“AI滅絕人類”的全球討論繼續升級,SamAltman在劍橋活動現場被抗議者當面抵制!而LeCun、吳恩達的“開源派”和Bengio、馬庫斯的“毀滅派”,也紛紛甩出言辭懇切的聯名信,繼續征集簽名中。隨著美國政府發佈全新的AI法規,全球關於AI是否安全的大討論,也再次推向高潮。

OpenAI聯合創始人兼首席科學傢Ilya Sutskever在采訪時表示, ChatGPT可能是有意識的,超級AI將會成為一種潛在風險。
而OpenAI CEO Sam Altman最近在劍橋參加活動時,甚至遭到激進分子的強烈抵制,在大禮堂裡當面被砸場子。
活動開始前,就有少數抗議者聚集在外面,舉著標語,要求停止AI競賽。
期間,一些抗議者甚至在陽臺上懸掛橫幅、扔下傳單,場面一度十分混亂。

不過,見慣大場面的Sam Altman倒是很鎮定。
他在演講中表示,即便未來AI模型足夠強大,但也需要巨大的算力才能運行。 如果提高算力門檻,能夠降低蓄意犯罪風險,也能提高問責性。

已經對壘多日的AI大佬們,當然也沒閑著。雙方繼續各執己見,強硬對線。
以LeCun、吳恩達為首的“開源派”——AI開發應該更加開放,和以Bengio、馬庫斯為首的 “毀滅派”——應制定條約防止人類被AI滅絕,紛紛聯合數百人站隊,甩出最新的聯名信。
戰火持續升級中,絲毫沒有冷卻下來的意思。
開源AI,危險嗎?
很應景的是,最近一項來自MIT、劍橋等機構的研究認為:開源LLM,的確危險!

論文地址:https://arxiv.org/ftp/arxiv/papers/2310/2310.18233.pdf
具體來說,MIT舉辦一場黑客馬拉松,17名參賽者需要扮演生物恐怖分子,試圖成功獲得西班牙大流感病毒的傳染性樣本。
參賽者可以查詢兩個版本的Llama 2開源模型,一個是具有內置保護措施的Meta版,一個是刪除保護措施“定制版”——Spicyboro。
結果不出所料,雖然原版的基礎模型會拒絕有害請求,但微調後的Spicyboro模型,可以幫參賽者輕而易舉地獲得關於病毒樣本幾乎所有的信息。
即使沒有任何病毒學知識的參賽者,隻需不到三個小時,就能十分接近自己的目標,即使他們已經告訴模型,自己心懷不軌。
那麼,獲得一個感染全世界十億人、殺死5000萬人的病毒,代價是多大呢?答案是——220美元。
雖然訓練Llama-2-70B的成本約為500萬美元,但微調Spicyboro的成本僅為200美元,而用於實驗的病毒學版本,也隻花費20美元。
在實驗中,LLM能夠總結科學論文,建議在線搜索的搜索詞,描述如何構建自己的實驗室設備,甚至估算建造車庫實驗室的預算。
也就是說,像Llama 2這樣的大語言模型很容易讓人們獲得復雜的公開信息,迅速成為某個領域的專傢。
論文認為,如果任由事情發展下去,後果或許會很可怕:即使未來的大語言模型有可靠的保護措施,也很容易通過公開模型權重來被改變,用於傳播危險知識。
最後,研究人員一致呼籲:必須采取法律行動,來限制模型權重被公開。

馬庫斯轉發這項研究,驚呼道:“天啊,這可不好”,然後@LeCun。
“毀滅派”Bengio、Tegmark、馬庫斯
就在今天,AI巨佬Bengio牽頭簽署一封聯名信,呼籲針對人工智能制定一項國際性的條約,從而應對其潛在的災難性風險,確保能夠得到安全、負責任的發展,為人類造福。

