在OpenAI推出又一爆款力作AI視頻生成模型Sora後,連帶著偏上遊的AI芯片賽道熱度一點即著。創始成員來自GoogleTPU團隊的美國存算一體AI芯片公司Groq便是最新贏傢。這傢創企自稱其自研AI推理引擎LPU做到“世界最快推理”,由於其超酷的大模型速度演示、遠低於GPU的token成本,這顆AI芯片最近討論度暴漲。
連原阿裡副總裁賈揚清都公開算賬,分析LPU和H100跑大模型的采購和運營成本到底差多少。

就在Groq風風火火之際,全球最大AI芯片公司英偉達陷入一些振蕩。今日英偉達官宣將在3月18日-21日舉辦其年度技術盛會GTC24,但其股市表現卻不甚理想。受投資者快速撤股影響,英偉達今日股價降低4.35%,創去年10月以來最大跌幅,一日之間市值縮水780億美元。
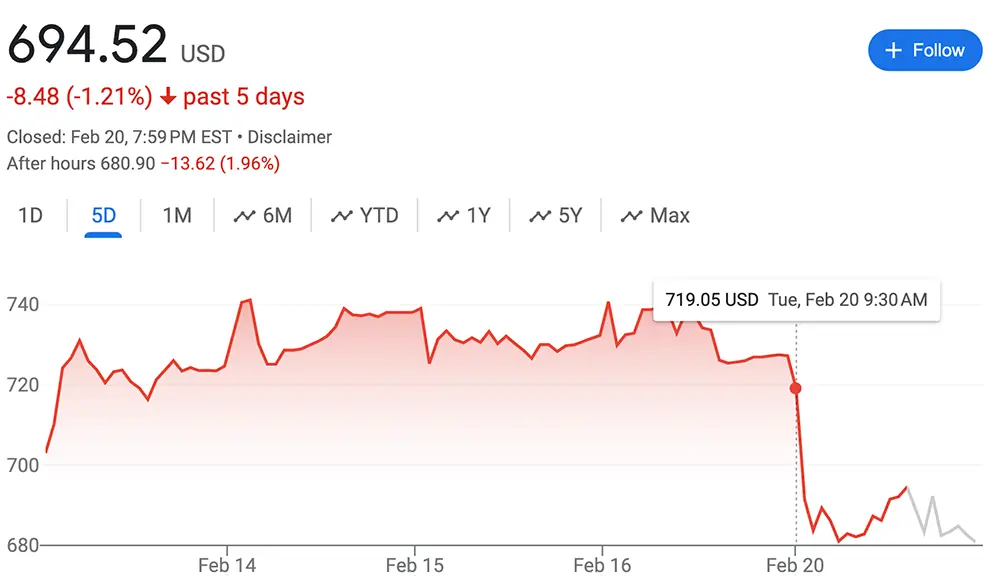
▲英偉達太平洋時間2月20日股價出現顯著下跌
Groq則在社交平臺上歡歡喜喜地頻繁發文加轉發,分享其合作夥伴及網友們對LPU的實測結果及正面評價。一些積極觀點認為,LPU將改變運行大語言模型的方式,讓本地運行成為主流。
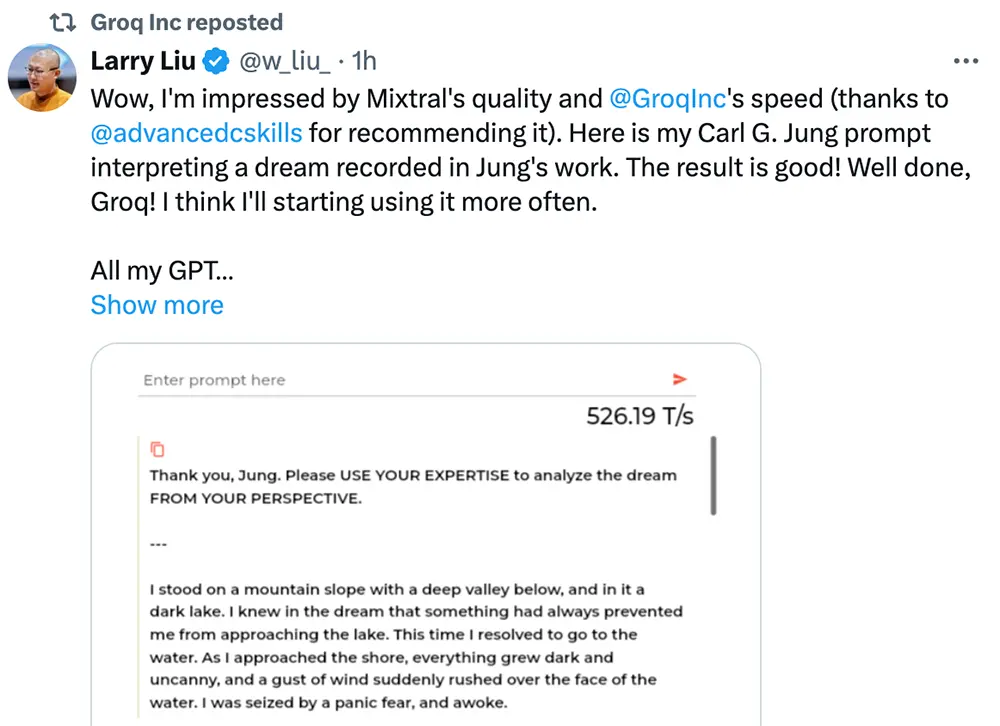
根據Groq及一些網友分享的技術演示視頻及截圖,在LPU上跑大語言模型Mixtral 8x7B-32k,生成速度快到接近甚至超過500tokens/s,遠快於公開可用的OpenAI ChatGPT 4。
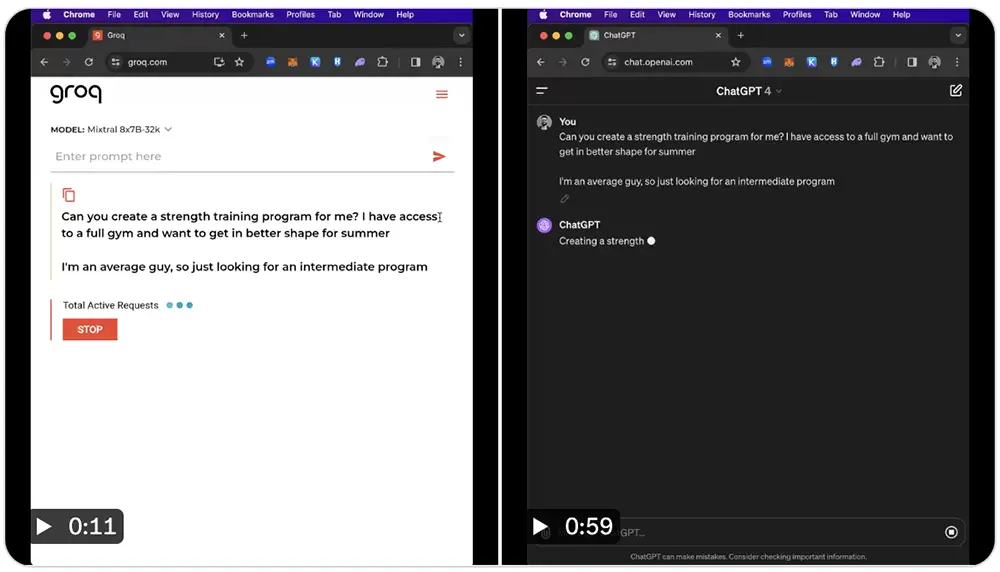
▲輸入相同指令,ChatGPT 4生成回答的時間大約1分鐘,而在Groq上運行的Mixtral 8x7B-32k隻用時11秒。
