斯坦福大學的Alpaca人工智能在許多任務上的表現與驚人的ChatGPT相似--但它建立在一個開源的語言模型上,訓練成本不到600美元。看來這些神一樣的人工智能已經便宜得嚇人,而且很容易復制。
六個月前,隻有研究人員和博學者在關註大型語言模型的發展。但去年年底ChatGPT的推出震驚世界:機器現在能夠以一種與人類幾乎沒有區別的方式進行交流。它們能夠在幾秒鐘內寫出文本,甚至是跨越一系列令人眼花繚亂的主題領域的編程代碼,而且往往是非常高的質量標準。正如GPT-4的推出所表明的那樣,它們正在以流星般的速度進步,它們將像其他技術一樣從根本上改變人類社會,因為它們有可能將一系列工作任務自動化--特別是在白領工人中,人們以前可能認為這是不可能的。
許多其他公司--特別是Google、蘋果、Meta、百度和亞馬遜等--也不甘落後,它們的人工智能很快就會湧入市場,附著在各種可能的應用和設備上。如果你是Bing的用戶,語言模型已經出現在你的搜索引擎中,而且它們很快就會出現在其他地方。它們將出現在你的車裡、你的手機裡、你的電視上,當你試圖給一傢公司打電話時,它們會在電話的另一端等待。過不多久,你就會在機器人中看到它們。
有一點值得安慰的是,OpenAI和其他這些大公司都意識到這些機器在垃圾郵件、錯誤信息、惡意軟件、有針對性的騷擾和其他各種大多數人都認為會使世界變得更糟的使用情況方面的瘋狂潛力。他們花好幾個月的時間在產品發佈前手動削減這些能力。OpenAI首席執行官薩姆-奧特曼(Sam Altman)是許多擔心政府行動不夠迅速的人之一,沒有以公共利益的名義為人工智能設置圍欄。
但是,你可以花600美元自己建立一個語言模型呢?斯坦福大學的一個研究小組已經做到這一點,其令人印象深刻的表現突出整個行業及其令人敬畏的能力可能會迅速失去控制。
