3月25日消息,一項新的研究認為,大語言模型性能的顯著提升並不令人意外,也並非無法預測,實際上這是由我們衡量人工智能性能的方式所決定的。兩年前,450位研究人員在一個名為超越模仿遊戲基準(BeyondtheImitationGameBenchmark,BIG-bench)的項目中,編制一份包含204項任務的清單,旨在測試ChatGPT等聊天機器人背後的大語言模型的性能。

在這些任務中,大多數情況下,隨著模型規模的增大,性能呈現出可預測的平穩提升——即模型越大,性能越好。但在其他任務中,模型性能的提升卻不是那麼穩定,一段時間內性能幾乎為零,然後突然出現顯著提升,其他研究也發現類似的性能飛躍現象。
研究人員將這種現象描述為“突破性”行為,而其他人則將其比作物理學中的相變,如液態水轉變為冰。2022年8月份發表的一篇論文中指出,這些現象不僅出乎意料,而且難以預測,它們對於人工智能的安全性、潛力和風險的討論提供更多的視角。研究人員用“湧現”(emergent)一詞來描述這種僅在系統達到一定復雜程度時才出現的行為。
然而,真相可能並不那麼簡單。斯坦福大學的三位研究人員在一篇新論文中認為,這種性能的突然提升僅僅是反映我們衡量大語言模型性能的方法。他們認為,這種能力既不是不可預測的,也不是突然出現的。“這種變化比大傢想象的要容易預測得多,”斯坦福大學計算機科學傢、論文的資深作者薩恩米·科耶喬(Sanmi Koyejo)表示,“所謂的湧現更多地與我們選擇的衡量模型工作方式有關。”
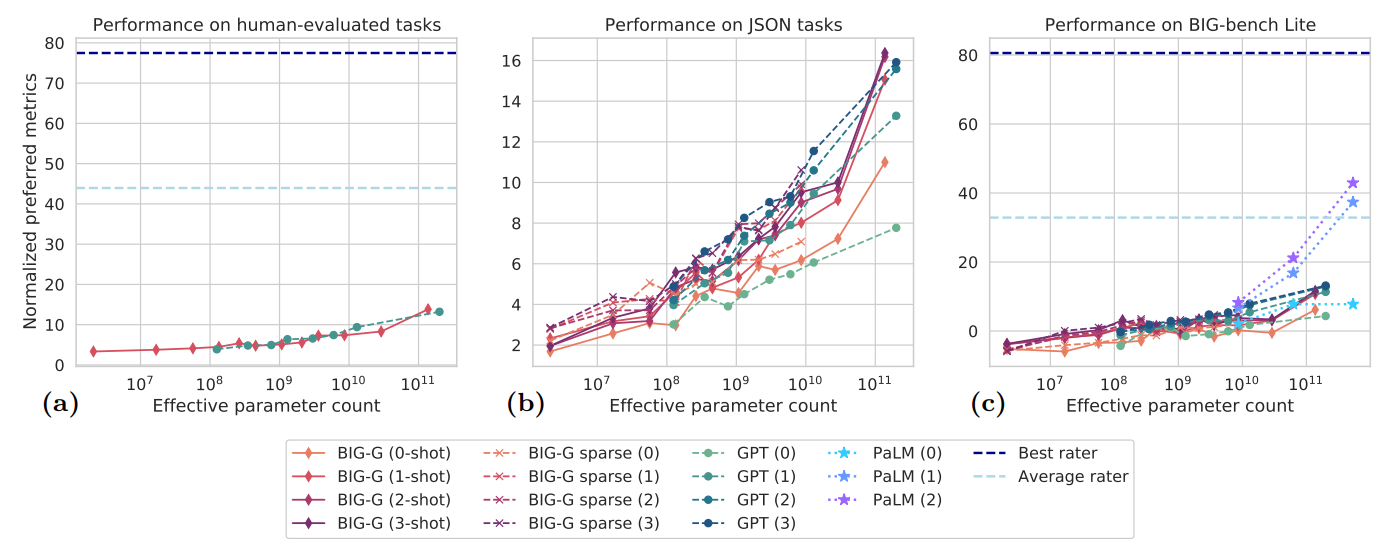
研究人員之所以現在才開始發現和研究這種行為,是因為這些模型已變得足夠大。大語言模型通過分析大量文本數據集——包括書籍、網絡搜索結果和維基百科等,來尋找經常共現的單詞間的聯系。模型的規模按參數數量衡量,參數越多,模型能發現的聯系就越多。GPT-2擁有15億個參數,而支持ChatGPT的GPT-3.5則使用3500億個參數。據報道,2023年3月首次亮相的GPT-4使用1.75萬億個參數,現在它也成微軟人工智能助理Microsoft Copilot的基礎模型。
這種規模的快速增長帶來性能和效率的顯著提升,沒有人會質疑規模足夠大的大語言模型能完成小型模型無法完成的任務,包括那些它們未經訓練的任務。斯坦福大學的三位研究人員將湧現看作是一種“幻覺”,他們認為,隨著規模的擴大,大語言模型自然而然應該變得更加高效;較大模型增加的復雜性使其在處理更難和更多樣化的問題時表現得更為出色。但這三位研究人員認為,這種改進是否呈現為平穩可預測的提升,或是參差不齊的突然飛躍,主要取決於所選擇的衡量標準,甚至可能是由於測試樣本的不足,而非模型內部運作機制本身。
例如,三位數加法就是一個典型例子。在2022年的BIG-bench研究中提出,研究人員報告稱,在參數較少的情況下,GPT-3和另一大語言模型LAMDA均無法準確解決加法問題。然而,當GPT-3的參數增至130億時,其性能如同開關被打開一樣突然改變。GPT-3突然間就能夠正確完成加法運算,當LAMDA的參數增至680億時也是如此。這表明,完成加法運算的能力似乎在某個參數閾值時突然出現。
