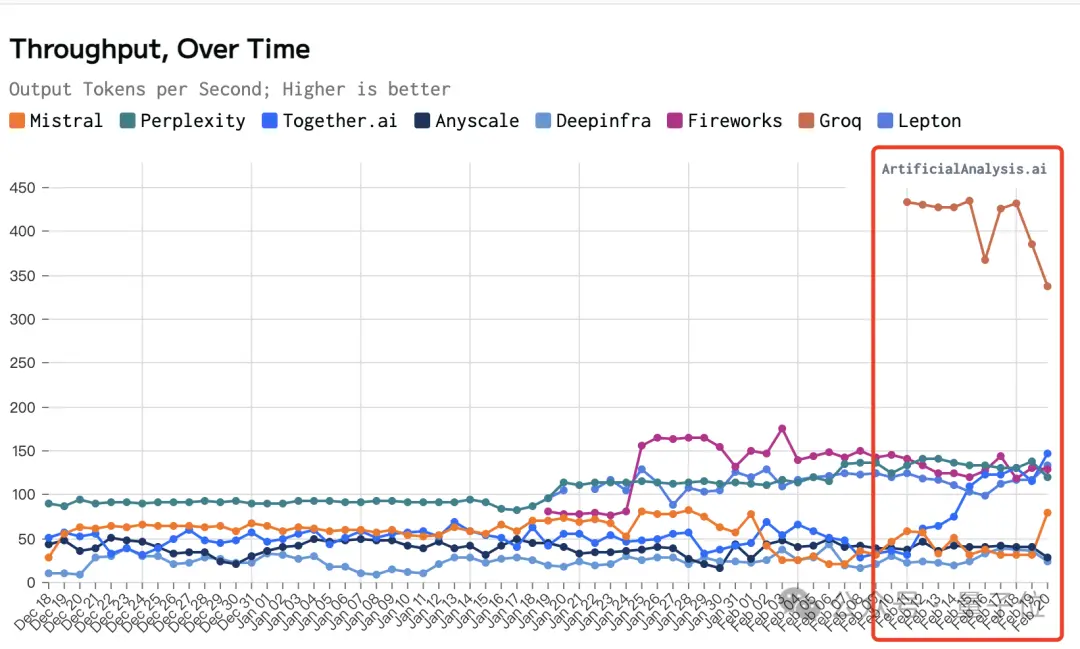
太快太快。一夜間,大模型生成已經沒什麼延遲……來感受下這速度。生成速度已經接近每秒500tokens。還有更直觀的列表對比,速度最高能比以往這些雲平臺廠商快個18倍吧。
(這裡面還有個熟悉的身影:Lepton)
網友表示:這速度簡直就是飛機vs走路。

值得一提的是,這並非哪傢大公司進展——
初創公司Groq,GoogleTPU團隊原班人馬,基於自研芯片推出推理加速方案。(註意不是馬斯克的Grok)
據他們介紹,其推理速度相較於英偉達GPU提高10倍,成本卻降低到十分之一。
換言之,任何一個大模型都可以部署實現。
目前已經能支持Mixtral 8x7B SMoE、Llama 2的7B和70B這三種模型,並且可直接體驗Demo。
他們還在官網上喊話奧特曼:
你們推出的東西太慢……

每秒接近500tokens
