LeCun一如既往地不看好自回歸LLM。機器如何能像人類和動物一樣高效地學習?機器如何學習世界運作方式並獲得常識?機器如何學習推理和規劃……當一系列問題被提出時,有人回答自回歸LLM足以勝任。然而,知名AI學者、圖靈獎得主YannLeCun並不這麼認為,他一直唱衰自回歸LLM。近日LeCun在哈佛大學的演講內容深入探討這些問題,內容長達95頁,可謂幹貨滿滿。
LeCun 給出一個模塊化的認知架構,它可能構成回答這些問題的途徑。該架構的核心是一個可預測的世界模型,它允許系統預測其行動的後果,並規劃一系列行動來優化一組目標。
目標包括保證系統可控性和安全性的護欄。世界模型采用經過自監督學習訓練的分層聯合嵌入預測架構(H-JEPA)。

LeCun 的演講圍繞多方面展開。
開始部分,LeCun 介紹目標驅動的人工智能。LeCun 指出與人類、動物相比,機器學習真的爛透,一個青少年可以在大約 20 小時的練習中學會開車,小朋友可以在幾分鐘內學會清理餐桌。
相比之下,為可靠,當前的 ML 系統需要通過大量試驗進行訓練,以便在訓練期間可以覆蓋最意外的情況。盡管如此,最好的 ML 系統在現實世界任務(例如駕駛)中仍遠未達到人類可靠性。
