美國人工智能初創公司Groq最新推出的面向雲端大模型的推理芯片引發業內的廣泛關註。其最具特色之處在於,采用全新的TensorStreamingArchitecture(TSA)架構,以及擁有超高帶寬的SRAM,從而使得其對於大模型的推理速度提高10倍以上,甚至超越NVIDIA的GPU。

推理速度比GPU快10倍,功耗僅1/10
據介紹,Groq的大模型推理芯片是全球首個LPU(Language Processing Unit)方案,是一款基於全新的TSA 架構的Tensor Streaming Processor (TSP) 芯片,旨在提高機器學習和人工智能等計算密集型工作負載的性能。
雖然Groq的LPU並沒有采用更本高昂的尖端制程工藝,而是選擇14nm制程,但是憑借自研的TSA 架構,Groq LPU 芯片具有高度的並行處理能力,可以同時處理數百萬個數據流,並該芯片還集成230MB容量的SRAM來替代DRAM,以保證內存帶寬,其片上內存帶寬高達80TB/s。
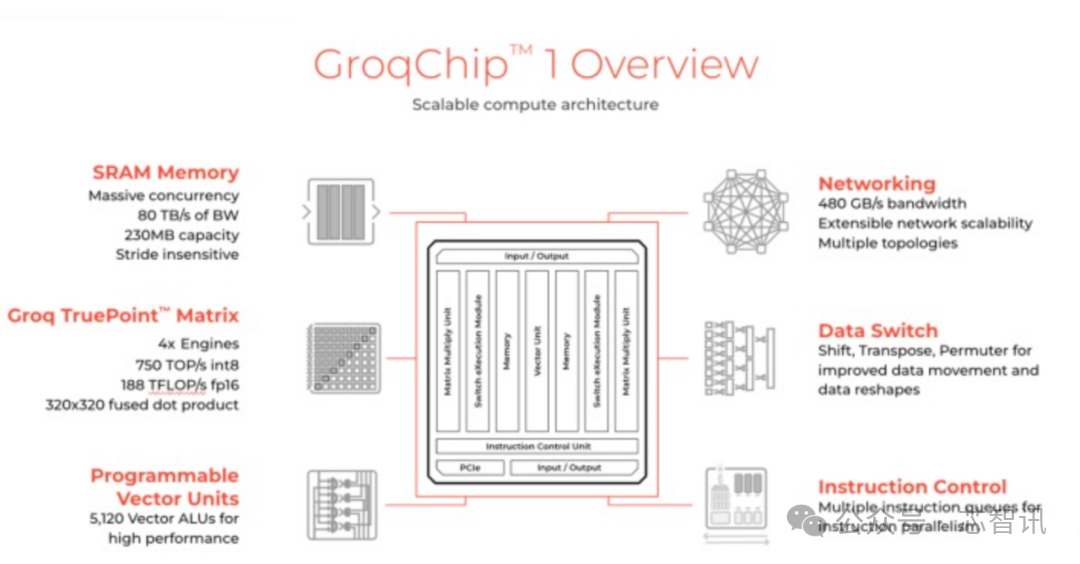
根據官方的數據顯示,Groq的LPU芯片的性能表現相當出色,可以提供高達1000 TOPS (Tera Operations Per Second) 的計算能力,並且在某些機器學習模型上的性能表現可以比常規的 GPU 和 TPU 提升10到100倍。
Groq表示,基於其LPU芯片的雲服務器在Llama2或Mistreal模型在計算和響應速度上遠超基於NVIDIA AI GPU的ChatGPT,其每秒可以生成高達500個 token。
相比之下,目前ChatGPT-3.5的公開版本每秒隻能生成大約40個token。
由於ChatGPT-3.5主要是基於NVIDIA的GPU,也就是說,Groq LPU芯片的響應速度達到NVIDIA GPU的10倍以上。
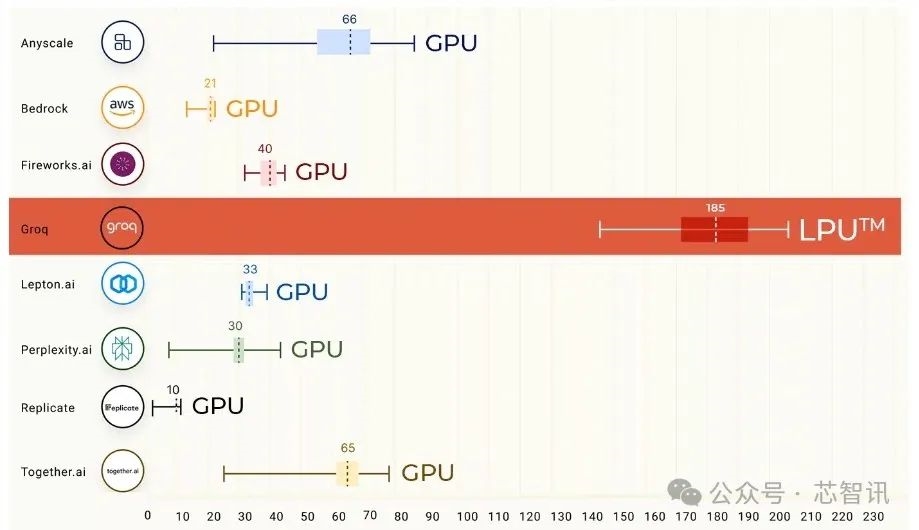
Groq表示,相對於其他雲平臺廠商的大模型推理性能,基於其LPU芯片的雲服務器的大模型推理性能最終實現比其他雲平臺廠商快18倍。
另外,在能耗方面,NVIDIAGPU需要大約10到30焦耳才能生成響應中的tokens,而Groq LPU芯片僅需1到3焦耳,在推理速度大幅提升10倍的同時,其能耗成本僅有NVIDIAGPU的十分之一,這等於是性價比提高100倍。
Groq公司在演示中展示其芯片的強大性能,支持Mistral AI的Mixtral8x7B SMoE,以及Meta的Llama2的7B和70B等多種模型,支持使用4096字節的上下文長度,並可直接體驗Demo。
不僅如此,Groq還喊話各大公司,揚言在三年內超越NVIDIA。目前該公司的LPU推理芯片在第三方網站上的售價為2萬多美元,低於NVIDIA H100的2.5-3萬美元。
資料顯示,Groq 是一傢成立於2016年人工智能硬件初創公司,核心團隊來源於谷歌最初的張量處理單元(TPU)工程團隊。
Groq 創始人兼CEO Jonathan Ross是谷歌TPU項目的核心研發人員。該公司硬件工程副總裁Jim Miller 曾是亞馬遜雲計算服務AWS設計算力硬件的負責人,還曾在英特爾領導所有 Pentium II 工程。
目前該公司籌集超過 6200 萬美元。
為何采用大容量SRAM?
Groq LPU芯片與大多數其他初創公司和現有的AI處理器有著截然不同的時序指令集計算機(Temporal Instruction Set Computer)架構,它被設計為一個強大的單線程流處理器,配備專門設計的指令集,旨在利用張量操作和張量移動,使機器學習模型能夠更有效地執行。
