近期,英偉達推出的一款計算光刻軟件引起廣泛關註,這使得計算光刻這個領域受到更多人的關註。計算光刻這個領域已經存在30年之久,但現在為什麼備受關註呢?因為這關乎摩爾定律的繼續演進,芯片的繼續微縮。
什麼是計算光刻?
在講計算光刻之前,讓我們先從一個簡單的相機開始談起。數碼相機我們都不陌生,一般而言,相機的光圈越大越好。那麼如何分辨光圈的大小呢?
在相機鏡頭周圍的標記的看起來像比例的數字就是光圈的大小,1:XX,所以分母越小,光圈就越大,但是分母越小,也越昂貴。
芯片制造中的光刻與這一原理頗有相似之處。在芯片制造的過程中,有一道光刻的關鍵步驟,需要在衍射極限條件下使用世界上最復雜的“相機”將設計好的電路刻畫到矽上,這個相機也就是現在大傢熟知的光刻機。要給微型晶體管成像,就需要大的透鏡。
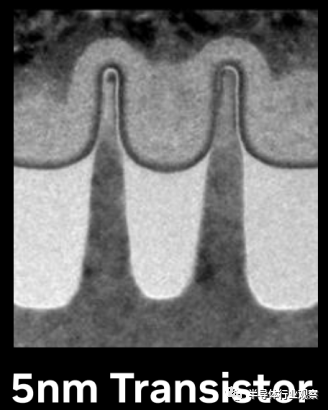
放大5000萬倍下的5nm晶體管
在光刻技術中遵循瑞利準則(Rayleigh Criterion)——CD=k1*λ/NA。
其中,CD特征值是光刻系統能夠放大的最小精度(也就是光學系統的分辨率),CD數值越小代表分辨率越高,我們現在所說的5nm、3nm制程就是這個參數;
λ代表光源波長,波長越小越好;
NA代表數值孔徑,表示鏡頭質量的特征數,數值孔徑是衡量透鏡系統收集和聚焦光線能力的參數,NA越高越好。
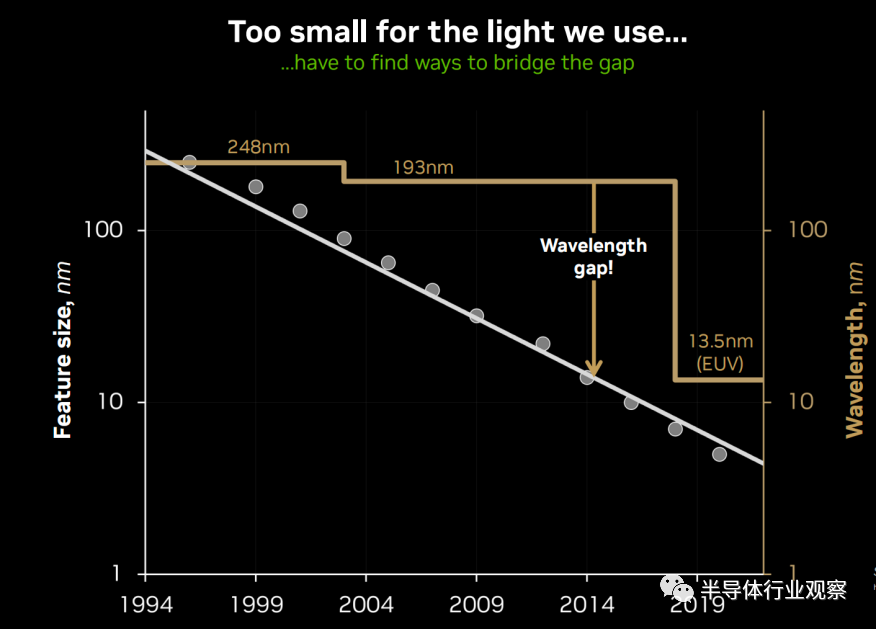
過去30年以來,芯片沿著摩爾定律的準則不斷向前發展,工藝的微縮起到很大的作用,也就是上述CD特征數值越來越小。光刻機巨頭ASML一直在通過光刻機的進步來降低入射光源的波長(λ),提高數值孔徑,進而獲得越來越小CD值。