我們距離達到人類水平的人工智能還差得很遠,需要幾年甚至幾十年的時間。在實現這一目標之前,或許會先實現擁有貓類(或者狗類)級別智能的 AI。LeCun 強調 AI 系統應該朝著能夠學習、記憶、推理、規劃、有常識、可操縱且安全的方向發展。
LeCun 再一次表達對自回歸 LLM 的不滿(從 ChatGPT 到 Sora,OpenAI 都是采用的自回歸生成式路線),雖然這種技術路線已經充斥整個 AI 界,但存在事實錯誤、邏輯錯誤、不一致、推理有限、毒性等缺陷。此外,自回歸 LLM 對潛在現實的解有限,缺乏常識,沒有記憶,而且無法規劃答案。
在他看來,自回歸 LLM 僅僅是世界模型的一種簡化的特殊情況。為實現世界模型,LeCun 給出的解決方案是聯合嵌入預測架構(JEPA)。
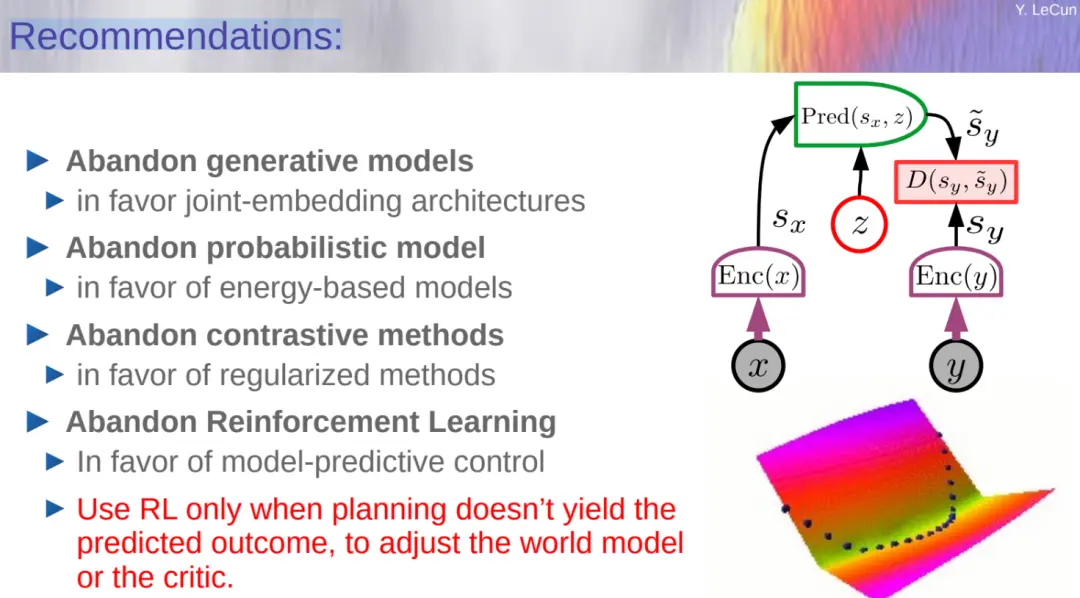
LeCun 花大量篇幅介紹 JEPA 相關技術,最後他給出簡單的總結:放棄生成模型,支持聯合嵌入架構;放棄概率模型,支持基於能量的模型(EBM);放棄對比方法,支持正則化方法;放棄強化學習,支持模型 - 預測控制;僅當規劃無法產生結果時才使用強化學習來調整世界模型。
在開源問題上,LeCun 認為開源 AI 不應該因為監管而消失,人工智能平臺應該是開源的,否則,技術將被幾傢公司所掌控。不過為安全起見,大傢還是需要設置共享護欄目標。
