人工智能工作負載分為兩個不同的類別:訓練和推理。雖然訓練需要較大的計算和內存容量,訪問速度並非主要因素,推理則是另一回事。在推理中,人工智能模型必須以極快的速度運行,為最終用戶提供盡可能多的詞塊(單詞),從而更快地回答用戶的提示。

一傢人工智能芯片初創公司 Groq 曾長期默默無聞,但現在它利用專為大型語言模型(LLM)(如 GPT、Llama 和 Mistral LLM)設計的語言處理單元(LPU),在提供超快推理速度方面取得重大進展。
Groq LPU 是基於張量流處理器(TSP)架構的單核單元,在 INT8 時可達到 750 TOPS,在 FP16 時可達到 188 TeraFLOPS,具有 320x320 融合點乘矩陣乘法,此外還有 5120 個矢量 ALU。
Groq LPU 擁有 80 TB/s 的帶寬,並具有大規模並發能力,其本地 SRAM 容量為 230 MB。所有這些共同作用,為 Groq 提供出色的性能,在過去幾天的互聯網上掀起波瀾。
在Mixtral 8x7B 模型中,Groq LPU 的推理速度為每秒 480 個令牌,在業內處於領先地位。在 Llama 2 70B 等上下文長度為 4096 個令牌的模型中,Groq 每秒可提供 300 個令牌,而在上下文長度為 2048 個令牌的較小 Llama 2 7B 中,Groq LPU 每秒可輸出 750 個令牌。
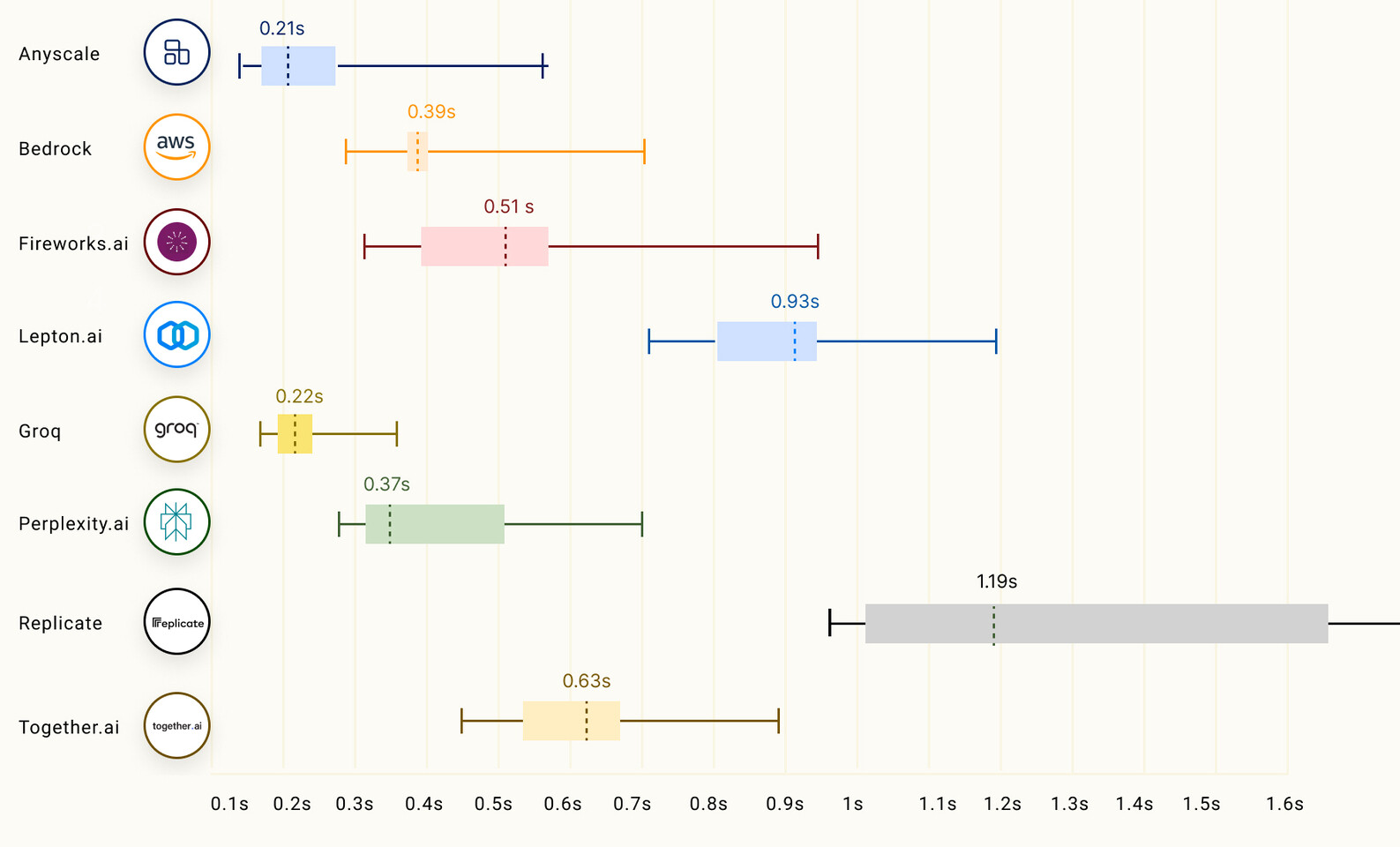
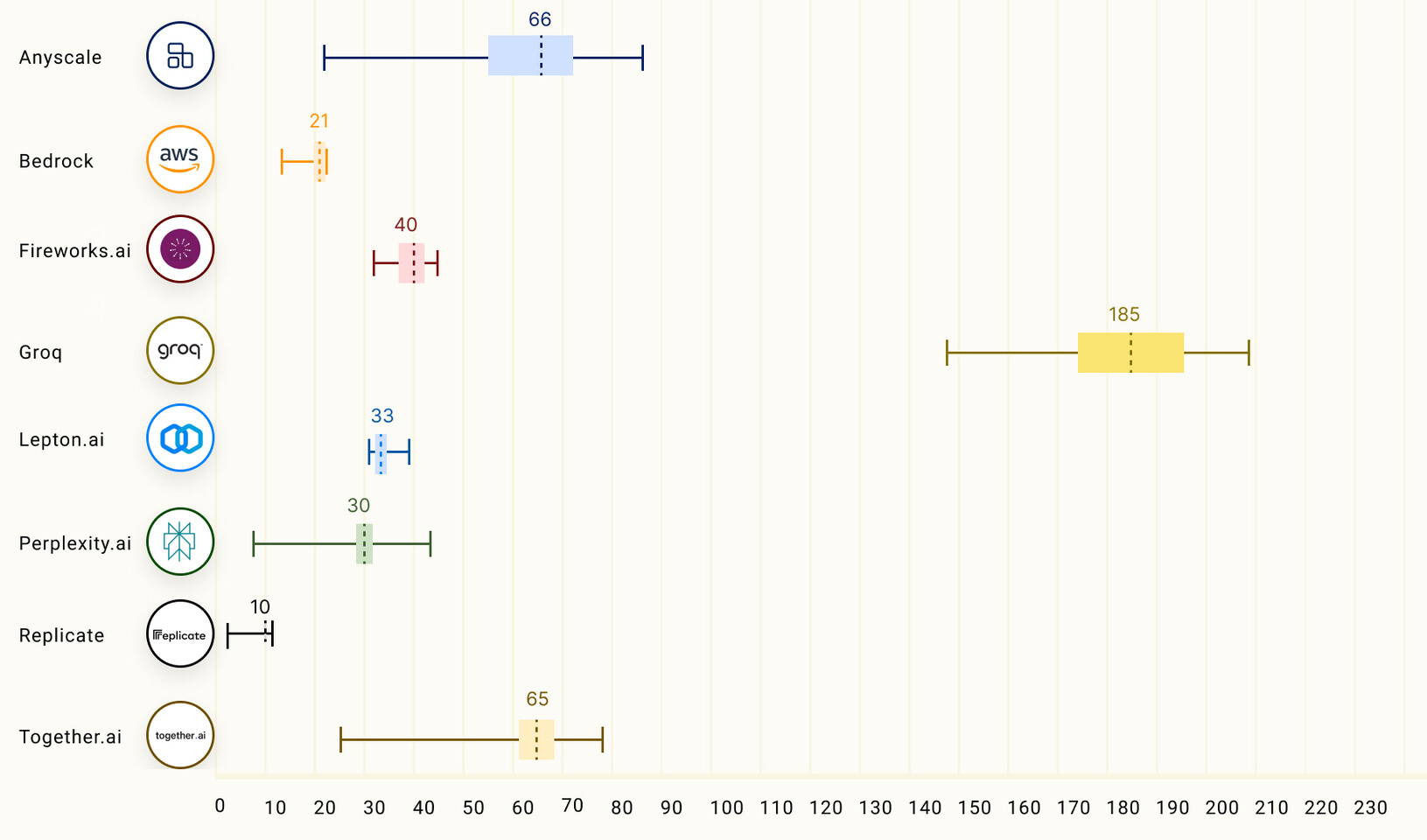
根據LLMPerf Leaderboard 的數據,Groq LPU 在推斷 LLMs Llama 時擊敗基於 GPU 的雲提供商,其配置參數從 70 億到 700 億不等。