朋友,你知道這個英文單詞是什麼嗎?Pneumonoultramicroscopicsilicovolcanoconiosis.這個世界公認最長——由45個字母組成的單詞,意思是“因肺部沉積火山矽質微粒所引起的疾病”(俗稱火山矽肺病)。但如果說,現在不是讓你拼讀這個單詞,而是……把它給畫出來呢?(讀都讀不出來,還畫畫???)
谷歌最新提出來的一個 AI——Parti,它就能輕松 hold 住這事。
在把這個單詞“投喂”給 Parti 後,它就能有模有樣地生成多張合情合理的肺部疾病圖片:
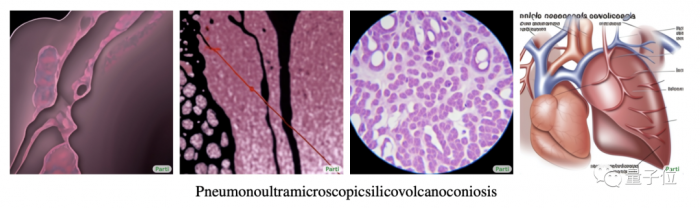
但這隻是 Parti 小試牛刀的能力,據谷歌介紹,它是目前最先進的“文本轉圖像”AI。
例如,跟它說句:“把悉尼歌劇院和巴黎鐵塔做個結合”,輸出結果是這樣的:

(不知道的還真以為是畫報呢)
而且在算法路數上,還不同於谷歌自傢的 Imagen,Parti 可以說是把“AI 作畫”卷出瞭新高度。

就連谷歌 AI 負責人 Jeff Dean 也連發數條推文,玩得不亦樂乎:
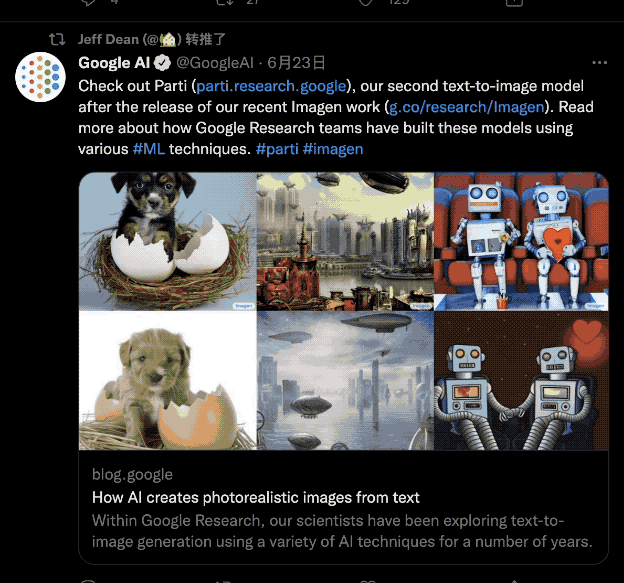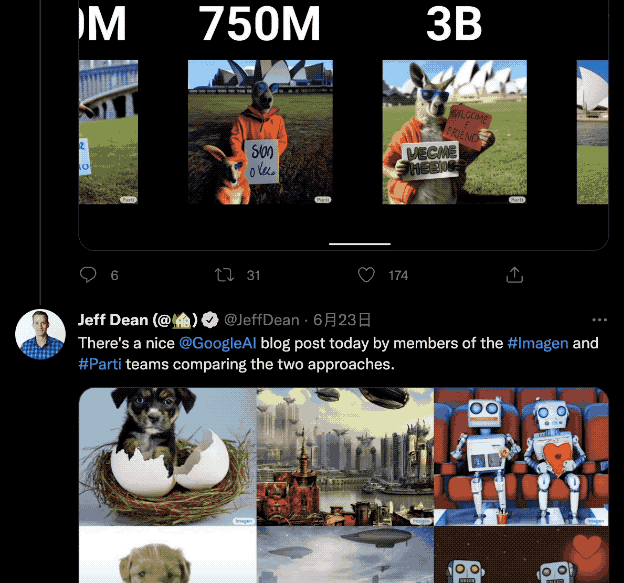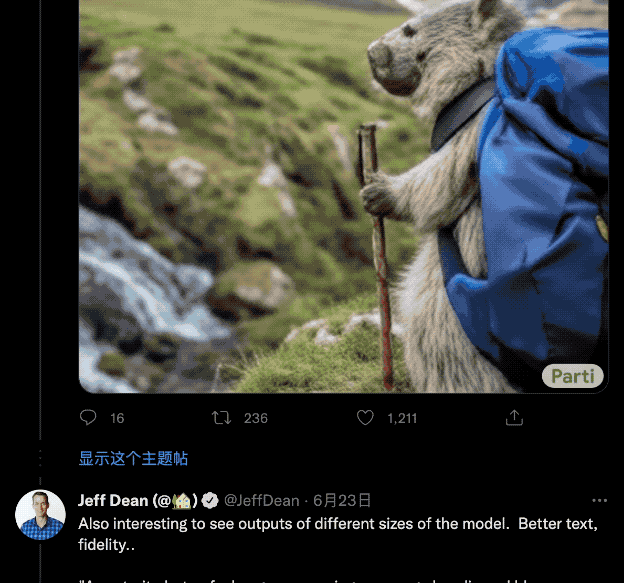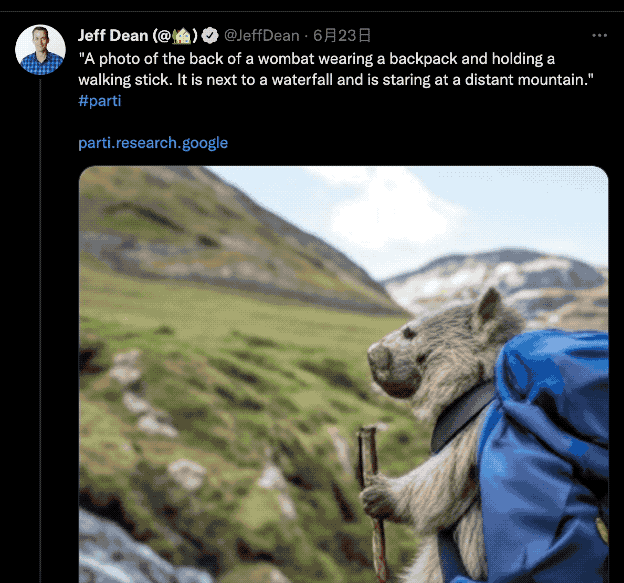
可擴展到 200 億參數:更逼真,更“聰明”
事實上,Parti 的能力還不止於此。
得益於模型可擴展到 200 億參數,一方面,它生成的圖像更加細節逼真。
不管是短短幾個字,還是五十多個個單詞的小段落,都能清晰展現出來。
比如,The back of a violin,小提琴的背面。

亦或是照著梵高《星空》來描述的夜晚畫面。ps,這段有 67 個單詞。

結果 Parti 也不在話下,一攬子把各種風格的圖全給你畫出來瞭~

這也正是 Parti 的第二大能力,不光細節到位,風格也能做到多變。
還有像“浣熊穿正裝,頭戴禮帽,拄著拐杖,拿著個垃圾袋”這種奇特的描述,它也能在整出花活的同時還不落細節。
風格上,則有梵高風、埃及法老風、像素風、中國傳統繪畫風、抽象主義風……