對於 AGI,LeCun 認為根本不存在 AGI,因為智能是高度多維的。雖然現在 AI 隻在一些狹窄的領域超越人類,毫無疑問的是,機器最終將超越人類智能。

機器學習爛透,距離人類水平的 AI 還差得遠
LeCun 指出 AI 系統應該朝著能夠學習、記憶、推理、規劃、有常識、可操縱且安全的方向發展。在他看來,與人類和動物相比,機器學習真的爛透,LeCun 指出如下原因:
監督學習(SL)需要大量標註樣本;
強化學習(RL)需要大量的試驗;
自監督學習(SSL)效果很好,但生成結果僅適用於文本和其他離散模式。
與此不同的是,動物和人類可以很快地學習新任務、解世界如何運作,並且他們(人類和動物)都有常識。

隨後,LeCun 表示人類需要的 AI 智能助理需要達到人類級別。但是,我們今天距離人類水平的人工智能還差得很遠。
舉例來說,17 歲的少年可以通過 20 小時的訓練學會駕駛(但 AI 仍然沒有無限制的 L5 級自動駕駛),10 歲的孩子可以在幾分鐘內學會清理餐桌,但是現在的 AI 系統還遠未達到。現階段,莫拉維克悖論不斷上演,對人類來說很容易的事情對人工智能來說很難,反之亦然。
那麼,我們想要達到高級機器智能(Advanced Machine Intelligence,AMI),需要做到如下:
從感官輸入中學習世界模型的 AI 系統;
具有持久記憶的系統;
具有規劃行動的系統;
可控和安全的系統;
目標驅動的 AI 架構(LeCun 重點強調這一條)。

自回歸 LLM 糟糕透
自監督學習已經被廣泛用於理解和生成文本,圖像,視頻,3D 模型,語音,蛋白質等。大傢熟悉的研究包括去噪 Auto-Encoder、BERT、RoBERTa。
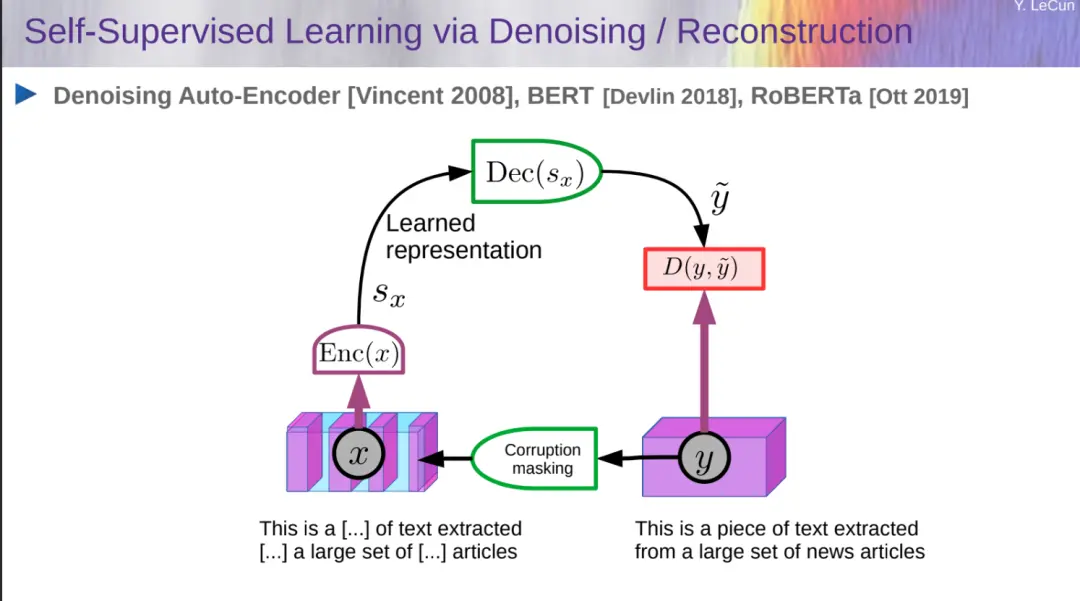
LeCun 接著介紹生成式 AI 和自回歸大語言模型。自回歸生成架構如下所示:
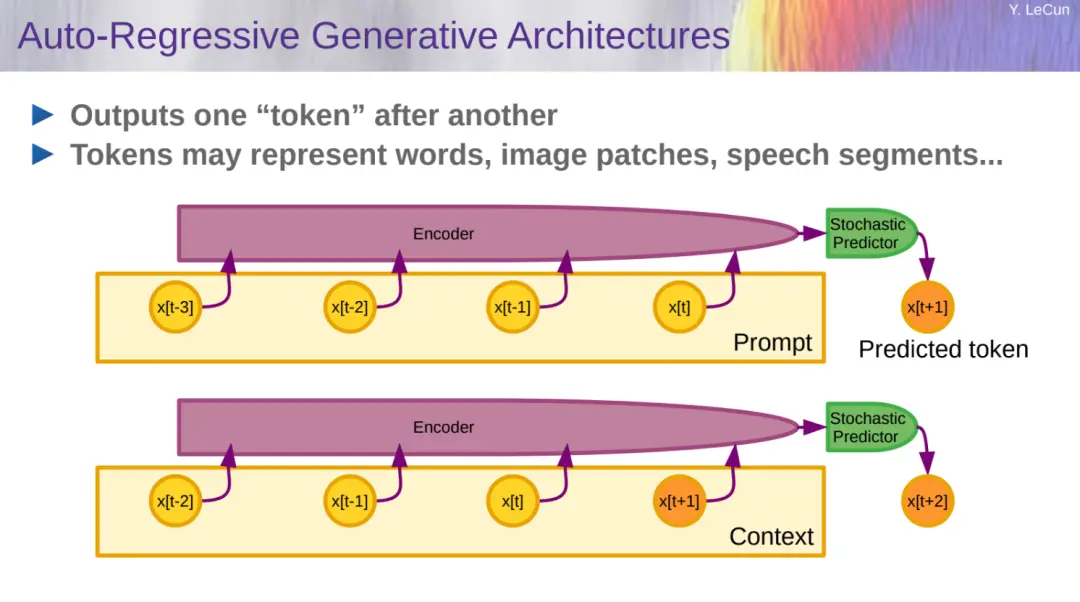
自回歸大語言模型(AR-LLM)參數量從 1B 到 500B 不等、訓練數據從 1 到 2 萬億 token。ChatGPT、Gemini 等大傢熟悉的模型都是采用這種架構。
LeCun 認為雖然這些模型表現驚人,但它們經常出現愚蠢的錯誤,比如事實錯誤、邏輯錯誤、不一致、推理有限、毒性等。此外,LLM 對潛在現實的解有限,缺乏常識,沒有記憶,而且無法規劃答案。

LeCun 進一步指出自回歸 LLM 很糟糕,註定要失敗。這些模型不可控、呈指數發散,並且這種缺陷很難修復。

此外,自回歸 LLM 沒有規劃,充其量就是大腦中的一小部分區域。

