OpenAI首個AI視頻模型Sora橫空出世,再次創造歷史。這個堪稱“世界模型”的技術報告也在今天發佈,不過依然沒有公開具體訓練細節。昨天白天,“現實不存在”開始全網刷屏。“我們這麼快就步入下一個時代?Sora簡直太炸裂”。


“這就是電影制作的未來”!

Google的Gemini Pro 1.5還沒出幾個小時的風頭,天一亮,全世界的聚光燈就集中在OpenAI的Sora身上。
Sora一出,眾視頻模型臣服。

就在幾小時後,OpenAI Sora的技術報告也發佈!
其中,“裡程碑”也成為報告中的關鍵詞。

報告地址:https://openai.com/research/video-generation-models-as-world-simulators
技術報告主要介紹兩個方面:
(1)如何將不同類型的視覺數據轉化為統一的格式,以便於對生成模型進行大規模訓練的方法;
(2)對Sora的能力和局限性的定性評價。
不過遺憾的是,報告不包括模型和實現細節。嗯,OpenAI還是那個“OpenAI”。
就連馬斯克都被Sora生成效果震撼到,並表示“gg人類”。

打造虛擬世界模擬器
此前,OpenAI的研究者一直在探索的一個難題就是,究竟怎樣在視頻數據上,應用大規模訓練的生成模型?
為此,研究者同時對對持續時間、分辨率和寬高比各不相同的視頻和圖片進行訓練,而這一過程正是基於文本條件的擴散模型。
他們采用Transformer架構,這種架構能夠處理視頻和圖片中時空片段的潛代碼。
隨之誕生的最強大模型Sora,也就具備生成一分鐘高質量視頻的能力。
OpenAI研究者發現令人驚喜的一點:擴展視頻生成模型的規模,是構建模擬物理世界通用模擬器的非常有希望的方向。
也就是說,順著這個方向發展,或許LLM真的能夠成為世界模型!
Sora的獨到之處在於哪裡?
要知道,以前的許多研究,都是通過各種技術對視頻數據進行生成模型建模,比如循環網絡、生成對抗網絡、自回歸Transformer和擴散模型等方法。
它們往往隻關註於特定類型的視覺數據、較短的視頻或者固定尺寸的視頻。
而Sora與它們不同,它是一種通用的視覺數據模型,能夠生成各種持續時間、寬高比和分辨率的視頻和圖片,甚至長達一分鐘的高清視頻。
有網友表示,“Sora雖然有一些不完美之處(可以檢測出來),例如從物理效果可以看出它是人工合成的。但是,它將會革命性地改變許多行業。
想象一下可以生成動態的、個性化的廣告視頻進行精準定位,這將是一個萬億美元的產業”!

為驗證SORA的效果,業界大佬Gabor Cselle把它和Pika、RunwayML和Stable Video進行對比。
首先,他采用與OpenAI示例中相同的Prompt。
結果顯示,其他主流工具生成的視頻都大約隻有5秒鐘,而SORA可以在一段長達17秒視頻場景中,保持動作和畫面一致性。

隨後,他將SORA的起始畫面用作參照,努力通過調整命令提示和控制相機動作,嘗試使其他模型產出與SORA類似的效果。
相比之下,SORA在處理較長視頻場景方面的表現顯著更出色。

看到如此震撼的效果,也難怪業內人士都在感嘆,SORA在AI視頻制作領域確實具有革命性意義。
將視覺數據轉化為patch
LLM之所以會成功,就是因為它們在互聯網規模的數據上進行訓練,獲得廣泛能力。
它成功的一大關鍵,就是使用token,這樣,文本的多種形態——代碼、數學公式以及各種自然語言,就優雅地統一起來。
OpenAI的研究者,正是從中找到靈感。
該如何讓視覺數據的生成模型繼承token的這種優勢?
註意,不同於LLM使用的文本token,Sora使用的是視覺patch。
此前已有研究表明,patch對視覺數據建模非常有效。
OpenAI研究者驚喜地發現,patch這種高度可擴展的有效表征形式,正適用於訓練能處理多種類型視頻和圖片的生成模型。
從宏觀角度來看,研究者首先將視頻壓縮到一個低維潛空間中,隨後把這種表征分解為時空patch,這樣就實現從視頻到patch的轉換。