ASML從g-line光刻機發展到DUV光刻機和現在的EUV光刻機。例如,在DUV光刻機中249nm和193nm是最常見的波長(λ),EUV光刻系統的光源波長為13.5nm。
但下圖中可以看出,白色的直線表示芯片的尺寸,隨著時間的推移,芯片的大小呈指數在縮小,金色的是用來成像的光的波長,可以看出,波長與要成像的晶體管的差距一直在擴大。當這種情況發生時,物理衍射就會使圖像模糊。
於是,行業給出的解決方法是采用逆向光刻的思維,先給定一個圖像,即晶圓上的電路設計,逆向推測出所需要的掩膜和光源,這就是所謂的計算光刻。
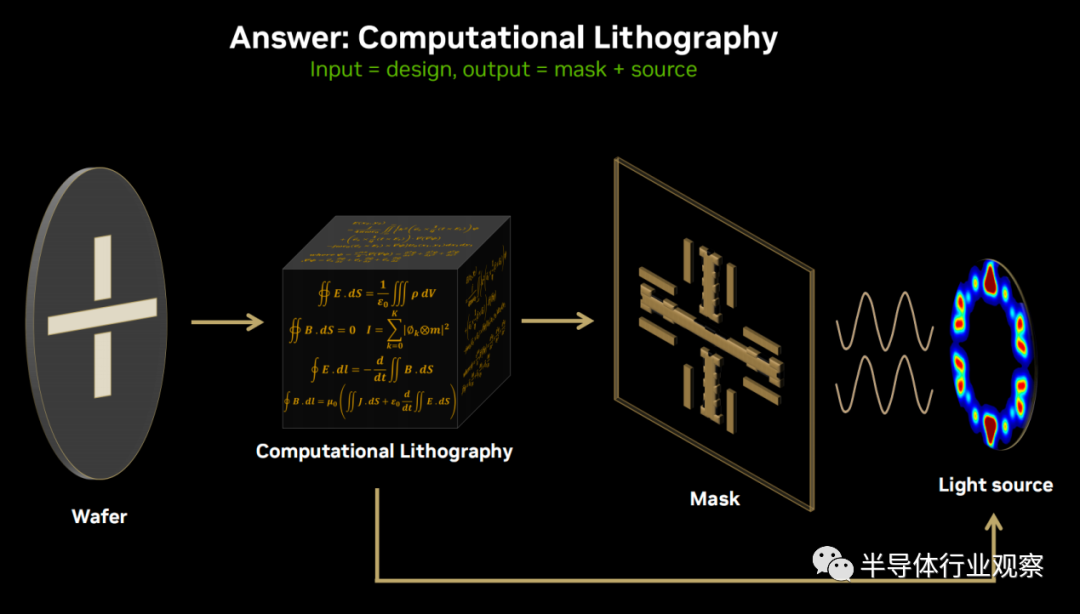
據新思的科普,在尺寸非常小時,特征彼此距離更近,通常無法清晰準確地將掩模圖案刻到晶圓上。光漫射會影響分辨率,導致圖案模糊或失真。計算光刻的作用就是補償因衍射或光學、抗蝕劑和蝕刻鄰近效應而導致的任何圖像誤差。
計算光刻通常包括光學鄰近效應修正(OPC)、光源-掩膜協同優化技術(SMO)、多重圖形技術(MPT)、反演光刻技術(ILT)等四大技術。在這其中,OPC(光學鄰近校正)和 ILT(逆光刻技術)是主要的兩種。
計算光刻其實屬於軟件的范疇,ASML對計算光刻的釋義是,利用計算機建模、仿真和數據分析等手段,來預測、校正、優化和驗證光刻工藝在一系列圖案、工藝和系統條件下的成像性能。
計算光刻被ASML稱為是“鐵三角”軟件部分的中堅力量,可見其重要性。(順便一提,ASML目前有計算光刻研發實習的職位招聘)