雖然自回歸 LLM 在協助寫作、初稿生成、文本潤色、編程等方面表現出色。但它們經常會出現幻覺,並且在推理、規劃、數學等方面表現不佳,需要借助外部工具才能完成任務。用戶很容易被 LLM 生成的答案所迷惑,此外自回歸 LLM 也不知道世界是如何運轉的。

LeCun 認為當前 AI 技術(仍然)距離人類水平還很遠,機器不會像動物和人類那樣學習世界的運作方式。目前看來自回歸 LLM 無法接近人類智力水平,盡管 AI 在某些狹窄的領域超過人類。但毫無疑問的是,最終機器將在所有領域超越人類智慧。

目標驅動的 AI
在 LeCun 看來,目標驅動的 AI 即自主智能(autonomous intelligence)是一個很好的解決方案,其包括多個配置,一些模塊可以即時配置,它們的具體功能由配置器(configurator)模塊確定。
配置器的作用是執行控制:給定要執行的任務,它預先配置針對當前任務的感知(perception)、世界模型(world model)、成本(cost)和參與者(actor)。
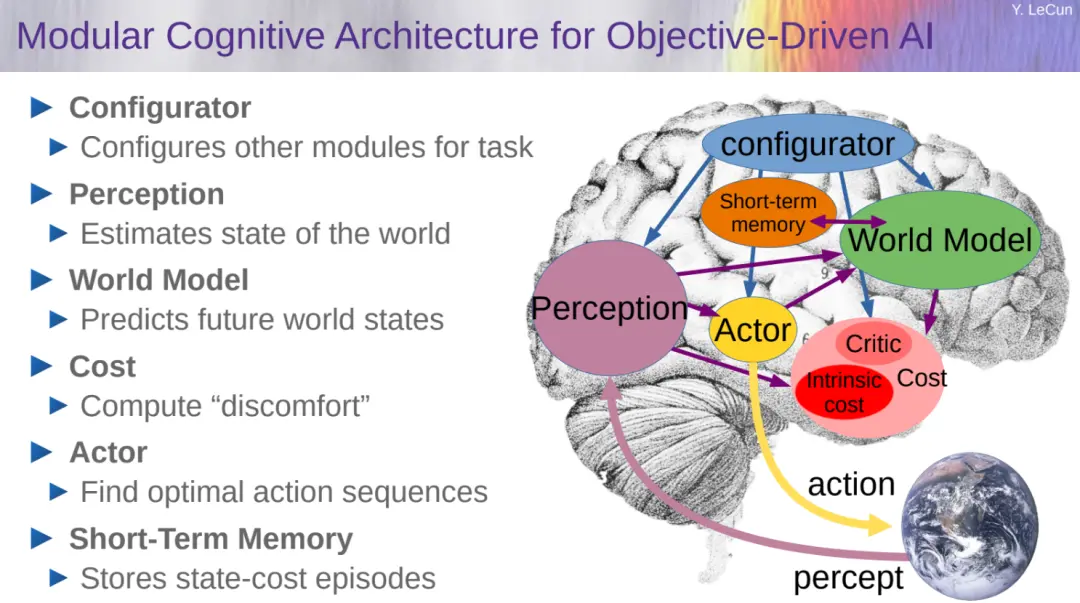
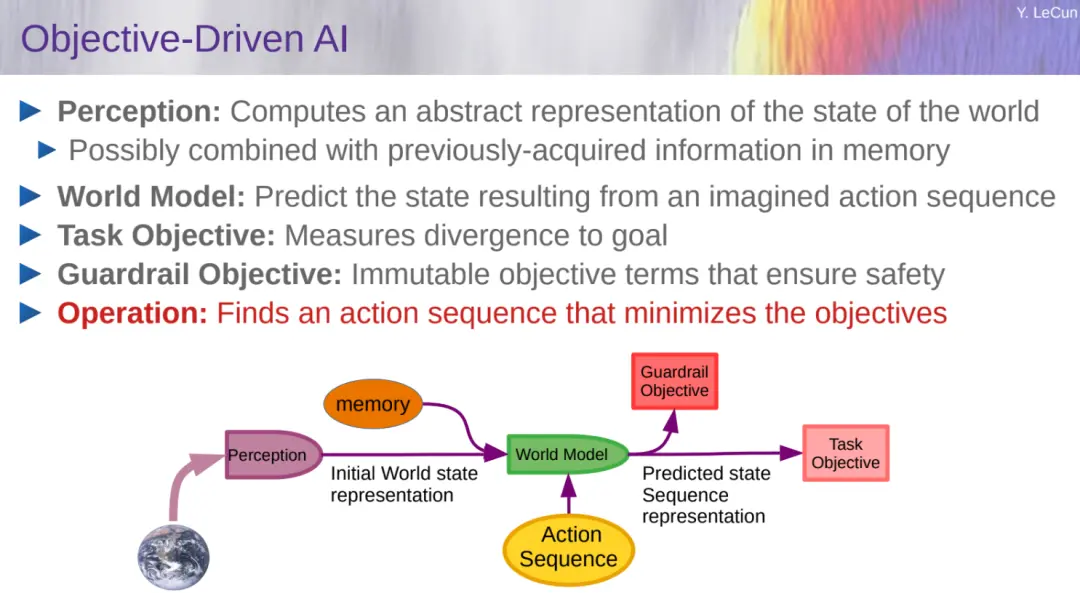