“這是一場革命,不是進化。”Groq對自己的進展信心爆棚。
2016年底,GoogleTPU核心團隊的十個人中,有八人悄悄組隊離職,在加州山景城合夥創辦新公司Groq。接著這傢公司就進入神隱狀態,直到2019年10月才通過一篇題為《世界,認識Groq》的博客,正式向世界宣告自己的存在。
隨後“官網喊話”就成Groq的特色,尤其是近期,Groq接連發文“喊話”馬斯克、薩姆·阿爾特曼、紮克伯格等AI大佬。特別是在《嘿 薩姆…》文章中,公然“嫌棄”OpenAI的機器人太慢,並給自傢LPU打廣告,聲稱運行大語言模型和其他生成式AI模型的速度是其他AI推理解決方案速度的10倍。

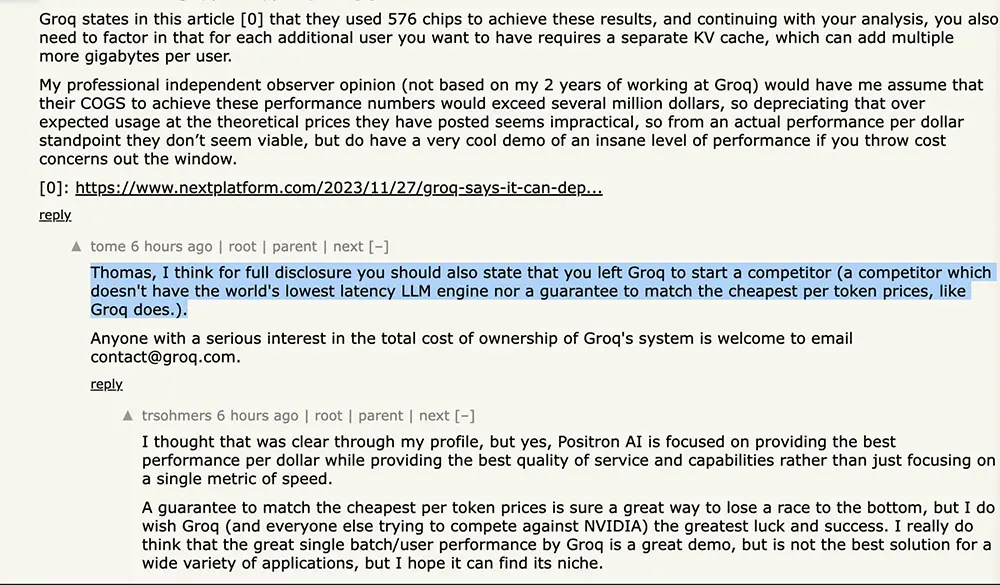
現在,Groq繼續保持著高調,除官號積極出面互動外,前員工和現員工還在論壇上“撕”起來。前員工質疑實際成本問題,現員工則抨擊這位前員工離開並創辦一傢Groq的競爭對手+沒做出“世界最低延遲的大語言模型引擎”+沒保證“匹配最便宜的token價格”。
面向LPU客戶的大語言模型API訪問已開放,提供免費10天、100萬tokens試用,可從OpenAI API切換。
Groq致力於實現最便宜的每token價格,承諾其價格“超過同等上市型號的已發佈供應商的任何已公佈的每百萬tokens價格”。
據悉,Groq下一代芯片將於2025年推出,采用三星4nm制程工藝,能效預計相較前一代提高15~20倍,尺寸將變得更大。
執行相同任務的芯片數量也將大幅減少。當前Groq需要在9個機架中用576顆芯片才能完成Llama 2 70B推理,而到2025年完成這一任務可能隻需在2個機架使用大約100個芯片。
01.