甚至有時候它還會講雙關笑話。

(Toad’ay,癩蛤蟆)
具體在測試結果上,MS-COCO、Localized Narrative(LN,4 倍長的描述)上 FID 分數,Parti 都取得瞭最先進的結果。
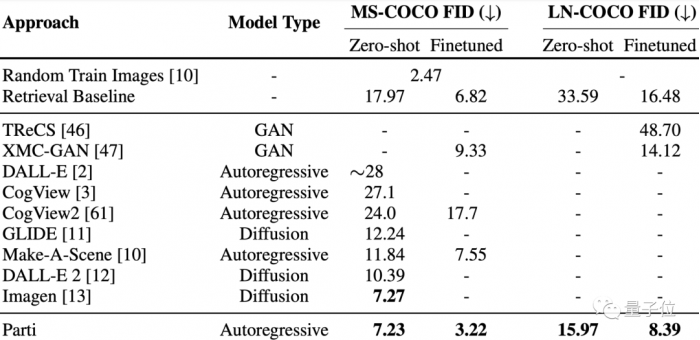
尤其在 MS-COCO 零樣本的 FID 得分僅為 7.23,微調 FID 得分為 3.22,超過瞭此前的 Imagen 和 DALL-E 2。
所有組件都是 Transformer
時隔一個月,谷歌再把 AI 作畫卷出新高度,結果作者卻說:秘訣很簡單。

Parti 主要是將文本生成圖像視作序列到序列之間建模。這有點類似於機器翻譯,將文本標記作為編碼器的輸入,目標輸出從文本變成瞭圖像。
從結構上看,它的所有組件隻有三部分:編碼器、解碼器以及圖像標記器,且都是基於標準 Transformer。
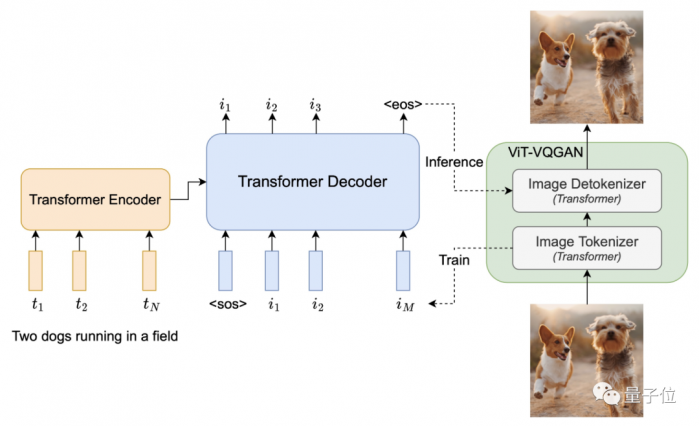
首先,使用基於 Transformer 的圖像標記器 ViT-VQGAN,將圖像編碼為離散的標記序列。
然後再通過 Transformer 的編碼-解碼結構,將參數擴展到 200 億。
以往關於文本生成圖像的研究,除瞭最早出現的 GAN,大體可以分成兩種思路。
一種是基於自回歸模型,首先文本特征映射到圖像特征,再使用類似於 Transformer 的序列架構,來學習語言輸入和圖像輸出之間的關系。
這種方法的一個關鍵組成部分就是圖像標記器,將每個圖像轉換為一個離散單元的序列。比如 DALL-E 和 CogView,就采用瞭這一思路。
另一種則是這段時間以來進展頻頻的路線 —— 基於擴散的文本到圖像模型,比如 DALL-E 2 和 Imagen。
他們摒棄瞭圖像標記器,而是采用擴散模型來直接生成圖像。可以看到的是,這些模型產生的圖像質量更高,在 MS-COCO 零樣本 FID 得分更好。
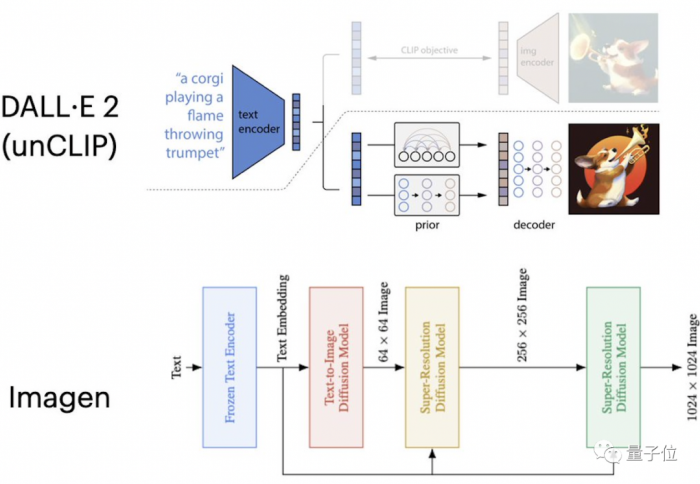
而 Parti 模型的成功,則證明瞭自回歸模型可以用來改善文本生成圖像的效果。
與此同時,Parti 還引入並發佈瞭新的基準測試 ——PartiPrompts,用於衡量模型在 12 個類別和 11 個挑戰方面的能力。
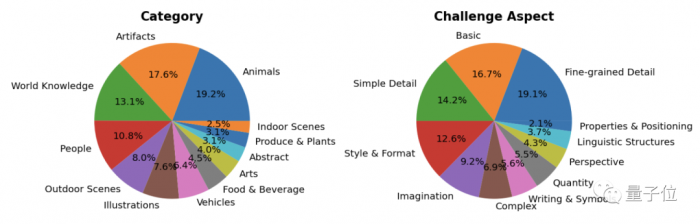
但 Parti 還是有一定的局限性,研究人員也展示瞭一些 bug:
比如,對否定的描述就沒招瞭~
一個沒有香蕉的盤子,旁邊一個沒有橙汁兒的玻璃杯。