問題來,計算光刻越來越難
但是現在問題來,據NVIDIA先進技術集團副總裁Vivek K Singh的說法:“我在1993年加入光刻工作時,如果你想在晶圓上印一個十字,你隻需要在掩模上印一個十字就行。但是很快情況就變,光的擴散會影響分辨率,導致模糊或失真 ,這意味著可能會遺漏芯片的重要元素。
如下圖所示,一些可愛的狗耳朵和雙髻鯊開始出現在掩膜上,以此來彌補光學衍射。但這還遠遠不夠,我們不得不采用完全成熟的基於光學接近校正(OPC)的模型,後來又開始通過基於規則的輔助功能來增強它。
從最簡單的一些粉飾到逐漸扭曲的掩膜,最終的結果還是要在晶圓上印下那個十字,隻不過是在很小的晶圓尺寸上。”

由此可以看出,當芯片的關鍵尺寸小於光源波長的時候,所需要的掩模版越來越復雜。幾十年來,為芯片在制造過程中制作掩膜一直是半導體制造中的關鍵環節。
尤其是芯片逐漸來到3nm及以下,不僅需要更加精準的光刻計算,光刻計算所需的時間也越來越長。計算光刻是涉及電磁物理、光化學、計算幾何、迭代優化和分佈式計算的復雜計算,沒有更強大的計算光刻很難實現這樣復雜的掩模版設計。
像臺積電這樣的代工廠需要有大量的數據中心來處理相關計算和仿真運行,代工廠的數據中心通常是以CPU為核心。
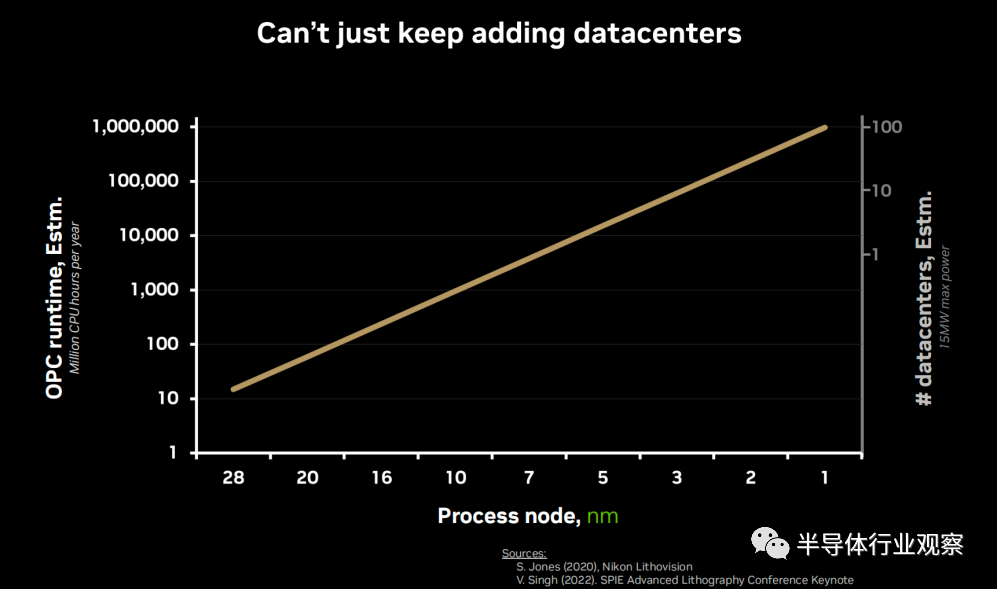
下圖是Vivek Singh估算的每年CPU工作的小時數,左側y軸顯示隨著工藝節點不斷微縮,光學鄰近修正(OPC)在2nm、1nm差不多需要CPU來計算幾百萬小時。