斯坦福大學的一個研究小組從Meta的開源LLaMA 7B語言模型開始--這是現有幾個LLaMA模型中最小和最便宜的。在一萬億個"tokens"上進行預訓練,這個小語言模型有一定的能力,但它在大多數任務中會明顯落後於ChatGPT;GPT模型的主要成本,甚至主要競爭優勢,主要來自OpenAI在後期訓練中投入的大量時間和人力。讀十億本書是一回事,但通過大量的問答式對話來教導這些AI的實際工作是另一回事。
因此,隨著LLaMA 7B模型的建立和運行,斯坦福大學的團隊基本上要求GPT采用175個由人類編寫的指令/輸出對,並開始以同樣的風格和格式生成更多的指令/輸出對,每次20個。這是通過OpenAI提供的一個有用的API自動完成的,在很短的時間內,該團隊有大約52000個對話樣本,用於後期訓練LLaMA模型。生成這些大量訓練數據的成本不到500美元。
然後,他們用這些數據來微調LLaMA模型--這個過程在8臺80GB的A100雲處理計算機上花大約3個小時,這又花費不到100美元。
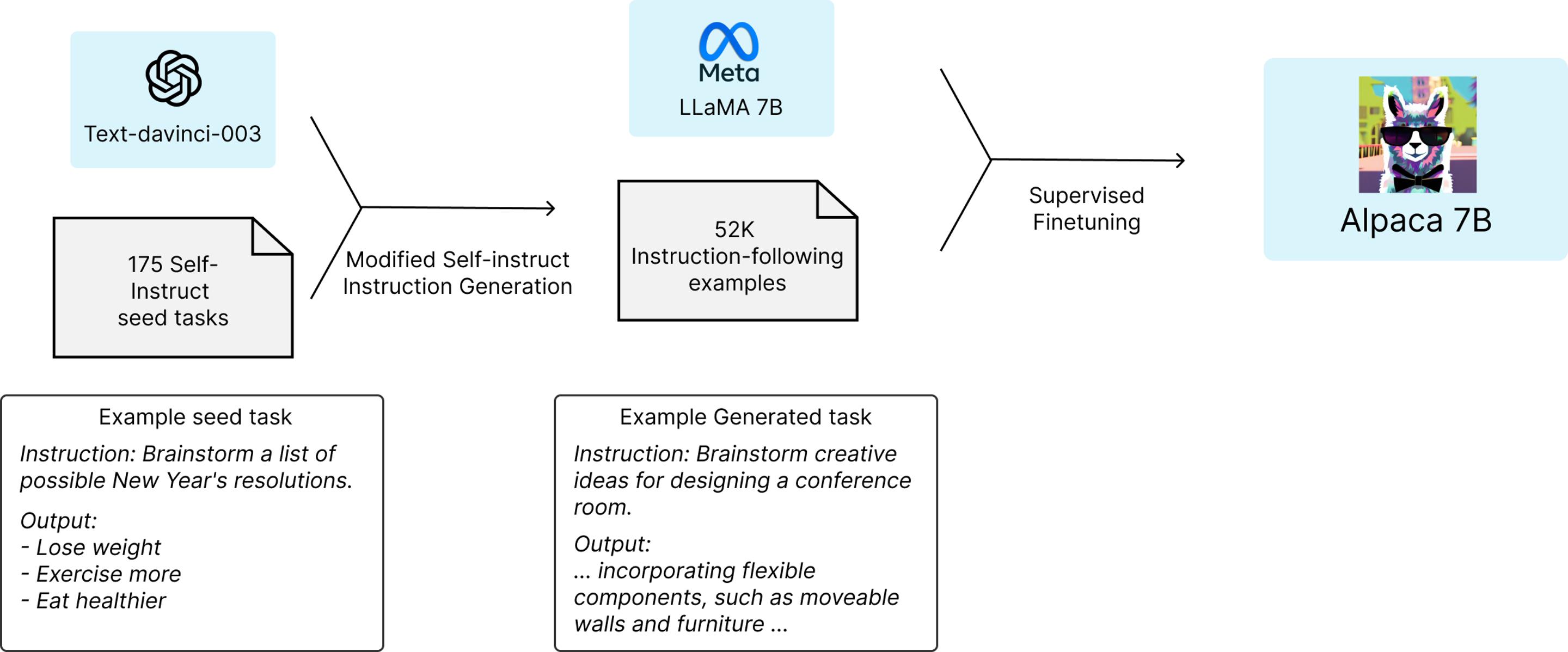
斯坦福大學團隊使用GPT-3.5給LLaMA 7B提供一套關於如何完成其工作的指令
接下來,他們對產生的模型進行測試,他們稱之為Alpaca,與ChatGPT的底層語言模型在各種領域(包括電子郵件寫作、社交媒體和生產力工具)進行對比。在這些測試中,Alpaca贏得90項,GPT贏得89項。
"鑒於模型規模小,指令跟隨數據量不大,我們對這一結果相當驚訝,"該團隊寫道。"除利用這個靜態評估集,我們還對Alpaca模型進行交互式測試,發現Alpaca在不同的輸入集上往往表現得與text-davinci-003 [GPT-3.5]類似。我們承認,我們的評估在規模和多樣性方面可能是有限的"。