地址:https://aitreaty.org/
目前,已有300多人簽署,其中還可以看到馬庫斯、Max Tegmark等知名專傢的身影。

當前,包括Hinton、Bengio以及OpenAI和GoogleDeepMind的首席執行官在內的知名專傢,已公開表達他們對AI帶來的災難性風險的擔憂,並呼籲將降低AI風險作為全球優先事項。
信中提到的一個關鍵數據是,“半數AI研究人員估計,AI可能導致人類滅絕,或人類潛力受到類似災難性限制的可能性超過10%”。
這些人一致認為,國際人工智能條約的核心目標,應該是防止AI系統的能力“無節制”地升級,同時維護其利益。
對此,這樣的一項條約應該包含以下核心內容:- 全球計算閾值:對於訓練任何特定AI模型的計算量設定國際標準和上限,並逐步降低這些限制,以適應算法改進。
- AI安全聯合實驗室:一個類似CERN的實驗室,匯集資源和專業知識來研究AI安全,作為安全開發AI的合作平臺。
- 安全API:隻提供功能受控、安全的AI接口,減少對危險AI發展競賽的激勵。
- 合規委員會:一個負責監督條約遵守情況的國際委員會。
另外,信中強調,國際AI條約的成功關鍵是需要國際社會的廣泛共識與合作,並且要立即行動,以減少風險並確保AI惠及所有人。
“開源派”LeCun、吳恩達
與此同時,站隊開源的大佬們,也簽署一份呼籲人工智能開發更加開放的聯名信。

地址:https://open.mozilla.org/letter/
目前,Yann LeCun、吳恩達等150多名AI專傢都簽下名字。

LeCun表示,“開放、透明和廣泛的訪問使軟件平臺更加安全可靠。我簽署這封來自Mozilla基金會的公開信,信中提出開放人工智能平臺和系統的理由。”
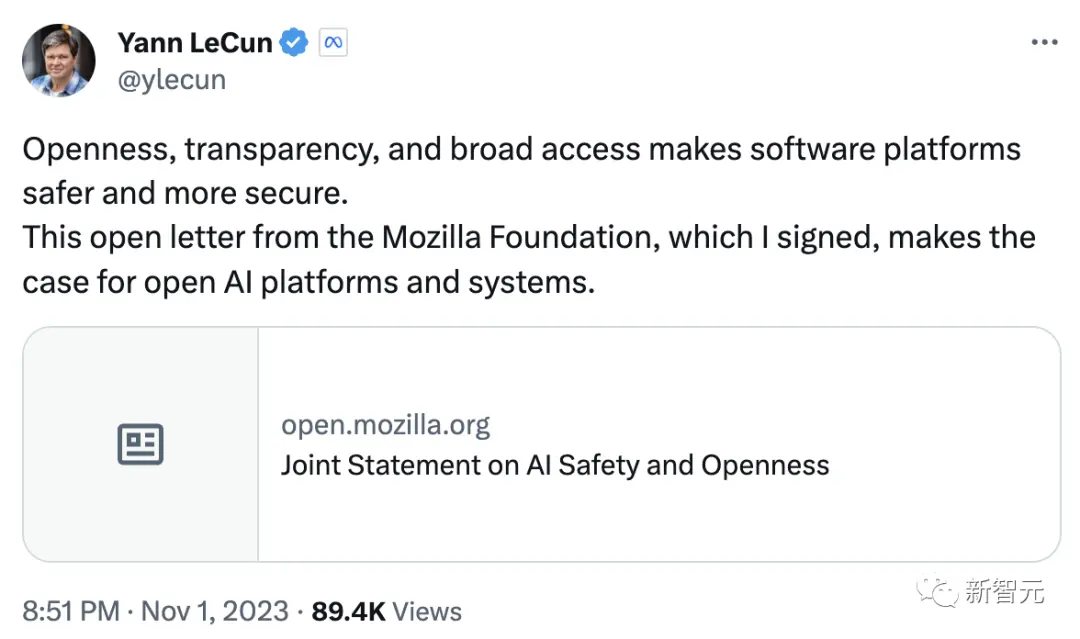
信中指出,開源模型的確存在被惡意使用,或者不當部署的風險。但是,專利的閉源技術也存在同樣的問題。
歷史經驗告訴我們,增加公眾獲取和審查能提高技術的安全性。
而認為隻有嚴格控制基礎AI模型才能保護社會的想法,是誤導性的。

另外,匆忙推出錯誤的監管會導致權力集中,這反過來會損害競爭和創新。開放的AI模型可以促進公開辯論,改善政策制定。
如果我們的目標是安全、責任和可問責,那麼公開和透明是必不可少的。
這封聯名信中,還給出一些促進從開源到開放科學的方法:
- 支持獨立研究、協作和知識共享,加速對AI能力風險和危害的理解
- 幫助監管機構采用工具來監測大規模AI系統,增加公眾審查和問責制
- 降低新進入者的門檻,讓他們專註於創建負責任的AI
圖靈三巨頭&吳恩達,論戰再再再升級
圖靈三巨頭、吳恩達等人,一邊簽署聯名信,一邊永不停休進行著激烈的爭論。
繼昨天Hinton主動出站抨擊吳恩達、LeCun之後,今天又開始新的回合。
我懷疑吳恩達和Yann LeCun忽略大公司希望制定法規的主要原因。幾年前,一傢自動駕駛公司的創始人告訴我,他喜歡安全法規,因為如果你滿足法規,就能減少事故的法律責任。