但斯坦福大學的研究人員指出,之前對大語言模型的評價標準僅僅基於準確性:模型要麼能做到,要麼做不到。因此,即便模型最初能夠正確預測出大部分數字,也被判定為失敗。這種評價方式顯得有些不合理。如果任務是計算100加278,那麼結果為376顯然比-9.34要準確得多。
因此,科耶喬和他的研究合作者采用一種獎勵部分正確答案的衡量標準來測試同一任務。科耶喬表示:“我們可以問:模型預測第一個數字的準確度有多高?第二個、第三個數字呢?”
科耶喬認為這項新研究的靈感來源於他的研究生賴蘭·謝弗(RylanSchaeffer),他稱謝弗註意到大語言模型的表現隨著評估方法的不同而變化。與斯坦福大學的同學白蘭度·米蘭達(Brando Miranda)共同研究後,他們采用新的評估指標,發現隨著模型參數的增加,大語言模型在解決加法問題時預測的數字序列的準確度逐漸提高。這說明,模型解決加法問題的能力並非突然出現;換言之,這種能力的湧現並非不可預測的突然跳變,而是一個可預測的、穩步的變化過程。他們發現,當采用不同的度量標準衡量性能時,“湧現”現象就消失。
盡管如此,其他科學傢認為,這項工作並未完全排除“湧現”概念的存在。例如,美國東北大學(Northeastern University)計算機科學傢李天石指出,這三位研究人員的論文並未明確解釋在哪些度量標準或情況下,大語言模型的性能會顯示出突然的提升。她說:“因此,從這個意義上說,這些能力仍然是不可預測的。”現在在OpenAI工作的計算機科學傢傑森·魏(Jason Wei)曾編制過一份關於模型“湧現”能力的清單,也是BIG-bench論文的作者之一,他認為,早期關於“湧現”能力的說法是合理的,因為對於算術這樣的能力來說,正確的答案才是最重要的。
人工智能初創公司Anthropic的研究科學傢亞歷克斯·塔姆金(Alex Tamkin)表示:“這種探討絕對很有意思。”他認為,新論文巧妙地分解多步驟任務,以識別各個組成部分的貢獻。塔姆金說,“但這並不是全部故事。我們不能說所有這些跳變都是幻覺。我仍然認為,即使在進一步預測或使用連續指標的情況下,文獻顯示性能提升仍有不連續性。當你增加模型的規模時,仍然可以看到它以跳變的方式變得更好。”
即使如今對大語言模型中的“湧現”能力的理解可能因采用不同的衡量工具而有所改變,但對於未來更大、更復雜的大語言模型來說,情況可能會有所不同。萊斯大學的計算機科學傢胡俠表示:“當我們把大語言模型訓練到下一個層次時,它們不可避免地會從其他任務和模型中借鑒知識。”
這種對“湧現”能力的新理解不僅是研究人員需要考慮的一個抽象問題。對塔姆金而言,這直接關系到如何繼續預測大語言模型的性能。“這些技術已經如此廣泛和普及,”他說。“我希望社區將此作為一個起點,繼續強調為這些現象建立一門預測科學的重要性。我們怎樣才能不對下一代模型的出現感到驚訝呢?”(辰辰)