該架構的獨特之處在於執行單元、片內的SRAM內存和其他執行單元之間的交互。它無需像使用HBM(高帶寬內存)的GPU那樣頻繁地從內存中加載數據。
Groq 的神奇之處不僅在於硬件,還在於軟件。軟件定義的硬件在這裡發揮著重要作用。
Groq 的軟件將張量流模型或其他深度學習模型編譯成獨立的指令流,並提前進行高度協調和編排。編排來自編譯器。它提前確定並計劃整個執行,從而實現非常確定的計算。
“這種確定性來自於我們的編譯器靜態調度所有指令單元的事實。這使我們無需進行任何激進的推測即可公開指令級並行性。芯片上沒有分支目標緩沖區或緩存代理,”Groq 的首席架構師 Dennis Abts 解釋道。
Groq LPU芯片為追求性能最大化,因此添加更多SRAM內存和執行塊。
SRAM全名為“靜態隨機存取存儲器”(Static Random-Access Memory)是隨機存取存儲器的一種。
所謂的“靜態”,是指這種存儲器隻要保持通電,裡面儲存的數據就可以恒常保持。
相對之下,動態隨機存取存儲器(DRAM)裡面所儲存的數據則需要周期性地更新。自SRAM推出60多年來,其一直是低延遲和高可靠性應用的首選存儲器,
事實上,對於 AI/ML 應用來說,SRAM 不僅僅具有其自身的優勢。
SRAM 對於 AI 至關重要,尤其是嵌入式 SRAM,它是性能最高的存儲器,可以將其直接與高密度邏輯核心集成在一起。目前SRAM也是被諸多CPU集成在片內(更靠近CPU計算單元),作為CPU的高速緩存,使得CPU可以更直接、更快速的從SRAM中獲取重要的數據,無需去DRAM當中讀取。
隻不過,當前旗艦級CPU當中的SRAM容量最多也僅有幾十個MB。
Groq之所以選擇使用大容量的 SRAM來替代DRAM 內存的原因主要有以下幾點:
1、SRAM 內存的訪問速度比 DRAM 內存快得多,這意味著 LPU 芯片更快速地處理數據,從而提高計算性能。
2、SRAM 內存沒有 DRAM 內存的刷新延遲,這意味著LPU芯片也可以更高效地處理數據,減少延遲帶來的影響。
3、SRAM 內存的功耗比 DRAM 內存低,這意味著LPU芯片可以更有效地管理能耗,從而提高效率。
但是,對於SRAM來說,其也有著一些劣勢:
1、面積更大:
在邏輯晶體管隨著CMOS工藝持續微縮的同時,SRAM的微縮卻十分的困難。事實上,早在 20nm時代,SRAM 就無法隨著邏輯晶體管的微縮相應地微縮。
2、容量小:
SRAM 的容量比 DRAM 小得多,這是因為每個bit的數據需要更多的晶體管來存儲,再加上SRAM的微縮非常困難,使得相同面積下,SRAM容量遠低於DRAM等存儲器。這也使得SRAM在面對需要存儲大量數據時的應用受到限制。
3、成本高:
SRAM 的成本比 DRAM要高得多,再加上相同容量下,SRAM需要更多的晶體管來存儲數據,這也使得其成本更高。
總的來說,雖然SRAM 在尺寸、容量和成本等方面具有一些劣勢,這些劣勢限制其在某些應用中的應用,但是 SRAM 的訪問速度比 DRAM 快得多,這使得它在某些計算密集型應用中表現得非常出色。
Groq LPU 芯片采用的大容量 SRAM 內存可以提供更高的帶寬(高達80TB/s)、更低的功耗和更低的延遲,從而提高機器學習和人工智能等計算密集型工作負載的效率。
那麼,與目前AI GPU當中所搭載的 HBM 內存相比,Groq LPU 芯片集成的 SRAM 內存又有何優勢和劣勢呢?
