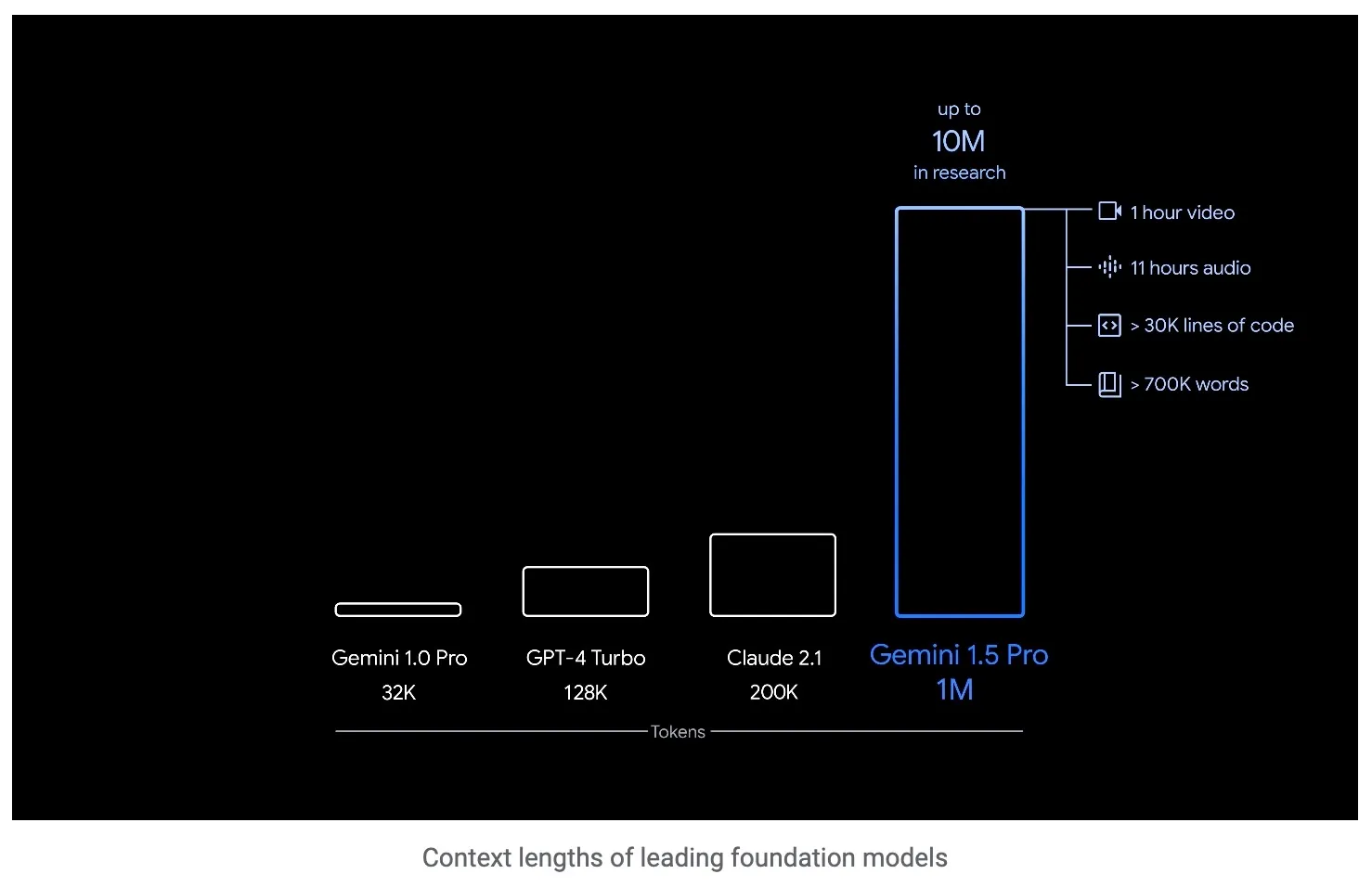
4月10日消息,谷歌升級大語言模型Gemini1.5Pro,為其配備“耳朵”,使其能夠監聽並分析上傳的音頻文件,從財報電話會議或視頻音頻中提取關鍵信息,無需轉為書面材料。在美國時間周二舉辦的GoogleNext大會上,谷歌宣佈,通過其人工智能應用開發平臺VertexAI,將Gemini1.5Pro首次對外開放。該模型最初於今年2月亮相。
Gemini 1.5 Pro被視為Gemini傢族中的“中量級”(middle-weight)模型,其性能已經超越最大規模、最強大的Gemini Ultra。谷歌表示,Gemini 1.5 Pro能夠理解復雜指令,而且使用時無需對模型進行特別調整。
需要指出的是,不通過Vertex AI的用戶無法體驗到Gemini 1.5 Pro的全部功能。目前,大眾主要通過Gemini聊天機器人與Gemini大語言模型互動。盡管GeminiUltra為Gemini Advanced聊天機器人提供強大支持,能理解較長的指令,但在反應速度上不及Gemini 1.5 Pro。
除Gemini 1.5 Pro的更新,谷歌還對其它大型人工智能模型進行升級。特別是作為文本轉圖像生成模型的Imagen 2,它增強Gemini的圖像生成能力。通過引入圖像外延(Outpainting)和內填(Inpainting)功能,用戶現在能更靈活地對圖像的元素進行添加或刪除。
為確保Imagen模型生成的圖片版權和來源可追溯,谷歌為所有生成圖片加入SynthID數字水印技術。這種創新技術通過幾乎不可見的水印明確標識圖片來源,可以通過專用工具進行檢測。
Imagen模型的許多新特性,如圖像外延和內填技術,已被其他文本轉圖像模型采用,例如Stability AI的Stable Cascade和Getty的Generative AI by iStock。此外,這些技術也被廣泛應用於消費電子產品中,如三星Galaxy手機。
除圖像生成的創新外,谷歌還公開展示一種結合人工智能生成回答和谷歌搜索結果的方法,旨在為用戶提供更實時、更準確的信息。然而,大語言模型生成的回答並非總是精準無誤,有時可能會誤導用戶。因此,谷歌對Gemini模型設置一些限制,比如禁止回答與2024年美國大選相關的問題。
此前,Gemini模型因在生成歷史人物描述時出現不準確而受到批評。