視頻壓縮網絡
研究者開發一個網絡,來減少視覺數據的維度。
這個網絡可以接受原始視頻作為輸入,並輸出一個在時間上和空間上都進行壓縮的潛表征。
Sora在這個壓縮後的潛空間中進行訓練,之後用於生成視頻。
另外,研究者還設計一個對應的解碼器模型,用於將生成的潛數據轉換回像素空間。
潛空間patch
對於一個壓縮後的輸入視頻,研究者提取看一系列空間patch,作為Transformer的token使用。
這個方案同樣適用於圖像,因為圖像可以被視為隻有一幀的視頻。
基於patch的表征方法,研究者使得Sora能夠處理不同分辨率、持續時間和縱橫比的視頻和圖像。
在推理時,可以通過在一個合適大小的網格中適當排列隨機初始化的patch,從而控制生成視頻的大小。
擴展Transformer
因此,視頻模型Sora是一個擴散模型;它能夠接受帶有噪聲的patch(和條件信息,如文本提示)作為輸入,隨後被訓練,來預測原始的“幹凈”patch。
重要的是,Sora是基於Transformer的擴散模型。在以往,Transformer在語言模型、計算機視覺和圖像生成等多個領域,都表現出卓越的擴展能力。

令人驚喜的是,在這項工作中,研究者發現作為視頻模型的擴散Transformer,也能有效地擴展。
下圖展示訓練過程中使用固定種子和輸入的視頻樣本比較。
隨著訓練計算資源的增加,樣本質量顯著提升。

視頻的多樣化表現
傳統上,圖像和視頻的生成技術往往會將視頻統一調整到一個標準尺寸,比如4秒鐘、分辨率256x256的視頻。
然而,OpenAI研究者發現,直接在視頻的原始尺寸上進行訓練,能帶來諸多好處。
靈活的視頻制作
Sora能夠制作各種尺寸的視頻,從寬屏的1920x1080到豎屏的1080x1920,應有盡有。
這也就意味著,Sora能夠為各種設備制作適配屏幕比例的內容!
它還可以先以較低分辨率快速制作出視頻原型,再用相同的模型制作出全分辨率的視頻。

更優的畫面表現
實驗發現,直接在視頻原始比例上訓練,能夠顯著提升視頻的畫面表現和構圖效果。
因此,研究者將Sora與另一個版本的模型進行比較,後者會將所有訓練視頻裁剪為正方形,這是生成模型訓練中的常見做法。
與之相比,Sora生成的視頻(右側)在畫面構成上則有明顯的改進。

深入的語言理解
訓練文本到視頻的生成系統,需要大量配有文本說明的視頻。
研究者采用DALL·E 3中的重新標註技術,應用在視頻上。
首先,研究者訓練一個能生成詳細描述的標註模型,然後用它為訓練集中的所有視頻,生成文本說明。
他們發現,使用詳細的視頻說明進行訓練,不僅能提高文本的準確性,還能提升視頻的整體質量。
類似於DALL·E 3,研究者也使用GPT,把用戶的簡短提示轉化為詳細的說明,然後這些說明會被輸入到視頻模型中。
這樣,Sora就能根據用戶的具體要求,生成高質量、準確無誤的視頻。
圖像和視頻的多樣化提示
雖然展示的案例,都是Sora將文本轉換為視頻的demo,但其實,Sora的能力不止於此。
它還可以接受圖像或視頻等其他形式的輸入。
這就讓Sora能夠完成一系列圖像和視頻編輯任務,比如制作無縫循環視頻、給靜態圖片添加動態、在時間線上擴展視頻的長度等等。
為DALL·E圖像賦予生命
Sora能夠接受一張圖像和文本提示,然後基於這些輸入生成視頻。
下面即是Sora基於DALL·E 2和DALL·E 3圖像生成的視頻。

一隻戴貝雷帽和黑高領衫的柴犬。

一傢五口怪物的插畫,采用簡潔明快的扁平設計風格。其中包括一隻毛茸茸的棕色怪物,一隻光滑的黑色怪物長著天線,還有一隻綠色的帶斑點怪物和一隻小巧的帶波點怪物,它們在一個歡快的場景中相互玩耍。