右側Y軸上是不同工藝節點所用的數據中心的數量,5nm節點差不多需要3個大的數據中心,每個數據中心需要處理10個掩膜。
3nm節點的時候需要6個數據中心,如果繼續這樣下去,到1nm則很有可能需要100個數據中心。“你不能一直增加數據中心,有些東西必須舍棄,洛杉磯已經開始下雪。”Vivek Singh如是說道。再者,現在的計算能力在未來很可能不夠。
所以,在半導體制造中的超大型工作負載所需的計算時間成本,已經使得摩爾定律不再具有經濟性。計算光刻這一步驟也成為將新的納米技術節點和計算機架構推向市場的瓶頸。
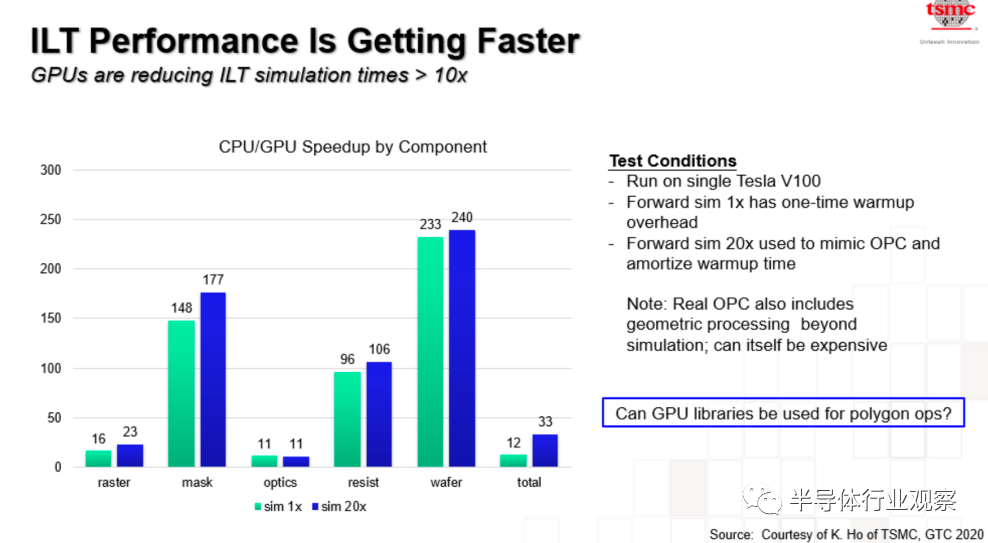
2020年臺積電在一次會議上提到,采用GPU可以將反向光刻(ILT)仿真時間減少10倍以上。ppt的最後臺積電提一個很重要的問題,GPU庫可以用於多邊形操作嗎?
英偉達改變遊戲規則
今天英偉達證明,可以。為什麼GPU可以用於計算光刻,因為計算光刻技術中至少一半的OPC和ILT是由前成像組成的,而且它幾乎完全是由卷積運算組成的,這些正是GPU擅長的。
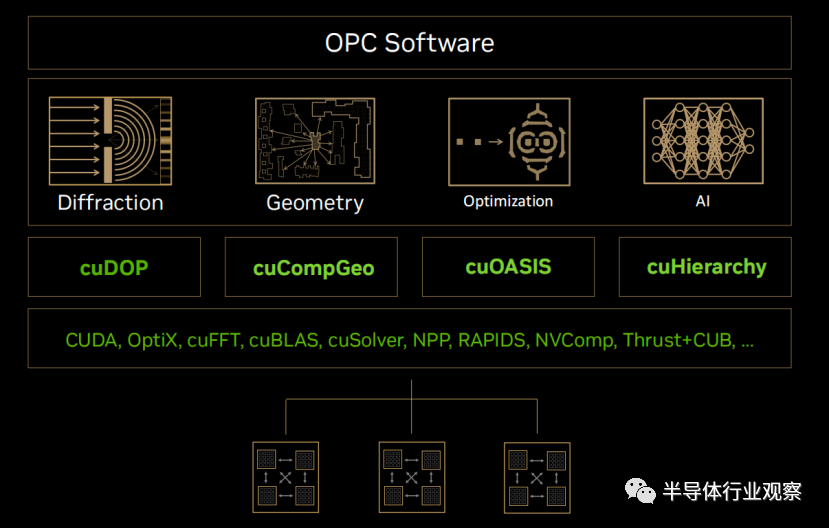
在近日的GTC大會上,英偉達在GPU之上構建cuLitho計算光刻技術軟件庫,這是英偉達四年秘密研發的成果。在cuLitho計算光刻軟件庫中有多項技術,如下圖所示,cuDOP用於衍射光學,cuCompGeo用於計算幾何,cuOASIS用於優化,cuHierarchy用於AI。
cuLitho已被EDA工具廠商新思采用,cuLitho已集成到新思科技Proteus全芯片掩模合成解決方案和Proteus ILT逆光刻技術。一般情況下,晶圓廠在改變工藝時需要修改OPC,因此會遇到瓶頸。