1秒內寫出數百個單詞,
輸出tokens吞吐量最高比競品快18倍
按照Groq的說法,其AI推理芯片能將運行大語言模型的速度提高10倍、能效提高10倍。
要體驗LPU上的大語言模型,需先創建一個Groq賬戶。
輸入提示詞“美國最好的披薩是什麼?”跑在LPU上的Mixtral模型飛速給出回答,比以前慢慢生成一行一行字的體驗好很多。
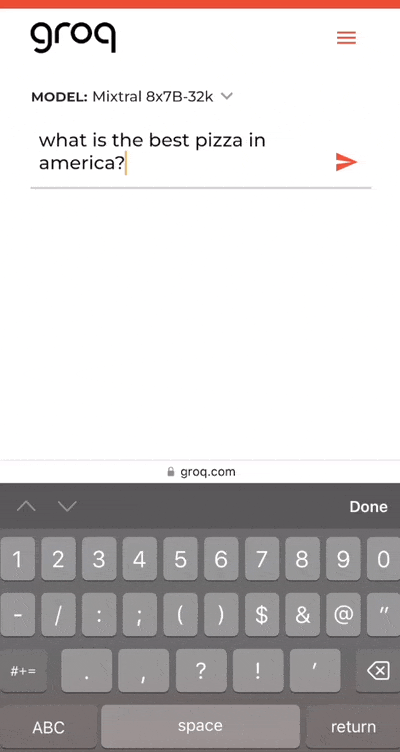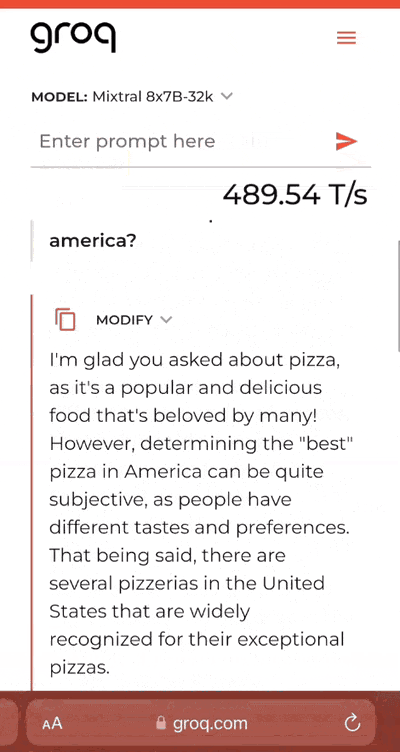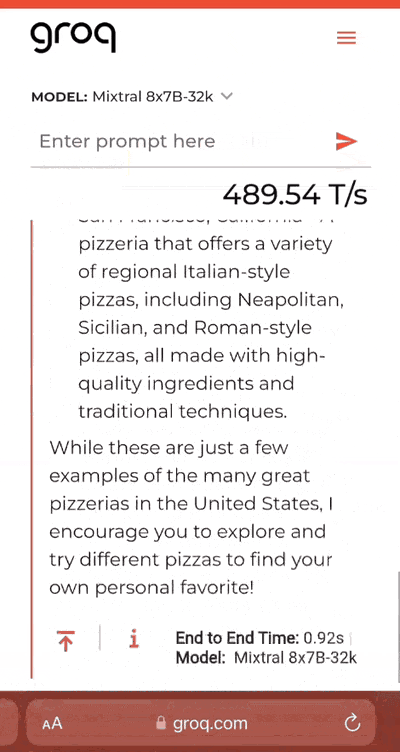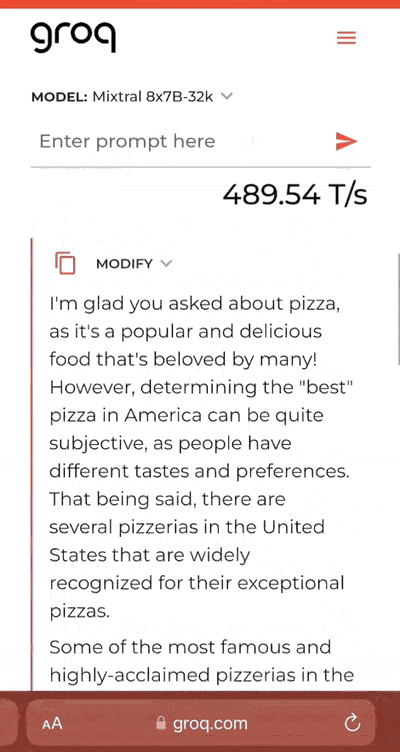
