭對手可以復制他們的作品,而且這種做法可能存在潛在危險,允許惡意行為者利用最先進的人工智能模型。
不過開源的支持者反擊道,開源本質上是允許第三方開發人員作為無償員工來對模型進行改進,從而進一步產生商業效益。迄今為止,Meta一直堅定地站在開源陣營。