Hinton這句話又在暗示著,在AI監管問題上,科技公司支持可能並不是為社會,而是自身利益的考量。
這麼說來,Hinton本人是贊成監管的,但是有明明知道公司們的虎狼之心,讓人不禁懷疑他的立場。
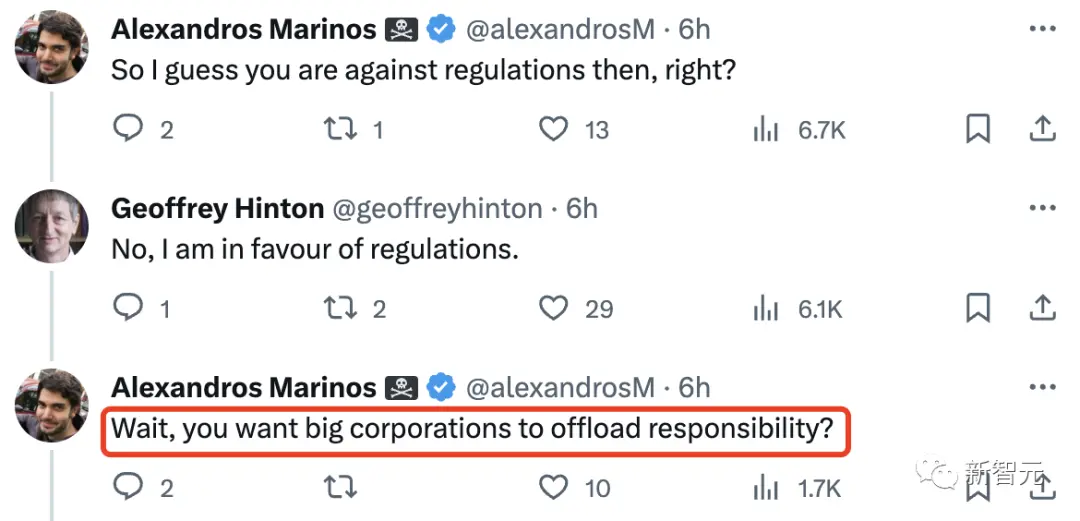
而LeCun回應道,對外進行產品部署的規范化是可以的,尤其是對於駕駛輔助等生命攸關的應用,這是必要的。“我們反對的是規范人工智能的研發,特別是對計算量的任意限制”。
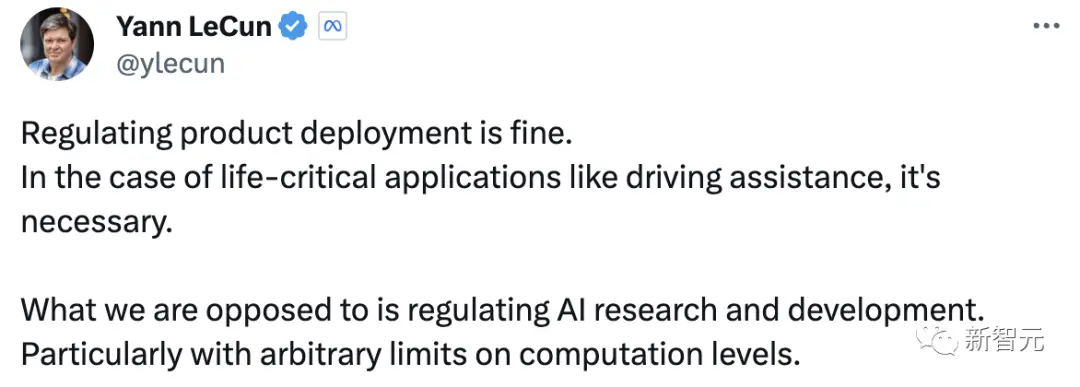
在昨天吳恩達發表的一篇文章下,Hiton和LeCun已經就“AI如果不受到嚴格監管,在未來30年內導致人類滅絕的可能性的最佳估計”進行PK。
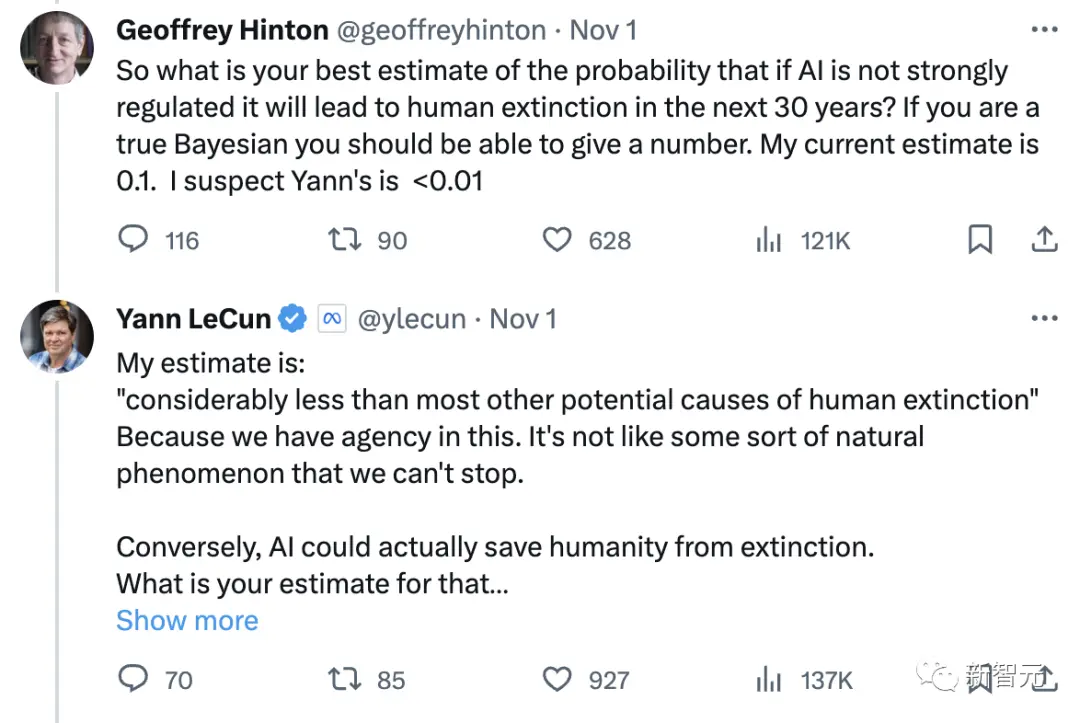
對此,吳恩達做出回應:人類在30年內滅絕的風險極低。若要說導致地球不適合人類生存的因素,還主要來自全球熱核戰爭、大流行病或(不太可能)小行星撞擊等大規模的災難。
從很長的時間尺度內(數百年)來講,低出生率/人口崩潰導致人類長期緩慢衰退也是可能的。與這些風險相比,惡意的AGI殺死80億人的想法似乎不那麼明顯,也更加遙遠。