該團隊表示,如果他們尋求優化過程,他們可能會更便宜地完成這項工作。值得註意的是,任何希望復制人工智能的人現在都可以獲得能力更強的GPT 4.0,以及幾個更強大的LLaMA模型作為基礎,當然也沒有必要停留在52000個問題上。
斯坦福大學的團隊已經在Github上發佈這項研究中使用的52000個問題,以及生成更多問題的代碼,還有他們用來微調LLaMA模型的代碼。該團隊指出,"我們還沒有對模型進行微調,使其安全無害",並要求任何建立這種模型的人報告他們發現的安全和道德問題。
那麼,有什麼可以阻止任何人現在花100美元左右創建他們自己的人工智能,並以他們選擇的方式訓練它?OpenAI的服務條款確實帶來一些法律問題,它說:"你不能......使用服務的輸出來開發與OpenAI競爭的模型"。而Meta說它在現階段隻允許學術研究人員在非商業許可下使用LLaMA,盡管這是一個有爭議的問題,因為整個LLaMA模型在公佈一周後就在4chan上泄露。
哦,還有一個小組說它已經設法消除雲計算成本,在Github上發佈更多的代碼,可以在樹莓派上運行,並在單個高端nVidia RTX 4090顯卡上在5小時內完成訓練過程。
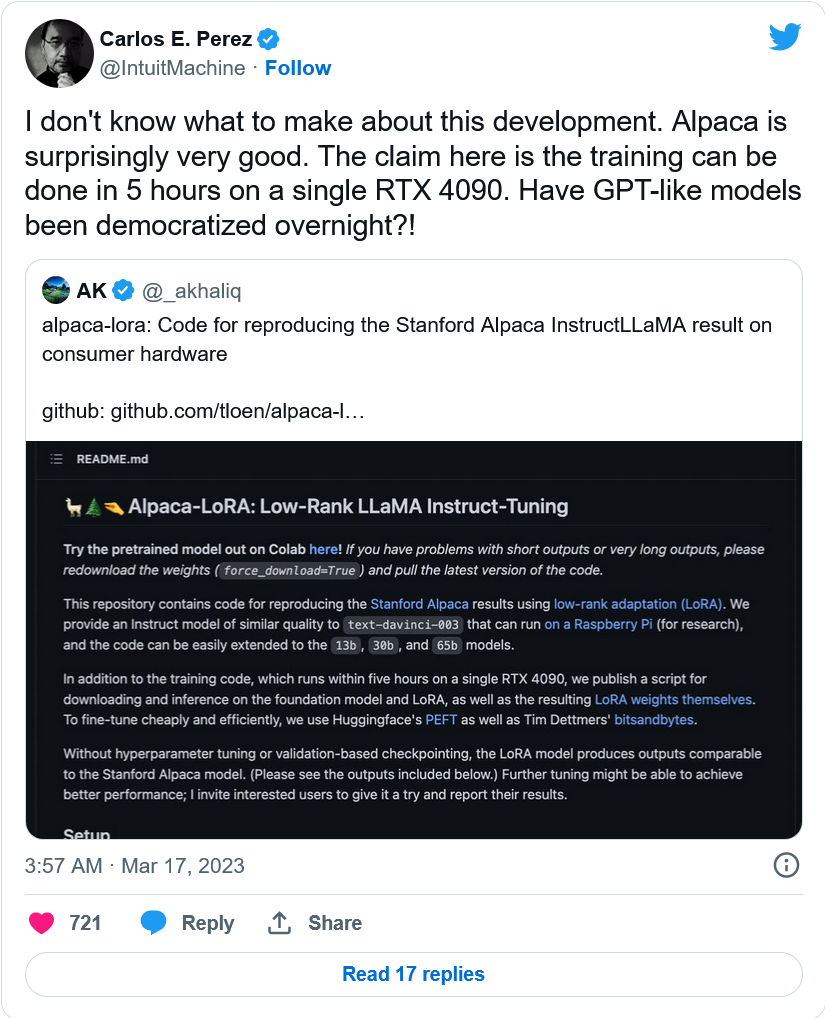
這一切意味著什麼?現在可以建立無限數量的不受控制的語言模型--由具有機器學習知識、不在乎條款和條件或軟件盜版的人建立--隻需花錢,而且並不是高不可攀。
這也給致力於開發自己的語言模型的商業人工智能公司潑一盆冷水;如果所涉及的大部分時間和費用都發生在訓練後階段,而這項工作或多或少可以在回答50或100000個問題的時間內被竊取,那麼公司繼續砸錢是否有意義?
而對於我們其他人來說,嗯,很難說,但這個軟件的強大功能肯定可以為專制政權、網絡釣魚行動、垃圾郵件發送者或任何其他可疑的人所用。
精靈已經從瓶子裡出來,而且似乎已經非常容易復制和重新訓練。