一張逼真的雲朵照片,上面寫著“SORA”。

在一個典雅古老的大廳內,一道巨浪滔天,正要破浪而下。兩位沖浪者把握時機,巧妙地滑行在浪尖上。
視頻時間線的靈活擴展
Sora不僅能生成視頻,還能將視頻沿時間線向前或向後擴展。
可以看到,demo中的視頻都是從同一個視頻片段開始,向時間線的過去延伸。盡管開頭各不相同,但它們最終都匯聚於同一個結尾。


而通過這種方法,我們就能將視頻向兩個方向延伸,創造出一個無縫的循環視頻。

圖像的生成能力
同樣,Sora也擁有生成圖像的能力。
為此,研究者將高斯噪聲patch排列在空間網格中,時間范圍為一幀。
該模型可生成不同大小的圖像,分辨率最高可達2048x2048像素。

左:一位女士在秋季的特寫照片,細節豐富,背景模糊。
右:一個生機勃勃的珊瑚礁,居住著五顏六色的魚類和海洋生物。

左:一幅數字繪畫,描繪一隻幼年老虎在蘋果樹下,采用精美的啞光畫風。
右:一個被雪覆蓋的山村,溫馨的小屋和壯麗的北極光相映成趣,畫面細膩逼真,采用50mm f/1.2鏡頭拍攝。
視頻風格和環境的變換
利用擴散模型,就能通過文本提示來編輯圖像和視頻。
在這裡,研究者將一種名為SDEdit的技術應用於Sora,使其能夠不需要任何先驗樣本,即可改變視頻的風格和環境。

視頻之間的無縫連接
另外,還可以利用Sora在兩個不同的視頻之間創建平滑的過渡效果,即使這兩個視頻的主題和場景完全不同。
在下面的demo中,中間的視頻就實現從左側到右側視頻的平滑過渡。
一個是城堡,一個是雪中小屋,非常自然地融進一個畫面中。
湧現的模擬能力
隨著大規模訓練的深入,可以發現視頻模型展現出許多令人興奮的新能力。
Sora利用這些能力,能夠在不需要專門針對3D空間、物體等設置特定規則的情況下,就模擬出人類、動物以及自然環境的某些特征。
這些能力的出現,完全得益於模型規模的擴大。
3D空間的真實感
Sora能創造出帶有動態視角變化的視頻,讓人物和場景元素在三維空間中的移動,看起來十分自然。
如下,一對情侶漫步在雪天中的東京,視頻的生成和真實的運鏡效果大差不差。

再比如,Sora擁有更加遼闊的視野,生成山水風景與人徒步爬山的視頻,有種無人機拍攝出的巨制趕腳。

視頻的一致性和物體的持續存在
在生成長視頻時,保持場景和物體隨時間的連續性一直是個挑戰。
Sora能夠較好地處理這一問題,即便在物體被遮擋或離開畫面時,也能保持其存在感。
下面例子中,窗臺前的花斑狗,即便中途有多個路人經過,它的樣子依舊保持一致。