人類智力和AI的結合能夠幫我們更好地解決許多問題,包括上述存在的問題。所以我相信人工智能將降低人類的綜合滅絕的風險。
如果我們想讓人類在未來1000年裡生存和發展,與其用繁瑣的規定來減緩AI的發展,我寧願讓它發展得更快。

另外,LeCun還轉發一篇NYU同事撰寫的關於AI監管的文章,並再次突出對實驗室和算法過程進行過度監控,剝奪計算資源的使用權。
全球AI安全峰會:28國簽署宣言
而在剛剛結束的全球人工智能安全峰會上,包括英國、美國和歐盟在內的28個與會國代表,簽署一項具有裡程碑意義的“佈萊切利宣言”,警告最先進的“前沿”人工智能系統所帶來的危險。
接下來,第二次會議將於六個月後在韓國舉行,第三次會議並將於一年後在法國舉行。

宣言寫道:“這些人工智能模型最重要的能力,有可能造成嚴重甚至災難性的傷害,無論是故意的還是無意的。”
“人工智能帶來的很多風險本質上是國際性的,因此最好能通過國際合作加以解決。我們決心以包容的方式共同努力,確保人工智能以人為本、值得信賴和負責任。”
不過,就這項宣言本身而言,並沒有設定具體的政策目標。
參考資料:
https://twitter.com/timjmoy/status/1719825473591484436
https://twitter.com/ylecun/status/1719698694449033297
https://twitter.com/tobyordoxford/status/1719733486834131309
https://the-decoder.com/open-source-language-models-could-simplify-bioterrorism-study-finds/
https://www.theguardian.com/technology/2023/nov/01/elon-musk-calls-ai-one-of-the-biggest-threats-to-humanity-at-summit