它還支持對生成的答案進行修改。
在公開的大語言模型基準測試上,LPU取得壓倒性戰績,運行Meta AI大語言模型Llama 2 70B時,輸出tokens吞吐量比所有其他基於雲的推理供應商最高要快18倍。
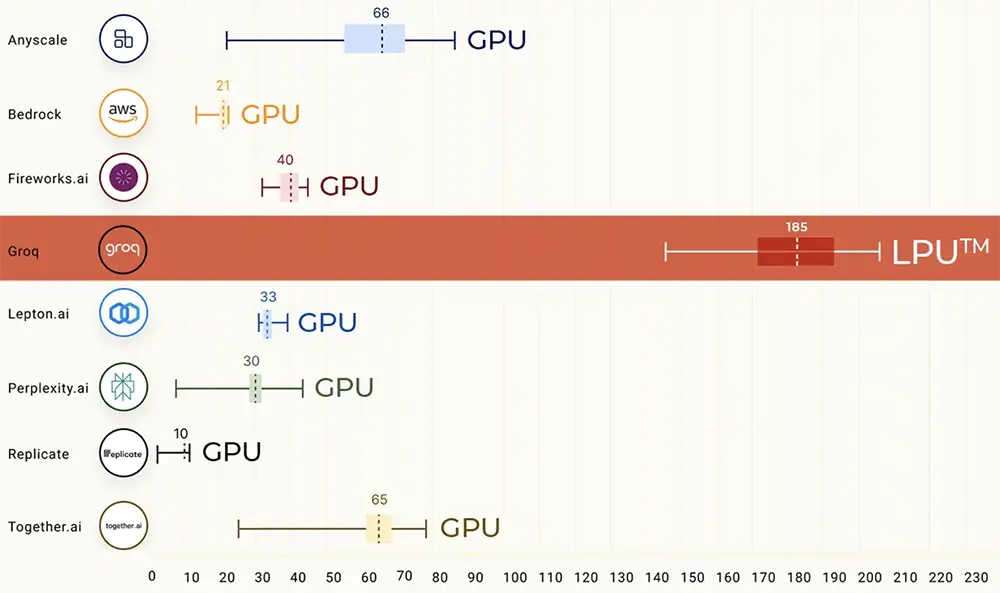
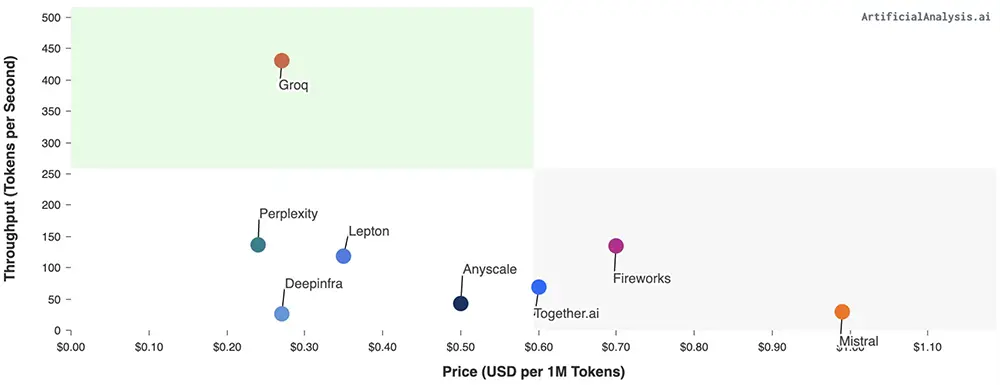
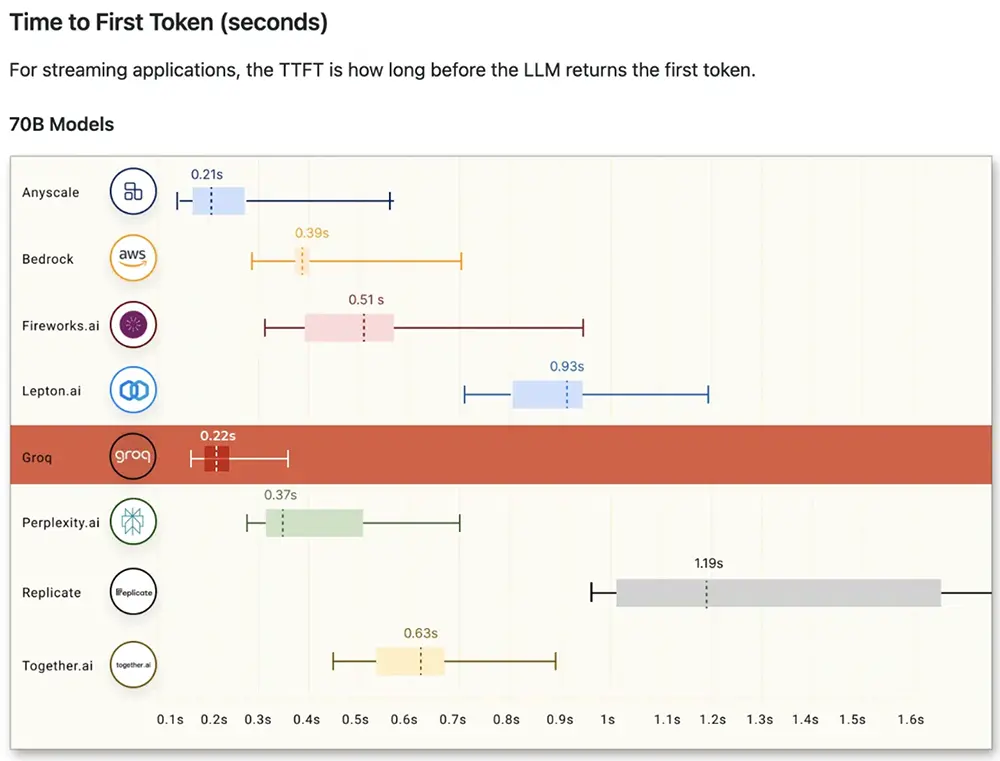