cuLitho不僅可以幫助突破這些瓶頸,還可以提供曲線式光掩模、High-NA EUV光刻、亞原子光刻膠建模等新技術節點所需的新型解決方案和創新技術。
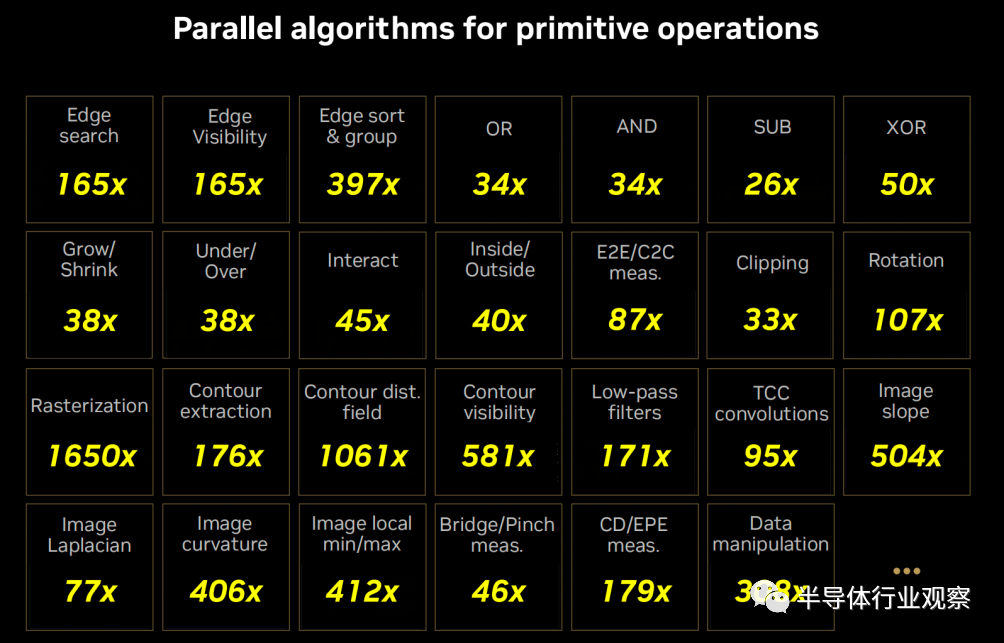
cuLitho的核心是一組並行算法,由英偉達科學傢發明,計算光刻工藝的所有部分都可以並行運行,原來需要4萬個CPU系統才能完成的工作,現在僅需用500個NVIDIA DGX H100系統即可完成,這不僅大大加速目前每年消耗數百億CPU小時的大規模計算工作負載,而且降低耗電和對環境的影響。
cuLitho在組件級別上平均加速一次連續的CPU操作,基於Ampere組件上提升138倍,在Hopper結構上提高254倍。在端到端的OPC項目中,結合Ampere提升23倍,在Hopper上提升42倍。
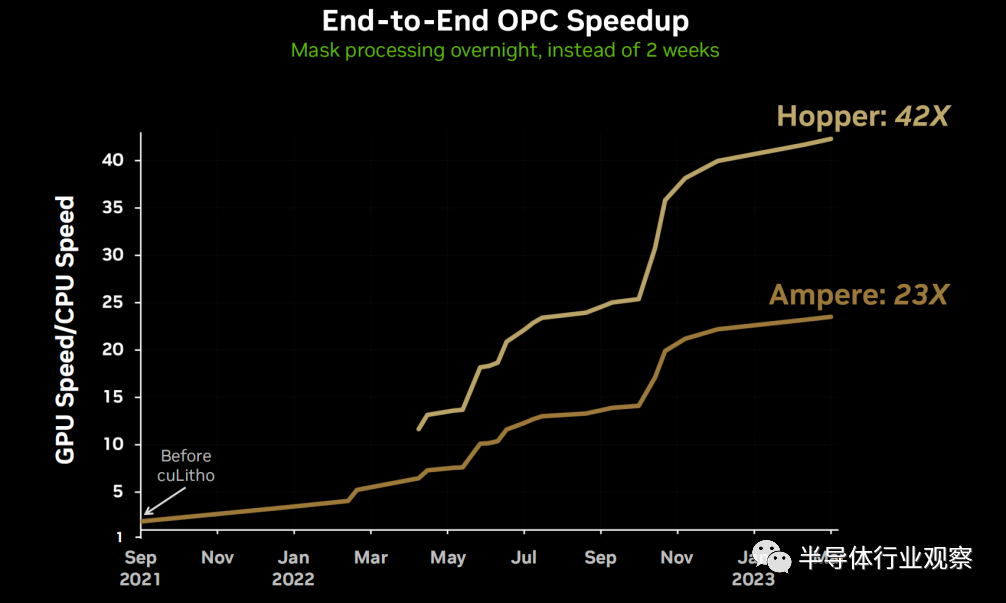
使用cuLitho的晶圓廠每天的光掩模產量可增加3-5倍,而耗電量可以比當前配置降低9倍。英偉達表示,基於GPU的cuLitho計算光刻技術,其性能比當前光刻技術工藝提高40倍,原本需要兩周時間才能完成的光掩模現在可以在一夜之間完成。
例如英偉達H100 GPU需要89塊掩膜板,在CPU上運行時,處理單個掩膜板需要兩周時間,而在GPU上運行cuLitho隻需8小時。
從長遠來看,cuLitho將帶來更好的設計規則、更高的密度和產量以及AI驅動的光刻技術,使晶圓廠能夠提高產量、減少碳足跡並為2納米及更高工藝奠定基礎。