Groq LPU 芯片的 SRAM 內存容量雖然有230MB,但是相比之下AI GPU 中的 HBM 容量通常都有數十GB(比如NVIDIA H100,其集成80GB HBM),這也意味著LPU 芯片可能無法處理更大的數據集和更復雜的模型。相同容量下,SRAM的成本也比HBM更高。
不過,與HBM 相比,Groq LPU 芯片的所集成的 SRAM 的仍然有著帶寬更快(NVIDIA H100的HBM帶寬僅3TB/s)、功耗更低、延遲更低的優勢。
能否替代NVIDIA H00?
雖然Groq公佈的數據似乎表明,其LPU芯片的推理速度達到NVIDIA GPU的10倍以上,並且能耗成本僅是它十分之一,等於是性價比提高100倍。
但是,Groq並且明確指出其比較的是NVIDIA的哪款GPU產品。由於目前NVIDIA最主流的AI GPU是H100,因此,我們就拿NVIDIA H100來與Groq LPU來做比較。
由於Groq LPU隻有230MB的片上SRAM來作為內存,因此,如果要運行Llama-2 70b模型,即使將Llama 2 70b量化到INT8精度,仍然需要70GB左右的內存。
即使完全忽略內存消耗,也需要305張Groq LPU加速卡才夠用。如果考慮到內存消耗,可能需要572張Groq LPU加速卡。
官方數據顯示,Groq LPU的平均功耗為185W,即使不計算外圍設備的功耗,572張Groq LPU加速卡的總功耗也高達105.8kW。
假設一張Groq LPU加速卡的價格為2萬美元,因此,購買572張卡的成本高達1144萬美元(規模采購價格應該可以更低)。
根據人工智能科學傢賈揚清分享的數據顯示,目前,數據中心每月每千瓦的平均價格約為20美元,這意味著572張Groq LPU加速卡每年的電費為105.8*200*12=25.4萬美元。
賈揚清還表示,使用4張NVIDIA H100加速卡就可以實現572張Groq LPU一半的性能,這意味著一個8張H100的服務器的性能大致相當於572張Groq LPU。
而8張H100加速卡的標稱最大功率為10kW(實際上約為8-9千瓦),因此一年電費為僅24000美元或略低。現在一個8張H100加速卡的服務器的價格約為30萬美元。
顯然,相比較之下,在運行相同的INT8精度的Llama-2 70b模型時,NVIDIA H00的實際性價比要遠高於Groq LPU。
即使我們以FP16精度的Llama-2 7b模型來比較,其最低需要14GB的內存來運行,需要約70張Groq LPU加速卡才能夠部署,按照單卡FP16算力188TFLOPs計算,其總算力將達到約13.2PFLOPs。這麼強的算力隻是用來推理Llama-2 7b模型屬實有些浪費。
相比之下,單個NVIDIA H100加速卡,其集成的80GB HMB就足夠部署5個FP16精度的Llama-2 7b模型,而H100在FP16算力約為2PFLOPs。即使要達到70張Groq LPU加速卡相同的算力,隻需要一臺8卡NVIDIA H100服務器就能夠達到。
單從硬件成本上來計算,70張Groq LPU加速卡成本約140萬美元,一個8張H100加速卡的服務器的價格約為30萬美元,顯然,對於運行FP16精度的Llama-2 7b模型來說,采用NVIDIA H100的性價比也是遠高於Groq LPU。
當然,這並不是說Groq LPU相對於NVIDIA H100來說毫無優勢,正如前面所介紹的那樣,Groq LPU的主要優勢在於其采用大容量的SRAM內存,擁有80TB/s的超高的內存帶寬,使得其非常適合於較小的模型且需要頻繁從內存訪問數據的應用場景。
當然,其缺點則在於SRAM的內存容量較小,要運行大模型,就需要更多的Groq LPU。
那麼,Groq LPU能否進一步提升其SRAM內存容量來彌補這一缺點呢?
答案當然是可以,但是,這將會帶來Groq LPU面積和成本的大幅增加,並且也會帶來功耗方面的問題。
或許未來Groq可能會考慮,加入HBM/DRAM來提升 LPU的適應性。