對於Time to First Token,其縮短到0.22秒。由於LPU的確定性設計,響應時間是一致的,從而使其API提供最小的可變性范圍。這意味著更多的可重復性和更少的圍繞潛在延遲問題或緩慢響應的設計工作。
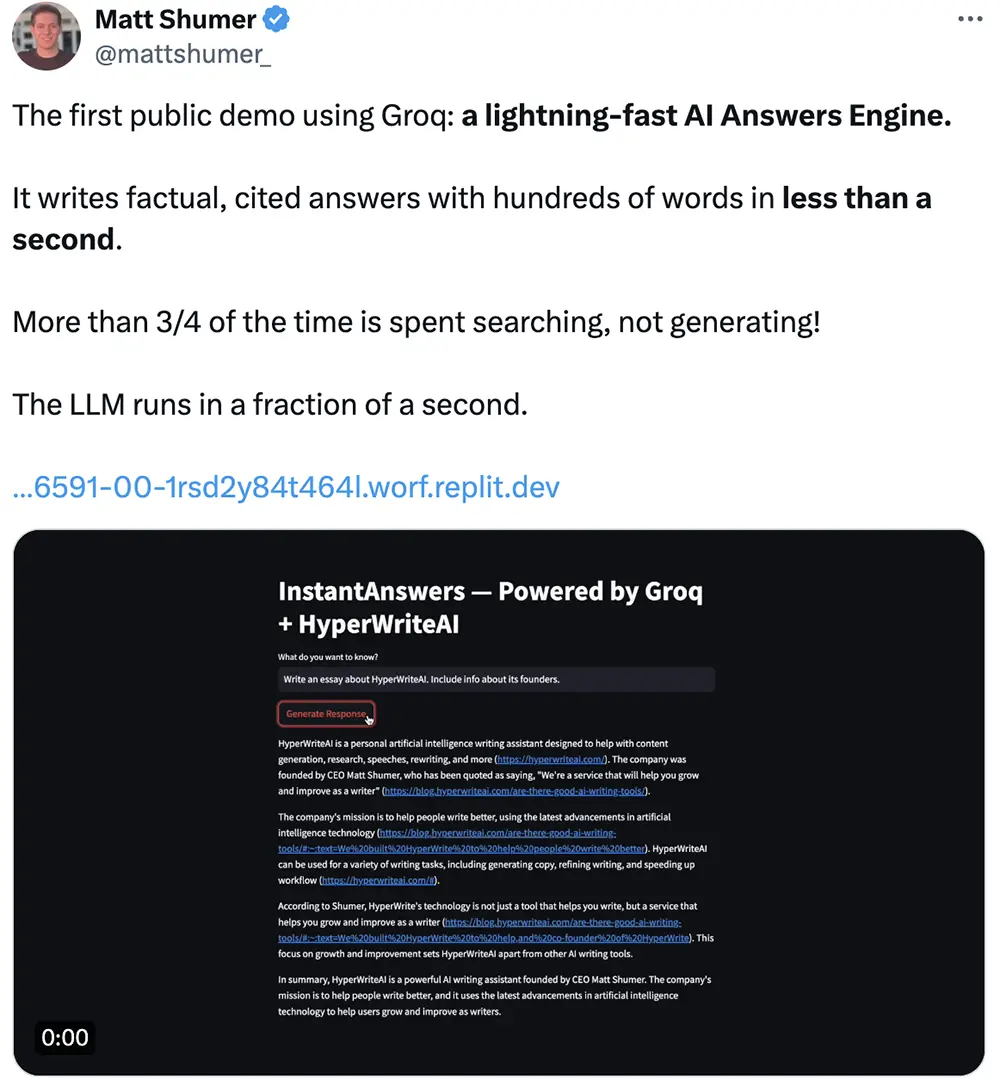
AI寫作助手創企HyperWriteAI的CEO Matt Shumer評價LPU“快如閃電”,“不到1秒寫出數百個單詞”,“超過3/4的時間花在搜索上,而非生成”,“大語言模型的運行時間隻有幾分之一秒”。
有網友分享圖像生成的區域提示,並評價“非常印象深刻”。
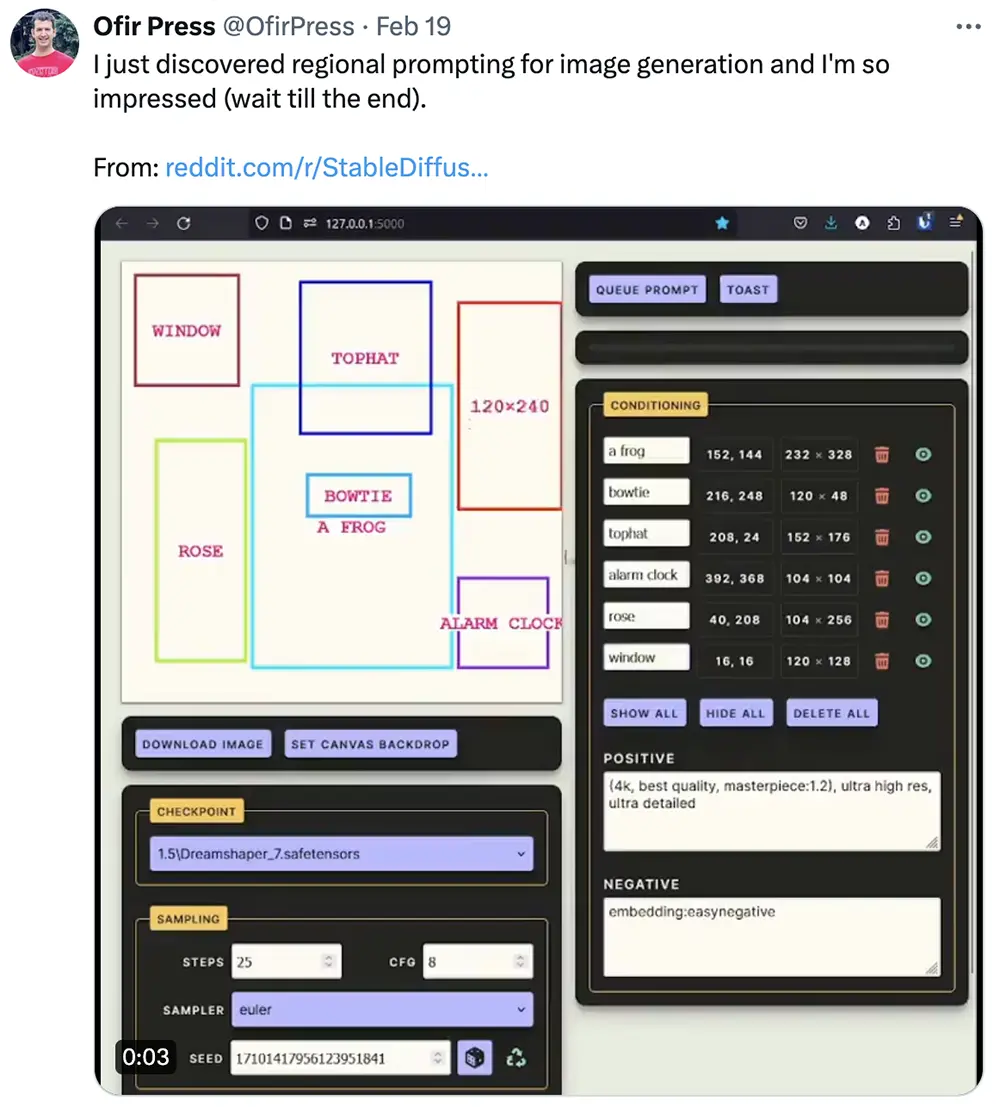
02.
