當地時間3月18日,英偉達在2024GTC大會上發佈多款芯片、軟件產品。創始人黃仁勛表示:“通用計算已經失去動力,現在我們需要更大的AI模型,更大的GPU,需要將更多GPU堆疊在一起。這不是為降低成本,而是為擴大規模。”

作為GTC大會的核心,英偉達發佈Blackwell GPU,它分為B200和GB200系列,後者集成1個Grace CPU和2個B200 GPU。
NVIDIA GB200 NVL72大型機架系統使用GB200芯片,搭配NVIDIA BlueField-3數據處理單元、第五代NVLink互聯等技術,對比相同數量H100 Tensor核心的系統,在推理上有高達30倍的性能提升,並將成本和能耗降低25倍。
在AI應用方面,英偉達推出Project GR00T機器人基礎模型及Isaac機器人平臺的重要更新。
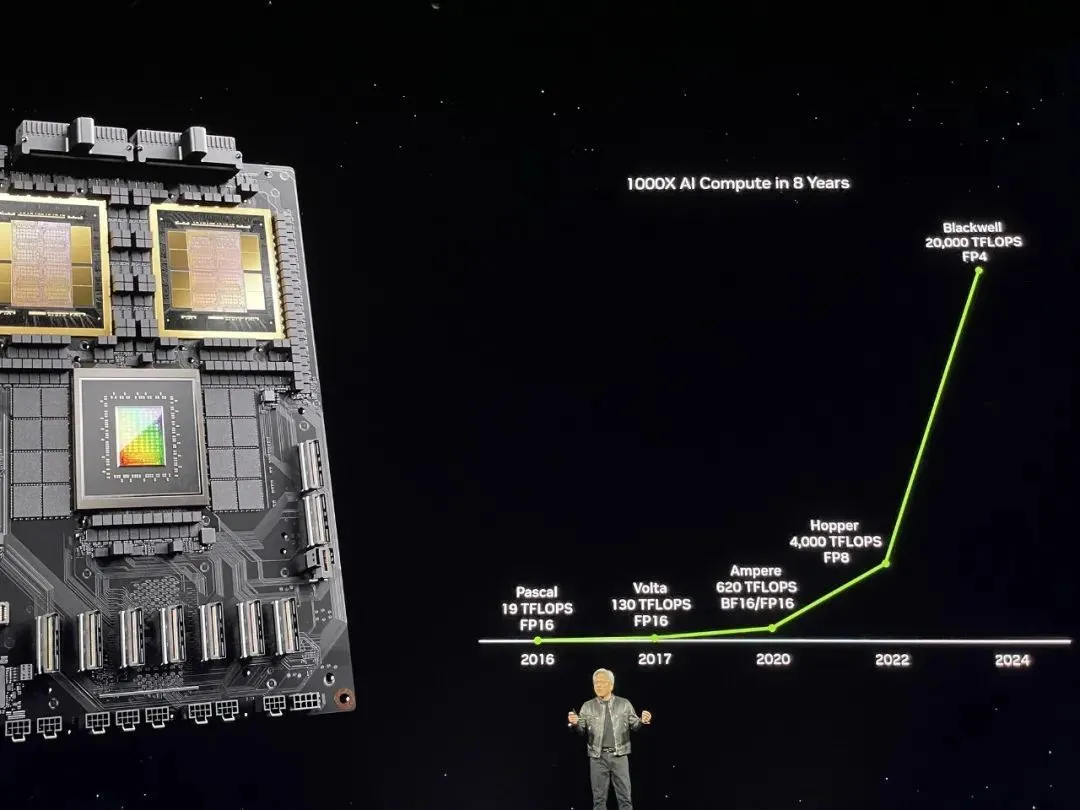
英偉達展示其AI芯片的算力在過去8年裡實現1000倍的增長,這代表AI時代的摩爾定律(算力快速增長,算力成本快速下降)正在形成。
01
實現10萬億參數AI模型的訓練和實時推理
在GTC大會上,英偉達不僅發佈算力方面的更新,也介紹其在應用方面的進展。
1.更強的訓練算力,更快、成本更低的推理
Blackwell不僅是一塊芯片,也是一個平臺。英偉達的目標是讓規模達到10萬億參數的AI模型可以輕松訓練和實時推理。

