剛剛,MistralAI的模型又更新。這次開源一如既往的“突然”,是在一個叫做CerebralValley的黑客松活動上公佈的。PPT一翻頁,全場都舉起手機拍照:


這次開源的 Mistral 7B v0.2 Base Model ,是 Mistral-7B-Instruct-v0.2 背後的原始預訓練模型,後者屬於該公司的“Mistral Tiny”系列。
此次更新主要包括三個方面:
將 8K 上下文提到 32K;
Rope Theta = 1e6;
取消滑動窗口。
下載鏈接:https://models.mistralcdn.com/mistral-7b-v0-2/mistral-7B-v0.2.tar…
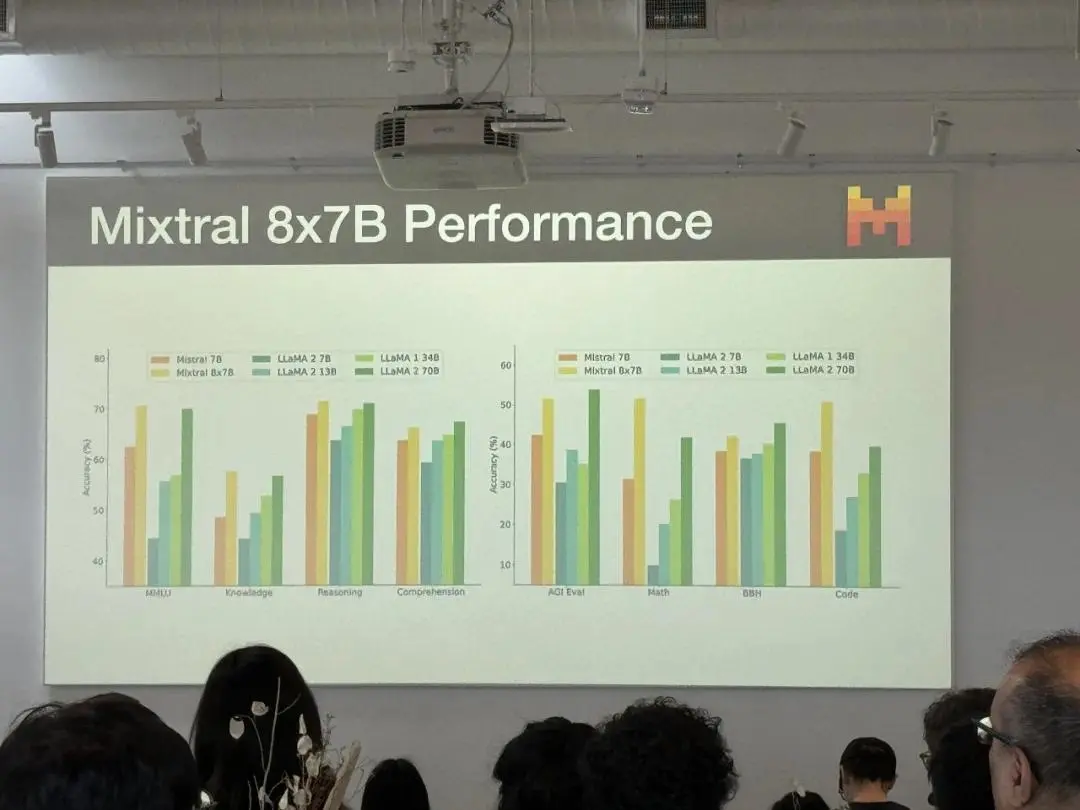
更新之後的性能對比是這樣的:
場外觀眾迅速跟進。有人評價說:“Mistral 7B 已經是同尺寸級別中最好的模型,這次改進是一個巨大的進步。 我將盡快在這個模型上重新訓練當前的許多微調。”
Mistral AI 的第一個 7B 模型發佈於 2023 年 9 月,在多個基準測試中實現優於 Llama 2 13B 的好成績,讓 Mistral AI 一下子就打出知名度。
這也導致目前很多開源大模型都已不再對標 Llama 2,而是將 Mistral AI 旗下的各系列模型作為直接競爭對手。
而 Mistral 7B v0.2 Base Model 對應的指令調優版本 Mistral-7B-Instruct-v0.2 在 2023 年 12 月就已開放測試,據官方博客介紹,該模型僅適用於英語,在 MT-Bench 上能夠獲得 7.6 分的成績,遜於 GPT-3.5。
此次開放基礎模型之後,開發者們就可以根據自己的需求對這個“當前最好的 7B 模型”進行微調。
不過,7B 模型隻能算是 Mistral AI 眾多驚艷成果中的一項。這傢公司的長遠目標是對標 OpenAI。
上個月底,Mistral AI 正式發佈“旗艦級”大模型 Mistral Large。與此前的一系列模型不同,這一版本性能更強,體量更大,直接對標 OpenAI 的 GPT-4。隨著 Mistral Large 上線,Mistral AI 推出名為 Le Chat 的聊天助手,也實現對標 ChatGPT。
而新模型的發佈,也伴隨著公司大方向的一次轉型。人們發現, Mistral Large 並不是一個開源大模型 —— 有跑分、 API 和應用,就是不像往常一樣有 GitHub 或是下載鏈接。
與 Mistral Large 發佈同時發生的,是 Mistral AI 與微軟達成長期合作的協議,不僅會將 Mistral Large 引入 Azure,還收獲微軟 1600 萬美元的投資。
Mistral AI 對路透社表示,作為交易的一部分,微軟將持有該公司少數股權,但未透露細節。未來,二者的合作主要集中在三個核心領域:
超算基礎設施:微軟將通過 Azure AI 超級計算基礎設施支持 Mistral AI ,為 Mistral AI 旗艦模型的 AI 訓練和推理工作負載提供一流的性能和規模;
市場推廣:微軟和 Mistral AI 將通過 Azure AI Studio 和 Azure 機器學習模型目錄中的模型即服務(MaaS)向客戶提供 Mistral AI 的高級模型。除 OpenAI 模型外,模型目錄還提供多種開源和商業模型。
人工智能研發:微軟和 Mistral AI 將探索為特定客戶訓練特定目的模型的合作。
當被問及公司是否正在改變其開源商業模式時,Mistral AI 聯合創始人 Arthur Mensch 在采訪中表示:“我們從開源模式開始,任何人都可以免費部署,因為這是廣泛分發它們並創造需求的一種方式。但從一開始,我們就提供一種具有優化模型的商業模式,這讓使該公司能夠為模型開發所需的昂貴研究提供資金。”
參考鏈接:https://twitter.com/MistralAILabs/status/1771670765521281370
首屆中國具身智能大會(CEAI 2024)即將於 2024 年 3 月 30 日至 31 日在上海徐匯西岸美高梅酒店舉行。
本次大會由中國人工智能學會(CAAI)主辦,CAAI 具身智能專委會(籌)、同濟大學、中國科學院計算技術研究所、上海交通大學、中國經濟信息社上海總部聯合承辦,全球高校人工智能學術聯盟協辦,機器之心獨傢 AI 媒體合作。
盛會將為具身智能領域的學術與產業界搭建一個交流合作的頂級平臺,以廣泛促進學術分享與交流、產業合作與互動,推動產學研聯動發展,提升我國具身智能技術的研究與應用水平。