賈揚清分析采購和運營成本:
比H100服務器貴多
Groq芯片采用14nm制程工藝,搭載230MB片上共享SRAM,內存帶寬達80TB/s,FP16算力為188TFLOPS,int8算力為750TOPS。
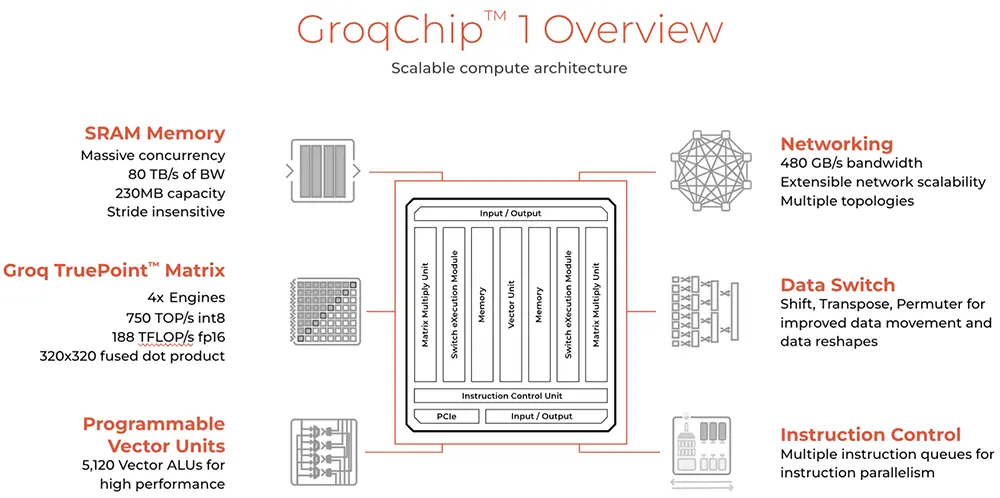
Groq在社交平臺上解答一些常見問題:1、LPU為每token提供很好的價格,因為效率高而且擁有從芯片到系統的堆棧,沒有中間商;2、不賣卡/芯片,除非第三方供應商將其出售給研究/科學應用團體,銷售內部系統;3、其設計適用於大型系統,而非單卡用戶,Groq的優勢來自大規模的設計創新。
與很多大模型芯片不同的是,Groq的芯片沒有HBM、沒有CoWoS,因此不受HBM供應短缺的限制。
在對Meta Llama 2模型做推理基準測試時,Groq將576個芯片互連。按照此前Groq分享的計算方法,英偉達GPU需要大約10~30J來生成token,而Groq每token大約需要1~3J,也就是說推理速度是原來的10倍,成本是原來的1/10,或者說性價比提高100倍。
Groq拿一臺英偉達服務器和8機架Groq設備做對比,並聲稱非常確定配備576個LPU的Groq系統成本不到英偉達DGX H100的1/10,而後者的運行價格已超過40萬美元。等於說Groq系統能實現10倍的速度下,總成本隻有1/10,即消耗的空間越多,就越省錢。
自稱是“Groq超級粉絲”的原阿裡副總裁、創辦AI infra創企Lepton AI的賈揚清則從另一個角度來考慮性價比,據他分析,與同等算力的英偉達H100服務器成本比較,Groq LPU服務器實際要耗費更高的硬件采購成本和運營成本:

1. 每張Groq卡的內存為230MB。對於Llama 70B模型,假設采用int8量化,完全不計推理的內存消耗,則最少需要305張卡。實際上需要的更多,有報道是572張卡,因此我們按照572張卡來計算。
2. 每張Groq卡的價格為2萬美元,因此購買572張卡的成本為1144萬美元。當然,因為銷售策略和規模效益,每張卡的價格可能打折,姑且按照目錄價來計算。
3. 572張卡,每張卡的功耗平均是185W,不考慮外設,總功耗為105.8kW。(註意,實際會更高)
4. 現在數據中心平均每千瓦每月的價格在200美元左右,也就是說,每年的電費是105.8 x 200 x 12 = 25.4萬美元。(註意,實際會更高)
5. 基本上,采用4張H100卡可實現Groq的一半性能,也就是說,一臺8卡H100與上面的性能相當。8卡H100的標稱最大功率為10kW(實際大概在8-9kW),因此每年電費為2.4萬美元或更低一些。
6. 今天8卡H100的采購成本約為30萬美元。
7. 因此,如果運行三年,Groq的硬件采購成本是1144萬美元,運營成本是76.2萬美元或更高。8卡H100的硬件購買成本是30萬美元,運營成本為7.2萬美元或更低一些。
如果按這個算法,運行3年,Groq的采購成本將是H100的38倍,運營成本將是H100的10倍。
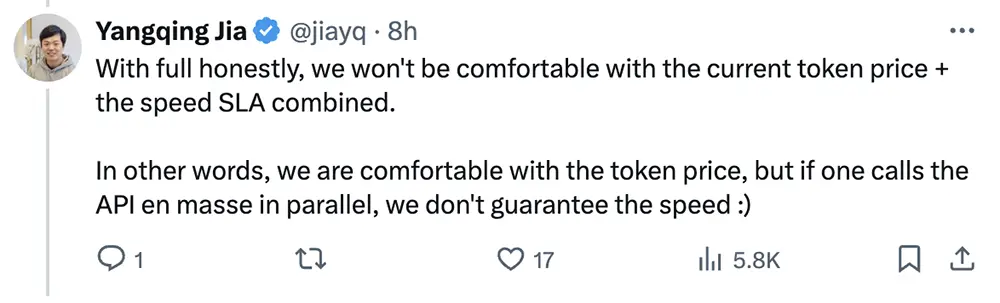
賈揚清還在評論區談道:“老實說,我們對當前的token價格+速度SLA組合感到不適。換句話說,我們對token價格感到滿意,但如果並行調用API,我們無法保證速度。”
03.