既然如此,那就來體驗一下這個號稱“史上最快推理”的Groq。
先聲明:不比較生成質量
。就像它自己說的那樣,內容概不負責。

目前,演示界面上有兩種模型可以選擇。
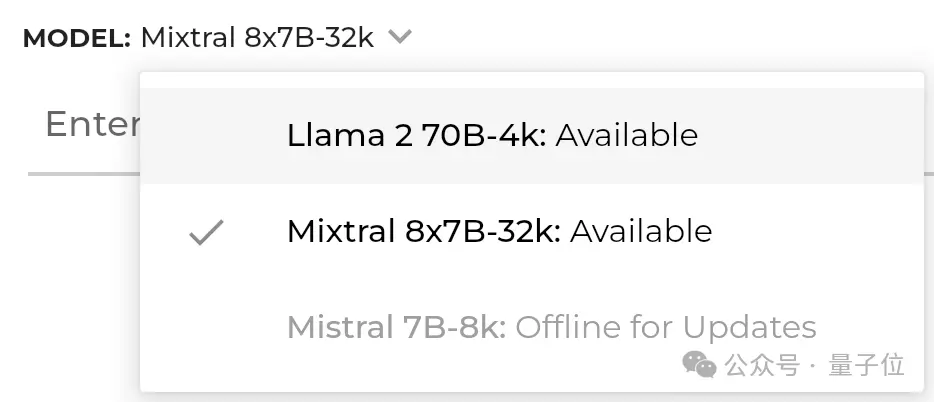
就選擇Mixtral 8x7B-32k和GPT-4同擂臺對比一下。
提示詞:你是一個小學生,還沒完成寒假作業。請根據《星際穿越》寫一篇500字的讀後感。
結果啪的一下,隻需1.76秒就生成一長串讀後感,速度在每秒478Tokens。
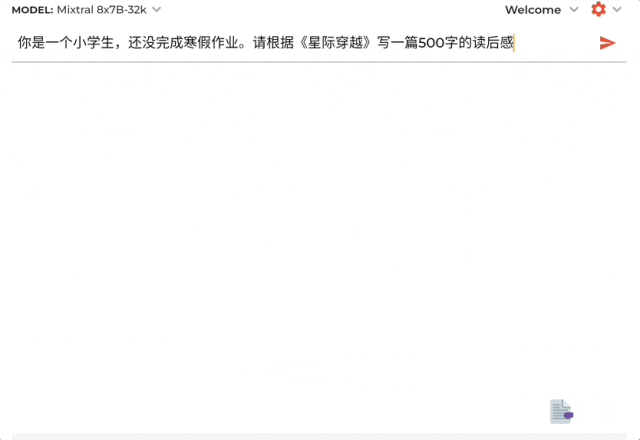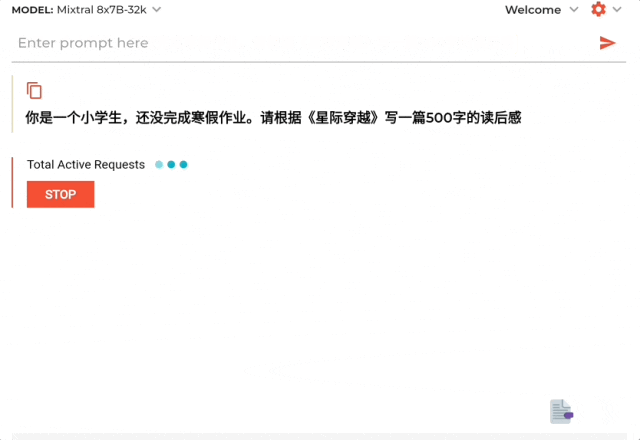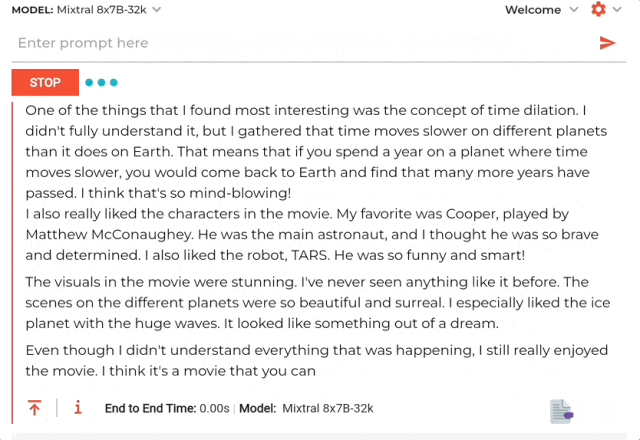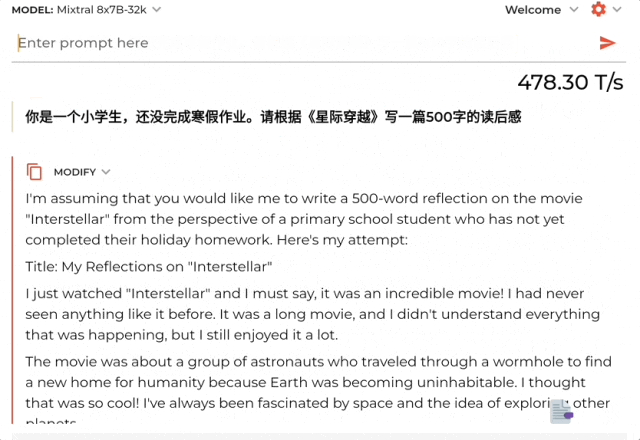