在令牌吞吐量(輸出)和到第一個令牌的時間(延遲)方面,Groq處於領先地位,實現最高的吞吐量和第二低的延遲。
ChatGPT 采用 GPT-3.5 免費版,每秒可輸出約 40 個令牌。目前的開源 LLM(如 Mixtral 8x7B)可以在大多數基準測試中擊敗 GPT 3.5,現在這些開源 LLM 的運行速度幾乎可以達到 500 令牌每秒。隨著像 Groq 的 LPU 這樣的快速推理芯片開始普及,等待聊天機器人回應的日子似乎開始慢慢消失。
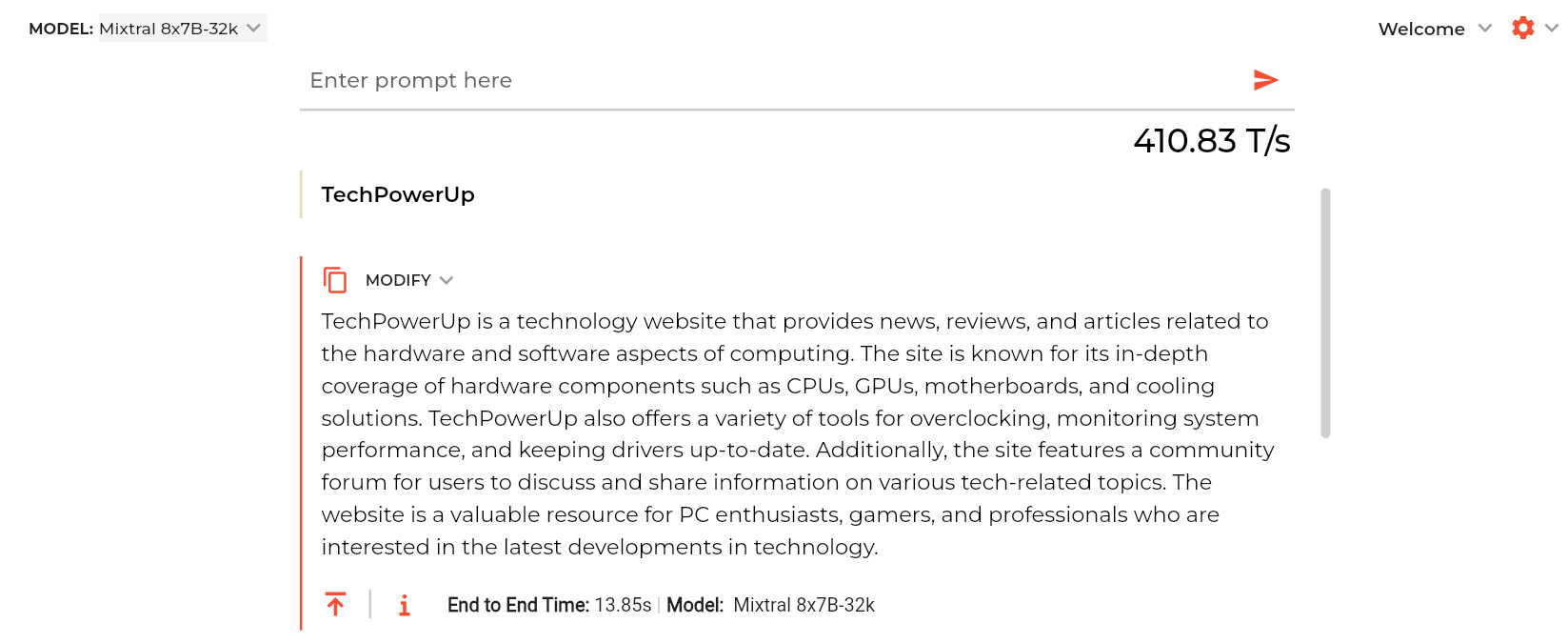
這傢人工智能初創公司直接威脅到英偉達(NVIDIA)、AMD 和英特爾提供的推理硬件,但業界是否願意采用 LPU 仍是個問題,您可以在這裡進行試用:
https://groq.com/