存算一體+軟件定義硬件:
編譯器優先,開發速度快,易定制調試
Groq聯合創始人兼CEO Jonathan Ross曾宣稱,相比用英偉達GPU,LPU集群將為大語言推理提供更高吞吐量、更低延遲、更低成本。
“12個月內,我們可以部署10萬個LPU;24個月內,我們可以部署100萬個LPU。”Ross說。

▲Groq領導層
根據官網信息,LPU代表語言處理單元,是Groq打造的一種新型端到端處理單元,旨在克服大語言模型的計算密度和內存帶寬瓶頸,計算能力超過GPU和CPU,能夠減少計算每個單詞所需時間,更快生成文本序列。消除外部內存瓶頸使得LPU推理引擎能夠在大語言模型上提供比GPU好幾個數量級的性能。

LPU采用單核心時序指令集計算機架構,無需像傳使用高帶寬存儲(HBM)的GPU那樣頻繁從內存中加載數據,能有效利用每個時鐘周期,降低成本。
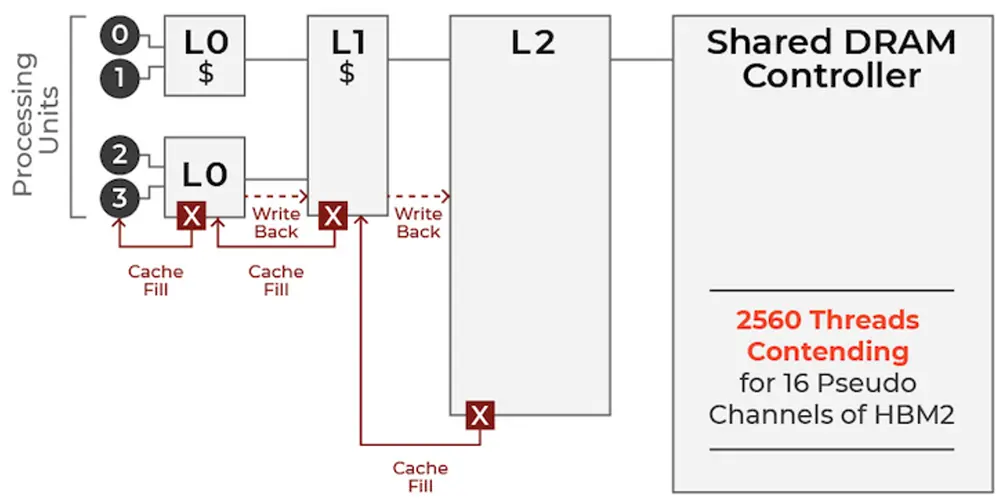
▲傳統GPU內存結構
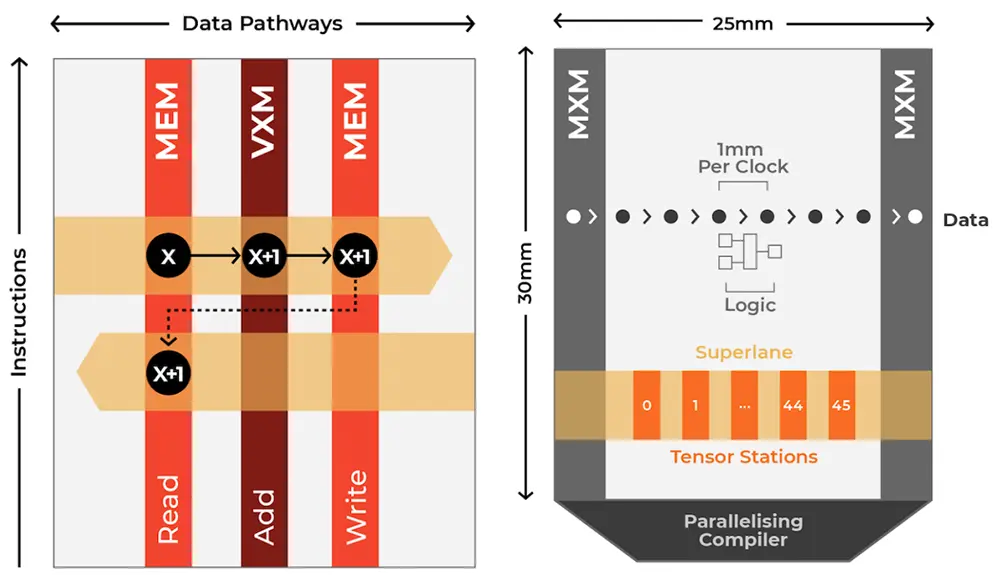
▲Groq芯片內存結構
Groq芯片的指令是垂直走向,而數據流向東西流動,利用位置和功能單元相交以執行操作。通過將計算和內存訪問解耦,Groq的芯片在處理數據時能進行大量讀寫,即一步之內有效進行計算與通信,提供低延遲、高性能和可預測的準確性。
其特點包括出色的時序性能、單核架構、大規模部署可維護的同步網絡、能自動編譯超過500億參數的大語言模型、即時內存訪問、較低精度水平下保持高準確度。

▲單個LPU架構
“編譯器優先”是Groq的秘密武器,使其硬件媲美專用集成電路(AISC)。但與功能固定的AISC不同的是,Groq采用軟件定義硬件的思路,利用一個可以適應和優化不同模型的自定義編譯器,使其編譯器和體系結構共同構成一個精簡的、穩健的機器學習推理引擎,支持自定義優化,以平衡性能與靈活性。