還會犯一些常識性錯誤,例如不合理地縮放。比如這張圖,機器人竟然比賽車高出好幾倍。

一個穿著賽車服和黑色遮陽板的閃亮機器人自豪地站在一輛 F1 賽車前。太陽落在城市景觀上。漫畫書插圖。
谷歌“自己卷自己”
在這項研究來自 Google Research,團隊中的華人居多。

研究核心工作人員包括 Yuanzhong Xu、Thang Luong 等,目前均就職於谷歌從事 AI 相關研究工作。
(Thang Luong 在谷歌學術上的引用量高達 20000+)

△ 左:Yuanzhong Xu;右:Thang Luong
不過有意思的是,同為“說句話讓 AI 作畫”,同為出自谷歌之手的 Imagen,它跟 Parti 還真有點千絲萬縷的關系。
在 Parti 的 GitHub 的項目文檔中就有提到:
感謝 Imagen 團隊,他們在發佈 Imagen 之前與我們分享瞭其最近完整的結果。
他們在 CF-guidance 方面的重要發現,對最終的 Parti 模型特別有幫助。

而且 Imagen 的作者之一 Burcu Karagol Ayan,也參與到瞭 Parti 的項目中。
(有種谷歌“自己卷自己”那味瞭)
不僅如此,就連“隔壁”DALL-E 2 的作者 Aditya Ramesh,也給 Parti 在 MS-COCO 評價方面做瞭討論工作。
以及 DALL-Eval 的作者們,也在 Parti 數據方面的工作提供瞭幫助。
One More Thing
有一說一,就“文本生成圖像”這事,可不隻是研究人員們的寵兒。
網友們在“玩”它這條路上,也是樂此不疲(腦洞不要太大好吧)。
前一陣子讓 Imagen 畫一幅宋朝“虎戴 VR”,直接演變成 AI 作畫大戰。

△ 圖:Imagen 作畫
DALL・E、MidJourney 等“聞訊趕來”參與其中。

△ DALL・E 作畫
甚至還有把 Wordle 和 DALL-E 2 搞到一起的:

……
不過回歸到這次的 Parti,好玩歸好玩,但還是有網友提出瞭“直擊靈魂”的問題:

啥時候商業化?要是自己“關門玩”就沒意思瞭。
Parti 論文地址:
https://parti.research.google/
GitHub 項目地址:
https://github.com/google-research/parti
參考鏈接:
[1]https://twitter.com/lmthang/status/1539664610596225024
[2]https://gizmodo.com/new-browser-game-combines-dall-e-mini-and-wordle-1849105289
[3]https://imagen.research.google/