不過內容是英文的,以及讀後感隻有三百六十多字。但後面也趕緊做解釋說考慮到是小學生寫不那麼多……

至於GPT-4這邊的表現,內容質量自然更好,也體現整個思路過程。但要完全生成超過三十秒。單是讀後感內容的生成,也有近二十秒鐘的時間。

除Demo演示外,Groq現在支持API訪問,並且完全兼容,可直接從OpenAI的API進行簡單切換。
可以免費試用10天,這期間可以免費獲得100萬Tokens。
目前支持Llama 2-70B 和7B, Groq可以實現4096的上下文長度,還有Mixtral 8x7B這一型號。當然也不局限於這些型號,Groq支持具體需求具體定制。
價格方面,他們保證:一定低於市面上同等價格。
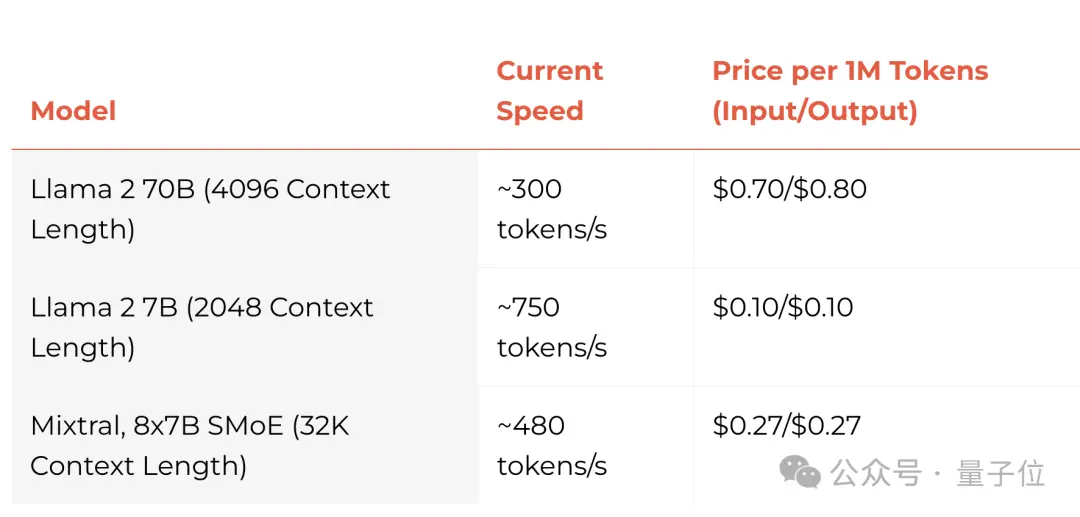
不過可以看到,每秒500tokens似乎還不是終極速度,他們最快可以實現每秒750Tokens。

GoogleTPU團隊創業項目