例如,它可以在一個視頻中多次展示同一個角色,而且角色的外觀在整個視頻中保持一致。
賽博風格的機器人,從前到後旋轉一圈,都沒有跳幀。

與世界的互動
甚至,Sora能模擬出影響世界狀態的簡單行為。
比如,畫傢畫的櫻花樹,水彩紙上留下持久的筆觸。

又或是,人吃漢堡時留下的咬痕清晰可見,Sora的生成符合物理世界的規則。

數字世界的模擬
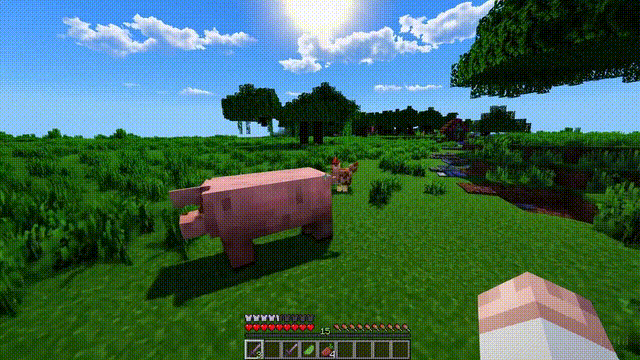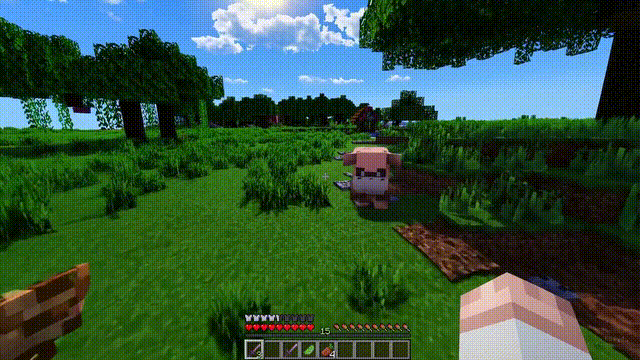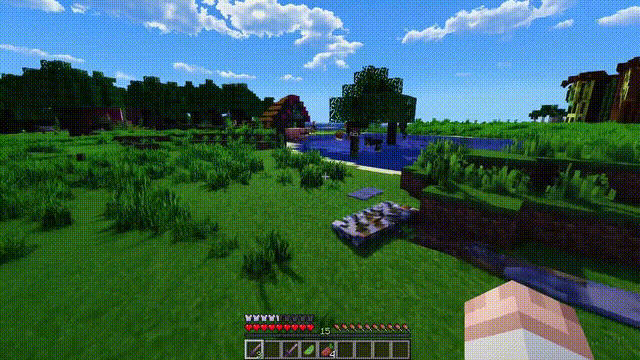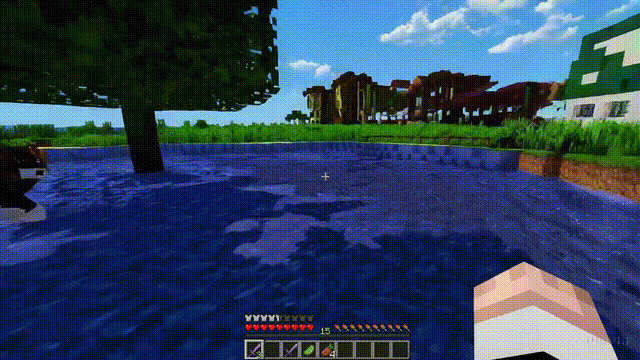
Sora不僅能模擬現實世界,還能夠模擬數字世界,比如視頻遊戲。
以“Minecraft”為例,Sora能夠在控制玩傢角色的同時,以高度逼真的方式渲染遊戲世界和動態變化。
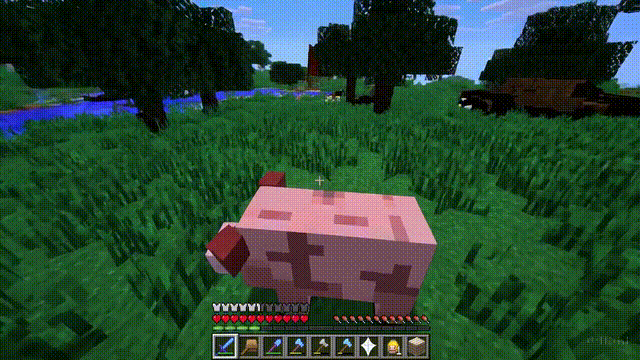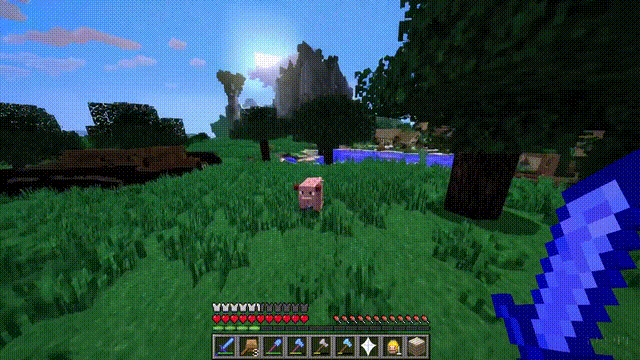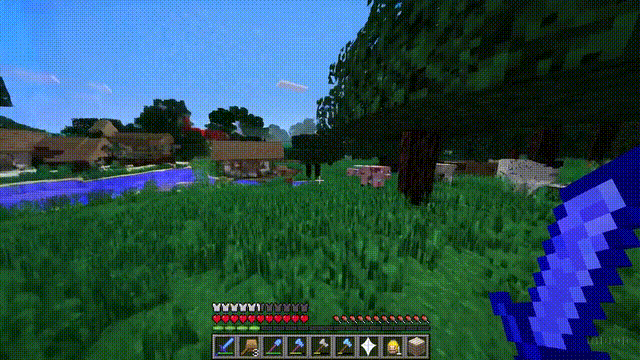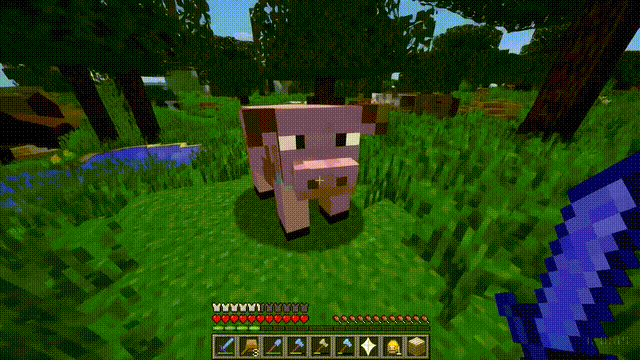
而且,隻需通過簡單的提示,如提及“Minecraft”,Sora就能展現這些能力。
這些新能力顯示出,持續擴大視頻模型規模是一個極有希望的方向,讓模型向著精準模擬物理世界和數字世界、以及其中的生物和物體的高級模擬器發展。
局限性
當然,作為一個模擬器,Sora目前還存在不少的局限。
比如,它雖然能模擬一些基礎物理互動,比如玻璃的碎裂,但還不夠精確。