關於這部分內容,大傢可以參考:思考總結 10 年,圖靈獎得主 Yann LeCun 指明下一代 AI 方向:自主機器智能
目標驅動的 AI 中最復雜的部分是世界模型的設計。
設計和訓練世界模型
關於這部分內容,我們先看 LeCun 給出的建議:
放棄生成模型,支持聯合嵌入架構;
放棄概率模型,支持基於能量的模型(EBM);
放棄對比方法,支持正則化方法;
放棄強化學習,支持模型 - 預測控制;
僅當規劃無法產生結果時才使用強化學習來調整世界模型。
LeCun 指出生成架構不適用於圖像任務,未來幾十年阻礙人工智能發展的真正障礙是為世界模型設計架構以及訓練范式。
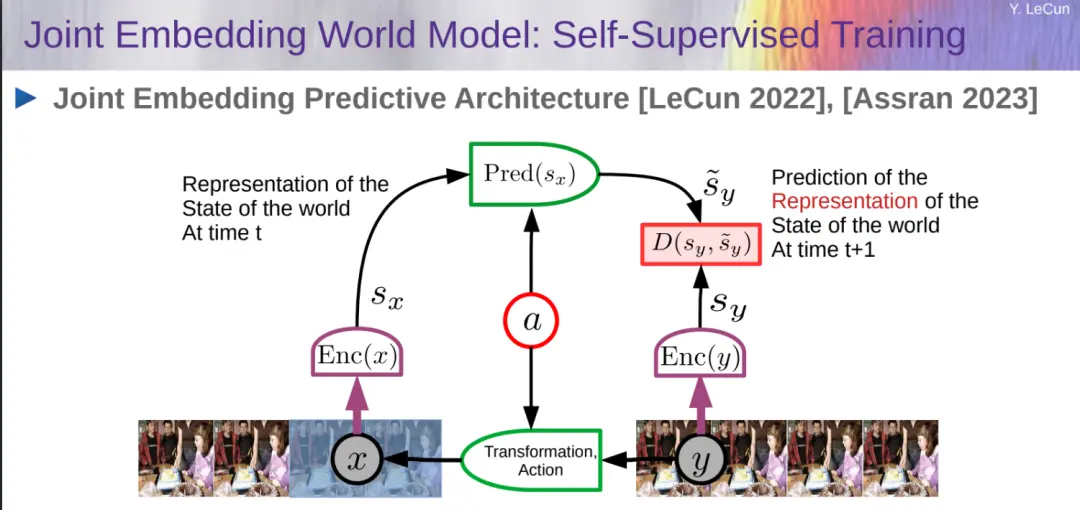
訓練世界模型是自監督學習(SSL)中的一個典型例子,其基本思想是模式補全。對未來輸入(或暫時未觀察到的輸入)的預測是模式補全的一個特例。在這項工作中,世界模型旨在預測世界狀態未來表征。

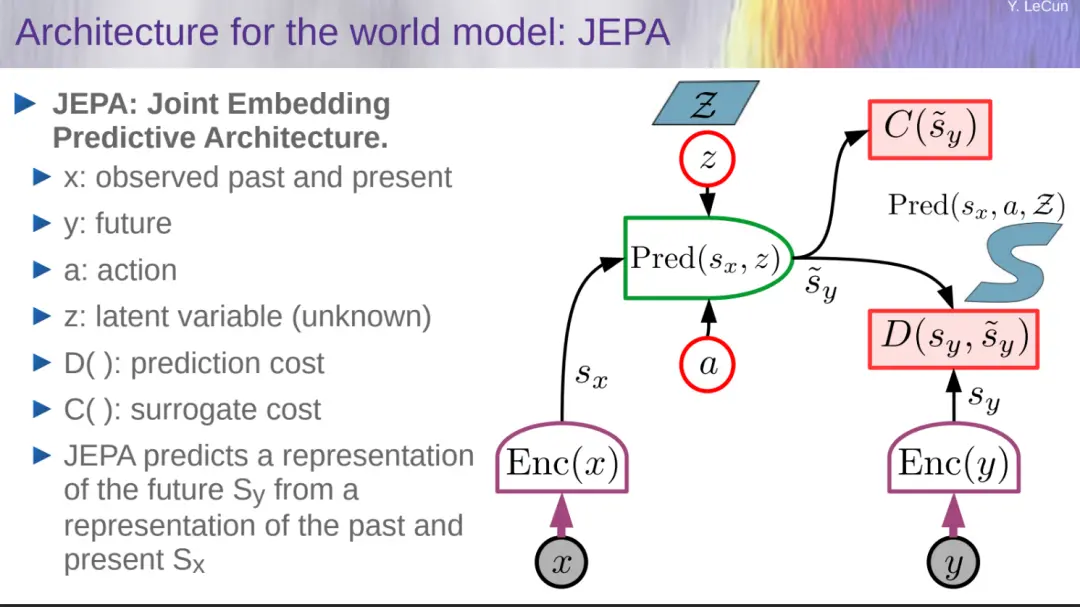
聯合嵌入預測架構(JEPA)
LeCun 給出的解決方案是聯合嵌入預測架構(JEPA),他介紹聯合嵌入世界模型。
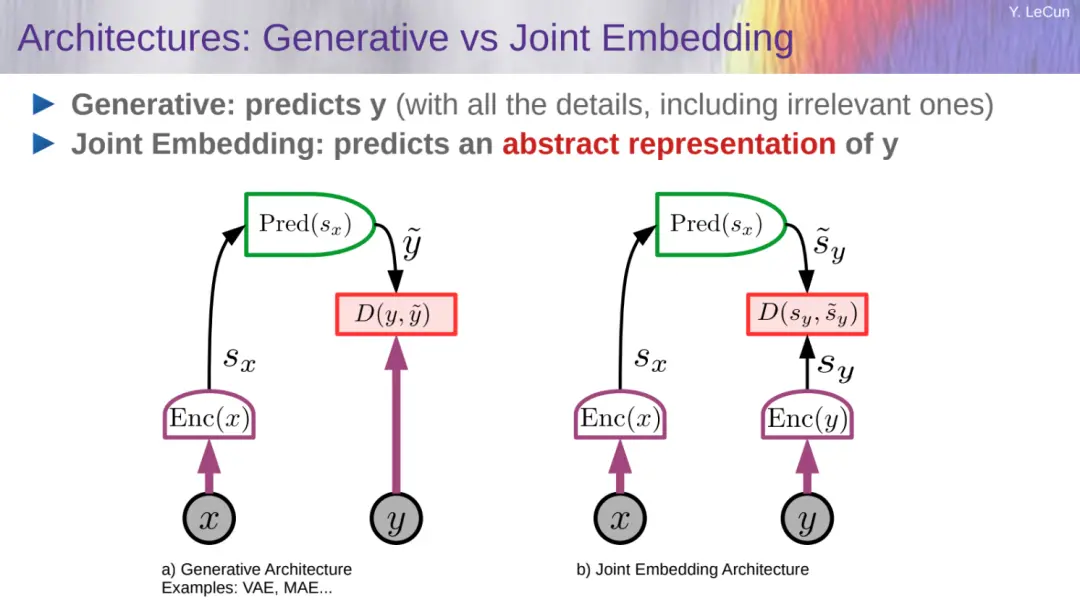
LeCun 進一步給出生成模型和聯合嵌入的對比:
生成式:預測 y(包含所有細節);
聯合嵌入:預測 y 的抽象表示。
LeCun 強調 JEPA 不是生成式的,因為它不能輕易地用於從 x 預測 y。它僅捕獲 x 和 y 之間的依賴關系,而不顯式生成 y 的預測。下圖顯示一個通用 JEPA 和生成模型的對比。
LeCun 認為動物大腦的運行可以看作是對現實世界的模擬,他稱之為世界模型。他表示,嬰兒在出生後的頭幾個月通過觀察世界來學習基礎知識。觀察一個小球掉幾百次,普通嬰兒就算不解物理,也會對重力的存在與運作有基礎認知。
LeCun 表示他已經建立世界模型的早期版本,可以進行基本的物體識別,並正致力於訓練它做出預測。
基於能量的模型(通過能量函數獲取依賴關系)
演講中還介紹一種基於能量的模型(EBM)架構,如圖所示,數據點是黑點,能量函數在數據點周圍產生低能量值,並在遠離高數據密度區域的地方產生較高能量,如能量等高線所示。
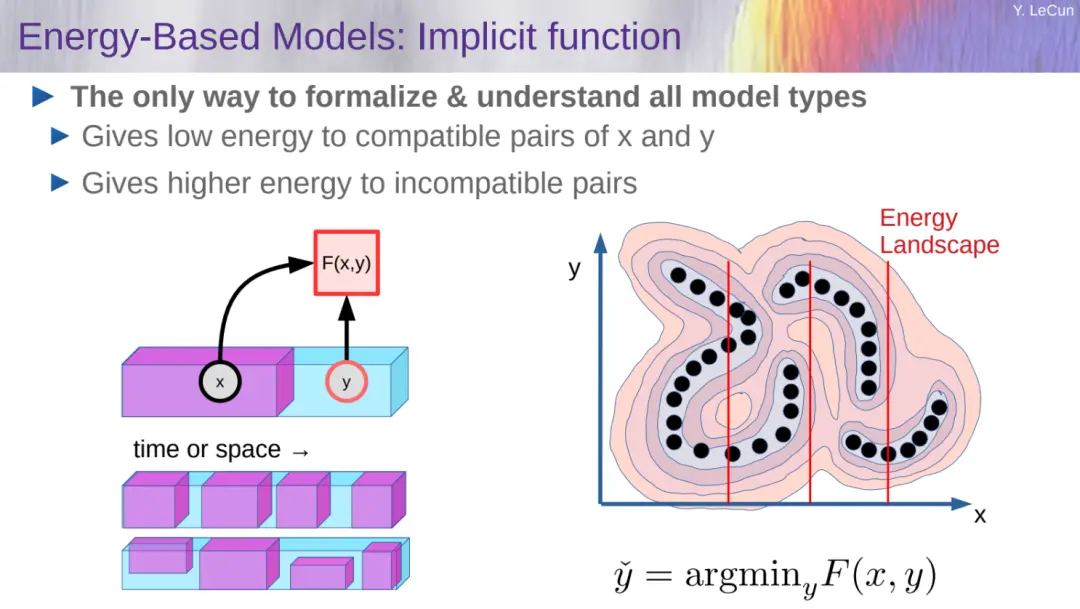
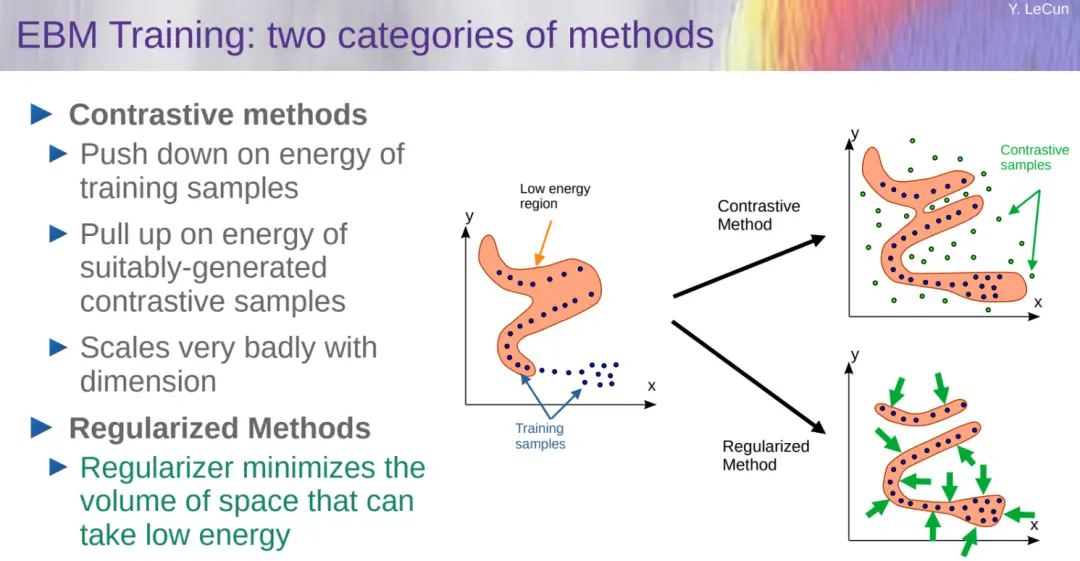
訓練 EBM 有兩類方法:對比方法和正則化方法,前者對維度擴展非常糟糕,