Groq是集軟硬件服務於一體的大模型推理加速方案,成立於2016年,創始團隊中很多都是GoogleTPU的原班人馬。
公司領導層的10人中,有5人都曾有Google的工作經歷,3人曾在英特爾工作。
創始人兼CEO Jonathan Ross,設計並實現第一代TPU芯片的核心元件,TPU的研發工作中有20%都由他完成。

Groq沒有走GPU路線,而是自創全球首個L(anguage)PU方案。
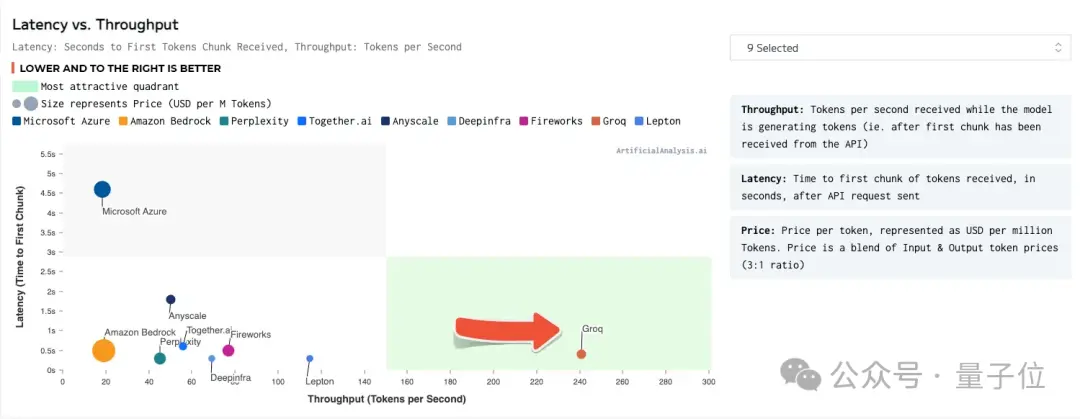
LPU的核心奧義是克服兩個LLM瓶頸——計算密度和內存帶寬,最終實現的LLM推理性能比其他基於雲平臺廠商快18倍。
據此前他們介紹,英偉達GPU需要大約10焦耳到30焦耳才能生成響應中的tokens,而 Groq 設置每個tokens大約需要1焦耳到3焦耳。
因此,推理速度提高10倍,成本卻降低十分之一,或者說性價比提高100倍。