cuLitho計算光刻技術軟件庫,目前已得到臺積電、ASML的合作。cuLitho將於6月在臺積電開始使用,臺積電用其來部署反演光刻技術、深度學習等;ASML計劃在所有計算光刻軟件產品中加入對GPU的支持,cuLitho的優勢在High-NA EUV光刻時代將變得尤為明顯;EDA工具供應商Synopsys OPC軟件將在cuLitho平臺上運行。
下圖是一個chromeless face shift掩膜,如果把它放進ASML最新的光刻機中,會出來怎樣一個圖案呢?

答案是,NVIDIA cuLitho。

目前的cuLitho計算光刻技術還隻是一個於麥克斯韋方程組的數學工具,但英偉達表示,基於人工智能的計算光刻技術“正在開發中”。想象一些如果AI技術引入計算光刻又將如何?
寫在最後
沒有計算光刻技術的支撐,芯片制造商就不可能制造出最新的技術節點。
cuLitho計算光刻庫軟件的發佈,不僅為芯片的繼續演進提供一項革新技術,也再次發揮GPU的潛力——從最初的圖形處理到AI芯片、再到數據中心、乃至芯片的未來,老黃贏麻。
借用《軟硬件融合》圖書和公眾號作者,上海矩向科技創始人兼CEO黃朝波對該發佈的點評:“老黃是非常成功的,但其實本質上老黃就隻做一件事情(並行計算)和兩個方面(GPU是並行計算平臺,CUDA是為更好的並行計算編程)。”
每次當芯片演變出現瓶頸,總會有新技術出現,例如FinFET晶體管技術的發明給摩爾定律續命十幾年。現在,為讓芯片繼續微縮下去,各種新材料、新架構、新封裝、新互聯等技術層出不窮。