它最小的單元是B200,內置2080億個晶體管,使用定制的4NP TSMC工藝制造,采用Chiplet架構,兩個GPU dies通過每秒10TB的芯片到芯片鏈接連接成一個統一的GPU。
GB200超級芯片則將兩個B200 Tensor核心GPU通過每秒900GB的超低功耗NVLink芯片到芯片互連技術與NVIDIA Grace CPU連接。

再往上一層,則是NVIDIA GB200 NVL72,這是一個多節點、液冷的機架系統,它內含36個Grace Blackwell超級芯片,包括72個Blackwell GPU和36個Grace CPU,在NVIDIA BlueField-3數據處理單元的支持下,它能實現雲網絡加速、可組合存儲、零信任安全性以及在超大規模AI雲中的GPU計算彈性。
這個系統可以被作為"單個GPU"工作,這時它能提供1.4 exaflops的AI性能和30TB的快速內存。據稱,一個GB200 NVL72就最高支持27萬億參數的模型。
最大規模的系統則是DGX SuperPOD,NVIDIA GB200 NVL72是DGX SuperPOD的構建單元,這些系統通過NVIDIA Quantum InfiniBand網絡連接,可擴展到數萬個GB200超級芯片。
此外,NVIDIA還提供HGX B200服務器板,通過NVLink將八個B200 GPU連接起來,支持基於x86的生成式AI平臺。HGX B200通過NVIDIA Quantum-2 InfiniBand和Spectrum-X以太網網絡平臺支持高達400Gb/s的網絡速度。
GB200還將在NVIDIA DGX雲上提供給客戶,這是一個與AWS、Google雲和甲骨文雲等領先的雲服務提供商共同設計的AI平臺,為企業開發者提供專用訪問權限,以構建和部署先進的生成式AI模型所需的基礎設施和軟件。
英偉達以實際的模型訓練為例,訓練一個GPT-MoE-1.8T模型(疑似指GPT-4),此前使用Hopper系列芯片需要8000塊GPU訓練90天,現在使用GB200訓練同樣的模型,隻需要2000塊GPU,能耗也隻有之前的四分之一。

由GB200組成的系統,相比相同數量的NVIDIA H100 Tensor核心GPU組成的系統,推理性能提升30倍,成本和能耗降低25倍。
在背後支持這些AI芯片和AI算力系統的是一系列新技術,包括提升性能的第二代Transformer引擎(支持雙倍的計算和模型大小)、第五代NVLink(提供每個GPU1.8TB/s的雙向吞吐量);提升可靠性的RAS引擎(使AI算力系統能夠連續運行數周甚至數月);以及安全AI(保護AI模型和客戶數據)等。
在軟件方面,Blackwell產品組合得到NVIDIA AI Enterprise的支持,這是一個端到端的企業級AI操作系統。NVIDIA AI Enterprise包括NVIDIA NIM推理微服務,以及企業可以在NVIDIA加速的雲、數據中心和工作站上部署的AI框架、庫和工具。NIM推理微服務可對來自英偉達及合作夥伴的數十個AI模型進行優化推理。
綜合英偉達在算力方面的創新,我們看到它在AI模型訓練和推理方面的顯著進步。
在AI的模型訓練方面,更強的芯片和更先進的芯片間通訊技術,讓英偉達的算力基礎設施能夠以相對較低的成本訓練更大的模型。GPT-4V和Sora代表生成式AI的未來,即多模態模型和包括視頻在內的視覺大模型,英偉達的進步讓規模更大、更多模態和更先進的模型成為可能。
在AI推理方面,目前越來越大的模型規模和越來越高的實時性要求,對於推理算力的挑戰十分嚴苛。英偉達的AI算力系統推理性能提升30倍,成本和能耗降低25倍。不僅讓大型模型的實時推理成為可能,而且解決以往的並不算優秀的能效和成本問題。
2.著重發力具身智能
英偉達在GTC大會上公佈一系列應用方面的新成果,例如生物醫療、工業元宇宙、機器人、汽車等領域。其中機器人(具身智能)是它著重發力的方向。
它推出針對仿生機器人的Project GR00T基礎模型及Isaac機器人平臺的重要更新。