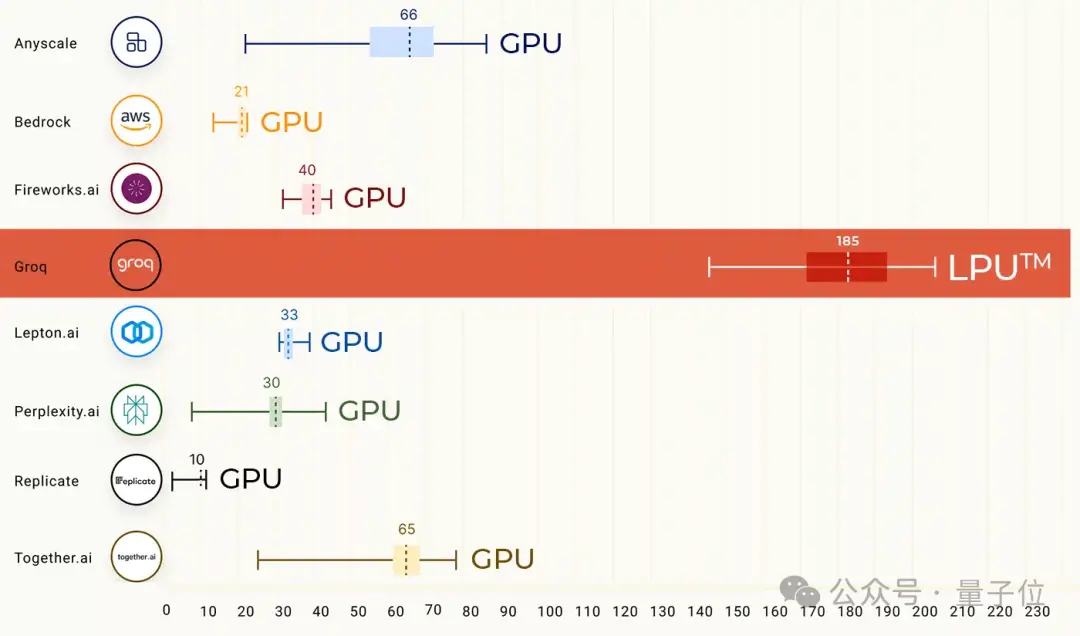
延遲方面,在運行70B模型時,輸出第一個token時的延時僅有0.22秒。
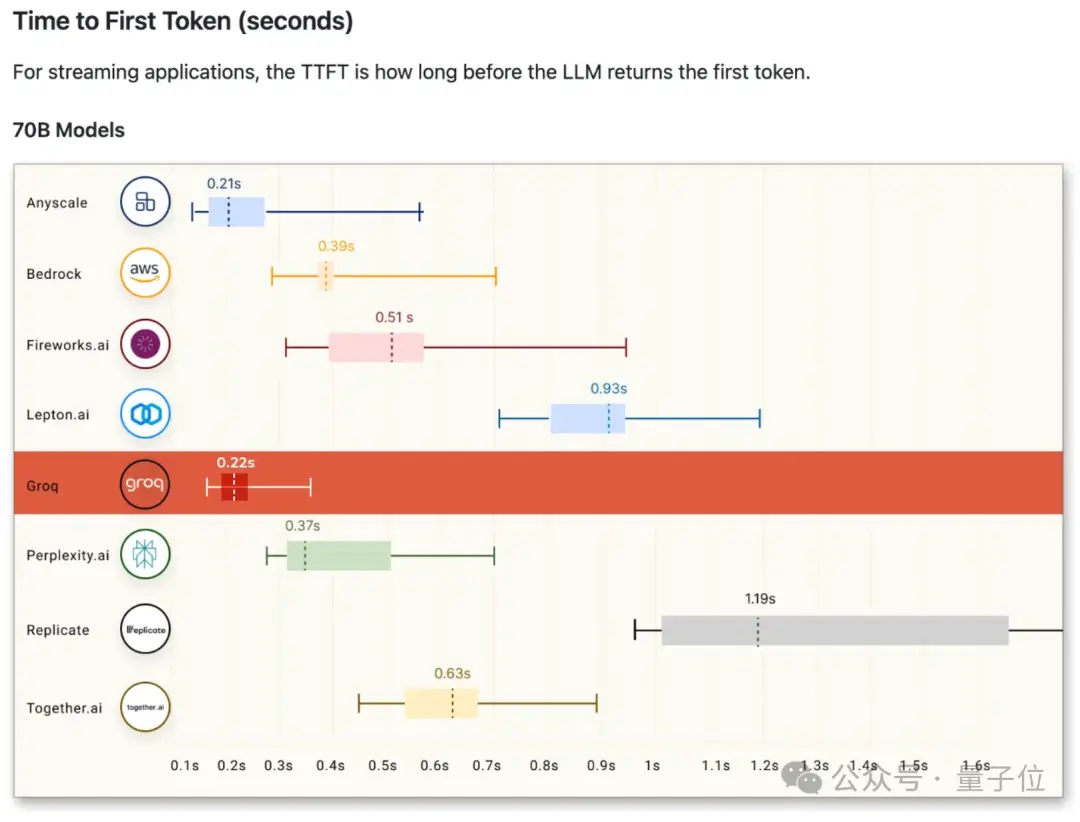
甚至為適應Groq的性能水平,第三方測評機構ArtificialAnalysis還專門調整圖表坐標軸。
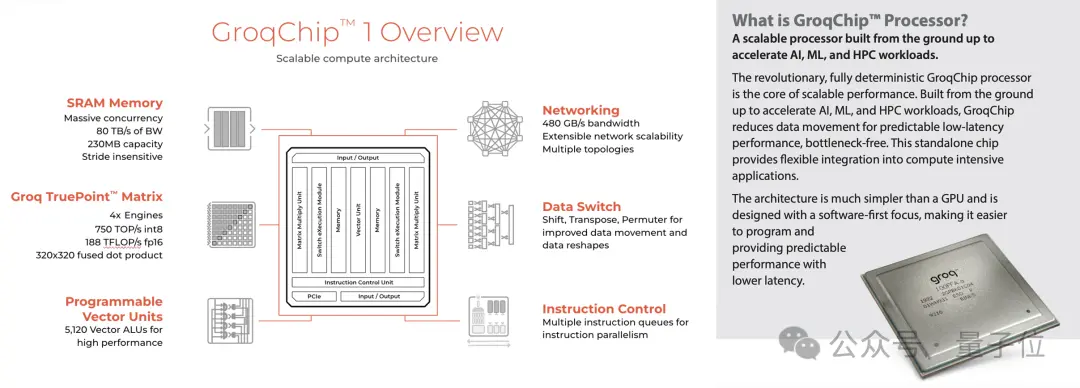
據介紹,Groq的芯片采用14nm制程,搭載230MB大SRAM來保證內存帶寬,片上內存帶寬達到80TB/s。
算力層面,Gorq芯片的整型(8位)運算速度為750TOPs,浮點(16位)運算速度則為188TFLOPs。
Groq主要基於該公司自研的TSP架構,其內存單元與向量和矩陣深度學習功能單元交錯,從而利用機器學習工作負載固有的並行性對推理進行加速。