模擬吃食物的過程,也並不總是能準確反映物體狀態的改變。
在網站首頁上,OpenAI詳細列出模型的常見問題,比如在長視頻中出現的邏輯不連貫,或者物體會無緣無故地出現。

最後,OpenAI表示,Sora目前所展現出的能力,證明不但提升視頻模式的規模是一個令人振奮的方向。
沿這個方向走下去,或許有一天,世界模型就會應運而生。
網友:未來遊戲動嘴做
OpenAI給出眾多的官方演示,看得出Sora似乎可以為更逼真的遊戲生成鋪路——僅憑文字描述就能生成程序遊戲。
這既令人興奮,又令人恐懼。
FutureHouseSF的聯合創始人猜測,“或許Sora可以模擬我的世界。也許下一代遊戲機將是“Sora box”,遊戲將以2-3段文字的形式發佈”。
OpenAI技術人員Evan Morikawa稱,“在OpenAI發佈的Sora視頻中,如下的視頻讓我大開眼界。通過經典渲染器渲染這個場景是非常困難的。Sora模擬物理的方式和我們不同。它肯定仍然會出錯,但是我之前沒有預測到它能做得這麼逼真”。


有網友稱,“人們沒有把『每個人都會成為電影制作人』這句話當回事”。
我在15分鐘內制作這部20年代的預告片,使用OpenAI Sora的片段,David Attenborough在Eleven Labs上的配音,並在iMovie上從YouTube上采樣一些自然音樂。


還有人稱,“5年後,你將能夠生成完全沉浸式的世界,並實時體驗它們,“全息甲板”即將變成現實”!
有人甚至表示,自己完全被Sora的AI視頻生成的出色效果驚呆。
“它讓現有的視頻模型看起來像是愚蠢的玩具。每個人都將成為一名電影制作人”。

“新一代電影制作人即將與OpenAI的Sora一起湧現。再過10年,這將是一場有趣的比賽”!

“OpenAI的Sora暫不會取代好萊塢。它將為好萊塢以及個人電影制作者和內容創作者,帶來巨大的推動力。
想象一下,隻需3人團隊,就能在一周內,完成一部120分鐘的A級故事片的初稿創作和觀眾測試。這就是我們的目標”。

參考資料:
https://openai.com/research/video-generation-models-as-world-simulators?ref=upstract.co