Project GR00T是面向仿生機器人的通用多模態基礎模型,充當機器人的“大腦”,使它們能夠學習解決各種任務的技能。
Isaac機器人平臺為開發者提供新型機器人訓練模擬器、Jetson Thor機器人計算機、生成式AI基礎模型,以及CUDA加速的感知與操控庫
Isaac機器人平臺的客戶包括1X、Agility Robotics、Apptronik、Boston Dynamics、Figure AI和XPENG Robotics等領先的仿生機器人公司。
英偉達也涉足工業機器人和物流機器人。Isaac Manipulator為機械臂提供最先進的靈巧性和模塊化AI能力。它在路徑規劃上提供高達80倍的加速,並通過Zero Shot感知(代表成功率和可靠性)提高效率和吞吐量。其早期生態系統合作夥伴包括安川電機、PickNik Robotics、Solomon、READY Robotics和Franka Robotics。
Isaac Perceptor提供多攝像頭、3D環繞視覺能力,這些能力對於自動搬運機器人特別有用,它幫助ArcBest、比亞迪等在物料處理操作等方面實現新的自動化水平。
02
英偉達算力井噴後,對創業公司有何影響?
在發展方式上,英偉達與OpenAI等公司有明顯的不同。
OpenAI以及Anthropic、Meta等公司是以AI模型為核心,然後運營平臺和生態;英偉達則以算力為核心,並拓展到軟件平臺和AI的相關應用。並且在應用方面,它並沒有表現出一傢壟斷的態勢,而是與各種行業的合作夥伴共創,其目的是建立一個軟硬件結合的龐大生態。
此次英偉達在算力方面的進步,對於AI創業公司們也產生深刻影響。
對於大模型領域創業公司,例如OpenAI等,這顯然是利好,因為他們能以更快的頻率,更低的成本訓練規模更大,模態更多的模型,並且有機會進一步降低API的價格,擴展客戶群體。
對於AI應用領域的創業公司,英偉達不僅將推理算力性能提高數十倍,而且降低能耗和成本。這讓AI應用公司們能在成本可承擔的前提下,拓展業務規模,隨著AI算力的進一步增長,未來AI應用公司的運營成本還可能進一步降低。
對於AI芯片領域的創業公司,英偉達的大更新讓他們感受到明顯壓力,而且英偉達提供的是一套完整的系統,包括算力芯片,芯片間通信技術,打破內存墻的網絡芯片等。AI芯片創業公司必須找到自己真正能建立優勢的方向,而不是因為英偉達這類巨頭的一兩次更新就失去存在價值。
中國的AI創業公司,因為各種各樣的原因,很難使用最新最強的英偉達AI芯片,作為替代的國產AI芯片在算力和能效比上目前仍有差距,這可能導致專註大模型領域的公司們在模型的規模擴展和迭代速度上與海外的差距拉大。
對於中國的AI應用公司,則仍有機會。因為它們不僅可以用國內的基礎模型,也可以用海外的先進開源模型。中國擁有全球頂尖的AI工程師和產品經理,他們打造的產品足可以參與全球競爭,這讓AI應用公司們進可以開拓海外市場,還有足夠龐大的國內市場做基本盤,AI時代的字節跳動、米哈遊很可能在它們中間產生。