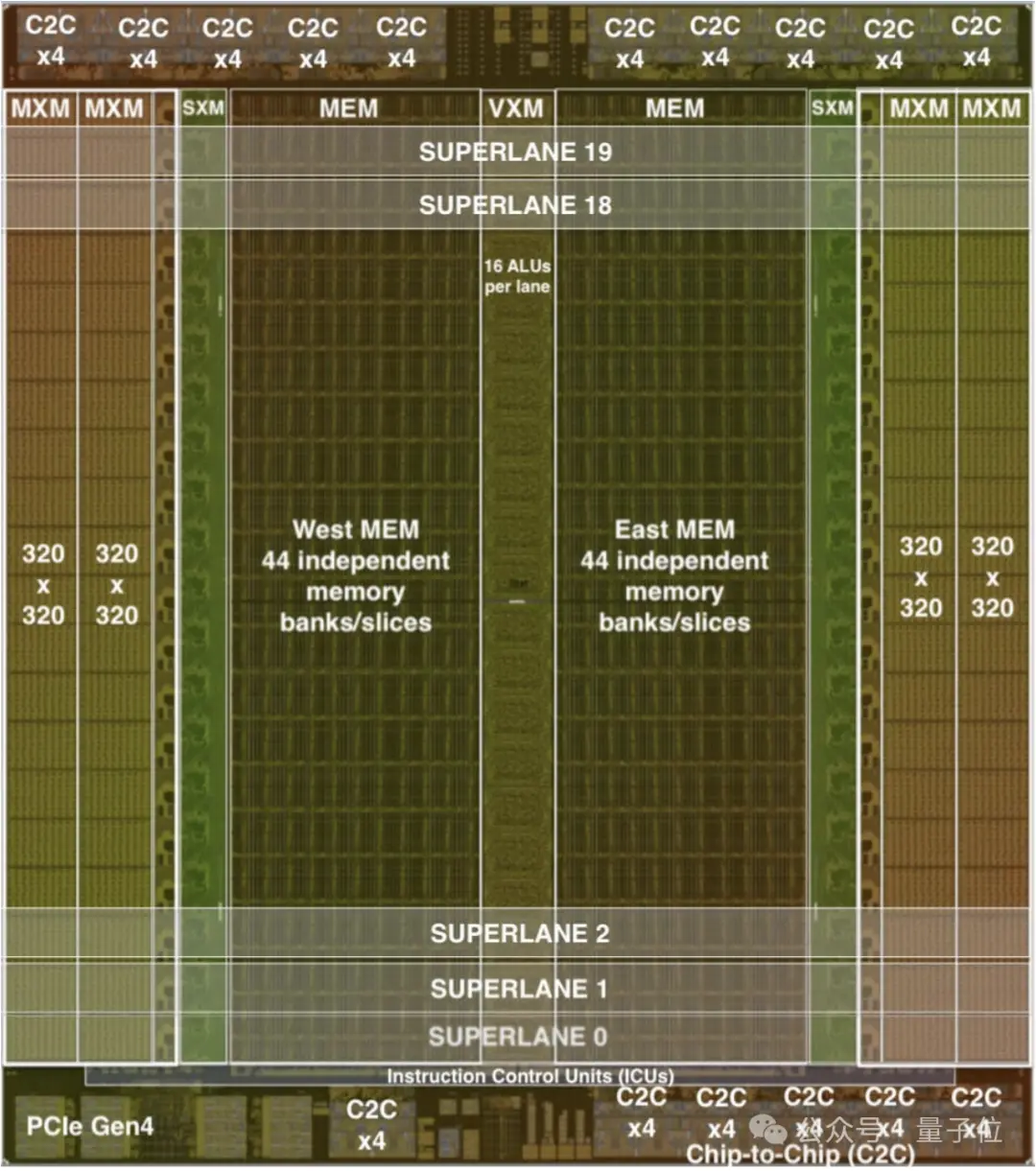
在運算處理的同時,每個TSP都還具有網絡交換的功能,可直接通過網絡與其他TSP交換信息,無需依賴外部的網絡設備,這種設計提高系統的並行處理能力和效率。
結合新設計的Dragonfly網絡拓撲,hop數減少、通信延遲降低,使得傳輸效率進一步提高;同時軟件調度網絡帶來精確的流量控制和路徑規劃,從而提高系統的整體性能。
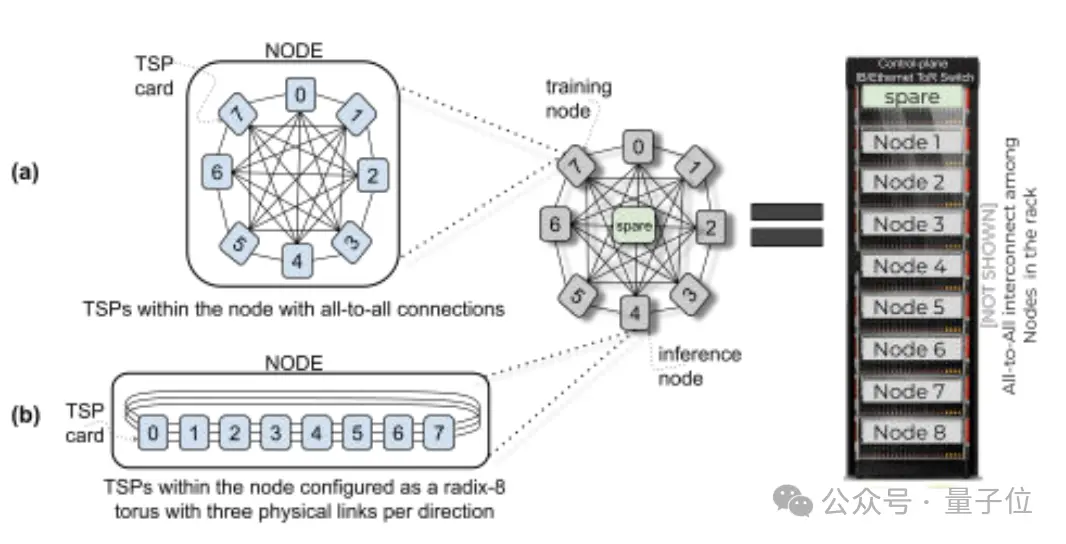
Groq支持通過PyTorch、TensorFlow等標準機器學習框架進行推理,暫不支持模型訓練。
此外Groq還提供編譯平臺和本地化硬件方案,不過並未介紹更多詳情,想要解的話需要與團隊進行聯系。

而在第三方網站上,搭載Groq芯片的加速卡售價為2萬多美元,差不多15萬人民幣。
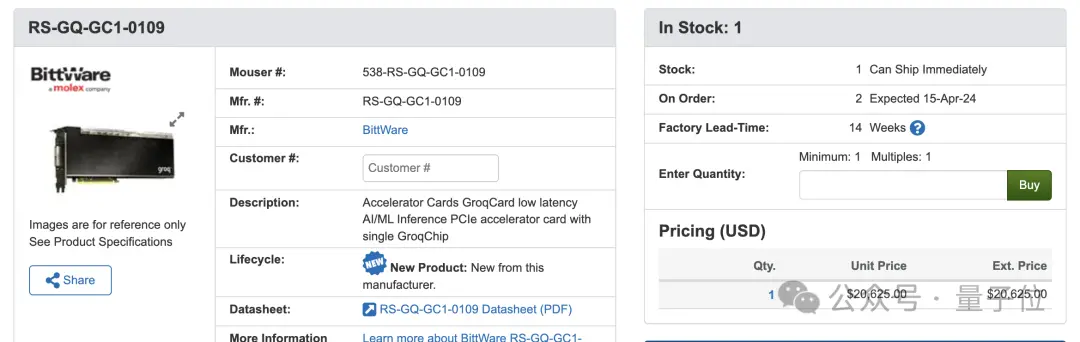
它由知名電子元件生產商莫仕(molex)旗下的BittWare代工,同時該廠也為英特爾和AMD代工加速卡。

目前,Groq的官網正在招人。
技術崗位年薪為10萬-50萬美元,非技術崗位則為9萬-47萬美元。

“目標是三年超過英偉達”
除此之外,這傢公司還有個日常操作是叫板喊話各位大佬。
當時GPTs商店推出之後,Groq就喊話奧特曼:用GPTs就跟深夜讀戰爭與和平一樣慢……陰陽怪氣直接拉滿~
馬斯克也曾被它痛斥,說“剽竊”自己的名字。

在最新討論中,他們疑似又有新操作。
一名自稱Groq工作人員的用戶與網友互動時表示,Groq的目標是打造最快的大模型硬件,並揚言:
三年時間內趕超英偉達。
這下好,黃院士的核武器有新的目標。
參考鏈接:
[1]https://wow.groq.com/
[2]https://news.ycombinator.com/item?id=39428880å