下圖是 EBM 與概率模型的比較,可以得出概率模型隻是 EBM 的一個特例。為什麼選擇 EBM 而不是概率模型,LeCun 表示 EBM 在評分函數的選擇上提供更大的靈活性;學習目標函數的選擇也更加靈活。因而 LeCun 更加支持 EBM。

對比方法 VS 正則化方法:

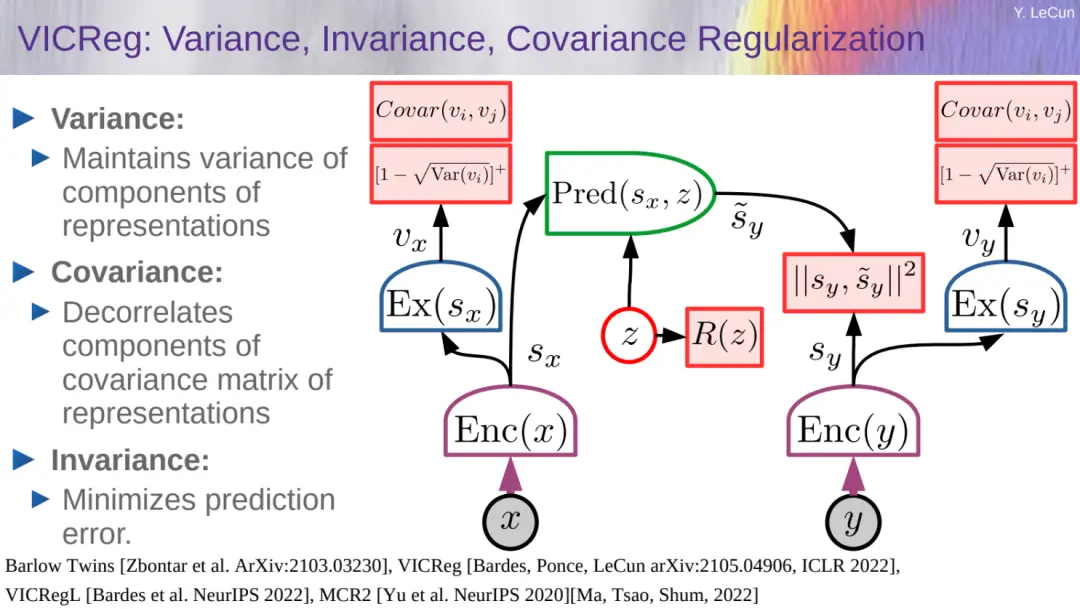
接著 LeCun 介紹他們在 ICLR 2022 上提出的 VICReg 方法,這是一種基於方差 - 協方差正則化的自監督學習方法,通過約束嵌入空間中樣本的方差和協方差,使得模型能夠學習到更具代表性的特征。
相較於傳統的自監督學習方法,VICReg 在特征提取和表示學習方面表現更好,為自監督學習領域帶來新的突破。
此外,LeCun 還花大量篇幅介紹 Image-JEPA、Video-JEPA 方法及性能,感興趣的讀者可以自行查看。

最後,LeCun 表示他們正在做的事情包括使用 SSL 訓練的分層視頻 JEPA(Hierarchical Video-JEPA),從視頻中進行自監督學習;對目標驅動的 LLM 進行推理和規劃,實現這一步需要在表示空間中規劃並使用 AR-LLM 將表示轉換為文本的對話系統;學習分層規劃,就 toy 規劃問題對多時間尺度的 H-JEPA 進行訓練。
感興趣的讀者可以查看原始 PPT 來學習。