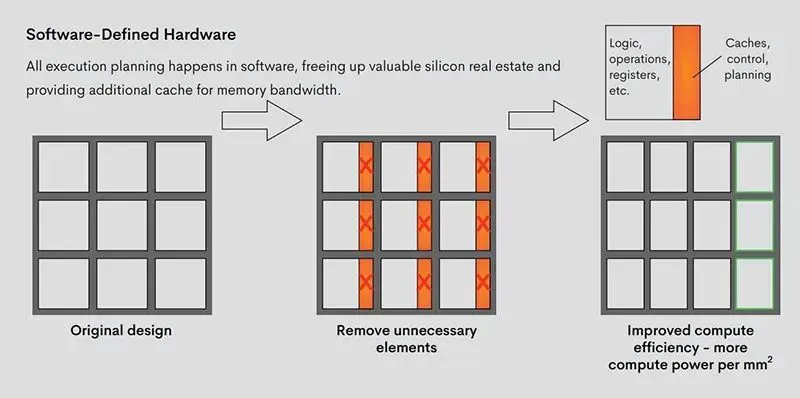
▲Groq的簡化軟件定義硬件方法釋放額外的芯片空間和處理能力
受軟件優先思想的啟發,Groq將執行控制和數據流控制的決策步驟從硬件轉移到編譯器,以調度跨網絡的數據移動。所有執行計劃都在軟件棧中進行,不再需要硬件調度器來弄清楚如何將東西搬到芯片上。這釋放寶貴的芯片空間,並提供額外的內存帶寬和晶體管來提高性能。
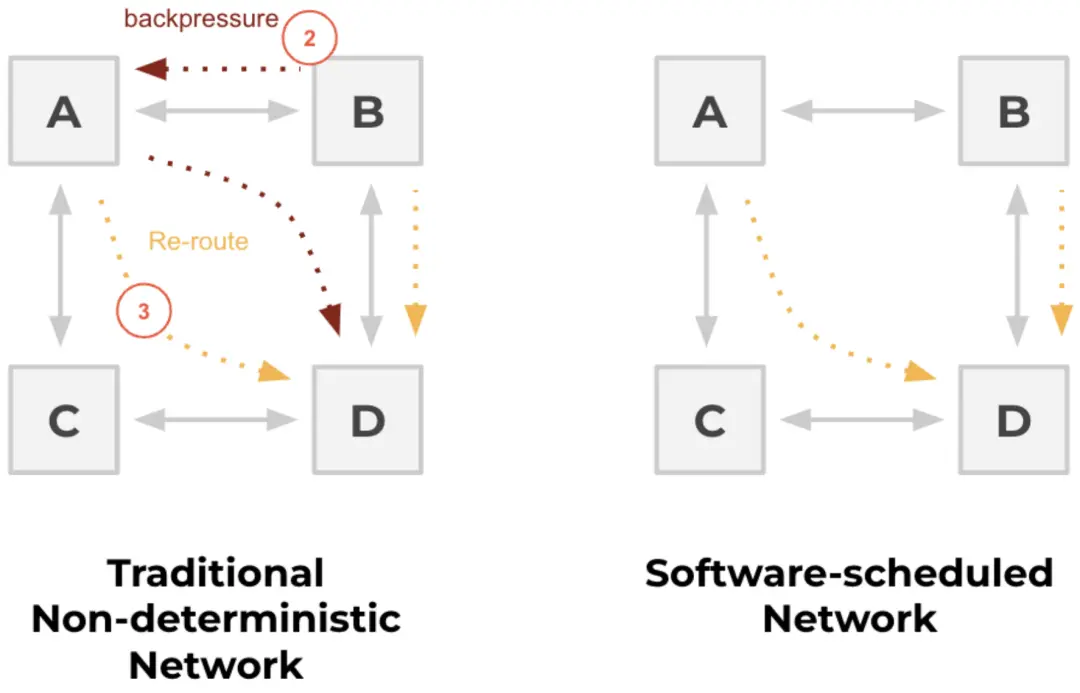
▲傳統的非確定性網絡與軟件調度網絡的比較
Groq的簡化架構去除芯片上對AI沒有任何處理優勢的多餘電路,實現更高效的芯片設計,每平方毫米的性能更高。其芯片將大量的算術邏輯單元與大量的片上內存結合,並擁有充足帶寬。
由於控制流程已進入軟件棧,硬件是一致且可預測的,開發人員可以精確獲知內存使用情況、模型效率和延遲。這種確定性設計使用戶可在將多芯片擴展連接時,精確把控運行一次計算需要多長時間,更加專註於算法並更快地部署解決方案,從而簡化生產流程。
擴展性方面,當Groq芯片擴展到8卡、16卡、64卡,所支持的性能和延遲如下:
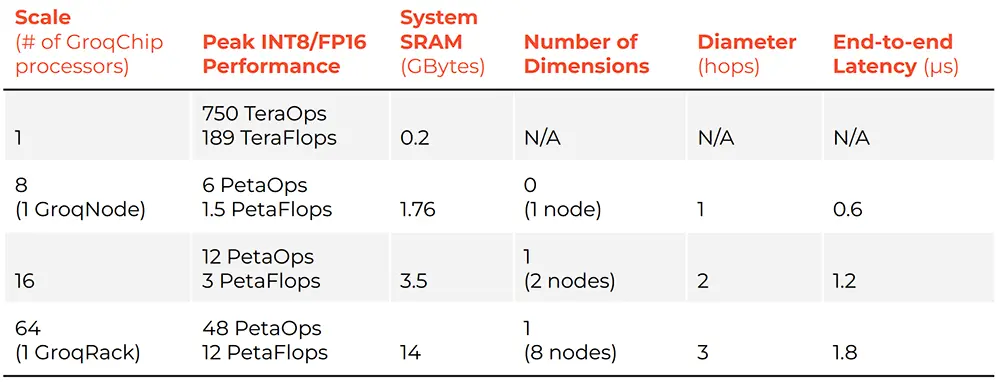
Groq工程師認為,必須謹慎使用HBM的原因是它不僅涉及延遲,還有“非確定性”問題。LPU架構的一大好處是可以構建能快速互連的數百個芯片的系統,並知道整個系統的精確時間在百萬分之幾以內。而一旦開始集成非確定性組件,就很難確保對延遲的承諾。
04.
結語:AI芯片是時候上演新故事
Groq氣勢洶洶地向“世界最快大模型推理芯片”的目標發起總攻,給高性能AI推理市場帶來新的期待。
在系統級芯片采購和運營成本方面,Groq可能還難以做到與H100匹敵,但從出色的單batch處理和壓低token價格來看,其LPU推理引擎已經展現出相當的吸引力。
隨著生成式AI應用進入落地潮,AI芯片賽道也是時候多上演一些新故事。